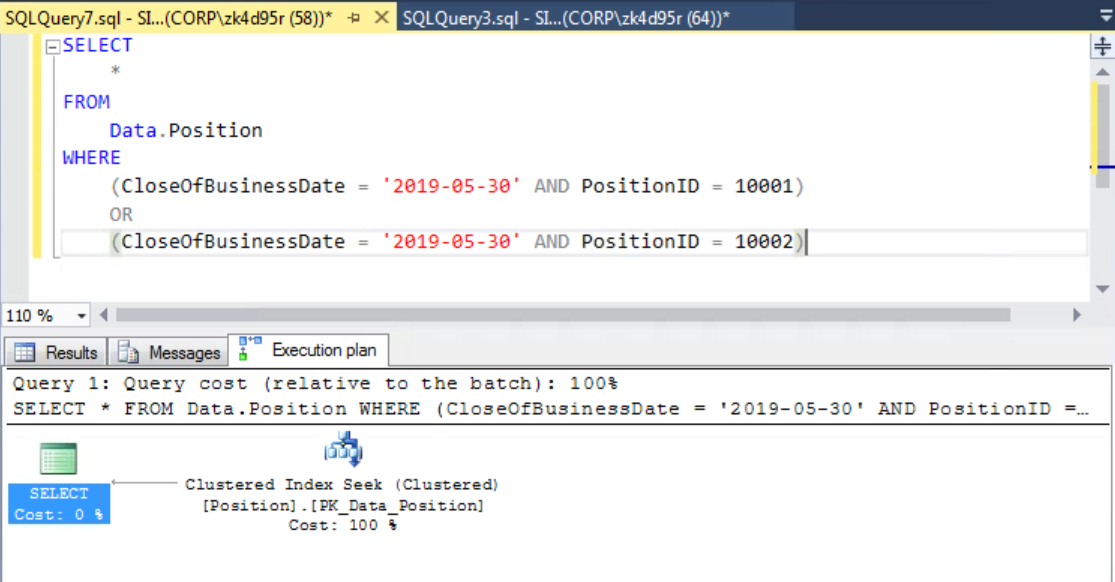
Всем привет!
Есть sql c
WHERE f1=1 or null
По f1 есть индекс. При этом план выполнения вместо поиска по индексу становится — TABLE SCAN (на самом деле SCAN TABLE .. USING COVERING INDEX)
Но если
WHERE f1=1
то используется INDEX SEEK.
Ну и в реальности на большой таблице, разница заметна, 1-й случай — секунда (или несколько, в зависимости от были ли в кэше данные), 2-й — 1мс (почти всегда).
База данных — sqlite.
Почему для A or null не используется поиск индексу? Ведь результаты для 1 и 2-го варианта одинаковы, я не вижу смысла использовать менее эффектиный план для 1-го варианта.
Это sqlite не додумывается? хотя верится с трудом тк вроде случай тривиальный и элеменировать несущественную константу не трудно..
Скорее всего есть какой-то нюанс который мне непонятен, но какой?
Как в других базах, такая же фигня?
PS sql генерится доволььно сложным образом и пока хотелось бы понять почему происходит вышеописанная хрень..
Здравствуйте, MadHuman, Вы писали:
MH>Всем привет! MH>Есть sql c MH> WHERE f1=1 or null MH>По f1 есть индекс. При этом план выполнения вместо поиска по индексу становится — TABLE SCAN (на самом деле SCAN TABLE .. USING COVERING INDEX) MH>Но если MH> WHERE f1=1 MH>то используется INDEX SEEK. MH>Ну и в реальности на большой таблице, разница заметна, 1-й случай — секунда (или несколько, в зависимости от были ли в кэше данные), 2-й — 1мс (почти всегда). MH>База данных — sqlite.
MH>Почему для A or null не используется поиск индексу? Ведь результаты для 1 и 2-го варианта одинаковы, я не вижу смысла использовать менее эффектиный план для 1-го варианта.
Вероятно, движок думает, что чтобы удовлетиворить условие null индекса не хватит, поэтому сканирует всю таблицу. Т.е. вероятно null записи в индекс не попадают.
Здравствуйте, Sharov, Вы писали:
MH>Есть sql c MH> WHERE f1=1 or null
MH>>Почему для A or null не используется поиск индексу? Ведь результаты для 1 и 2-го варианта одинаковы, я не вижу смысла использовать менее эффектиный план для 1-го варианта.
S>Вероятно, движок думает, что чтобы удовлетиворить условие null индекса не хватит, поэтому сканирует всю таблицу. Т.е. вероятно null записи в индекс не попадают.
это врядли, тк в данном случае в результат попадают только записи с не пустым значением в f1 (даже с конкретным = 1), и то что в индексе нет записей с null, не мешает его использовать для поиска записей с f1=1
то есть для движка не использовать индекс на основании того что в него не включены записи с null в f1, никак не является внятной мотивацией для такого его поведения.
Здравствуйте, MadHuman, Вы писали:
MH>Здравствуйте, Sharov, Вы писали:
MH>>Есть sql c MH>> WHERE f1=1 or null
MH>>>Почему для A or null не используется поиск индексу? Ведь результаты для 1 и 2-го варианта одинаковы, я не вижу смысла использовать менее эффектиный план для 1-го варианта.
S>>Вероятно, движок думает, что чтобы удовлетиворить условие null индекса не хватит, поэтому сканирует всю таблицу. Т.е. вероятно null записи в индекс не попадают. MH>это врядли, тк в данном случае в результат попадают только записи с не пустым значением в f1 (даже с конкретным = 1), и то что в индексе нет записей с null, не мешает его использовать для поиска записей с f1=1 MH>то есть для движка не использовать индекс на основании того что в него не включены записи с null в f1, никак не является внятной мотивацией для такого его поведения.
Так смысл использовать индекс, если для null все равно надо сканировать всю таблиуц? Тут боюсь, проблема не в движке, а в запросе, ибо как смысли в ентом or null
S>Так смысл использовать индекс, если для null все равно надо сканировать всю таблиуц?
дак null тут по сути константа, для этого не надо ничего сканировать.
S> Тут боюсь, проблема не в движке, а в запросе, ибо как смысли в ентом or null
такой sql генерится автоматически в результате работы определённого нашего генератора, можно конечно логику генератора наворачивать, но пока хочется понять почему движок так себя ведет.
ведь добавка or null никак не меняет сути и результат отбора, и можно использовать индекс для более эффективного плана, но
движок почему-то не использует, вот и хочется понять — почему?
если всё таки копнуть почему у нас так генериться, то в самом начале был критерий типа A or B=Параметр1, где Параметр1 имеет пустое значение.
генератор содержит определённую логику оптимизации условий и B=null заменяет на константу null. поэтому и имеем в финале A or null.
Так лучше, тк константный null уже говорит что нечего из записи брать не надо, что вроде бы должно упрощать задачу оптимизатору движка БД.
заменять B=null на false нельзя, тк это может быть часть другого выражения типа (.... B=null ) is null, тогда результат будет неверный.
можно логику генерации и оптимизации условий наворачивать, но вроде же оптимизатор БД этим тоже и занимается, и должен заниматься лучше...
И вот надо понять, он тут не занимается потому что не научили?
или есть какая-то другая существенная причина?
Здравствуйте, MadHuman, Вы писали:
MH>Почему для A or null не используется поиск индексу? Ведь результаты для 1 и 2-го варианта одинаковы, я не вижу смысла использовать менее эффектиный план для 1-го варианта. MH>Скорее всего есть какой-то нюанс который мне непонятен, но какой? MH>Как в других базах, такая же фигня?
При использовании в условии хотя бы одного OR всегда происходит TABLE SCAN
Нужно OR заменить на
Здравствуйте, Ops, Вы писали:
Ops>Здравствуйте, MadHuman, Вы писали:
MH>> WHERE f1=1 or null
Ops>А это точно то, чего ты хочешь?
Да, точно
Ops>М.б. where f1 = 1 or f1 is null?
Нет, именно where f1 = 1 or null
sql генерится автоматически, просто в определённом случае получается такой, и с точки зрения финального результата он валиден.
Но план выполнения, его не очень хорош (индекс не используется), что печально.
Раз sql валиден, то нехотелось бы лезть в логику генерации, полагал что оптимизатор движка БД сделает своё дело.
Я сначала думал что есть какой-то нюанс именно с null, но where f1 = 1 or 0 (где 0 — это по сути false, и можно сократить всё выражение до f1=1)
также имеет такую же проблему (план выполнения не использует индекс). Что говорит о том, что видимо всё таки оптимизатор не обучен таким простым оптимизациям.
Что тоже странно, ведь оптима тривиальная.
Здравствуйте, MadHuman, Вы писали:
Ops>>А это точно то, чего ты хочешь? MH>Да, точно
Ops>>М.б. where f1 = 1 or f1 is null? MH>Нет, именно where f1 = 1 or null
Орнул с "OR null".
Эта часть условия всегда FALSE. Наличие OR + константа приводит к тому, что индекс использоваться не будет. Похоже на ошибку.
Здравствуйте, MozgC, Вы писали:
MC>Здравствуйте, Maniacal, Вы писали:
M>>При использовании в условии хотя бы одного OR всегда происходит TABLE SCAN
MC>Это неправда. MC>Image: index.png
Ну, давно я на оракле не оптимизировал запросы. Возможно это когда скан по двум таблицам и между условиями для двух таблиц используется OR. Может, это особенность Oracle. Может, зависит от того, сколько полей в индексе.
Здравствуйте, Maniacal, Вы писали:
M>Ну, давно я на оракле не оптимизировал запросы. Возможно это когда скан по двум таблицам и между условиями для двух таблиц используется OR. Может, это особенность Oracle. Может, зависит от того, сколько полей в индексе.
Ораклоиду везде Оракл мерещится. У MozgC на картинке MSSQL. А у ТС вообще SQLite.
Кстати, ЕМНИП для Оракла X OR NULL всегда NULL, и запрос ТС будет всегда возвращать 0 строк.
Здравствуйте, MadHuman, Вы писали:
MH>Я сначала думал что есть какой-то нюанс именно с null, но where f1 = 1 or 0 (где 0 — это по сути false, и можно сократить всё выражение до f1=1)
Я как раз хотел порпросить проверить этот случай.
MH>также имеет такую же проблему (план выполнения не использует индекс). Что говорит о том, что видимо всё таки оптимизатор не обучен таким простым оптимизациям.
Здравствуйте, MadHuman, Вы писали: MH>Почему для A or null не используется поиск индексу? Ведь результаты для 1 и 2-го варианта одинаковы, я не вижу смысла использовать менее эффектиный план для 1-го варианта.
Похоже на баг. https://www.sqlite.org/optoverview.html#or_opt
Там вроде как каждый из термов под OR должен анализироваться, и оптимизируется
rowid IN (SELECT rowid FROM table1 WHERE f1=1
UNION SELECT rowid FROM table1 WHERE null)
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, TMU_1, Вы писали:
TMU>От меня ускользает смысл этой конструкции. В части or null.
В некоторых диалектах bool-константу unknown называют null.
Не во всех диалектах можно написать её явно; можно получить её в результате вычисления выражения. Например, вот так:
select count(*) from table1 where f1=1 or 1 = null
Там явно какой-то генератор SQL попытался выполнить оптимизацию, свернув константное выражение в его результат. Это, вообще говоря, разумно, т.к. большинство СУБД не задуряются с микрооптимизациями самих выражений.
Считается, что эту работу надо проводить до того, как дёргать СУБД своими запросами. Вот оптимизации, зависящие от данных — это уже к СУБД (ну там, выкинуть выражение, которое заведомо совпадает с верифицированным check constraint).
Получается, что генератору SQL надо быть ещё умнее, и сворачивать A or null в A
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
S>Получается, что генератору SQL надо быть ещё умнее, и сворачивать A or null в A
Всё так, но была мысль, что эту работу сделает оптимизатор движка БД, но получается не делает.
Придётся заморочиться, чтоб в генераторе SQL её сделать, хотя уже заморочились и сделали