Здравствуйте, Cynic, Вы писали:
C>Взявшись за анализ существительное/глагол, довольно быстро пришел к выводу, что такой анализ состоит из набора однотипных действий. А проанализировав пару десятков страниц вручную, чего-то очень захотелось автоматизировать процесс  По сути описание прецедента это сценарий, где на каждом шагу пользователь взаимодействует с системой, и всё что нужно сделать это разделить действия на действия выполняемые системой и пользователем. Если язык описания прецедентов достаточно формализован, то это сделать не сложно. Потом откинуть действия типа "Пользователь выбрал", "Пользователь ввёл", "Система предлагает" или "Система сообщает" и останется, то к чему уже собственно и надо применять мозги.
C>Вот я и подумал, что наверняка уже кто нибудь позаботился об этом и должны быть средства облегчающие такой анализ
По сути описание прецедента это сценарий, где на каждом шагу пользователь взаимодействует с системой, и всё что нужно сделать это разделить действия на действия выполняемые системой и пользователем. Если язык описания прецедентов достаточно формализован, то это сделать не сложно. Потом откинуть действия типа "Пользователь выбрал", "Пользователь ввёл", "Система предлагает" или "Система сообщает" и останется, то к чему уже собственно и надо применять мозги.
C>Вот я и подумал, что наверняка уже кто нибудь позаботился об этом и должны быть средства облегчающие такой анализ 
Вот что нашел сам. Разработчики сайтов используют понятие "семантическое ядро", это по сути список ключевых слов использующихся в тексте. Процедура разбора текста для вычленения семантического ядра называется "семантический анализ текста". С её помощью можно выяснить всё, что нужно о взаимоотношении слов в тексте. Для примера нашел
такой ресурс.
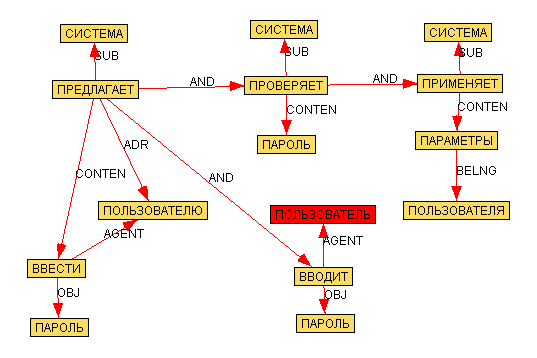
Смотрите какой симпатичный граф строит
эта демка, для такого UseCas'a:
1. Система предлагает пользователю ввести пароль
2. Пользователь вводит пароль
3. Система проверяет пароль
4. Система применяет параметры пользователя
Собственно граф:
В связи с этим, наверняка существует система способная проанализировать текст этого UseCas'a, убрать повторы, учесть слово-формы, сгруппировать по сущностям и построить нечто вроде таблицы ниже:
1. [Интерфейс ] Пользователь | вводит | пароль
2. [Интерфейс ] Система | предлагает | пользователю ввести пароль
3. [Менеджер паролей] Система | проверяет | пароль
4. [Менеджер системы] Система | применяет | параметры пользователя
А ваша задача уже раздать обязанности соответствующим классам анализа(в квадратных скобках). Правда для этого язык UseCas'a должен быть достаточно формализован(использовать ограниченное число слов). Но это небольшая проблема, т.к. при взаимодействии пользователя и системы, в 90% случаев выполняются типовые действия, из цикла "Пользователь выбрал", "Пользователь ввёл", "Система предлагает" или "Система сообщает" и т.п.
Интересно, что проанализировав UseCas'ы касающиеся управления учётными записями и аутентификации, общей длинной в 11 страниц, я с удивлением обнаружил, что в описываемых ими взаимодействиях участвует всего 14 уникальных сущностей и 88 взаимодействий между ними. После этого, откинув взаимодействия связанные с логикой работы интерфейса, осталось всего 12 взаимодействий, которые были распределены по 3 классам анализа. Таким образом, в аналитической схеме описывающей эти UseCas'ы использовалось всего 4 класса анализа, которые полностью описывали её функциональность.
Но при этом на построение схемы после анализа у меня ушло 15 минут, а на сам анализ 8 часов, включая такие замечательные операции как составление словаря, таблиц, поиск дубликатов и прочей ереси

При этом я всю дорогу делал по сути одно и то-же. Так, что автоматизировать процесс не помешало-бы
Мне интересно, что вы об этом думаете


