Пытаюсь разобраться в columnstore index, но пока во всех тестах они медленнее чем обычные (не смотря на то, что execution plan говорит об обратном).
Я создаю indexed view и на нём обычные и columnstore index (тесты провожу на большой 1с таблице, чтобы работать с большим объёмом данных).
CREATE VIEW dbo.test WITH SCHEMABINDING
AS
select d._IDRRef, d._Date_Time, v._LineNo2131, v._Fld2134, v._Fld2135 from dbo._Document191 d
JOIN dbo._Document191_VT2130 v on d._IDRRef = v._Document191_IDRRef
create unique clustered index test_pk on dbo.test(_IDRRef, _LineNo2131) WITH(MAXDOP=12)
create nonclustered index sales_date on dbo.test (_Date_Time, _LineNo2131) WITH(MAXDOP=12)
create nonclustered columnstore index sales_date2 on dbo.test (_Date_Time, _LineNo2131) WITH(MAXDOP=12)
И запускаю тесты:
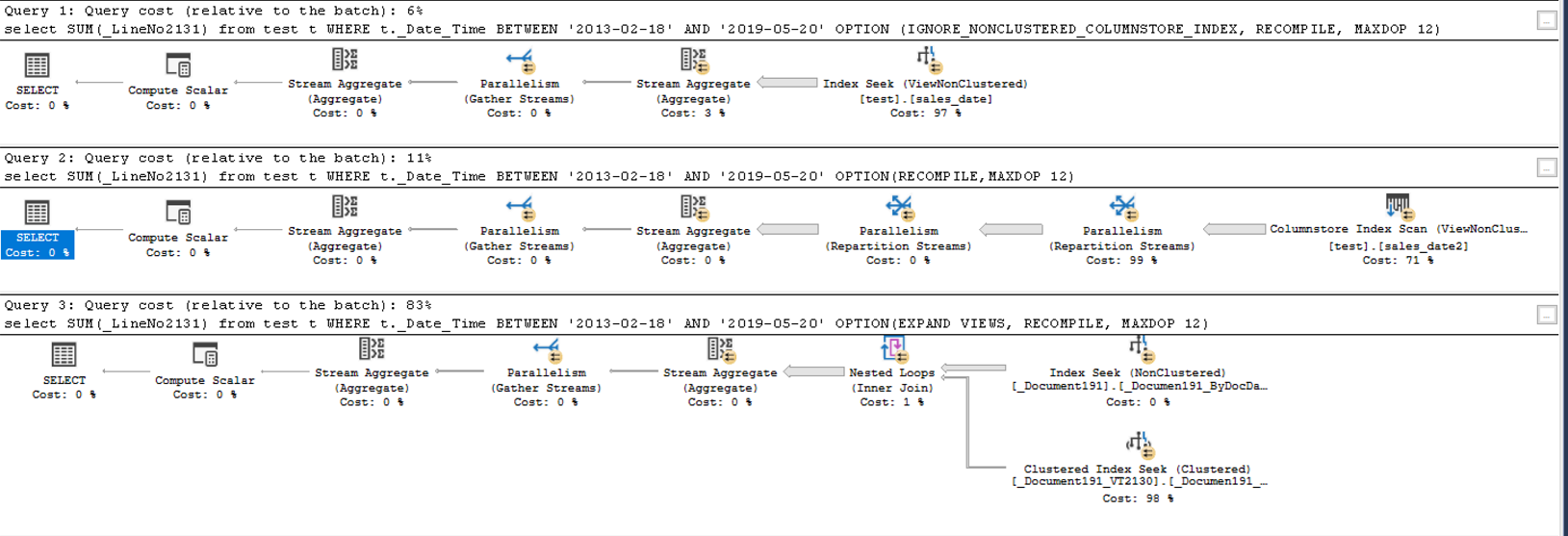
select SUM(_LineNo2131) from test t
WHERE t._Date_Time BETWEEN '2013-02-18' AND '2019-05-20'
OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX, RECOMPILE, MAXDOP 12)
select SUM(_LineNo2131) from test t
WHERE t._Date_Time BETWEEN '2013-02-18' AND '2019-05-20'
OPTION(RECOMPILE, MAXDOP 12)
select SUM(_LineNo2131) from test t
WHERE t._Date_Time BETWEEN '2013-02-18' AND '2019-05-20'
OPTION(EXPAND VIEWS, RECOMPILE, MAXDOP 12)
Первый, соответственно, берёт индекс test и выполняется порядка 5 сек, второй sales_date2 (23 сек) и третий не использует индексы вьюшки (12 сек). Вроде сам запрос как раз того плана, который предполагается ускорять columnstore, но эффект получается обратным. В принципе меня устраивает быстродействие первого индекса (особенно когда выяснил, что оптимизатор может подставлять его в обычный запрос, не использующий вьюшку. Более того — он может подставить даже агрегированный индекс, с суммированием по дням, выдавая 0.057с!), но просто интересно как правильно им пользоваться.
Планы (простите, захват с hidpi работает странно)
ЗЫ. SQL Sever 14.1000.169.
ARI ARI ARI... Arrivederci!
Re: [MSSQL] Columnstore index - как правильно использовать?
Здравствуйте, Somescout, Вы писали:
S>Пытаюсь разобраться в columnstore index, но пока во всех тестах они медленнее чем обычные (не смотря на то, что execution plan говорит об обратном).
execution plan в SSMS врёт при подсчёте времени. Не обращайте внимания
S>Я создаю indexed view и на нём обычные и columnstore index (тесты провожу на большой 1с таблице, чтобы работать с большим объёмом данных).
S>
S>CREATE VIEW dbo.test WITH SCHEMABINDING
S> AS
S> select d._IDRRef, d._Date_Time, v._LineNo2131, v._Fld2134, v._Fld2135 from dbo._Document191 d
S> JOIN dbo._Document191_VT2130 v on d._IDRRef = v._Document191_IDRRef
S>create unique clustered index test_pk on dbo.test(_IDRRef, _LineNo2131) WITH(MAXDOP=12)
S>create nonclustered index sales_date on dbo.test (_Date_Time, _LineNo2131) WITH(MAXDOP=12)
S>create nonclustered columnstore index sales_date2 on dbo.test (_Date_Time, _LineNo2131) WITH(MAXDOP=12)
S>
S>И запускаю тесты: S>
S>select SUM(_LineNo2131) from test t
S> WHERE t._Date_Time BETWEEN '2013-02-18' AND '2019-05-20'
S> OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX, RECOMPILE, MAXDOP 12)
S>select SUM(_LineNo2131) from test t
S> WHERE t._Date_Time BETWEEN '2013-02-18' AND '2019-05-20'
S> OPTION(RECOMPILE, MAXDOP 12)
S>select SUM(_LineNo2131) from test t
S> WHERE t._Date_Time BETWEEN '2013-02-18' AND '2019-05-20'
S> OPTION(EXPAND VIEWS, RECOMPILE, MAXDOP 12)
S>
S>Первый, соответственно, берёт индекс test и выполняется порядка 5 сек, второй sales_date2 (23 сек) и третий не использует индексы вьюшки (12 сек). Вроде сам запрос как раз того плана, который предполагается ускорять columnstore, но эффект получается обратным.
Зависит от данных и от того, что именно выбирается.
Рассматривайте columnstore index как просто отдельную таблицу из ключа и одной колонки.
Если у вас полное заполнение этой таблицы, и индекс не covered для запроса, и выбирается большая часть колонок таблицы, то ускорения и не будет.
А в вашем случае вообще идёт index scan, то есть, никакой с неко пользы и не получается.
S>В принципе меня устраивает быстродействие первого индекса (особенно когда выяснил, что оптимизатор может подставлять его в обычный запрос, не использующий вьюшку. Более того — он может подставить даже агрегированный индекс, с суммированием по дням, выдавая 0.057с!),
Учтите, что он это умеет в продакшне только в Enterprise версии
S>но просто интересно как правильно им пользоваться.
Columstore index — это вообще фишка для аналитики. Когда у вас в таблице несколько десятков-сотен колонок, заполненных большей частью nullами. А в выборке участвует только небольшая часть этихз колонок.
В таком сценарии columnstore indexes рулят по сравнению с поиском по широченным таблицам.
Re[2]: [MSSQL] Columnstore index - как правильно использовать?
Здравствуйте, vmpire, Вы писали:
V>Рассматривайте columnstore index как просто отдельную таблицу из ключа и одной колонки. V>Если у вас полное заполнение этой таблицы, и индекс не covered для запроса, и выбирается большая часть колонок таблицы, то ускорения и не будет. V>А в вашем случае вообще идёт index scan, то есть, никакой с неко пользы и не получается.
Так вроде columnstore как раз и оптимизирован на indexscan — при indexseek он вообще не используется?
S>>В принципе меня устраивает быстродействие первого индекса (особенно когда выяснил, что оптимизатор может подставлять его в обычный запрос, не использующий вьюшку. Более того — он может подставить даже агрегированный индекс, с суммированием по дням, выдавая 0.057с!), V>Учтите, что он это умеет в продакшне только в Enterprise версии
Её и используем.
V>Columstore index — это вообще фишка для аналитики. Когда у вас в таблице несколько десятков-сотен колонок, заполненных большей частью nullами. А в выборке участвует только небольшая часть этихз колонок. V>В таком сценарии columnstore indexes рулят по сравнению с поиском по широченным таблицам.
Ну вот я и пытаюсь понять как их правильно применять.
ARI ARI ARI... Arrivederci!
Re[3]: [MSSQL] Columnstore index - как правильно использовать?
Здравствуйте, Somescout, Вы писали:
V>>А в вашем случае вообще идёт index scan, то есть, никакой с неко пользы и не получается. S>Так вроде columnstore как раз и оптимизирован на indexscan — при indexseek он вообще не используется?
Да, при неполном заполнении columnstore index должен сканироваться быстрее. Но нужно же ещё данные выбрать после сканирования. На этом всё преимущество и теряется.
И уж точно это будет медленнее чем index seek.
Re[4]: [MSSQL] Columnstore index - как правильно использовать?
Здравствуйте, vmpire, Вы писали:
V>>>А в вашем случае вообще идёт index scan, то есть, никакой с неко пользы и не получается. S>>Так вроде columnstore как раз и оптимизирован на indexscan — при indexseek он вообще не используется? V>Да, при неполном заполнении columnstore index должен сканироваться быстрее. Но нужно же ещё данные выбрать после сканирования. На этом всё преимущество и теряется.
Так в запросе, по-идее, как раз идеальный вариант: суммирование по одному полю + индекс построенный по этому полю — в теории это должно быть быстрее, хотя-бы за счёт меньшего количества страниц для обработки. А на практике получается вот так.
И мне как раз интересно, что нужно сделать чтобы увидеть преимущество columnstore. Не зря же его вообще вводили.
V>И уж точно это будет медленнее чем index seek.
Почему?
ARI ARI ARI... Arrivederci!
Re[5]: [MSSQL] Columnstore index - как правильно использовать?
Здравствуйте, Somescout, Вы писали:
S>И мне как раз интересно, что нужно сделать чтобы увидеть преимущество columnstore. Не зря же его вообще вводили.
Сделайте таблицу с сотней колонок, в которых 90% NULL-ов и запрос, который выбирает из них только пару колонок по условию диапазона или точного равенства.
V>>И уж точно это будет медленнее чем index seek. S>Почему?
Потому, что scan — это полный перебор O(N), seek — поиск по деоеву, O(log(n))
Re: [MSSQL] Columnstore index - как правильно использовать?
S>ЗЫ. SQL Sever 14.1000.169.
rtm без патчей это реально очень-очень дурная идея с колумнсторами.
судя по repartition streams у тебя скан колумнстора работает в row-mode, и все последующие аггрегаты тоже
т.е. перекладывает данные из columnstore в rowstore — толку от этого, понятное дело, никакого вообще.
пока скан и агрегат не перейдут в батч режим — все будет тормозить
тебе для получения бенефита с колумнсторов и батч режима не нужен содержательный колумнстор индекс.
создай filtered nonclustered columnstore на какой-то из таблиц с условием, которое никогда не выполняется
create nonclustered columnstore index sales_date2 on dbo.dbo._Document191(_IDRRef ) where (_IDRRef < 0)
совет
-проверить что в планах row mode
-поставить последний CU
-поднять в базе compatibility level до максимума
-повторить тесты