Здравствуйте, Kvazimodo75, Вы писали:
K>Есть таблица в которой довольно часто меняются данные (вставка, обновление, удаление). K>И тут понадобилось сделать count(a) where person_id in .... K>в результате время выполнения запроса — 7 минут K>Что можно придумать, чтобы работало быстро? (приемлемо секунд 30)
1) Если нужно просто посчитать количество строк, где person_id = ..., то лучше считать count(person_id)
2) Covering index (person_id, a)
3) Index on person_id include (a)
Здравствуйте, Kvazimodo75, Вы писали:
K>в результате время выполнения запроса — 7 минут
Для начала следует разобраться, на что СУБД тратит эти семь минут. Для этого есть всякие разные инструменты, описанные в performance tuning guide тщательно скрываемого Вами сервера.
K>Что можно придумать, чтобы работало быстро? (приемлемо секунд 30)
Придумать можно много, но как бы ежу понятно, что в случаях "в таблице 1.000.000.000 записей" и "в таблице 100 записей" правильные действия будут немного разными.
Здравствуйте, Kvazimodo75, Вы писали:
K>Есть таблица в которой довольно часто меняются данные (вставка, обновление, удаление).
K>И тут понадобилось сделать count(a) where person_id in ....
K>в результате время выполнения запроса — 7 минут
K>Что можно придумать, чтобы работало быстро? (приемлемо секунд 30)
1. Не делать count(*). Обычно это реально никому не надо.
2. Вести статистику в отдельной таблице, может быть даже не в СУБД, например при старте сервера считать число строк и потом хранить это значение в оперативной памяти сервера (если у нас не кластер). В связи с транзакциями, откатами и тд значение может быть неточным, но для миллионов обычно интересен примерный порядок, а не точное значение.
2.1. Использовать служебные данные из статистики БД.
По факту count(*) это тяжёлая операция, если её делать корректно и таблица большая и от этого никуда не деться.
Здравствуйте, Kvazimodo75, Вы писали:
K>Есть таблица в которой довольно часто меняются данные (вставка, обновление, удаление).
K>И тут понадобилось сделать count(a) where person_id in ....
K>в результате время выполнения запроса — 7 минут
K>Что можно придумать, чтобы работало быстро? (приемлемо секунд 30)
select count(a)from tablea with(nolock)
where person_id in
K>Что можно придумать, чтобы работало быстро? (приемлемо секунд 30)
Кроме вышесказанного — еще раз посмотреть, что там в in. В некоторых случаях эффективнее exists. Иногда (если там подзапрос) внутреннее соединение.
Может слишком большой список пытаетесь запихнуть в in.
Здравствуйте, Kvazimodo75, Вы писали:
K>Есть таблица в которой довольно часто меняются данные (вставка, обновление, удаление).
... K>Что можно придумать, чтобы работало быстро? (приемлемо секунд 30)
Потрясающе. Люди уже дают советы, но при этом что за запрос, или что за СУБД хотя бы — никто даже не уточнил
Здравствуйте, Kvazimodo75, Вы писали:
K>Есть таблица в которой довольно часто меняются данные (вставка, обновление, удаление).
K>И тут понадобилось сделать count(a) where person_id in ....
K>в результате время выполнения запроса — 7 минут
K>Что можно придумать, чтобы работало быстро? (приемлемо секунд 30)
vsb>1. Не делать count(*). Обычно это реально никому не надо.
Где Вы видели звездочку?
vsb>2. Вести статистику в отдельной таблице, может быть даже не в СУБД, например при старте сервера считать число строк и потом хранить это значение в оперативной памяти сервера (если у нас не кластер). В связи с транзакциями, откатами и тд значение может быть неточным, но для миллионов обычно интересен примерный порядок, а не точное значение.
Нужно точное значение
vsb>2.1. Использовать служебные данные из статистики БД.
Здравствуйте, Kvazimodo75, Вы писали:
K>Быстрый селект. K>Без count тот же запрос выполняется за 0-1 секунду.
Делаю предположение, что count(cpl1.id) — это и есть count(a)?
Идет скан всей таблицы для получения cpl1.id и последующий nested join.
Одним из возможных решений является создание индекса, который подсказывает план.
Скачайте SQL Sentry Plan Explorer и прогоните запрос там. У него есть функция анонимизации
плана в бесплатной версии. После анонимизации можно без особой опаски выложить полный план
в виде отдельного файла, а не скриншота.
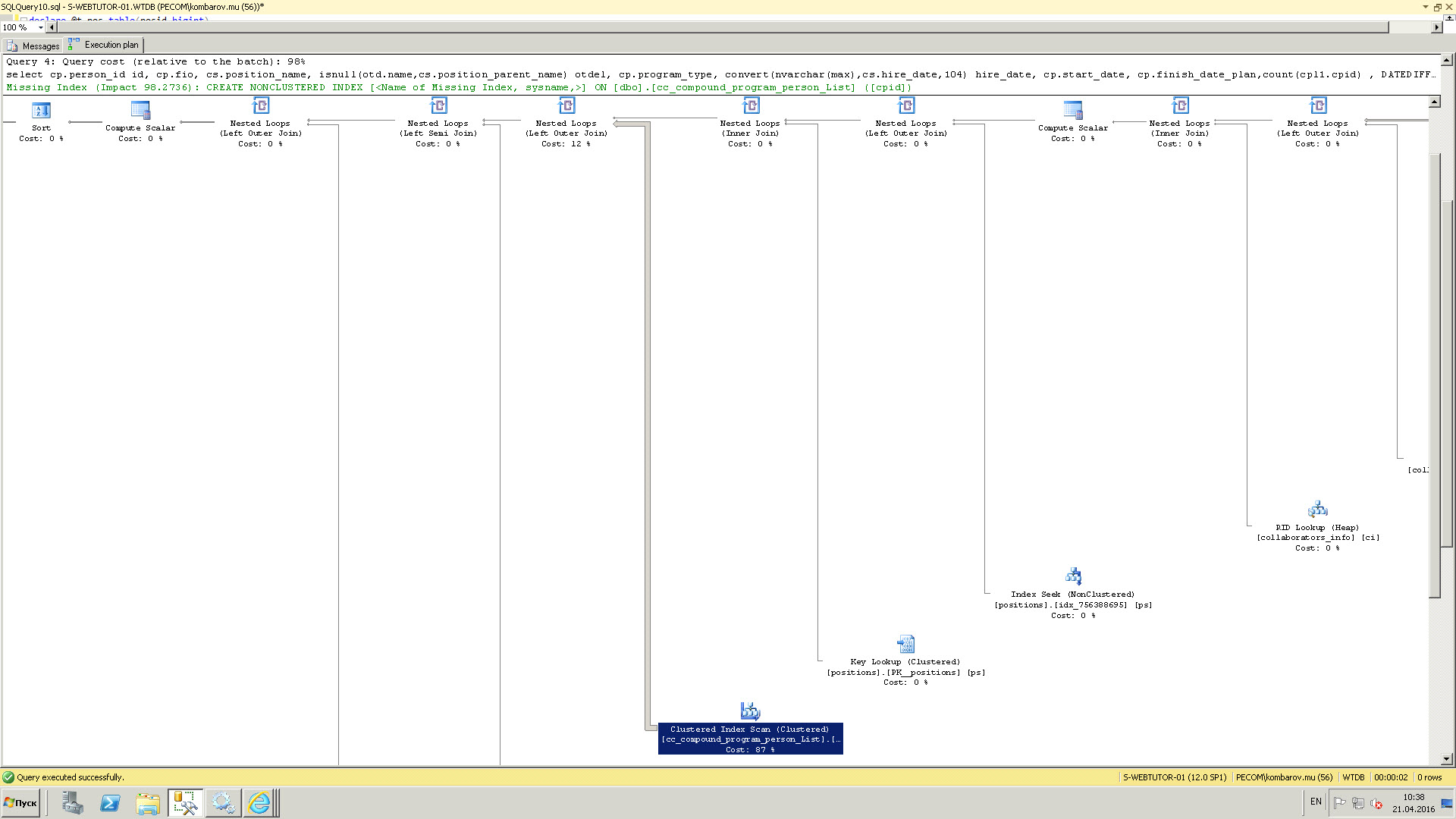
Здравствуйте, Kvazimodo75, Вы писали: K>Сервер MS SQL 2014. K>План запроса:
1. План — от какого-то совсем другого запроса. В кроме count() есть много всего прочего, что влияет на стоимость.
2. Удивительным образом, на плане прямо написан совет, как ускорить ваш запрос.
Вы пробовали этот совет применить?
K>Количество записей исчисляется десятками тысяч — вроде как не много совсем.
K>Примерный результат не допустим.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
S>1. План — от какого-то совсем другого запроса. В нём вообще нет count(). Зато есть много всего
Да не, есть у него там ближе к правому краю картинки: count(cpl1.cpid)
PS Но давать план запроса в таком виде это форменное издевательство.
Здравствуйте, Sinclair, Вы писали:
S>1. План — от какого-то совсем другого запроса. В кроме count() есть много всего прочего, что влияет на стоимость. S>2. Удивительным образом, на плане прямо написан совет, как ускорить ваш запрос. S>Вы пробовали этот совет применить?
Данные в этой таблице постоянно обновляются, поэтому я не добавляю индексы в неё специально.
Решил тем, что результат count удивительным образом совпадает с порциями изменяемых данных, поэтому подсчитывается триггером и пишется в отдельную таблицу.
Исходный запрос изменён на left outer join с этой отдельной таблицей.
Здравствуйте, Kvazimodo75, Вы писали:
K>Здравствуйте, Sinclair, Вы писали:
S>>1. План — от какого-то совсем другого запроса. В кроме count() есть много всего прочего, что влияет на стоимость. S>>2. Удивительным образом, на плане прямо написан совет, как ускорить ваш запрос. S>>Вы пробовали этот совет применить?
K>Данные в этой таблице постоянно обновляются, поэтому я не добавляю индексы в неё специально.
Ну знаете, тогда не стоит жаловаться. У вас идет сканирование таблицы (тупой перебор строки за строкой), потому что индексов нет. И как написал SQL Server, запрос можно улучшить в разы, добавив его.
Как по-вашему работают высоконагруженные системы с миллиардами записей — все часами ждут ответа? Думаете, там тоже без индексов совсем, потому что вставки по 1000 транзакций в минуту? Почитайте про FILLFACTOR, чтобы улучшить понимание того, что можно сбалансировать индексы, чтобы они нормально работали и на вставку, и на чтение.
Здравствуйте, Kvazimodo75, Вы писали:
K>Данные в этой таблице постоянно обновляются, поэтому я не добавляю индексы в неё специально.
Ну, я бы всё таки рискнул и посмотрел, насколько это ухудшит производительность вставки.
K>Решил тем, что результат count удивительным образом совпадает с порциями изменяемых данных, поэтому подсчитывается триггером и пишется в отдельную таблицу.
Вы и вправду думаете, что триггер с записью в отдельную таблицу будет значительно быстрее, чем обновление индекса? Почему?
Уйдемте отсюда, Румата! У вас слишком богатые погреба.