Здравствуйте, adontz, Вы писали:
A>Ну давай мерятся пиписьками. На вот A>http://en.wikipedia.org/wiki/Object-relational_mapping A>Что я сказал не так?
Видимо, не использовал Hibernate в реальности Кэш второго уровня там часто ускоряет работу в десятки раз, я об этом тут даже писал.
A>>>Если транзакция нужна, а её нет ORM не спасёт. kuj>>Какие проблемы с транзакциями? OR/M отлично справляются с организацией транзакций. A>БД справляется ещё лучше. Нельзя на ORM сваливать всё то, что лень было запрограммировать в БД, так как в результате ты получишь неповоротливую систему.
Ты слово "организацией" не заметил? В Hibernate там для этого так вообще инструментов БОЛЬШЕ, чем в голом SQL. В частности, есть очень полезная автоматическая оптимистическая блокировка с поддержкой detach/attach для сессионных объектов, которую руками писать — только ошибки плодить (так как ее обязательно будут забывать использовать).
A>>>Если делается выборка по неиндексированному столбцу ORM опять таки не спасёт. Спасают, в плане не дают облажатся, именно ХП. kuj>>Да что Вы говорите... А посмотреть статистику сервера по запросам и грамотно проставить индексы не судьба? A>Ага, то есть предлагаешь отлаживаться на production сервере? Зашибись. А если вдруг выяснится что сама структура хранения неверная и надо не индексами манипулировать, а менять всё нафиг?
Нормальность (во всех смыслах) схемы ПРЕКРАСНО можно проверить вообще "на глаз". Если DBA не замечает таких явных косяков — то его увольнять надо. Расстановка неочевидных индексов, действительно, лучше всего делается по результатам нагрузочного тестирования (на тестовом сервере, не на production!).
Другое дело, когда все было изначально неправильно спроектировано из-за неправильного моделирования предметной области. Но тут хранимые процедуры будут только в минусе — код с нормальным DAL'ом рефакторить легче.
kuj>>А то время, которые Ваши программисты тратят на поддержку монструозных нечитабельных нетестируемых ХП, можно было бы потратить на более тщательную проработку архитектуры базы и клиентов базы. A>Нечитабельные ХП это миф. Нет никаких причин их так писать.
Они сами так получаются. Причем, если программисты читают ХП, то у нас теряется один из мотивов их внедрения — разделения труда между разработчиками БД и приложения.
A>>>Именно тот факт, что ORM являясь очень удобными средствами никак не контроллирующим разработчика и приводит к отказу от ORM в действительно крупных проектах. kuj>>Кто Вам эту чушь сказал? A>Я тебе говорю. Никто в крупном проекте HQL не пользуется, это подходит только для какого-нибудь среднего онлайн-магазина.
???
Ты знаешь такой меееелкий тормозной проект как Google Adwords или Google Blogs? Так вот, их не существует, так как Hibernate в них используется.
A>>>Когда БД растёт вместе с проектом и эта специфика меняется начинаются странные падения производительности "хотя совсем недавно всё работало". Получаем мину замедленного действия. kuj>>Чушь. A>Ну значит не всречался. Я вот встречался.
Чушь, чушь. Такие "падения производительности" были бы и с SQL, так как Hibernate не делает ничего магического.
A>>>Единственное известно мне исключение — это BLT, но там просто функциональности недостаточно чтоб мины делать (хотя в том что BLT делает, она на высоте). kuj>>Не знаю, не работал с BLT и не слышал ни об одном более-менее крупном проекте на BLT. A>Ну расширить твой кругозор не сложно. http://www.rsdn.ru/Forum/Info/FAQ.rfd.rfdprojects.aspx
http://hibernate.org/113.html http://hibernate.org/290.html
(и это мааааааааааленькая часть общего количества)
A>То что ты написал это полный бред. Получается нельзя тестировать методы классов вызывающие другие методы. Тесты для ХП пишет тот жекто и ХП, для него она не чёрный ящик. А вот тот факт, что ХП чёрный ящик для всех остальных меня радует. Примерно так же как модификатор private. Инкапсуляция... слышал?
Открой для себя mock objects Я сейчас вообще слабо понимаю как без них тестировал раньше.
A>>>Если тебе не совсем плевать на производительность, то да. kuj>>А какие проблемы с производительностью? A>Если ты пишешь SQL код работащий под несколько СУБД с минимальными правками, то наверняка не учитываешь особенности СУБД и не пользуешься всеми её возможностями. Как следствие — абсолютно неадекватная производительность.
Так если тормозит — втыкаем вместо HQL-запроса оптимизированый SQL. Какие проблемы-то? Hibernate позволяет замечательно использовать нативный SQL. Только вот нужно это всего в процентах случаев.
Sapienti sat!
Re[11]: Оформление работы с БД в корпоративных приложениях -
Здравствуйте, adontz, Вы писали:
A>>Что процедурное программирование не менее удобно чем объектное?
A>Зависит от контекста. Иногда объекты ни к селу, ни к городу. В реляционной БД я места ООП не вижу.
Конечно не видете. Как же Вам видеть, если Вы вообще не понимаете о чем речь...
... << RSDN@Home 1.2.0 alpha rev. 746>>
Re[15]: Оформление работы с БД в корпоративных приложениях -
Здравствуйте, adontz, Вы писали:
A>>>Вот-вот! Вот этого-то ты и не понимаешь! Народ пишет мегамощные оптимизаторы, реализует сложнешие алгоритмы, а ты телевозир используешь как тумбочку. БД — это НЕ только хранилище данных, но и обработчик низкого уровня. A>>Если бы Вы такое произнесли в году там 97, это было бы сильное высказывание, а вот в 2007ом стараются максимально абстрагироваться от конкретики СУБД . ORM стновится де факто стандартом разработки корпоративных приложений, linq уже близок к релизному варианту, веб страницы активно пишут на компилируемых яъзыках, скрипты постепенно отмирают...
A>Я так понимаю для тебя SQL и PHP языки одного типа. Печально.
Разберитесь для начала ЧТО такое SQL и что такое хранимые процедуры на T-SQL, а для развития почитайте еще про PL/SQL.
... << RSDN@Home 1.2.0 alpha rev. 746>>
Re[11]: Оформление работы с БД в корпоративных приложениях -
Здравствуйте, adontz, Вы писали:
A>>>Потому что если есть возможность совершить ошибку, ты хоть миллион предупреждений повесь, всё равно найдётся дурак, который её совершит. C>>В том числе и DBA в ХП, а эту ошибку потом будут долго отлаживать тупые прикладные пользователи, которые ни разу в жизни не написали ни одного запроса. A>Извини, мы не об опечатках. Я ни разу не видел, чтобы разработчик БД сам написал SELECT с кривым планом для БД разработанной им же. Он значит притворяется разработчиком БД если так.
Планы для "SELECT ... WHERE a.name='aa'" он тоже проверяет? А ведь таких тривиальных запросов — больше всего.
A>>>Эти операции тебе понадобятся в любом случае. Никаких лишних сущностей тут нет. C>>Есть. Я могу выкинуть кучу ручного труда с помощью разных автоматических байндеров и валидаторов. A>Ты не можешь с помошью байндеров и валидаторов избежать неоптимизированного конечного SQL запроса. SQL запросы пишутся руками и я за то чтобы из писали только квалифицированны кадры, а не все подряд по мере надобности.
Т.е. разработчики будут стучать головой об стену, пока программисты БД не соизволят написать нужный запрос? Действительно, так и получается — сам видел.
А про оптимизацию сложных запросов я уже писал — это работа DBA, ее никто не отнимает.
C>>Если DBA знает только SQL — то он не сможет понять ТЗ, написаное аналитиком. Так что возможны два варианта: A>Вполне сможет, если оно написано на уровне Entity-Relations.
Ага, кончено. А модель в виде готовой схемы БД от аналитика он так вообще хорошо может понять.
A>Это порочная практика. Рядовой разработчик никогда не сможет придумать действительно удачную схему хранения данных в БД. DBA должен плясать не от объектной модели, а от ER-диаграммы.
Для тебя будет сюрпризом, но ER-диаграммы прекрасно ложатся на объектную модель.
A>В описанном тобой сценарии DAL скорее всего выродится, так как БД будет отображать иерархию объектов, а не хранимые данные.
А иерархия объектов (кстати, использовали наследование в persistent-объектах всего несколько раз) — это не данные?
A>Подкрутить индексы и денормализовать чего-нибудь это далеко не самое главное в разработке схемы. Есть данные которые в реляционную модель, порой, просто не укладываются как есть и их надо преобразовывать до неузнаваемости.
Если они преобразуются до неузнаваемости — то программистам все равно придется с ними как-то работать. Так что опять никаких преимуществ.
C>>2. Аналитик дает задание DBA. DBA рисует схему и отдает ее программистам. Программисты по схеме строят DAL. A>Хороший сценарий, мой любимый. Я получаю качественный продукт от человека, не сбитого с толку чьими-то неуместными ОО-идеями.
Ага, вот только обычно от DBA получаются далеко не самые удобные для использования схемы (типа с эмуляцией наследования с помощью CASE'ов).
C>>Случай когда тебе дают готовую схему БД означает, что приложение уже скорее всего было написано и работает. Тогда ничего не мешает тебе дать и готовый слой DAL (в виде отдельного модуля). Просто очень часто как раз делают псевдо-DAL на хранимках. A>Нет, я всегда по мере возможности настаиваю чтобы БД разрабатывалась в первую очередь.
Мда...
C>>Хороший пример. А если у нас нет операции MoveArticle? Как ты в случае БД A>Ты кажется не дописал вопрос. Во всяком случае он выглядит недописанным.
Да, странно. Сейчас надо вспомнить что я хотел написать Надо меньше писать в 5 часов утра....
C>>На откуп DBA остаются только оптимизации сложных запросов и всякие сложные операции, требующие временных таблиц, километровых запросов и кувырков с переворотами. Вот тут, кстати, ХП как раз вполне подходят. A>Это DBA-лентяи какие-то. Напрограммил то, что было самому интересно, а на остальное плюнул, путь негры пашут Безответственно Почему именно — ниже (пометил знаком %).
Нет, это очень хороший подход — все делают то, что им нравится. А рутинная работа автоматизирована и ее вообще делает сам компьютер.
C>>Вот ты мне привел пример с XP для операций с User'ом. Не вижу там ни одного нетривиального SQL-оператора, который не смогу написать бы даже студент. Зачем тогда заставлять высококвалифицированного DBA заниматься этой ерундой? A>Высококвалифицированного вероятно незачем, но даже такой ерундой кто-то должен заниматся не по мере надобности, а в соответствии с генеральным планом, потому что даже в такой ерунде можно наломать дров.
А почему бы не поручить эту работу самому компьютеру? Чем это хуже?
C>>А если мы даем программистам писать/править свои ХП — то тогда они уже у нас скорее всего не полные идиоты, неспособные понять даже простого SQL UPDATE. A>% (пометка, которую ты ждал) A>Проблема в том, что этот простой SQL UPDATE в деномализованной для чего-то там БД может разрушить целостность данных. DBA знает (помнит, записал, пометил для себя крестиком на пальце) что таблица денормализована и что обновив тут, надо ещё подкрутить там (кстати опять транзакция уровня БД, без неё никак). Рядовой программист этого не знает и может напортачить. А раз может, значит обязательно напортачит. Считай это законом Мерфи.
Кстати! Хорошее замечание, у нас была подобная проблема — неявная связь нескольких таблиц. В результате выловили несколько сложных ошибок, DBA забывали (по закону Мерфи!) синхронизировать таблицы (DBA ничего не заметил).
В результате написали набор декларативных правил, которые теперь следят за целостностью системы.
A>DBA не тормозит разработку как ты пытаешь представить, он не злой дядя-тормозун. Просто изменения большой системы с сохраненим её согласованности это конечно же куда более сложный и длительный процесс, чем написание "с нуля" как надо. Да, добавить столбец в таблицу оставив все запросы целостными может оказатся не просто. Но пусть этим занимается один человек, а иначе будут "сюрпризы".
Нет, нужно проектировать систему так, чтобы добавление столбцов ничего не ломало (или ломало как можно быстрее). А не надеятся на внимание одного человек.
Sapienti sat!
Re[11]: Оформление работы с БД в корпоративных приложениях -
C>>Если DBA знает только SQL — то он не сможет понять ТЗ, написаное аналитиком. Так что возможны два варианта:
A>Вполне сможет, если оно написано на уровне Entity-Relations.
Где Вы видели такие ТЗ?
A>DBA должен плясать не от объектной модели, а от ER-диаграммы.
Да ну? Кто Вам это сказал?
C>>Случай когда тебе дают готовую схему БД означает, что приложение уже скорее всего было написано и работает. Тогда ничего не мешает тебе дать и готовый слой DAL (в виде отдельного модуля). Просто очень часто как раз делают псевдо-DAL на хранимках.
A>Нет, я всегда по мере возможности настаиваю чтобы БД разрабатывалась в первую очередь.
Я бы хотел поинтересоваться, с чего Вы решили, что БД должна разрабатываться в первую очередь? Особенно, если речь о корпоративных приложениях?
C>>А если мы даем программистам писать/править свои ХП — то тогда они уже у нас скорее всего не полные идиоты, неспособные понять даже простого SQL UPDATE.
A>% (пометка, которую ты ждал) A>Проблема в том, что этот простой SQL UPDATE в деномализованной для чего-то там БД может разрушить целостность данных. DBA знает (помнит, записал, пометил для себя крестиком на пальце) что таблица денормализована и что обновив тут, надо ещё подкрутить там (кстати опять транзакция уровня БД, без неё никак).
Мдаааааааааааа...................
... << RSDN@Home 1.2.0 alpha rev. 746>>
Re[10]: Оформление работы с БД в корпоративных приложениях -
Здравствуйте, Cyberax, Вы писали:
C>Видимо, не использовал Hibernate в реальности Кэш второго уровня там часто ускоряет работу в десятки раз, я об этом тут даже писал.
Любой кеш, как только у тебя появляется несколько серверов, надо между ними синхронизировать. Либо сбрасывать (плохо), либо подправлять (сложно). В любом случае, трафик синхронизации кеша между элементами кластера — зло, так как рождает топологию все-ко-всем, абсолютно не масштабируемую по определению.
C>Нормальность (во всех смыслах) схемы ПРЕКРАСНО можно проверить вообще "на глаз". Если DBA не замечает таких явных косяков — то его увольнять надо. Расстановка неочевидных индексов, действительно, лучше всего делается по результатам нагрузочного тестирования (на тестовом сервере, не на production!).
Дело в том, что то как ты хранишь данные во многом зависит от того, что ыт потом с ними собираешься делать и добавление новой операции может привести к пересмотру способа хранения.
C>Они сами так получаются. Причем, если программисты читают ХП, то у нас теряется один из мотивов их внедрения — разделения труда между разработчиками БД и приложения.
Программисты использующие ХП, читают, естесвенно, не весь код не ХП, а только описание (declaration).
C>Ты знаешь такой меееелкий тормозной проект как Google Adwords или Google Blogs? Так вот, их не существует, так как Hibernate в них используется.
Там есть HQL? HQL != Hibernate.
A>>Ну значит не всречался. Я вот встречался. C>Чушь, чушь. Такие "падения производительности" были бы и с SQL, так как Hibernate не делает ничего магического.
Ну вот почему-то их нет.
C>http://hibernate.org/113.html C>http://hibernate.org/290.html C>(и это мааааааааааленькая часть общего количества)
C>Открой для себя mock objects Я сейчас вообще слабо понимаю как без них тестировал раньше.
Тестирование знаешь вообще не панацея. Оно позволяет раньше вылавливать ошибки, но не позволяет лучше писать. Использование ORM приводит к выработке некоторых привычек, далеко не все из которых полезные.
C>Так если тормозит — втыкаем вместо HQL-запроса оптимизированый SQL. Какие проблемы-то? Hibernate позволяет замечательно использовать нативный SQL. Только вот нужно это всего в процентах случаев.
ХЗ, у нас этот процент оказался настолько большой, что HQL был отвергнут совсем. Может быть есть задачи на которых Hibernate генерирует что-то вменяемое, я больше сталкивался с другими задачами.
Здравствуйте, kuj, Вы писали:
kuj>Человек говорит Вам о рефакторинге и об опечатках в колонках. Когда у вас сотни процедур с таким вот именем колонки жестко прописанным в каждой процедуре... kuj>В случае с OR/M, поменяв имя колонки в базе, мне достаточно поменять его всего-лишь раз в файле мэпинга, а Вам придется перелопачивать все сотни процедур да еще и без стредств рефакторинга.
Здравствуйте, Aviator, Вы писали:
A>>Видишь ли, Hibernate как правило наботает в tier бизнесс-логики. У этого подхода есть преимущества в администрировании. Так что чего т так удивился я не особо понял. A>Сам то понял что написал?
ОМГ. У тебя есть две машины, на одной всё что на java, на воторой SQL-сервер. Это достаточно стандартная схема.
A>Это sql, мы говорим о T-SQL и хранимках. типичный код хранимки не декларативный и представляет из себя жёское процедурное программирование
Это какая-то неправильная хранимка, она значит что-то лишнее делает.
A>Что понимается по как попало объясните пожалуйста, а то я начинаю терять нить изложения.
Как попало обозначает "без виденья общей структуры БД, включая проведённые денормализации, кеширования и т.п.".
Нужно было работать с пользователями, прочитал документацию только про табличку Users, но не прочитал про таблички так или иначе с ней связанные и как следствие нарушил целостность данных некорерктными действиями.
Здравствуйте, Aviator, Вы писали:
kuj>>В случае с OR/M, поменяв имя колонки в базе, мне достаточно поменять его всего-лишь раз в файле мэпинга, а Вам придется перелопачивать все сотни процедур да еще и без стредств рефакторинга. A>Подозреваю, что человек не знает что такое рефакторинг так что Ваш довод для него пустой звук .
Здравствуйте, kuj, Вы писали:
kuj>Наоборот тут речь о том, чтоб генерацией SQL-запросов занимался Hibernate (или т.п.), который прекрасно с этой задачей справляется, и в запросах, генерируемых Hibernate, Вы не увидете "*".
Это миф. В реальной системе соответствие поле_класса<->колонка_таблицы встречается достааточно редко! Hibernate просто не в состоянии автоматически построить подобные запросы.
Здравствуйте, kuj, Вы писали:
A>>Зависит от контекста. Иногда объекты ни к селу, ни к городу. В реляционной БД я места ООП не вижу. kuj>Конечно не видете. Как же Вам видеть, если Вы вообще не понимаете о чем речь...
Давай я объясню просто, на примере. Если у тебя есть класс User вида
class User
{
public Guid ID {get;set};
public string Login {get;set}
public string FirstName {get;set}
public string LastName {get;set}
public ChangePassword(string oldPassword, string newPassword)
...
}
То ты, как адепт ОРМ, конечно же создашь таблицу с полями ID, Login, Password, FirstName, LastName. В нормальной, расширяемой БД такого не будет. Будет таблица Users (ID, Login, Password) и таблица UserProperties (UserID REFERENCES (Users.ID), PropertyName, PropertyValue). Это верное решение, потому что добавление полей в клас User никак не забрачивает схему БД, DAL и т.п. Чтобы такие правильные решения принимать надо при построении БД плясать не от иерархии объектов, а от представляемых сущностей. Фактически ORM это зло, действительно правильно делать ROM, так как только в этом случае можно получить вменяемую БД, построенную как надо и не являющуюся жалкой тенью чужеродного ей понятия иерархии объектов. ООП в БД делать нечего, Entity-Relations описанные в ТЗ ложатся в БД один к одному, объекты — нет. объекты вторичны, ER — первичны и именно на их основе надо строить БД.
Здравствуйте, Cyberax, Вы писали:
A>>Извини, мы не об опечатках. Я ни разу не видел, чтобы разработчик БД сам написал SELECT с кривым планом для БД разработанной им же. Он значит притворяется разработчиком БД если так. C>Планы для "SELECT ... WHERE a.name='aa'" он тоже проверяет? А ведь таких тривиальных запросов — больше всего.
Нет, он пишет ХП план которой разбирает один раз. Остальные пользуются ХП с проверенным планом. вот для того и нужны ХП, что это гарантированный способ не напортачить.
C>Т.е. разработчики будут стучать головой об стену, пока программисты БД не соизволят написать нужный запрос? Действительно, так и получается — сам видел.
Значит БД плохо расширяемая если на каждый чихз надо новый запрос писать. Пример про таблицы Users и Users-UserProperties я уже привёл.
A>>Вполне сможет, если оно написано на уровне Entity-Relations. C>Ага, кончено. А модель в виде готовой схемы БД от аналитика он так вообще хорошо может понять.
Я всегда требую описания ER, иначе это не ТЗ, а филькина грамота.
C>Для тебя будет сюрпризом, но ER-диаграммы прекрасно ложатся на объектную модель.
Далеко не всегда. У БД с этим намного лучше.
C>А иерархия объектов (кстати, использовали наследование в persistent-объектах всего несколько раз) — это не данные?
В общем случае иерархия объектов это НЕ данные. Ты разве не знал?
C>Если они преобразуются до неузнаваемости — то программистам все равно придется с ними как-то работать. Так что опять никаких преимуществ.
проблема в том, что их вовремя не пробразовывают строя БД как зеркало иерархии объектов, а не для хранения даных.
C>Ага, вот только обычно от DBA получаются далеко не самые удобные для использования схемы (типа с эмуляцией наследования с помощью CASE'ов).
Это уже мои проблемы, его дело эффективность. Можно найти компромисс, но БД первична и не должна строится на основе иерархии объектов.
C>А почему бы не поручить эту работу самому компьютеру? Чем это хуже?
Ничем, это идеальный вариант. Только компьютеры зачастую с этой задачей не справляются.
A>>Проблема в том, что этот простой SQL UPDATE в деномализованной для чего-то там БД может разрушить целостность данных. DBA знает (помнит, записал, пометил для себя крестиком на пальце) что таблица денормализована и что обновив тут, надо ещё подкрутить там (кстати опять транзакция уровня БД, без неё никак). Рядовой программист этого не знает и может напортачить. А раз может, значит обязательно напортачит. Считай это законом Мерфи.
C>Кстати! Хорошее замечание, у нас была подобная проблема — неявная связь нескольких таблиц. В результате выловили несколько сложных ошибок, DBA забывали (по закону Мерфи!) синхронизировать таблицы (DBA ничего не заметил). C>В результате написали набор декларативных правил, которые теперь следят за целостностью системы.
Хммм... может у вас DBA нормальных нет? Вот и обходитесь другими стредствами? Я-то с монстрами работал, повезло конечно, вот и привык доверять. ХЗ, конечно всегда надо исходить из квалификации тех с кем работаешь, но у меня таких проблем точно не было.
A>>DBA не тормозит разработку как ты пытаешь представить, он не злой дядя-тормозун. Просто изменения большой системы с сохраненим её согласованности это конечно же куда более сложный и длительный процесс, чем написание "с нуля" как надо. Да, добавить столбец в таблицу оставив все запросы целостными может оказатся не просто. Но пусть этим занимается один человек, а иначе будут "сюрпризы".
C>Нет, нужно проектировать систему так, чтобы добавление столбцов ничего не ломало (или ломало как можно быстрее). А не надеятся на внимание одного человек.
Нет, надо проектировать систему так, чтобы расширения функиональности не сопровождалось добавлением новых столбцов
Здравствуйте, kuj, Вы писали:
kuj>Где Вы видели такие ТЗ?
В руках держал.
A>>DBA должен плясать не от объектной модели, а от ER-диаграммы. kuj>Да ну? Кто Вам это сказал?
Так лучше выходит.
A>>Нет, я всегда по мере возможности настаиваю чтобы БД разрабатывалась в первую очередь. kuj>Я бы хотел поинтересоваться, с чего Вы решили, что БД должна разрабатываться в первую очередь?
Скажем так, тут не столько важна хронология, сколько важно отсутствие влияния объектной модели на разработку БД.
Здравствуйте, adontz, Вы писали:
A>Здравствуйте, kuj, Вы писали:
kuj>>Наоборот тут речь о том, чтоб генерацией SQL-запросов занимался Hibernate (или т.п.), который прекрасно с этой задачей справляется, и в запросах, генерируемых Hibernate, Вы не увидете "*".
A>Это миф. В реальной системе соответствие поле_класса<->колонка_таблицы встречается достааточно редко! Hibernate просто не в состоянии автоматически построить подобные запросы.
Да что вы говорите . Вы статистику по проектам собирали или говорите на основании вашего горького опыта? Уже даже не смешно...
Re[11]: Оформление работы с БД в корпоративных приложениях -
Здравствуйте, adontz, Вы писали:
C>>Видимо, не использовал Hibernate в реальности Кэш второго уровня там часто ускоряет работу в десятки раз, я об этом тут даже писал. A>Любой кеш, как только у тебя появляется несколько серверов, надо между ними синхронизировать. Либо сбрасывать (плохо), либо подправлять (сложно). В любом случае, трафик синхронизации кеша между элементами кластера — зло, так как рождает топологию все-ко-всем, абсолютно не масштабируемую по определению.
Видимо, ты никогда не видел: http://tangosol.com/coherence-overview.jsp — кластерный транзакционный кэш, легко масштабируется на десятки машин (но стоит денег, сволочь). Сейчас используем тупой JBoss Cache — на кластере из пяти машин все спокойно живет, даже 100MBit не заполняет.
Кстати, получается намного эффективнее, чем без кэша — куча простых запросов до БД даже не доходит.
C>>Нормальность (во всех смыслах) схемы ПРЕКРАСНО можно проверить вообще "на глаз". Если DBA не замечает таких явных косяков — то его увольнять надо. Расстановка неочевидных индексов, действительно, лучше всего делается по результатам нагрузочного тестирования (на тестовом сервере, не на production!). A>Дело в том, что то как ты хранишь данные во многом зависит от того, что ыт потом с ними собираешься делать и добавление новой операции может привести к пересмотру способа хранения.
Замечательно. Поменяли способ хранения. Что дальше? Вариантов всего два:
1) Ляпать заплатки в виде видов для совместимости, хранимых процедур и т.п. Именно так обычно и поступают DBA.
2) Зарефакторить приложение. Тут несомненным лидером являются нормальные языки.
C>>Они сами так получаются. Причем, если программисты читают ХП, то у нас теряется один из мотивов их внедрения — разделения труда между разработчиками БД и приложения. A>Программисты использующие ХП, читают, естесвенно, не весь код не ХП, а только описание (declaration).
Ага, а в коде ХП ошибок ну вообще никогда не бывает, конечно?
C>>Ты знаешь такой меееелкий тормозной проект как Google Adwords или Google Blogs? Так вот, их не существует, так как Hibernate в них используется. A>Там есть HQL? HQL != Hibernate.
Есть Создатели Google Blogs написали неплохой guide про использование Hibernate в таких приложениях. Про HQL там тоже глава была.
Собственно, HQL — это просто другая запись SQL. Так что ничего удивительного, да еще и в следующей версии собираются добавить прямо в HQL поддержку DB-specific хинтов.
C>>Открой для себя mock objects Я сейчас вообще слабо понимаю как без них тестировал раньше. A>Тестирование знаешь вообще не панацея. Оно позволяет раньше вылавливать ошибки, но не позволяет лучше писать. Использование ORM приводит к выработке некоторых привычек, далеко не все из которых полезные.
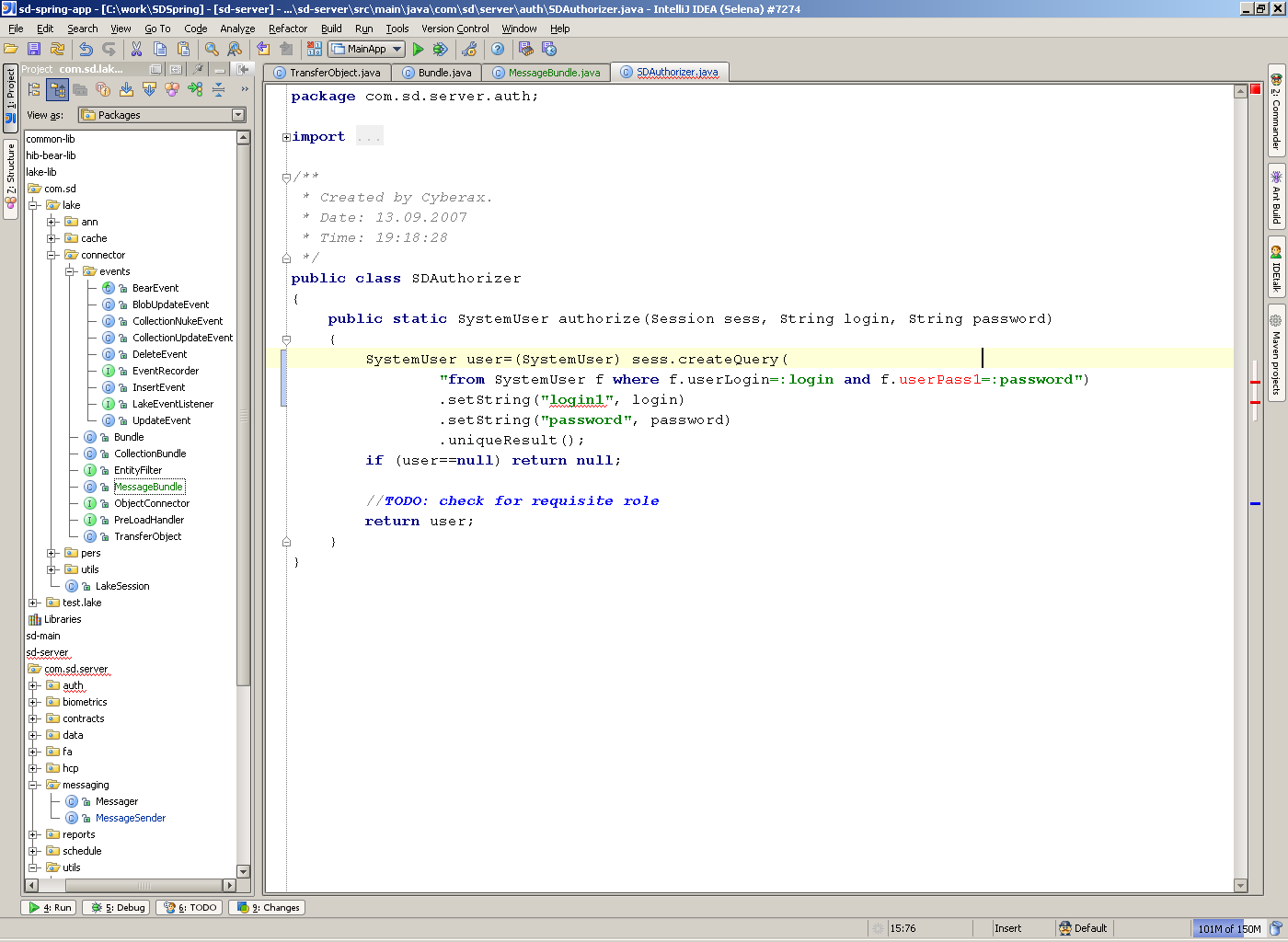
Ага, такие вредные привычки как легкорефакторируемый код и запросы. Например, вот так умеет новая IDEA:
Я специально сделал ошибки: неправильное имя поля и установку несуществующего параметра. Обрати внимание на подсветку синтаксиса запроса. Естественно, при редактировании запроса работает автокомплит, рефакторинг и т.п.
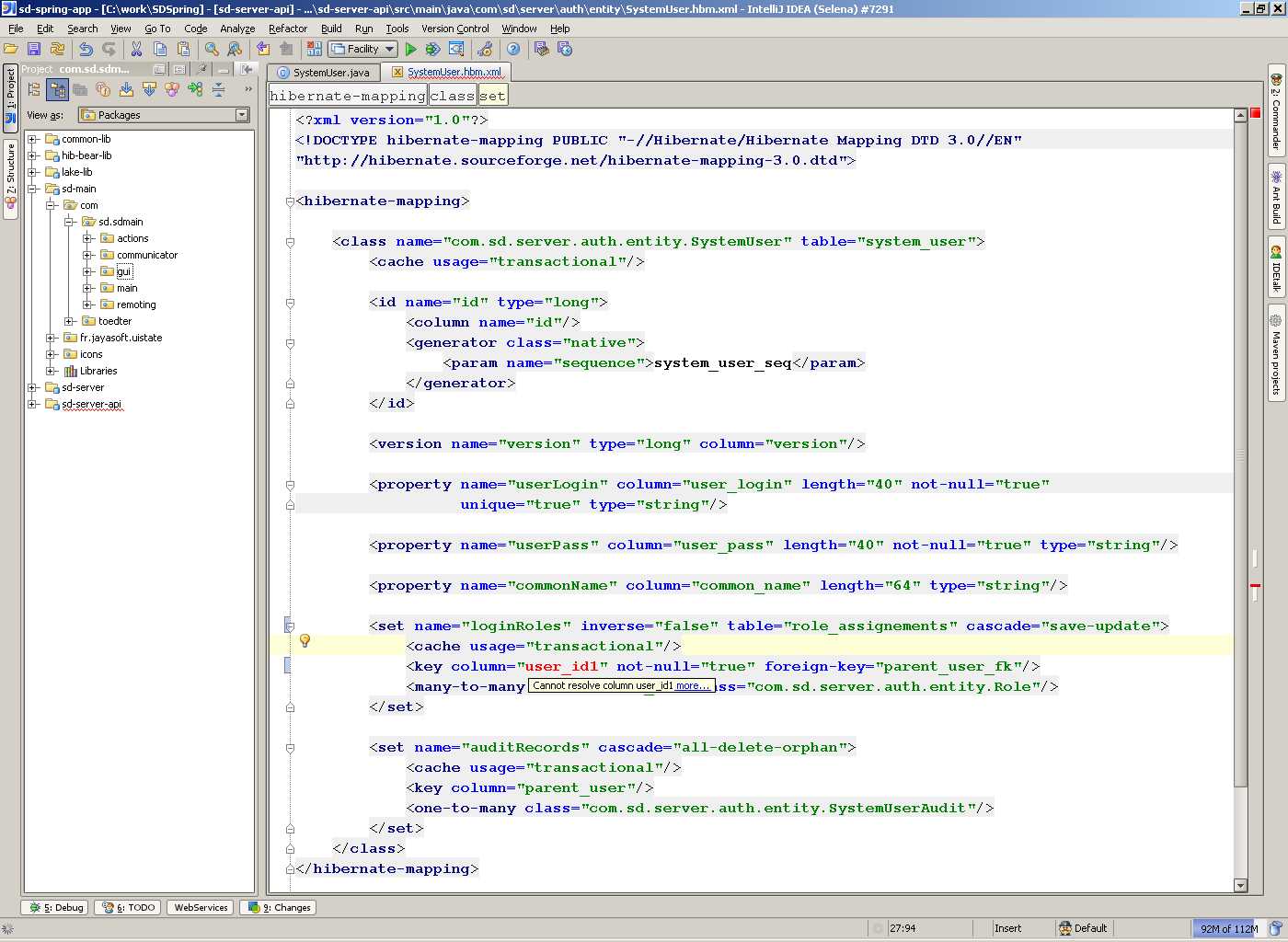
А если у меня в mapping'е будет ошибка, то получится примерно так:
Т.е. IDE автоматически сравнивает mapping с реальной схемой и находит ошибки.
C>>Так если тормозит — втыкаем вместо HQL-запроса оптимизированый SQL. Какие проблемы-то? Hibernate позволяет замечательно использовать нативный SQL. Только вот нужно это всего в процентах случаев. A>ХЗ, у нас этот процент оказался настолько большой, что HQL был отвергнут совсем. Может быть есть задачи на которых Hibernate генерирует что-то вменяемое, я больше сталкивался с другими задачами.
Hibernate генерирует абсолютно очевидный SQL. Что там такое у вас было??
Sapienti sat!
Re[15]: Оформление работы с БД в корпоративных приложениях -
Здравствуйте, adontz, Вы писали:
A>Здравствуйте, kuj, Вы писали:
kuj>>Кстати говоря, SQL это ни разу не декларативный язык.
A>Сильно. Я это сообщение добавлю в favorites в раздел Юмор, можно?
Для начала почитайте в гугле что такое T-SQL. А то создаётся ощущение, что Вы защищаете то, о чём у Вас практически нет представления.
Re[15]: Оформление работы с БД в корпоративных приложениях -
Здравствуйте, adontz, Вы писали:
A>>>Видишь ли, Hibernate как правило наботает в tier бизнесс-логики. У этого подхода есть преимущества в администрировании. Так что чего т так удивился я не особо понял. A>>Сам то понял что написал? A>ОМГ. У тебя есть две машины, на одной всё что на java, на воторой SQL-сервер. Это достаточно стандартная схема.
У меня вот два сервера БД (кластер с failover) и 3 app-сервера в качестве front-end'ов. Все прекрасно работает с Hibernate.
Sapienti sat!
Re[12]: Оформление работы с БД в корпоративных приложениях -
Здравствуйте, adontz, Вы писали:
A>Здравствуйте, AndrewJD, Вы писали:
kuj>>>ХП vs запросы? О чем Вы? AJD>>Хм. А о чем ветка? Разве не о преимуществах/недостатках использования ХП?
A>Нет, ветка у нас получалась Object-Relational Mappers против Хранимых Процедур. A>Скоро kuj поднимет ветку C# против Алгоритмов.
Видите ли, Ваша позиция напоминает программистов, которые в стародавние временна утверждали, что реальтный пацаны пишут на асме, где полный контроль машины, С для недоделанных. Дальше были дискуссии, что у Java/.NET нет будущего, на них приложения всегда будут проигрывать в эффективности С++... Время расставило всё на свои места.