Здравствуйте, kov_serg, Вы писали:
IT>>У нас более 5 террабайт реляционных данных. Потому-что мы собираем много данных по банку и генерируем обобщённые, по которым делаем свои расчёты. Выносить в другие базы ничего не нужно. Нужно использовать партиционирование. _>Как обеспечиваете целостность данных на таких объёмах?
Используем СУБД.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, кубик, Вы писали:
К>Кто работает с базами больше 2х террабайт, расскажите почему ваша база такая большая. Можно ли сделать ее поменьше за счет переноса части необновляемых данных по базам. К>Например по годам рассортировать....
У нас более 5 террабайт реляционных данных. Потому-что мы собираем много данных по банку и генерируем обобщённые, по которым делаем свои расчёты. Выносить в другие базы ничего не нужно. Нужно использовать партиционирование.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, MadHuman, Вы писали:
IT>>Выносить в другие базы ничего не нужно. Нужно использовать партиционирование. MH>дак партицирование это по сути вынос части данных в другую таблицу.
Это вынос части данных в отдельную файлгруппу, но не обязательно.
MH>вообще интересно, а есть ли смысл в партицировании? партицирование имеет смысл когда есть поле например — дата операции
Совершенно верно. Не все таблицы можно эффективно партиционировать. Для этого нужно соблюсти одно условие. У тебя должна быть колонка (можно вычисляемая), которую ты используешь абсолютно во всех запросах в качестве фильтра. Если такое условие не выполняется, то партиционирование не имеет смысла.
MH>и записи за разные например года в разных таблицах. но зачем? если в условии отбора будет указан диапазон дат по этому полю, то при наличии индекса (особенно кластерного) выборка записей попадающих в этот диапазон итак будет быстро. зачем партцирование?
При наличии у тебя в таблице ну скажем пары-тройки сотен миллионов записей деградация производительности при массовой вставке/удалении данных становится заметной, а при приближении к полумиллиардам может убить твоё приложение совсем. Да и при селектах одно дело сканировать 10 миллиардов записей, другое — 10 миллионов. Даже по ключу.
К этому можно добавить ещё следующие возможности:
— ребилд идексов и статистики для отдельно взятой партиции.
— компрессия отдельных партиций.
— хранение отдельных партиций на разных носителях, например, более свежих данных на SSD, старых и не очень используемых на HDD (и ещё можно их поджать)
— truncate отдельных партиций.
— partition switching — мгновенный перенос данных из одной таблицы в другую.
У нас деградация производительности началась примерно к тремстам миллионам записей в основных таблицах. Добавили портиционирование. Сейчас в одной таблице у нас как раз те самые 10 миллиардов и никакой деградации не наблюдается. Всего у нас сейчас порядка 750 партиций. Т.е. физически эти 10 BN разбиты на 750 частей, в каждой по 10-15 M записей, что делает работу с ними вполне адекватной.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, кубик, Вы писали:
К>Кто работает с базами больше 2х террабайт, расскажите почему ваша база такая большая. Можно ли сделать ее поменьше за счет переноса части необновляемых данных по базам. К>Например по годам рассортировать....
Честно, лично — не работаю. Но наблюдал коллег. Базы у них такие большие, просто потому что так можно. Ну т.е. в одну базу совать всё, что не попадя, любым образом, лишь бы было удобно программировать поверх этого. И поскольку по рукам никто не бьет, железо дают, то какими-то переносами, сортировками или даже партицированием тупо не заморачиваются... Пользователь подождёт.
IT>У меня складывается такое впечатление, что ты пытаешься натянуть МОИ решения на ТВОЮ задачу, у тебя это не получается и я в этом очень сильно виноват. Я прав?
нет, не прав. ты сейчас злишься, прекрасно понимая, что задачи хранилища у всех одинаковые и я лучше твоего знаю что и как ты сделал и почему тебе пришлось приседать с partition switch и с контролем целостности. и дело не только в partition switch, в разные таблицы данные ты льешь в рамках несвязанных транзакций, ломая всю концепцию прослойки вокруг транзакции и read consistency.
IT>Мадам, мы в течении дня генерируем около 250M записей, всё это зиливаем в базу без особых тормозов, сложностей масштабирования и отдельных ETL инструментов. Что мы делаем не так?
не так то, что ты не убрал причину тормозов, а лишь отключил у прокладки некоторые из систем контроля. отключение FK и partition switch лишь отодвинули момент, когда задача не поместиться в одну машину.
IT>Вывод — помоечки в банке приживаются.
скорее что товарищи посмеялись над тобой. закон о защите данных не позволяет банку свалить что-то в сыром виде на потом.
IT>Так я ожидал вменяемую альтернативу, а не это.
майкрософт не та компания, какой интересно твое мнение. важно что майкрософт это считает альтернативой и hadoop+spark уже в mssql2019
Здравствуйте, rm822, Вы писали:
R>память бьется. типично в одном диме 1 ошибка в мес
У тебя статистика не правильная
Какой техпроцесс, какая частота, какой объем, какой производитель и т.д.....
Плюс учитывай, что есть разница между сбоем в банке памяти и кучей систематических ошибок, к которым он привёл и случайной ошибкой (последние, как считается, случаются реже).
R>если димм с ECC, то большинство будет восстановлено, будет ~1 невосстановимая ошибка в год. а в серваке у нас их пусть 48 R>и опаньки — уже 4 невосстановимые ошибки в мес
Есть предел восстановления, а есть предел обнаружения. Однобитные ошибки исправляются, многобитные (до определенного предела) — обнаруживаются и сервер вываливается в синий экран.
Если идти твоими расчетами, то будет не "~1 невосстановимая ошибка в год/4 невосстановимые ошибки в мес", а BSOD из-за неккоректируемой ошибки памяти.
R>понятно что в основном оперативка используется как кэш, и должны сойтись звезды чтобы битая страница кэша была модифицирована и отправлена на запись, но серваки не перегружают по много месяцев.
Да нет, просто ECC это маленький кусочек. Есть штуки вроде SDDC / Online Spare / Mirror Memory / Fast Fault Tolerance / Memory scrubbing — и куча всего остального. От банального зеркалирования половины памяти во вторую половину — когда для сбоя неккоректируемый ECC сбой должен возникнуть одновременно в одних и тех же ячейках разных модулей, до хитрых мапингов адресов когда bios/os маркирует область памяти как lockstep и не используют из-за потенциальной возможности возникновения ошибок.
R>Серьезные производители ловят событие от железа, и перечитывают битую страницу.
Это далеко не всегда возможно и сложно писать ПО которое адекватно работает с такими событиями, поэтому обычно стараются не доводить.
R>Короче это реально происходит, пару раз натыкался.
ИМХО в реальном Enterprise, на хорошем и корректно настроенном железе вероятность стремится к нулю. Но есть, 100% защита отсутствует, всё мирятся с ничтожной вероятностью столкнутся вживую.
А относительно твоего вопроса, не побить ли по базам — это на надежность в общем-то не повлияет, скорей наоборот увеличит шансы получить такую ошибку.
Здравствуйте, rm822, Вы писали:
S>>Ну выше написали, что в случае чего BSOD или kernel panic (?), а не битые данные пользователя. R>хрена с два там какой-то бсод происходит, в логе появляется событие о hard memory error и все продолжает работать как будто и не было ничего....
Вот казалось бы гугл с нами, "hard memory error" третий ссылкой выдаёт https://support.hpe.com/hpesc/public/docDisplay?docId=c03111253
Где расписано, что soft и hard memory error — это корректируемые ошибки и в чём между ними разница.
R>ах ну да, на серваке может загориться светодиод, ...если есть.... вот только когда еще на него кто посмотрит. а если посмотрит, то неизвестно что будет делать. R>может просто сбросит алерт и всё. сервак-то в аренду сдан или выкуплен. на кой хрен какой-то гемор себе пока клиент не жалуется....
Потому что hard memory error — это скорректированные ошибки, но их много и bios предупреждает, что модуль памяти желательно заменить, пока не начали возникать некорректируемые сбои и остановка системы.
R>а в серваках подешевле вообще ничего не появляется. и гадай как хочешь
Ну не знаю, что уж там за сервера подешевле, но некорректируемые ошибки памяти приводят к остановке системы даже для Supermicro и всё там с ECC памятью нормально.
PS. У меня есть лично возникает впечатление, что в силу недостатка знаний/опыта штатные ситуации, в которых ECC память защитила от сбоев трактуются как фейлы этой технологии. И порождают охоту на ведьм.
Ошибки возможны. Они могут быть не только в памяти, но и при передаче данных, и в процессоре и на HDD/SSD и т.д. Нет сквозной защиты, которая гарантировала бы на всех этапах 100% целостность данных. Кроме ECC есть куча мест где теми или иными способами идёт проверки на целостность — совокупно они не дают эти самые 100%, но вероятность при правильно эксплуатируемом серверном железе столкнутся с такими ошибками пренебрежительно мала.
Здравствуйте, Gt_, Вы писали:
IT>>И субд и алгоритмы. Там где можно воспользоваться возможностями субд мы от этого вовсе не отказываемся. Зачем изобретать велосипеды? Gt_>что бы не получить минусы из обоих миров.
Из каких "обоих" миров? Почему не всех трёх или сразу пятнадцати? Что за миры такие?
Gt_>вы отключили констреинты, отказались от транзакций в пользу exchange partition,
Не от транзакций, а от check constraint. Не отказались, а локально применили другое решение. Не в пользу exchange partition, а в пользу partition switching.
Gt_>у клиента подозреваю и консистентно вычитать уже и не выйдет.
Что, простите?
Gt_>но при этом вы остались с тяжелой прослойкой субд, которая слабо работает в параллель и зажаты в структарх хранения субд. ну и главное — цена. это же все EE лицензии жрет.
Мне сложно коментировать этот набор домыслов, т.к. по всей видимости он относится к твоей конкретной ситуации и требует расшифровки контекста именно твоей ситуации. Лично у меня никакой тяжести субд нет, слабых параллелей не замечено, и главное — цена не имеет значения.
IT>>По-твоему, субд — это только целостность и транзакционность? Gt_>ну да. ну еще может консистентная выборка.
Это какой-то новый термин "консистентная выборка"? Набрал в гугле — субд "консистентная выборка", получил — No results found for субд "консистентная выборка".
IT>>И какие альтернативы? Gt_>файлики, бигдата.
Понятно. Ты мне предлагаешь нереляционную файло/бигдата помойку.
Gt_>в файлики parquet на hadoop кластер можно писать с гораздо большим уровнем параллелизма. там колончатая структура + упаковка. поверх этих файликов mpp engine, который файлики в виде почти реляционных табличек показывает, внешние потребители в основной массе и не поймут, что там файлики, а не субд.
Зачем мне всё это? Файлики, уяйлики, кластеры, уястеры. Что за чушь?
Gt_>вот только колхозить и костылись заметно больше приходится, но если речь об альтернативе — она есть. у нас вот хранилище на оракле заменено.
Т.е. альтернатива — колхозить и костылить
Если нам не помогут, то мы тоже никого не пощадим.
S>А какая связь между объемом данных и отказаустойчивостью железа? Что там может не так сработать в отличие от small dat'ы? Можно подробнее про неожиданные изменения?
память бьется. типично в одном диме 1 ошибка в мес
если димм с ECC, то большинство будет восстановлено, будет ~1 невосстановимая ошибка в год. а в серваке у нас их пусть 48
и опаньки — уже 4 невосстановимые ошибки в мес
понятно что в основном оперативка используется как кэш, и должны сойтись звезды чтобы битая страница кэша была модифицирована и отправлена на запись, но серваки не перегружают по много месяцев.
Серьезные производители ловят событие от железа, и перечитывают битую страницу.
Короче это реально происходит, пару раз натыкался.
Здравствуйте, kov_serg, Вы писали:
IT>>У нас более 5 террабайт реляционных данных. Потому-что мы собираем много данных по банку и генерируем обобщённые, по которым делаем свои расчёты. Выносить в другие базы ничего не нужно. Нужно использовать партиционирование. _>Как обеспечиваете целостность данных на таких объёмах?
А в чем проблема? Если речь про реляционные БД и целостность ссылок, то поиск в таблице по индексу среди миллиона записей и среди миллиарда, будет почти не отличаться по времени и ресурсам. А без индекса будут проблемы уже на ста тысячах.
S>А можно чуть подробнее про невосстановимость при ECC и прочих избыточных кодах?
гугл когда-то проводил масштабное исследование https://www.zdnet.com/article/dram-error-rates-nightmare-on-dimm-street/
S>Ну типа того, и в чем тогда проблема, если все это решается на уровне железа? Как можно битые данные получить?
может решается а может и нет.
сейчас уже большинство арендует железки в дата центрах, лично я не верю в их надежность, судя по демпинговым ценам....
Gt_>>файлики, бигдата. в файлики parquet на hadoop кластер можно писать с гораздо большим уровнем параллелизма. там колончатая структура + упаковка. поверх этих файликов mpp engine, который файлики в виде почти реляционных табличек показывает, внешние потребители в основной массе и не поймут, что там файлики, а не субд.
P>А чем пользователи эти почти таблички смотрят? (к тому, что пользователям сами по себе таблички не нужны, им нужны отфильтрованные по разным условиям данные из разных табличек, сиречь joints)
поверх этих файликов mpp engine. у нас предпочитают cloudera impala, которая тяготеет к inmemory. там вполне навороченый SQL, понятно что с JOIN, с CTE, аналитическими запросами типа over() partition by, LEAD() и т.п.
еще популярен hive и spark sql. майкрософт как я понял spark sql сейчас любит, hadoop+spark недавно запихнули в mssql2019
Здравствуйте, paucity, Вы писали:
P>А в местах где FKs "выключены", как целостность обеспечивается?
Алгоритмами. Например, в случае падения многоступенчатого процесса, перед его перезапуском выполняется проверка на наличие и удаление недоданных. Где можно используются staging таблицы и т.п.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, кубик, Вы писали:
К>Привет друзья.
К>Кто работает с базами больше 2х террабайт, расскажите почему ваша база такая большая.
до двух терабайт дело не дошло. было два редизайна когда они (баз много) начали к терабайту подбираться.
в обоих случаях по разным причинам
в одном случае произошел переход на колумнстор, а во втором — выброс части неизменяемых и редко используемых данных в облако
без редизайнов наверное терабайт 5 было бы, а так в пределах 200-300ГБ
Потому что в ней лежит много данных.
К>Можно ли сделать ее поменьше за счет переноса части необновляемых данных по базам
Можно.
К>Например по годам рассортировать
Мы и сортируем "по годам". Только без разнесения данных по разным базам, а внутри одной базы с использованием упомянутого выше партиционирования.
Но, несмотря на это, в безусловной и всепокрывающей верности утверждения "выносить в другие базы ничего не нужно" я не уверен.
"Больше 100кмч можно ехать на автобане в любом ряду кроме правого крайнего" (c) pik
"В германии земля в частной собственности" (c) pik
"Закрывать школы, при нулевой смертности среди детей и подростков, это верх глупости" (c) Abalak
Здравствуйте, fmiracle, Вы писали:
F>А в чем проблема? Если речь про реляционные БД и целостность ссылок, то поиск в таблице по индексу среди миллиона записей и среди миллиарда, будет почти не отличаться по времени и ресурсам. А без индекса будут проблемы уже на ста тысячах.
Я про сбои в самих данных даже если они иногда переезжают в озу и обратно можно словить не ожиданные изменения. Т.к. надёжность оборудования всё же конечная и на больших объёмах вероятность получить битые данные гораздо выше несмотря на все контрольные суммы, коды Рида-Соломона и регулярные бэкапы. Или целиком доверяем субд и волевым решением приравниваем вероятность ошибок к 0.
Здравствуйте, Gt_, Вы писали:
Gt_>угу. т.е. на проверку целостность вовсе не субд обеспечивает, а алгоритмы.
И субд и алгоритмы. Там где можно воспользоваться возможностями субд мы от этого вовсе не отказываемся. Зачем изобретать велосипеды? Отказ от транзакций происходит только, если это не возможно в принципе. Например, если данные генерируются разными процессами в разное время. Снятие флага CHECK CONSTRAINT с FK делается в основном из соображений производительности. Например, partition switching позволяет переносить данные из одной таблицы в другую в одно мгновение. В то время как обычный INSERT INTO и DELETE занимает в общей сложности минут 40. Стоит такая экономия усложнения обеспечения целостности, если учесть, что это только один из способов сэкономить?
Gt_>обычно дальше идет вопрос, а правильно ли тогда использовать субд, если с определенных объемов уже ни целостность ни транзакционность не применить.
По-твоему, субд — это только целостность и транзакционность? И какие альтернативы?
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
Gt_>>угу. т.е. на проверку целостность вовсе не субд обеспечивает, а алгоритмы.
IT>И субд и алгоритмы. Там где можно воспользоваться возможностями субд мы от этого вовсе не отказываемся. Зачем изобретать велосипеды?
что бы не получить минусы из обоих миров. вы отключили констреинты, отказались от транзакций в пользу exchange partition, у клиента подозреваю и консистентно вычитать уже и не выйдет. но при этом вы остались с тяжелой прослойкой субд, которая слабо работает в параллель и зажаты в структарх хранения субд. ну и главное — цена. это же все EE лицензии жрет.
IT>По-твоему, субд — это только целостность и транзакционность?
ну да. ну еще может консистентная выборка.
IT>И какие альтернативы?
файлики, бигдата. в файлики parquet на hadoop кластер можно писать с гораздо большим уровнем параллелизма. там колончатая структура + упаковка. поверх этих файликов mpp engine, который файлики в виде почти реляционных табличек показывает, внешние потребители в основной массе и не поймут, что там файлики, а не субд.
вот только колхозить и костылись заметно больше приходится, но если речь об альтернативе — она есть. у нас вот хранилище на оракле заменено.
Здравствуйте, Gt_, Вы писали:
IT>>У меня складывается такое впечатление, что ты пытаешься натянуть МОИ решения на ТВОЮ задачу, у тебя это не получается и я в этом очень сильно виноват. Я прав? Gt_>нет, не прав. ты сейчас злишься, прекрасно понимая, что задачи хранилища у всех одинаковые и я лучше твоего знаю что и как ты сделал и почему тебе пришлось приседать с partition switch и с контролем целостности. и дело не только в partition switch, в разные таблицы данные ты льешь в рамках несвязанных транзакций, ломая всю концепцию прослойки вокруг транзакции и read consistency.
Мадам, вы не перестаёте удивлять меня своей оригинальной женской логикой. Вы только вдумайтесь в это — "концепцию прослойки вокруг транзакции". Может тогда уж прокладки?
IT>>Мадам, мы в течении дня генерируем около 250M записей, всё это зиливаем в базу без особых тормозов, сложностей масштабирования и отдельных ETL инструментов. Что мы делаем не так? Gt_>не так то, что ты не убрал причину тормозов, а лишь отключил у прокладки некоторые из систем контроля. отключение FK и partition switch лишь отодвинули момент, когда задача не поместиться в одну машину.
Вот и прокладки
Задача уже поместилась куда надо, не переживай так за нас. У нас всё хорошо, просто замечательно. Твои предсказания уже года 4 как опровергаются каждый день.
Тебе нужно научится не натягивать весь окружающий мир на свою конкретную задачку. Если у тебя у самого когда-то что-то с чем-то не получилось, то не стоит всех подряд считать такими же неудачниками, особенно, если у них с тем же самым всё хорошо
IT>>Вывод — помоечки в банке приживаются. Gt_>скорее что товарищи посмеялись над тобой. закон о защите данных не позволяет банку свалить что-то в сыром виде на потом.
Ты ещё и лоер? Ты думаешь они прямо целыми днями сидят и обрабатывают сырое видео с камер или сортируют e-mail пары сотен тысяч сотрудников?
IT>>Так я ожидал вменяемую альтернативу, а не это. Gt_>майкрософт не та компания, какой интересно твое мнение. важно что майкрософт это считает альтернативой и hadoop+spark уже в mssql2019
Подожди ка, а как же файлики? Ты же только что предлагал вместо майкрософтского легаси поколхозить и покостылить, а тут вдруг такое
Если нам не помогут, то мы тоже никого не пощадим.
Кто работает с базами больше 2х террабайт, расскажите почему ваша база такая большая. Можно ли сделать ее поменьше за счет переноса части необновляемых данных по базам.
Например по годам рассортировать....
Здравствуйте, Аноним931, Вы писали:
А>Но, несмотря на это, в безусловной и всепокрывающей верности утверждения "выносить в другие базы ничего не нужно" я не уверен.
Так это и не безусловно. Все зависит от бизнес- и "техно"- процессов и требований.
Здравствуйте, IT, Вы писали:
IT>У нас более 5 террабайт реляционных данных. Потому-что мы собираем много данных по банку и генерируем обобщённые, по которым делаем свои расчёты. Выносить в другие базы ничего не нужно. Нужно использовать партиционирование.
Как обеспечиваете целостность данных на таких объёмах?
Здравствуйте, IT, Вы писали:
IT>Выносить в другие базы ничего не нужно. Нужно использовать партиционирование.
дак партицирование это по сути вынос части данных в другую таблицу.
вообще интересно, а есть ли смысл в партицировании? партицирование имеет смысл когда есть поле например — дата операции
и записи за разные например года в разных таблицах. но зачем? если в условии отбора будет указан диапазон дат по этому полю, то при наличии индекса (особенно кластерного)
выборка записей попадающих в этот диапазон итак будет быстро. зачем партцирование?
Здравствуйте, kov_serg, Вы писали:
_>Я про сбои в самих данных даже если они иногда переезжают в озу и обратно можно словить не ожиданные изменения. Т.к. надёжность оборудования всё же конечная и на больших объёмах вероятность получить битые данные гораздо выше несмотря на все контрольные суммы, коды Рида-Соломона и регулярные бэкапы.
А какая связь между объемом данных и отказаустойчивостью железа? Что там может не так сработать в отличие от small dat'ы? Можно подробнее про неожиданные изменения?
IT>При наличии у тебя в таблице ну скажем пары-тройки сотен миллионов записей деградация производительности при массовой вставке/удалении данных становится заметной, а при приближении к полумиллиардам может убить твоё приложение совсем.
вот это странно, если добавляются скажем так последние операции (допусти разбиение по дате операции) и дата операции кластерный индекс, то данные фактически будут вставляться
в конец, какая разница сколько их там в начале? то есть в моем понимании по сути это всё равно что дописывать в конец большого файла, это не зависит от того сколько в нем данных.
допустим даже не в конец (вставка в середину периода), то за счет страничной организации данных, где-то будет сплит и указатель на новые вставляемые данные, которые фактически будут дописываться в конец файла.
также замедляет производительность перестройка индексов. тут важно их кол-во. но насколько я понимаю, значительно меньшую роль играет его размер, тк опять же при вставке в индекс
будет модифицироваться какой-то его локальный кусок и неважен полный его размер.
IT>Да и при селектах одно дело сканировать 10 миллиардов записей, другое — 10 миллионов. Даже по ключу.
дак в том то и дело, что из-за колонки "которую ты используешь абсолютно во всех запросах в качестве фильтра" сканиться будет вполне конкретный кусок
и одинаковый в обоих случаях. то есть за счет индекса мы выйдем на начало участка записей и далее линейно (если ключ кластерный) сканим. что это партиция что часть большой таблицы разницы не должно быть.
IT>К этому можно добавить ещё следующие возможности: IT>- ребилд идексов и статистики для отдельно взятой партиции. IT>- компрессия отдельных партиций. IT>- хранение отдельных партиций на разных носителях, например, более свежих данных на SSD, старых и не очень используемых на HDD (и ещё можно их поджать) IT>- truncate отдельных партиций. IT>- partition switching — мгновенный перенос данных из одной таблицы в другую.
это да.
IT>У нас деградация производительности началась примерно к тремстам миллионам записей в основных таблицах.
непонятна природа деградации, если всегда использовать фильтр по ключу.
Здравствуйте, MadHuman, Вы писали:
MH>вот это странно, если добавляются скажем так последние операции (допусти разбиение по дате операции) и дата операции кластерный индекс, то данные фактически будут вставляться
В этом индексе не одно поле. И, кстати, в случае партиционирования, эту ключ-солонку можно из индекса убрать.
MH>в конец, какая разница сколько их там в начале? то есть в моем понимании по сути это всё равно что дописывать в конец большого файла, это не зависит от того сколько в нем данных. MH>допустим даже не в конец (вставка в середину периода), то за счет страничной организации данных, где-то будет сплит и указатель на новые вставляемые данные, которые фактически будут дописываться в конец файла.
Видимо даже в этом случае ковыряться в 10 M записях проще, чем в 10 BN.
MH>также замедляет производительность перестройка индексов. тут важно их кол-во. но насколько я понимаю, значительно меньшую роль играет его размер, тк опять же при вставке в индекс MH>будет модифицироваться какой-то его локальный кусок и неважен полный его размер.
Вообще-то индекс в процессе должен балансироваться и когда-нибудь придётся перебалансировать все 10 BN записей.
IT>>Да и при селектах одно дело сканировать 10 миллиардов записей, другое — 10 миллионов. Даже по ключу. MH>дак в том то и дело, что из-за колонки "которую ты используешь абсолютно во всех запросах в качестве фильтра" сканиться будет вполне конкретный кусок
Это только в теории. Если у тебя запрос простой и оптимизатор решил всё правильно. У нас частой ошибкой разрабов бало написание такого SQL:
select *
from partitioned_table1 t1
join partitioned_table1 t2 on t.key_column = t2.key_column
where t1.key_column = 10
Казалось бы у оптимизатора есть вся информация и он для t2 может легко вычислить значение ключ-колонки. Но нет. Не всегда. Не на всех версиях сервера. При потере статистики и т.д. Добавление условия по t2 в явную всегда решало проблему. Если здесь вообще убрать партиционирование, то в сложных запросах пути оптимизатора окажутся совсем неисповедимы.
MH>и одинаковый в обоих случаях. то есть за счет индекса мы выйдем на начало участка записей и далее линейно (если ключ кластерный) сканим. что это партиция что часть большой таблицы разницы не должно быть.
Как это нет? Просканить 10 миллиардов записей вообще-то не очень хорошая затея.
IT>>У нас деградация производительности началась примерно к тремстам миллионам записей в основных таблицах. MH>непонятна природа деградации, если всегда использовать фильтр по ключу.
Думаю там у них под партиционирование много чего заточено внутри. Особенно последние версии SQL сервера ведут себя ну очень грамотно. Мой пример на последней версии всегда работает корректно, я его пока не смог сломать. Поэтому скорее всего если таблица партиционированная и есть ключ-колонка в фильтре, то решения принимаются ещё на ранних стадиях, а учитывая, что даже статистика на партиции отдельная на каждую, то запрос можно построить гораздо эффективнее, чем на всю таблицу целиком.
Если нам не помогут, то мы тоже никого не пощадим.
S>>А какая связь между объемом данных и отказаустойчивостью железа? Что там может не так сработать в отличие от small dat'ы? Можно подробнее про неожиданные изменения? R>память бьется. типично в одном диме 1 ошибка в мес R>если димм с ECC, то большинство будет восстановлено, будет ~1 невосстановимая ошибка в год. а в серваке у нас их пусть 48 R>и опаньки — уже 4 невосстановимые ошибки в мес
А можно чуть подробнее про невосстановимость при ECC и прочих избыточных кодах?
R>понятно что в основном оперативка используется как кэш, и должны сойтись звезды чтобы битая страница кэша была модифицирована и отправлена на запись, но серваки не перегружают по много месяцев. R>Серьезные производители ловят событие от железа, и перечитывают битую страницу.
Ну типа того, и в чем тогда проблема, если все это решается на уровне железа? Как можно битые данные получить?
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, kov_serg, Вы писали:
IT>>>У нас более 5 террабайт реляционных данных. Потому-что мы собираем много данных по банку и генерируем обобщённые, по которым делаем свои расчёты. Выносить в другие базы ничего не нужно. Нужно использовать партиционирование. _>>Как обеспечиваете целостность данных на таких объёмах?
IT>Используем СУБД.
Здравствуйте, rm822, Вы писали:
S>>Ну типа того, и в чем тогда проблема, если все это решается на уровне железа? Как можно битые данные получить? R>может решается а может и нет.
Ну выше написали, что в случае чего BSOD или kernel panic (?), а не битые данные пользователя.
S>Ну выше написали, что в случае чего BSOD или kernel panic (?), а не битые данные пользователя.
хрена с два там какой-то бсод происходит, в логе появляется событие о hard memory error и все продолжает работать как будто и не было ничего....
ах ну да, на серваке может загориться светодиод, ...если есть.... вот только когда еще на него кто посмотрит. а если посмотрит, то неизвестно что будет делать.
может просто сбросит алерт и всё. сервак-то в аренду сдан или выкуплен. на кой хрен какой-то гемор себе пока клиент не жалуется....
а в серваках подешевле вообще ничего не появляется. и гадай как хочешь
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, кубик, Вы писали:
К>>Кто работает с базами больше 2х террабайт, расскажите почему ваша база такая большая. Можно ли сделать ее поменьше за счет переноса части необновляемых данных по базам. К>>Например по годам рассортировать....
IT>У нас более 5 террабайт реляционных данных. Потому-что мы собираем много данных по банку и генерируем обобщённые, по которым делаем свои расчёты. Выносить в другие базы ничего не нужно. Нужно использовать партиционирование.
А если не секрет, какая база (MS SQL, Oracle, Postgres, mysql), какое железо?
Здравствуйте, Lonely Dog, Вы писали:
IT>>У нас более 5 террабайт реляционных данных. Потому-что мы собираем много данных по банку и генерируем обобщённые, по которым делаем свои расчёты. Выносить в другие базы ничего не нужно. Нужно использовать партиционирование. LD>А если не секрет, какая база (MS SQL, Oracle, Postgres, mysql), какое железо?
MS SQL. Про железо подробностей не знаю. Знаю только, что оно большое и его много.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, paucity, Вы писали:
P>>А в местах где FKs "выключены", как целостность обеспечивается?
IT>Алгоритмами. Например, в случае падения многоступенчатого процесса, перед его перезапуском выполняется проверка на наличие и удаление недоданных. Где можно используются staging таблицы и т.п.
угу. т.е. на проверку целостность вовсе не субд обеспечивает, а алгоритмы.
обычно дальше идет вопрос, а правильно ли тогда использовать субд, если с определенных объемов уже ни целостность ни транзакционность не применить.
Здравствуйте, rm822, Вы писали:
R>если димм с ECC, то большинство будет восстановлено, будет ~1 невосстановимая ошибка в год. а в серваке у нас их пусть 48
Невосстановимая ошибка в нынешних Линуксах просто приведёт к извлечению страницы из памяти (если в кэше) или убийству процесса (если в памяти процесса).
В теории могут быть ошибки, которые не обнаруживаются ECC, но это уж очень редкое явление.
Gt_>>вы отключили констреинты, отказались от транзакций в пользу exchange partition, IT>Не от транзакций, а от check constraint. Не отказались, а локально применили другое решение. Не в пользу exchange partition, а в пользу partition switching.
partition switching = отказ от транзаций.
Gt_>>у клиента подозреваю и консистентно вычитать уже и не выйдет. IT>Что, простите?
гугли, что такое read consistency. блокировочный RC выдает неконсистентную кашу, а чтения на уровне транзакции RCSI partition switching завершает с ошибкой.
Gt_>>но при этом вы остались с тяжелой прослойкой субд, которая слабо работает в параллель и зажаты в структарх хранения субд. ну и главное — цена. это же все EE лицензии жрет. IT>Мне сложно коментировать этот набор домыслов, т.к. по всей видимости он относится к твоей конкретной ситуации и требует расшифровки контекста именно твоей ситуации. Лично у меня никакой тяжести субд нет, слабых параллелей не замечено, и главное — цена не имеет значения.
у тебя тот самый мсскл, что не масштабируется толком даже в пределах одной машины, заливка в одну партицию практически не параллелится, я уж не говорю о том что по узлам кластера вообще никак не масштабируется. из-за тормозов и сложностей масштабирования прослойки тяжелые заливки принято отдельными ETL инструментами делать.
IT>Это какой-то новый термин "консистентная выборка"? Набрал в гугле — субд "консистентная выборка", получил — No results found for субд "консистентная выборка".
термин из учебников: read consistency. подробней например тут statement/transaction level read consistency https://docs.microsoft.com/en-us/sql/relational-databases/sql-server-transaction-locking-and-row-versioning-guide?view=sql-server-ver15
IT>Понятно. Ты мне предлагаешь нереляционную файло/бигдата помойку.
помойки не приживаются в фин и банковских секторах.
IT>Зачем мне всё это? Файлики, уяйлики, кластеры, уястеры. Что за чушь?
не знаю зачем ты про альтернативу спросил.
IT>Т.е. альтернатива — колхозить и костылить
да. по мне так интересней майкрософтского легаси. да и по деньгам бигдата интересней.
Здравствуйте, Gt_, Вы писали:
Gt_>файлики, бигдата. в файлики parquet на hadoop кластер можно писать с гораздо большим уровнем параллелизма. там колончатая структура + упаковка. поверх этих файликов mpp engine, который файлики в виде почти реляционных табличек показывает, внешние потребители в основной массе и не поймут, что там файлики, а не субд.
А чем пользователи эти почти таблички смотрят? (к тому, что пользователям сами по себе таблички не нужны, им нужны отфильтрованные по разным условиям данные из разных табличек, сиречь joints)
Здравствуйте, Gt_, Вы писали:
Gt_>partition switching = отказ от транзаций.
Видимо ты думаешь, что у меня в системе две таблицы и моё приложение только и занимается тем, что тысячи раз в секунду переключает партиции между ними и одновременно открывает и закрывает транзакции. Уверяю тебя, это не так. Поэтому, в моём случае partition switching != отказ от транзаций.
Gt_>гугли, что такое read consistency. блокировочный RC выдает неконсистентную кашу, а чтения на уровне транзакции RCSI partition switching завершает с ошибкой.
У меня складывается такое впечатление, что ты пытаешься натянуть МОИ решения на ТВОЮ задачу, у тебя это не получается и я в этом очень сильно виноват. Я прав? В принципе, я такую логику часто встречаю, но у женщин. Ты — женщина?
Gt_>у тебя тот самый мсскл, что не масштабируется толком даже в пределах одной машины, заливка в одну партицию практически не параллелится, я уж не говорю о том что по узлам кластера вообще никак не масштабируется. из-за тормозов и сложностей масштабирования прослойки тяжелые заливки принято отдельными ETL инструментами делать.
Мадам, мы в течении дня генерируем около 250M записей, всё это зиливаем в базу без особых тормозов, сложностей масштабирования и отдельных ETL инструментов. Что мы делаем не так?
Gt_>термин из учебников: read consistency. подробней например тут statement/transaction level read consistency
Трудности перевода. Понимаю. Это переводится как 'согласованность чтения'.
IT>>Понятно. Ты мне предлагаешь нереляционную файло/бигдата помойку. Gt_>помойки не приживаются в фин и банковских секторах.
Ну почему же. Была у меня одна такая команда. У них данных было петабайты. Всё как тебе нравится — файлики, бигдаты. Сваливают туда всё без разбора, что касается legal. Вообще всё. На вопрос "парни, а как вы в этом ищите, если вам пришёл запрос?", ответ примерно "ну, за недельку-две найдём что-нибудь в нашей помоечке".
Т.е. на вопрос "это помойка?" ответ утвердительный.
На вопрос "это банк?" ответ тоже утвердительный.
"Всё это работает?" — "Вполне".
Вывод — помоечки в банке приживаются.
IT>>Зачем мне всё это? Файлики, уяйлики, кластеры, уястеры. Что за чушь? Gt_>не знаю зачем ты про альтернативу спросил.
Так я ожидал вменяемую альтернативу, а не это.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Gt_, Вы писали:
Gt_>майкрософт не та компания, какой интересно твое мнение. важно что майкрософт это считает альтернативой и hadoop+spark уже в mssql2019
Только, наверное, не альтернативой, а совместным использованием с разных типов данных и задач.
Gt_>>майкрософт не та компания, какой интересно твое мнение. важно что майкрософт это считает альтернативой и hadoop+spark уже в mssql2019
P>Только, наверное, не альтернативой, а совместным использованием с разных типов данных и задач.
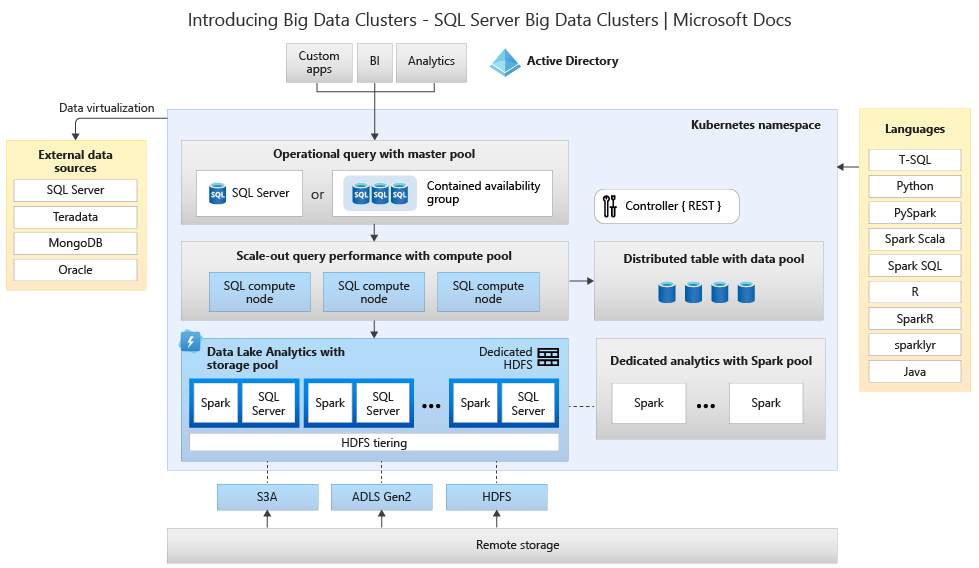
картинка классического hadoop кластера, а SQL server там явно такой же, как и любой другой сервис на hadoop кластере. интегрирован в hadoop mpp идеологию, тучи executors пишут на распределенную файловую систему hdfs/s3/adls.
Здравствуйте, Gt_, Вы писали:
IT>>Понятно. Ты мне предлагаешь нереляционную файло/бигдата помойку. Gt_>помойки не приживаются в фин и банковских секторах.
Да, именно поэтому прижился только kdb. А всякие хадупы — помойка.


 Если нам не помогут, то мы тоже никого не пощадим.
Если нам не помогут, то мы тоже никого не пощадим.