Здравствуйте.
Пытаюсь разобраться в columnstore index, но пока во всех тестах они медленнее чем обычные (не смотря на то, что execution plan говорит об обратном).
Я создаю indexed view и на нём обычные и columnstore index (тесты провожу на большой 1с таблице, чтобы работать с большим объёмом данных).
CREATE VIEW dbo.test WITH SCHEMABINDING
AS
select d._IDRRef, d._Date_Time, v._LineNo2131, v._Fld2134, v._Fld2135 from dbo._Document191 d
JOIN dbo._Document191_VT2130 v on d._IDRRef = v._Document191_IDRRef
create unique clustered index test_pk on dbo.test(_IDRRef, _LineNo2131) WITH(MAXDOP=12)
create nonclustered index sales_date on dbo.test (_Date_Time, _LineNo2131) WITH(MAXDOP=12)
create nonclustered columnstore index sales_date2 on dbo.test (_Date_Time, _LineNo2131) WITH(MAXDOP=12)
И запускаю тесты:
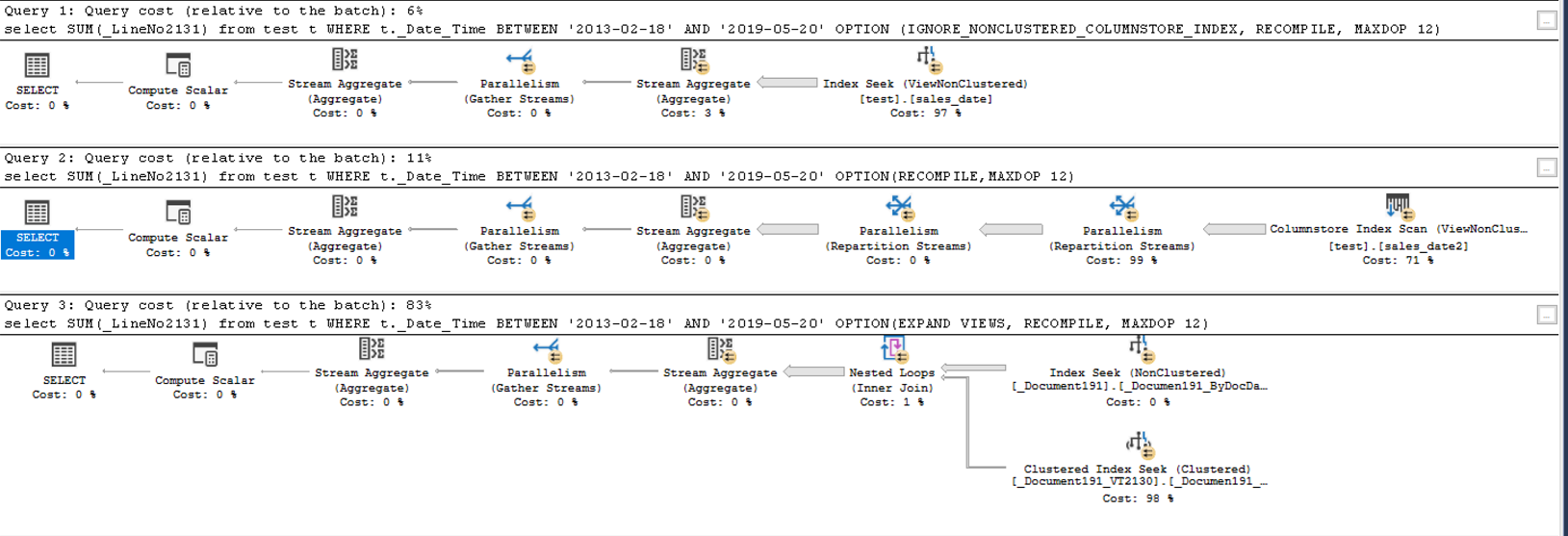
select SUM(_LineNo2131) from test t
WHERE t._Date_Time BETWEEN '2013-02-18' AND '2019-05-20'
OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX, RECOMPILE, MAXDOP 12)
select SUM(_LineNo2131) from test t
WHERE t._Date_Time BETWEEN '2013-02-18' AND '2019-05-20'
OPTION(RECOMPILE, MAXDOP 12)
select SUM(_LineNo2131) from test t
WHERE t._Date_Time BETWEEN '2013-02-18' AND '2019-05-20'
OPTION(EXPAND VIEWS, RECOMPILE, MAXDOP 12)
Первый, соответственно, берёт индекс test и выполняется порядка 5 сек, второй sales_date2 (23 сек) и третий не использует индексы вьюшки (12 сек). Вроде сам запрос как раз того плана, который предполагается ускорять columnstore, но эффект получается обратным. В принципе меня устраивает быстродействие первого индекса (особенно когда выяснил, что оптимизатор может подставлять его в обычный запрос, не использующий вьюшку. Более того — он может подставить даже агрегированный индекс, с суммированием по дням, выдавая 0.057с!), но просто интересно как правильно им пользоваться.
| | Планы (простите, захват с hidpi работает странно) |
| |  |
| | |
ЗЫ. SQL Sever 14.1000.169.
ARI ARI ARI... Arrivederci!

