Есть таблица T1 с такой структурой:
ID int,
Name varchar(50)
В ней есть записи с ID = 1,2,3, 9, и 20. Есть некоторый набор чисел (1,2,10,9,23). Нужно составить SQL запрос, к-рый вернет все числа из последовательности, которых нет в таблице. Т.е. я ожидаю на выходе:
10,
23
Как такое сделать ср-вами одного SQL запроса?
Здравствуйте, senglory, Вы писали:
S>Есть таблица T1 с такой структурой:
S>S>ID int,
S>Name varchar(50)
S>
S>В ней есть записи с ID = 1,2,3, 9, и 20. Есть некоторый набор чисел (1,2,10,9,23). Нужно составить SQL запрос, к-рый вернет все числа из последовательности, которых нет в таблице. Т.е. я ожидаю на выходе:
S>S>10,
S>23
S>Как такое сделать ср-вами одного SQL запроса?
select x.id
from (values (1),(2),(10),(9),(23)) as x(id)
left join dbo.T1 t on t.id = x.id
where (t.id is null)
Здравствуйте, senglory, Вы писали:
S>Есть таблица T1 с такой структурой:
S>S>ID int,
S>Name varchar(50)
S>
S>В ней есть записи с ID = 1,2,3, 9, и 20. Есть некоторый набор чисел (1,2,10,9,23). Нужно составить SQL запрос, к-рый вернет все числа из последовательности, которых нет в таблице. Т.е. я ожидаю на выходе:
S>S>10,
S>23
S>Как такое сделать ср-вами одного SQL запроса?
select ID from T1 where ID not IN (1,2,10,9,23)
... << RSDN@Home 1.0.0 alpha 5 rev. 0>>
Здравствуйте, senglory, Вы писали:
S>Есть таблица T1 с такой структурой:
S>...
Вот вам и третий вариант в копилку...
select Id from (select 1 union all select 2 union select 10 union select 9 union all select 23) a(Id)
except
select Id from dbo.T1
O>Вот вам и третий вариант в копилку...
O>O>select Id from (select 1 union all select 2 union select 10 union select 9 union all select 23) a(Id)
O>except
O>select Id from dbo.T1
O>
раз пошла такая пьянка, а в каком из способов оптимальнее будет план запроса?
A>раз пошла такая пьянка, а в каком из способов оптимальнее будет план запроса?
план запроса будет примерно одинаковым во всех случаях.
а вот время компиляции этого плана может отличаться на порядок
краткий тест
values (.)(.) SQL Server parse and compile: CPU time = 94 ms, elapsed time = 108 ms.
union all SQL Server parse and compile time: CPU time = 107 ms, elapsed time = 107 ms.
in(....) SQL Server parse and compile time: CPU time = 2385 ms, elapsed time = 2385 ms.
set statistics time on
dbcc freeproccache
drop table if exists #t
create table #t(id int primary key clustered)
go
declare @q1 as nvarchar(max) = N'0' + (select ',' + cast(number as nvarchar(max)) from master..spt_values for xml path(''))
declare @q1_ as nvarchar(max) = N'select * from #t where id not in(' + @q1 + N')'
print '0'
exec sp_executesql @q1_, N''
print '1'
GO
declare @q1 as nvarchar(max) = (select 'select ' + cast(number as nvarchar(max)) + N' union all ' from master..spt_values for xml path('')) + N' select null '
declare @q1_ as nvarchar(max) = N'select * from #t where id not in (select * from (' + @q1 + N') a(Id))'
print '2'
exec sp_executesql @q1_, N''
print '3'
GO
declare @q1 as nvarchar(max) = N'values(0)' + (select N',(' + cast(number as nvarchar(max)) + N')' from master..spt_values for xml path(''))
declare @q1_ as nvarchar(max) = N'select * from #t where id not in(select * from (' + @q1 + N') as x(id))'
print '4'
exec sp_executesql @q1_, N''
print '5'
GO
Здравствуйте, aios, Вы писали:
O>>Вот вам и третий вариант в копилку...
O>>O>>select Id from (select 1 union all select 2 union select 10 union select 9 union all select 23) a(Id)
O>>except
O>>select Id from dbo.T1
O>>
A>раз пошла такая пьянка, а в каком из способов оптимальнее будет план запроса?
Исходные данные:
1. Таблица с 99 998 записей, в которой отсутствуют значения с ID = 10, 23
2. Производная таблица со значениями (1, 2, 9, 10, 23)
| | Запрос |
| | create table dbo.T1
(
Id int primary key,
Name varchar(50)
);
;with cte as
(
select *
from (select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) a(n)
)
-- Вставляем 99 998 записей
insert into dbo.T1(Id, Name)
select a.n, 'Test'
from
(
select top 100000 t1.n + t2.n * 10 + t3.n * 100 + t4.n * 1000 + t5.n * 10000 as n
from cte t1, cte t2, cte t3, cte t4, cte t5
order by n
) a
where n not in (10, 23);
go
|
| | |
Решения с UNION ALL для 2005+:
1. Left join
2. Not in
3. Except
4. Not exists
| | Запрос |
| | /* Вариант 1 */
select a.Id
from (select 1 union all select 2 union select 10 union select 9 union all select 23) as a(Id)
left join dbo.t1 t on t.Id = a.Id
where t.id is null
/* Вариант 2 */
select a.Id from (select 1 union all select 2 union select 10 union select 9 union all select 23) a(Id)
where Id not in (select Id from dbo.T1)
/* Вариант 3 */
select a.Id from (select 1 union all select 2 union select 10 union select 9 union all select 23) a(Id)
except
select Id from dbo.T1
/* Вариант 4 */
select a.Id from (select 1 union all select 2 union select 10 union select 9 union all select 23) a(Id)
where not exists(select Id from dbo.T1 t where t.Id = a.Id)
|
| | |
СУБД:
MS SQL Server 2012 BI Edition, MS SQL Server 2014 Developer Edition
Результаты:
Вариант c left join дает худший план по сравнению с остальными в пакете и занимает 56% относительно всей стоимости. После конкатенации 4-х значений в производной таблице выполняется сортировка стоимостью 74% от всего запроса, а потом конкатенируется последнее значение. В качестве логического оператора используется Left Outer Join.
| | План запроса |
| | 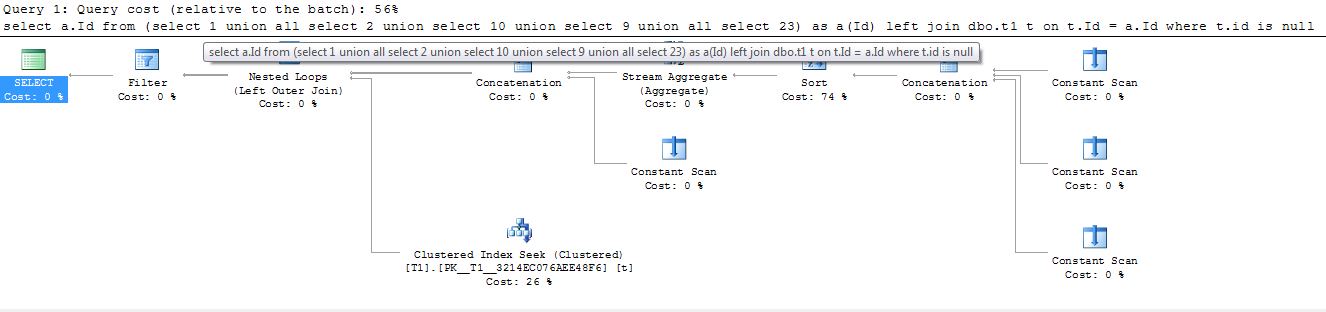 |
| | |
Остальные 3 варианта (2, 3, 4) дают одинаковый план запроса и используют логический оператор Left Semi Anti Join.
| | План запроса |
| | 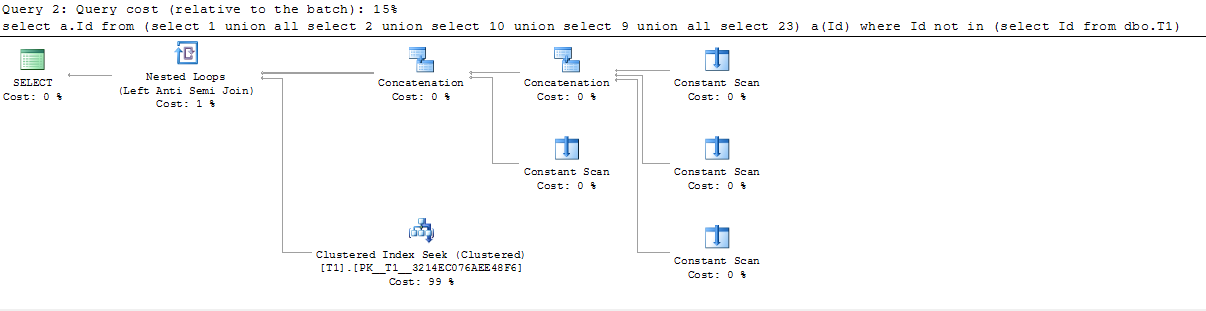 |
| | |
По количеству операций ввода-вывода все решения идентичны:
Table 'T1'. Scan count 0, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Т.к. автор в качестве требования предъявил версию SQL Server 2005+, то от использования TVC при решении пришлось отказаться в пользу UNION ALL для формирования производной таблицы. Но ради интереса решил проверить, а что если использовать TVC…
Решения с TVC для 2008+:
1. Left join
2. Not in
3. Except
4. Not exists
| | Запрос |
| | /* Вариант 1 */
select a.Id
from (values (1),(2),(10),(9),(23)) as a(Id)
left join dbo.t1 t on t.Id = a.Id
where t.id is null
/* Вариант 2 */
select a.Id from (values (1),(2),(10),(9),(23)) a(Id)
where Id not in (select Id from dbo.T1)
/* Вариант 3 */
select a.Id from (values (1),(2),(10),(9),(23)) a(Id)
except
select Id from dbo.T1
/* Вариант 4 */
select a.Id from (values (1),(2),(10),(9),(23)) a(Id)
where not exists(select Id from dbo.T1 t where t.Id = a.Id)
|
| | |
Все четыре решения дают приблизительно одинаковую стоимость от пакета — 25% Вариант номер 1 по-прежнему использует логический оператор Left Outer Join, но конкатенация и сортировка значений заменены на оператор Constant Scan.
| | План запроса |
| | 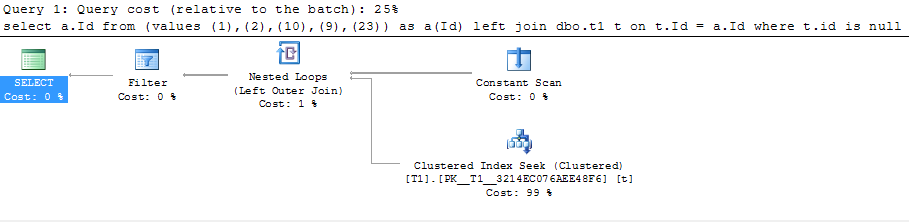 |
| | |
Остальные решения (2, 3, 4) используют Left Semi Anti Join и так же Constatnt Scan. Операции ввода-вывода индентичны варианту выше с UNION ALL.
| | План запроса |
| | 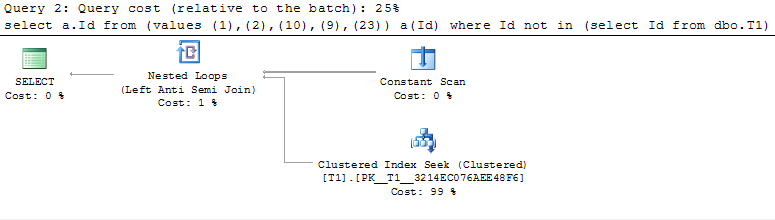 |
| | |
Что касается времени выполнения, то оно близкое и находится в интервале 1-2 мс для всех решений. Проверял через SQL Query Stress на 1000 итераций, как с dbcc freeproccache так и без.
Все сказанное ИМХО, на истинность не претендует и главное – каждую ситуацию необходимо проверять на конкретной БД, схеме, данных и т.п., я постарался использовать те условия, которые предоставил автор топика.






