Планирую написать программу-библиотеку.
Задача: есть несколько не связанных между собой компьютеров. На каждом 40-50 тысяч книг/журналов/статей/документов и т.п. в популярных форматах (pdf, djvu, doc, html, tiff). На некоторых машинах ожидаются незначительные изменения (1-2 тысячи добавятся/удалятся/изменятся). На других — значительные изменения: документы будут добавляться до количества как минимум 300 тысяч.
Если запрашиваемый документ на текущей машине не найден — то будут опрашиваться все машины из списка.
На данный момент все документы хранятся как простые файлы в папках. База будет содержать небольшое описание документа/книги + заметки персонала.
Встал вопрос как правильно организовать хранение большого количества файлов?
1) Может имеет смысл положить их в базу? И потом по запросу доставать во временную папку и показывать пользователю. Из плюсов — что удобнее бекапить, можно бекабить блобом, соответсвенно скорость бекапа будет выше + случайно потерять документ сложно. Из минусов — как-то мне не нравится, что полноценную самодостаточную сущность нужно запихивать в базу.
2) Либо оставить всё так как есть? И в базе хранить только пути к книгам/документам? Из плюсов — проще на данном этапе, хранение возлагается на файловую систему. Из минусов — бекап множества мелких файлов занимает очень много времени + потенциальная возможность получить неконсистентность данных, когда файл удаляется/добавляется не xxthtp мою программу.
Нужен совет как поступить лучше.
Re: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, push, Вы писали:
P>Встал вопрос как правильно организовать хранение большого количества файлов?
Вариант дёшево и сердито:
1. Чем не подходит peer-based репликация? Бэкап делается банальным поднятием клонов + diff-снапшотами через shadow copying/LVM
2. Документы в таких системах как правило считаются неизменяемыми, как раз чтоб не было необходимости возиться с синхронизацией контента / консистентностью.
Для оптимистов: ms sql filetable: тож дёшево, тож сердито, всё из коробки, во сколько обойдётся репликация и утыкание в лимиты бесплатной версии — это не ко мне
Re: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, push, Вы писали:
P>Нужен совет как поступить лучше.
Каким образом предполагается добавлять/удалять/искать контент? Исключительно через твою программу или ещё третьмим средствами вроде проводника или ftp? Какая ОС стоит на этих компьютерах?
Sic luceat lux!
Re: Как правильно организовать хранение большого количества небольших файлов?
GlusterFS — это распределённая, параллельная, линейно масштабируемая файловая система с возможностью защиты от сбоев. С помощью InfiniBand RDMA или TCP/IP GlusterFS может объединить хранилища данных, находящиеся на разных серверах, в одну параллельную сетевую файловую систему.
...
Бо́льшая часть функциональности GlusterFS реализована в виде трансляторов (модулей). Использование необходимых трансляторов и их настройка позволяет гибко конфигурировать режим работы системы. Трансляторы реализуют следующую функциональность:
Синхронная репликация между серверами (нельзя расширить уже существующий том, добавив сервер для репликации)
Чередование порций данных между серверами (Striping)
Распределение файлов между серверами
Балансировка нагрузки
Восстановление после отказа узла (в ручном режиме с помощью опроса файлов (ls -lR или find на смонтированом томе))
Опережающее чтение (read-ahead) и запаздывающая запись (write-behind) для увеличения быстродействия
Дисковые квоты
Или вот Ceph, Lustre, MooseFS, и так далее.
P>Может имеет смысл положить их в базу?
Базу данных логично использовать для поиска, но уж точно не для хранения файлов.
P>бекап множества мелких файлов занимает очень много времени + потенциальная возможность получить неконсистентность данных
Для этого и нужны отказоустойчивые файловые системы, есть ссылка на файл, а уж как они там обеспечат репликацию их забота.
Re[2]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, Sinix, Вы писали:
S>Для оптимистов: ms sql filetable: тож дёшево, тож сердито, всё из коробки, во сколько обойдётся репликация и утыкание в лимиты бесплатной версии — это не ко мне
Дёшево и сердито это обычная синхронизация, вроде Rsync. Но это уже совсем дёшево, и совсем сердито.
Re: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, push, Вы писали:
P>Планирую написать программу-библиотеку. P>Задача: есть несколько не связанных между собой компьютеров. На каждом 40-50 тысяч книг/журналов/статей/документов и т.п. в популярных форматах (pdf, djvu, doc, html, tiff). На некоторых машинах ожидаются незначительные изменения (1-2 тысячи добавятся/удалятся/изменятся). На других — значительные изменения: документы будут добавляться до количества как минимум 300 тысяч. P>Если запрашиваемый документ на текущей машине не найден — то будут опрашиваться все машины из списка.
Пока количество документов — сотни тысяч/миллионы — можно спокойно держать на каждом компьютере полные индексы и регулярно обмениваться их обновлениями. И только после первого-второго миллиона документов начинать потихоньку думать о каких-то оптимизациях.
Re[3]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, velkin, Вы писали:
V>Дёшево и сердито это обычная синхронизация, вроде Rsync. Но это уже совсем дёшево, и совсем сердито.
Не, я по совокупности расходов.
Всё-таки для peer-based sync не надо самому разруливать поднятие доп узла, перевыборы, поиск пиров и прочую нудятину.
Re[2]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, Sinix, Вы писали:
S>1. Чем не подходит peer-based репликация? Бэкап делается банальным поднятием клонов + diff-снапшотами через shadow copying/LVM
Собственно вопрос в том хранить ли в базе пути к файлам, или сами файлы?
S>2. Документы в таких системах как правило считаются неизменяемыми, как раз чтоб не было необходимости возиться с синхронизацией контента / консистентностью.
О, хорошее замечание. Тоже один из вопросов — о изменении. Но тоже прихожу к выводу, что каждое изменение — это будет новая версия файла. Иначе всё усложняется.
Re[2]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, Kernan, Вы писали:
K>Каким образом предполагается добавлять/удалять/искать контент? Исключительно через твою программу или ещё третьмим средствами вроде проводника или ftp? Какая ОС стоит на этих компьютерах?
В идеале — только через мою программу, чтобы я мог контролировать версии файлов. ОС — на всех Windows, на одной Linux Mint (тут больше всего файлов)
Re[2]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, push, Вы писали:
S>>1. Чем не подходит peer-based репликация? Бэкап делается банальным поднятием клонов + diff-снапшотами через shadow copying/LVM P>Собственно вопрос в том хранить ли в базе пути к файлам, или сами файлы?
Проблема в том, что при хранении файлов в базе вам нужно будет решение всё-в-одном: чтоб была репликация, эффективная работа с блобами, полнотекстовый поиск и тыды. Да ещё и бесплатно на больших объёмах. Много таких знаете?
При хранении по отдельности задача одновременно усложняется и упрощается — можно развязать собственно систему хранения файлов и саму базу.
Тогда у вас не будет необходимости искать решение "как реплицировать и файлы и базу одновременно?" и будет работать примерно такая схема:
сервис получает guid файла из базы, отдаёт его вашей псевдо-CDN, та подтягивает файл в локальный кэш и отдаёт файл сервису. Минусы стандартные — надо будет самостоятельно закладываться на ситуации "опс, что-то отвалилось".
В общем определяйтесь и сравнивайте, т.к. по сути от этого решения зависит вся остальная архитектура.
Если бы не было требования хранить распределённо и только часть файлов, я бы взял бесплатный ms sql express, там есть всё, включая полнотекстовый поиск.
При некотором везении можно уместиться в его лимиты.
Re[3]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, push, Вы писали:
P>мммммм, так вопрос-то собственно: хранить ли сами файлы в базе, или только пути к ним?
Так и пишу, что индексы хранить везде — т.е. пути (+ может быть на каких машинах) + какой-то набор признаков (от имени до обложек/данных для поиска). Или все-таки rsync-ом на всех компах поддерживать общую кучу документов + слепить из соплей и палокdiff и patch обмен метаданными (которые заметки персонала).
Только один подозрительный момент — как согласуются
есть несколько не связанных между собой компьютеров
с
документ на текущей машине не найден — то будут опрашиваться все машины из списка
?
P.S. А точно общая сетевая шара не вариант?
P.P.S. Для таких объемов в роли "базы" вполне сойдет обычный csv (или несколько), может быть сжатый zlib-ом.
Re[4]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, Sinix, Вы писали:
S>Проблема в том, что при хранении файлов в базе вам нужно будет решение всё-в-одном: чтоб была репликация, эффективная работа с блобами, полнотекстовый поиск и тыды. Да ещё и бесплатно на больших объёмах. Много таких знаете?
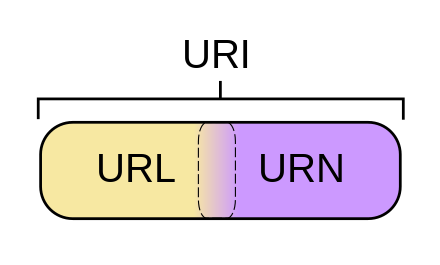
Postgres, другое дело, а стоит ли так делать, то есть хранить файлы блобами в базе данных. У файлов же на мой взгляд есть две характеристики. Для общего понимания можно прочесть URN.
URN не включает в себя путь к файлу:
<NID>
идентификатор пространства имён (англ. Namespace Identifier); представляет собой синтактическую интерпретацию NSS, не чувствителен к регистру.
<NSS>
строка из определённого пространства имён (англ. Namespace Specific String); если в этой строке содержатся символы не из набора ASCII, то они должны быть закодированы в Юникоде (UTF-8) и предварены (каждый из них) знаком процента «%» (подробнее см. URL).
То есть NSS может быть чем угодно, хоть ISBN, но по-настоящему в эту концепцию укладываются контрольные суммы.
Вторая часть это URL. Отношение таблицы URN к таблице URL как один ко многим. Нетрудно догадаться, что весь диск легко просканировать высчитав хеш-суммы и добавить их в базу данных. При добавлении же просматривать встречался ли файл. Если нет, тогда создать новый файл в таблице urn. Если да, тогда использовать существующий. И соответственно добавить новый путь, если такового не существует в таблице url.
А так, конечно, мне эта тема близка, всякие велосипедные библиотеки каталогизаторы. И блобы записывал и извлекал, и файлы на диске сканировал криптографией, там надо читать с диска один раз, и вычислять сразу все возможные хеши во всех доступных потоках исполнения. Блобы ещё плохи тем, что на самом деле это не то, что нужно пользователям в данной ситуации.
Re[5]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, push, Вы писали:
V>> Блобы ещё плохи тем, что на самом деле это не то, что нужно пользователям в данной ситуации. P>Что вы имеете ввиду? (нутром чувствую тоже самое но не получается сформулировать почему)
Всё это обсуждали ещё на форуме генезиса в 2009 году, опять же собственные опыты и требования выдвигаемые разными людьми. К примеру, база данных может навернуться во время работы, и так получится со всеми файлами. Файл базы данных будет чудовищных размеров, это лишние проблемы, а если ещё захочется кэшировать в оперативке. Нерешаемых проблем нет, но смысл решать проблемы, которые создаёшь себе сам.
Важно, чтобы люди доверяли каталожной системе. Засунуть файлы блобами в базу данных для большинства всё равно, что создать закрытый формат. Негатив вызывает даже переименование файлов в контрольные суммы, но это ещё куда ни шло. Иными словами без вашей программы с базой данных файлы превратятся в мусор. От базы данных требуется хранение метаданных (данные о данных), но не самих данных. Это позволит вести быстрый поиск и открытие файлов. Без этого скорее всего даже сам каталогизатор бы не понадобился. Посмотрите хотя бы на тот же генезис, у них там 1.5 миллиона файлов, база отдельно, а файлы можно выкачать поштучно или торрентами.
В итоге выкачав относительно небольшую по объёму базу данных уже можно осуществлять поиск по файлам самостоятельно. А с блобами такой фокус не пройдёт, да ещё и сам замучаешься её копировать, не говоря уже о пользователях. По идее база данных может быть даже не базой данных как таковой, а sql-запросом заархивированный каким-нибудь архиватором файлов, который создаёт схему базы и добавляет записи в таблицы, блобы опять в пролёте.
Базу данных можно настроить на репликацию в реальном времени, а можно старомодно на бекапы хотя бы раз в сутки. Файлы же гораздо проще контролировать с помощью контрольных сумм. Находись они у вас в папке, вам даже не придётся ничего писать, примитивная синхронизация (rsync), подсчёт контрольных сумм (md5sum, sha1sum), и то и другое вместе плюс распространение через файлообменные сети (BitTorrent, Direct Connect и т.д.). Давным давно помню некоторые даже создавали решения на основе magnet-ссылок.
Не помню где видел, скорее всего в программной инженерии. Самое первое, что должен рассмотреть программист это отказ от программирования, то есть использование готовых решений. А это проще, когда метаданные и данные разделены. Опять же захочется массово извлечь из файлов текстовый слой, но лень долго писать и разбираться, хотя на файлы сразу можно было бы натравить готовую утилиту со скриптами или запуская её программой с параметрами. Преимуществ же хранения файлов в базе данных по сути нет. Опять же мелкий файл это килобайт, а даже если файлы в среднем мегабайт, то это уже крупные и проблем с их копированием не будет, и это речь всего лишь про HDD, а есть ведь SSD и там расклад другой.
Re[3]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, push, Вы писали:
P>Здравствуйте, Kernan, Вы писали:
K>>Каким образом предполагается добавлять/удалять/искать контент? Исключительно через твою программу или ещё третьмим средствами вроде проводника или ftp? Какая ОС стоит на этих компьютерах? P>В идеале — только через мою программу, чтобы я мог контролировать версии файлов. ОС — на всех Windows, на одной Linux Mint (тут больше всего файлов)
Тогда тебе проще всего воспользоваться советом про распределённую ФС и смонтировать его как одино хранилище, тобишь виртуализировать всё что можно и уже поверх этого прикрутить своё софт.
Sic luceat lux!
Re[7]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, velkin, Вы писали:
V>Здравствуйте, push, Вы писали:
V>>> Блобы ещё плохи тем, что на самом деле это не то, что нужно пользователям в данной ситуации. P>>Что вы имеете ввиду? (нутром чувствую тоже самое но не получается сформулировать почему)
V>Всё это обсуждали ещё на форуме генезиса в 2009 году, V> Посмотрите хотя бы на тот же генезис, у них там 1.5 миллиона файлов, база отдельно, а файлы можно выкачать поштучно или торрентами.
Что за генезис? Где можно почитать на форуме?
V>В итоге выкачав относительно небольшую по объёму базу данных уже можно осуществлять поиск по файлам самостоятельно.
А где про такую технику(подход) можно подробнее почитать? Это типа как торренты организованы?
Кодом людям нужно помогать!
Re[8]: Как правильно организовать хранение большого количества небольших файлов?
Здравствуйте, Sharov, Вы писали:
S>Что за генезис? Где можно почитать на форуме?
Форум Library Genesis, все ссылки на главной странице. Сообщество закрытое, прежде чем читать нужно зарегистрироваться на форуме. Качать можно сразу.
V>>В итоге выкачав относительно небольшую по объёму базу данных уже можно осуществлять поиск по файлам самостоятельно. S>А где про такую технику(подход) можно подробнее почитать? Это типа как торренты организованы?
Почитайте тогда уж на их форуме, подходов на самом деле много.
Re: Как правильно организовать хранение большого количества небольших файлов?
Тут как бы противоречие: если компьютеры не связаны, то опрашивать все машины из списка не выйдет.
Во вторых, не оговорена необходимость синхронизации документов.
P>Встал вопрос как правильно организовать хранение большого количества файлов?
Лучше файловой системы вроде ничего не придумали, зато их напридумывали очень разными.
Из практики есть рекомендация использовать вложенные папки и не сваливать всё в одну папку.