Вопрос такого рода:
У нас преобладает тематика — моделирование и научные расчёты.
Я придерживаюсь мнения, что СУБД MS SQL Server 2012 можно успешно применять для хранения данных в клиент-серверных приложениях по подобной тематике.
На сегодняшний день, наши приложения используют именно его.
Конечно, есть некоторые вопросы. Основной из них:
Файл лога транзакций растёт очень быстро (приложения моделирования пишут много данных на каждом шаге прогона модели).
Это приводит к увеличению (весьма сильному) back-up файлов.
Как избежать данной проблемы?
Как правильно избавиться от создания и сохранения Log-ов транзакций?
Имеет ли смысл полностью избавляться от него, или просто как-то ограничить рост Log-а транзакций?
Для наших задач, откат транзакции не актуален, это не банк
You cannot "turn off" the transaction log. You can switch the recovery model to Simple or Bulk-Logged during the import. You also might want to drop some of your non-clustered indexes in the destination database. This will make the import go faster.
Как быть в этом случае? Имеет ли смысл придерживаться данного совета, или есть другие решения?
ПРИМЕЧАНИЕ: Сам сервер MS SQL Server 2012 (developer edition) у нас ставится локально,
на рабочем месте разработчика-экспериментатора и работает под ОС Windows 7 (64) SP1.
Заранее благодарю ответивших!
P.S. Так как у уважаемых товарищей, которые не в теме задач моделирования и расчётов, возникает недоумение:
— Зачем в контексте поставленных задач целый MS SQL Server?
То обоснование данного выбора приведено вот здесь
Здравствуйте, AlexGin, Вы писали:
AG>Доброе время суток, уважаемые коллеги!
AG>Вопрос такого рода: AG>У нас преобладает тематика — моделирование и научные расчёты. AG>Я придерживаюсь мнения, что СУБД MS SQL Server 2012 можно успешно применять для хранения данных в клиент-серверныхприложениях по подобной тематике. AG>На сегодняшний день, наши приложения используют именно его.
AG>Конечно, есть некоторые вопросы. Основной из них: AG>- Файл лога транзакций растёт очень быстро (приложения моделирования пишут много данных на каждом шаге прогона модели). Что приводит к увеличению (весьма сильному) back-up файлов. AG>Как избежать данной проблемы? AG>Как правильно избавиться от создания и сохранения Log-ов транзакций?
Совсем избавиться не получится. Но можно поставить простую модель восстановления (Recovery model simple). Тогда файл лога транзакций будет использоваться как кольцевой буфер и иметь ограниченный размер.
Re: MS SQL Server для моделирования и научных расчётов
Здравствуйте, AlexGin, Вы писали:
AG>Файл лога транзакций растёт очень быстро (приложения моделирования пишут много данных на каждом шаге прогона модели). AG>Это приводит к увеличению (весьма сильному) back-up файлов. AG>Как избежать данной проблемы? AG>Как правильно избавиться от создания и сохранения Log-ов транзакций? AG>Имеет ли смысл полностью избавляться от него, или просто как-то ограничить рост Log-а транзакций?
Избавиться нельзя, да и смысла не имеет. Ограничить можно.
1. Почитайте про модели восстановления (recovery model), выберите подходящую.
2. Делайте бэкапы чаще, их размер станет меньше. Старые и ненужные удаляйте.
3. На промежуточных этапах расчетов вместо обычных таблиц пишите во временные. Они не увеличивают лог.
4. Подумайте о распределении данных по нескольким базам в рамках одного инстанса. (исходные данные, промежуточные, окончательные результаты и т.д.). Для каждой базы можно настроить свой режим восстановления, стратегию бэкапа и т.д.
А лучше вместо всего этого наймите грамотного DBA. Он вам все сделает.
AG>Для наших задач, откат транзакции не актуален, это не банк
Не зарекайтесь
Re: MS SQL Server для моделирования и научных расчётов
Здравствуйте, AlexGin, Вы писали:
AG>ПРИМЕЧАНИЕ: Сам сервер MS SQL Server 2012 (developer edition) у нас ставится локально, AG>на рабочем месте разработчика-экспериментатора и работает под ОС Windows 7 (64) SP1.
Это по бедности или есть на то веские причины? Централизованно и с логами, и с бэкапами проще управляться.
Re[2]: MS SQL Server для моделирования и научных расчётов
Здравствуйте, capgreen, Вы писали:
C>Совсем избавиться не получится. Но можно поставить простую модель восстановления (Recovery model simple). Тогда файл лога транзакций будет использоваться как кольцевой буфер и иметь ограниченный размер.
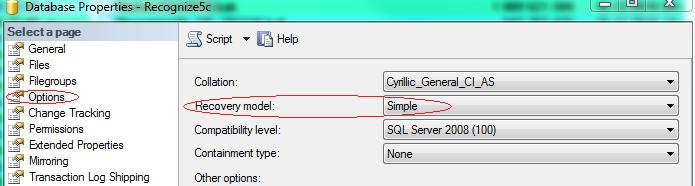
В настройках Свойств Базы Данных:
Это, как я понимаю, именно оно?
Re[2]: MS SQL Server для моделирования и научных расчётов
Здравствуйте, wildwind, Вы писали:
W>Избавиться нельзя, да и смысла не имеет. Ограничить можно.
W>1. Почитайте про модели восстановления (recovery model), выберите подходящую. W>2. Делайте бэкапы чаще, их размер станет меньше. Старые и ненужные удаляйте. W>3. На промежуточных этапах расчетов вместо обычных таблиц пишите во временные. Они не увеличивают лог. W>4. Подумайте о распределении данных по нескольким базам в рамках одного инстанса. (исходные данные, промежуточные, окончательные результаты и т.д.). Для каждой базы можно настроить свой режим восстановления, стратегию бэкапа и т.д.
Спасибо, уважаемый wildwind, интересные мысли!
W>А лучше вместо всего этого наймите грамотного DBA. Он вам все сделает.
AG>>Для наших задач, откат транзакции не актуален, это не банк W>Не зарекайтесь
Здесь, если есть сомнения в результатах моделирования, просто проводим эксперимент повторно.
Каждый эксперимент — это тысячи (иногда даже десятки тысяч) относительно небольших записей в определённые таблицы БД.
Re[2]: MS SQL Server для моделирования и научных расчётов
Здравствуйте, wildwind, Вы писали:
W>Это по бедности или есть на то веские причины? Централизованно и с логами, и с бэкапами проще управляться.
Есть сервер — контроллер домена (Windows Server 2012), но пока — экспериментируем на рабочем месте.
Тем более, что для каждого из исследователей — характерна своя тематика.
На будущее — возможно развернём и центральный сервер.
Re[3]: MS SQL Server для моделирования и научных расчётов
Здравствуйте, AlexGin, Вы писали:
AG>Здравствуйте, capgreen, Вы писали:
C>>Совсем избавиться не получится. Но можно поставить простую модель восстановления (Recovery model simple). Тогда файл лога транзакций будет использоваться как кольцевой буфер и иметь ограниченный размер.
AG>В настройках Свойств Базы Данных: AG>Image: RecoveryModel1.jpg AG>Это, как я понимаю, именно оно?
Да.
Но можно и так
ALTER DATABASE имя_базы_данных SET RECOVERY SIMPLE;
Re: MS SQL Server для моделирования и научных расчётов
Если анализ покажет, что "затык" в дисковой подсистеме, то можно попробовать разнести файлы базы данных по разным физическим дискам, если они есть, конечно.
Я как-то растащил файлы БД по трем дискам и наблюдал увеличение производительности дисковой подсистемы чуть меньше чем в три раза
Re[2]: MS SQL Server для моделирования и научных расчётов
Здравствуйте, capgreen, Вы писали:
C>Если анализ покажет, что "затык" в дисковой подсистеме, то можно попробовать разнести файлы базы данных по разным физическим дискам, если они есть, конечно. C>Я как-то растащил файлы БД по трем дискам и наблюдал увеличение производительности дисковой подсистемы чуть меньше чем в три раза
Спасибо, уважаемый capgreen, в данном случае — проблема несколько иная (скорее теоретическая):
Если (у Заказчика) возникнет вопрос, почему выбрали именно эту СУБД (здесь достоинств масса) и как ограничить рост БД,
если лог-транзакций не нужен.
Вот и прорабатываю, как ограничить рост базы, но пока (да и в обозримой перспективе) ничего в пределы не упирается
Re[3]: MS SQL Server для моделирования и научных расчётов
Здравствуйте, AlexGin, Вы писали: AG>Если (у Заказчика) возникнет вопрос, почему выбрали именно эту СУБД (здесь достоинств масса) ...
естественно возникнет,
я вот честно сказать, даже и не знаю что ответить, зачем сиквелсервер, если асид не нужен
Re[3]: MS SQL Server для моделирования и научных расчётов
AG>Вот и прорабатываю, как ограничить рост базы, но пока (да и в обозримой перспективе) ничего в пределы не упирается
Мне, вообще, кажется, что использование MS SQL-Server в задаче где не требуется поддержка целостности данных это перебор.
Тут надо что-то из NoSQL попробовать, MongoDB например.
Re[3]: MS SQL Server для моделирования и научных расчётов
Здравствуйте, AlexGin, Вы писали:
AG>Здравствуйте, capgreen, Вы писали:
C>>Совсем избавиться не получится. Но можно поставить простую модель восстановления (Recovery model simple). Тогда файл лога транзакций будет использоваться как кольцевой буфер и иметь ограниченный размер.
AG>В настройках Свойств Базы Данных: AG>Image: RecoveryModel1.jpg AG>Это, как я понимаю, именно оно?
Если у вас все равно получается большой лог при простой модели, то имеет дело в том, что у вас данные пишутся в рамках больших транзакций, тогда имеет смысл резать такие транзакции на куски поменьше, например вставлять или удалять не больше заданного порога за раз. (Использовать SET ROWCOUNT ... или SELECT/INSERT/DELETE TOP (N) ... )
Re[4]: MS SQL Server для моделирования и научных расчётов
Здравствуйте, capgreen, Вы писали:
C>Мне, вообще, кажется, что использование MS SQL-Server в задаче где не требуется поддержка целостности данных это перебор. C>Тут надо что-то из NoSQL попробовать, MongoDB например.
Ага. Или что-то типа HDF5 (сам не пробовал, только приглядываюсь).
_____________________
С уважением,
Stanislav V. Zudin
Re[4]: MS SQL Server для моделирования и научных расчётов
Здравствуйте, capgreen, Вы писали:
AG>>Вот и прорабатываю, как ограничить рост базы, но пока (да и в обозримой перспективе) ничего в пределы не упирается C>Мне, вообще, кажется, что использование MS SQL-Server в задаче где не требуется поддержка целостности данных это перебор. C>Тут надо что-то из NoSQL попробовать, MongoDB например.
Если я чётко представляю структуру хранимых данных, то какой мне смысл отказываться от неё в пользу этого: https://en.wikipedia.org/wiki/NoSQL
Здравствуйте, AlexGin, Вы писали:
AG>Здравствуйте, capgreen, Вы писали:
AG>>>Вот и прорабатываю, как ограничить рост базы, но пока (да и в обозримой перспективе) ничего в пределы не упирается C>>Мне, вообще, кажется, что использование MS SQL-Server в задаче где не требуется поддержка целостности данных это перебор. C>>Тут надо что-то из NoSQL попробовать, MongoDB например.
AG>Если я чётко представляю структуру хранимых данных, то какой мне смысл отказываться от неё в пользу этого: AG>https://en.wikipedia.org/wiki/NoSQL
AG>Вот по теме: AG>https://habrahabr.ru/post/164361
Красивая и понятная схема данных это прекрасно (лично я только за), но она не всегда способствует повышению производительности системы, хотя, определенно, способствует повышению производительности программиста
Бывают ситуации когда для повышения производительности требуется, например такая штука, как "денормализация" данных (прямое нарушение какой-либо из нормальных форм). В общем тут, как обычно, есть место для компромисов между красотой и производительность.
Re[4]: MS SQL Server для моделирования и научных расчётов
Здравствуйте, capgreen, Вы писали:
AG>>Вот и прорабатываю, как ограничить рост базы, но пока (да и в обозримой перспективе) ничего в пределы не упирается C>Мне, вообще, кажется, что использование MS SQL-Server в задаче где не требуется поддержка целостности данных это перебор.
Есть две задачи:
a) Хранение данных с известной структурой;
b) Удобная выборка данных.
Разве этого НЕдостаточно, чтобы принять к применению чт-то из реляционних СУБД?
Спорить можно скорее на тему: ORACLE vs MS SQL
C>Тут надо что-то из NoSQL попробовать, MongoDB например.
Я читал статьи наподобие этой: https://habrahabr.ru/company/ruvds/blog/324936
или этой: https://habrahabr.ru/post/152477
...и даже и небольшую практику с MongoDB имел на старом рабочем месте.
Тем не менее, для хранилища данных (если знать структуру этих данных) — что удобнее, нежели SQL
P.S. Хочу всё-таки напомнить, что СУБД — это всё-таки инструмент для решения задач хранения данных, а не задач по созданию лишнего геморроя.
Здравствуйте, AlexGin, Вы писали: AG>Есть две задачи: AG>a) Хранение данных с известной структурой; AG>b) Удобная выборка данных.
для этой задачи даже elasticsearch подходит