Внимание, опубликую и запрос и ПЛАН сразу. хрен вам они помогут только гагага.
Итак, проблема следующая. есть Запрос, который работает медленно если в первый раз запускаешь. Вторые и последующие запуски (даже с изменением параметров запроса) уже более-менее быстрые — то есть видать что-то там оракл кладет в кэш. Хотелось бы чтоб запрос работал более стабильно!
План вообще какой-то неинформативный как по мне — кост очень небольшой. То есть непонятно что там улучшать, оно типа и так все хорошо.
Запрос:
select B.* from (select A.*, rownum as rn from (select C.COMPANYNAME, C.COMPANYID as CLIENT, P.INSTRUMENT, P.VALID_FROM, P.FREQUENCY, P.DETAILEDFREQUENCY, cf.VAL_DATE ,
(select max(vv.val_date) from tableE vv
where vv.REQUEST = p.PKEY and vv.VALID = 'Y' and vv.dealer=8
) as ASOF from tableN c
inner join tableD dp on c.companyId=dp.companyId and dp.dealer=8
inner join tableC p on p.VALID = 'Y' and p.SINGLE = 'Y' and p.OWNER = c.COMPANYID
inner join VM_CALENDAR_FREQUENCIES cf on cf.FREQUENCY=p.FREQUENCY and cf.DETAILEDFREQUENCY=p.DETAILEDFREQUENCY and cf.VAL_DATE between '20150427' and '20150427' and cf.REGIONALHUB in ('ALL',c.REGIONALHUB)
inner join VM_IDS i on i.ID_KEY = P.INSTRUMENT and i.VALID = 'Y'
inner join tableA b on i.BOND = b.PKEY and b.VALID = 'Y'
inner join tableB_DEFAULT_PERMS pd on pd.dealer=12584 and pd.VALID ='Y' and
(pd.START_DATE is null or '20150427' > pd.START_DATE) and(pd.END_DATE is null or '20150727' < pd.END_DATE)
and pd.client=p.owner and ( (pd.bond_type=b.type and pd.bond_type in ('Sov','Corp','StatBody')) or ( pd.bond_type = 'Unclassified' and (b.type not in ('Sov','Corp','StatBody') or b.type is null ) ) ) left outer join tableB_REQUEST_PERMS pm on pm.instrument = p.instrument and pm.CLIENT = p.owner
and pm.DEALER = 12584 and pm.VALID = 'Y' and pm.request_id=p.pkey and (pm.START_DATE is null or '20150427' > pm.START_DATE) and(pm.END_DATE is null or '20150427' < pm.END_DATE) where (c.ISCURRENT = 'Y' and c.ISDEALER = 'N' and c.REGIONALHUB in ('BLA', 'BLU', 'BLE', 'BBB', 'YY')) and ((pm.permission in ('A','B','M','Y') ) or ( (pm.permission is null or pm.permission ='P') and (pd.permission in ('A','B','M','Y') ) )) order by c.COMPANYNAME Asc nulls first , c.COMPANYNAME, cf.VAL_DATE asc ) A where rownum <= 30) B where rn > 1
Здравствуйте, зиг, Вы писали:
зиг>Внимание, опубликую и запрос и ПЛАН сразу. хрен вам они помогут только гагага. зиг>Итак, проблема следующая. есть Запрос, который работает медленно если в первый раз запускаешь. Вторые и последующие запуски (даже с изменением параметров запроса) уже более-менее быстрые — то есть видать что-то там оракл кладет в кэш. Хотелось бы чтоб запрос работал более стабильно! зиг>План вообще какой-то неинформативный как по мне — кост очень небольшой. То есть непонятно что там улучшать, оно типа и так все хорошо.
ну то есть какой помощи от вас я прошу. не чтоб вы мне тут запрос переписали, или с индексами помогли — понятно что это невозможно без всех знаний всех таблиц и всего что там находится.
мне нужен совет — в каком направлении пнуть наших DBA которые базу майнтейнят. может быть тут очевидная какая-то недоработка с их стороны? типа если кост запроса небольшой а фактически выполняется он долго — значит , я не знаю, статистика там хреново обновляется например. или что-нибудь аналогичное же.
если б хотя бы план отображал действительную картину — тогда было бы уже легче инвестигировать. то есть я так понимаю проблему надо начинать решать с этой стороны?
зиг>select B.* from (select A.*, rownum as rn from (select C.COMPANYNAME, C.COMPANYID as CLIENT, P.INSTRUMENT, P.VALID_FROM, P.FREQUENCY, P.DETAILEDFREQUENCY, cf.VAL_DATE ,
зиг>(select max(vv.val_date) from tableE vv
зиг> where vv.REQUEST = p.PKEY and vv.VALID = 'Y' and vv.dealer=8
зиг> ) as ASOF from tableN c
зиг> inner join tableD dp on c.companyId=dp.companyId and dp.dealer=8
зиг> inner join tableC p on p.VALID = 'Y' and p.SINGLE = 'Y' and p.OWNER = c.COMPANYID
зиг> inner join VM_CALENDAR_FREQUENCIES cf on cf.FREQUENCY=p.FREQUENCY and cf.DETAILEDFREQUENCY=p.DETAILEDFREQUENCY and cf.VAL_DATE between '20150427' and '20150427' and cf.REGIONALHUB in ('ALL',c.REGIONALHUB)
зиг> inner join VM_IDS i on i.ID_KEY = P.INSTRUMENT and i.VALID = 'Y'
зиг> inner join tableA b on i.BOND = b.PKEY and b.VALID = 'Y'
зиг> inner join tableB_DEFAULT_PERMS pd on pd.dealer=12584 and pd.VALID ='Y' and
зиг> (pd.START_DATE is null or '20150427' > pd.START_DATE) and(pd.END_DATE is null or '20150727' < pd.END_DATE)
зиг> and pd.client=p.owner and ( (pd.bond_type=b.type and pd.bond_type in ('Sov','Corp','StatBody')) or ( pd.bond_type = 'Unclassified' and (b.type not in ('Sov','Corp','StatBody') or b.type is null ) ) ) left outer join tableB_REQUEST_PERMS pm on pm.instrument = p.instrument and pm.CLIENT = p.owner
зиг> and pm.DEALER = 12584 and pm.VALID = 'Y' and pm.request_id=p.pkey and (pm.START_DATE is null or '20150427' > pm.START_DATE) and(pm.END_DATE is null or '20150427' < pm.END_DATE) where (c.ISCURRENT = 'Y' and c.ISDEALER = 'N' and c.REGIONALHUB in ('BLA', 'BLU', 'BLE', 'BBB', 'YY')) and ((pm.permission in ('A','B','M','Y') ) or ( (pm.permission is null or pm.permission ='P') and (pd.permission in ('A','B','M','Y') ) )) order by c.COMPANYNAME Asc nulls first , c.COMPANYNAME, cf.VAL_DATE asc ) A where rownum <= 30) B where rn > 1
Опишу свои мысли:
Несколько таблиц, вероятно больших, джойнятся между собой, а потом результат сильно усекается условиями, т.е. получается, например, 2.000X2.000=4.000.000 строк и потом условия по этому множеству дают всего 200 строчек, то есть 99% данных, выбранных из базы, на которые было истрачено время, просто выкидываются. Вместо этого проще перебрать условиями каждую из таблиц и потом джойнить маленькие остатки. Будет в разы быстрее. Например, вот этот кусок:
[sql]
inner join tableB_DEFAULT_PERMS pd
on pd.dealer=12584
and pd.VALID ='Y'
and(pd.START_DATE is null or '20150427' > pd.START_DATE)
and(pd.END_DATE is null or '20150727' < pd.END_DATE)
and pd.client=p.owner
and ( (pd.bond_type=b.type and pd.bond_type in ('Sov','Corp','StatBody'))
or
( pd.bond_type = 'Unclassified' and (b.type not in ('Sov','Corp','StatBody') or b.type is null ) )
должен выглядеть так:
inner join
(
select pd.client /* и может еще колонки, нужные для финальной таблицы */from tableB_DEFAULT_PERMS pd
on pd.dealer=12584
and pd.VALID ='Y'
and(pd.START_DATE is null or '20150427' > pd.START_DATE)
and(pd.END_DATE is null or '20150727' < pd.END_DATE)
and ( (pd.bond_type=b.type and pd.bond_type in ('Sov','Corp','StatBody'))
or
( pd.bond_type = 'Unclassified' and (b.type not in ('Sov','Corp','StatBody') or b.type is null ) )
) as pd on pd.client=p.owner
Здравствуйте, зиг, Вы писали: зиг>Внимание, опубликую и запрос и ПЛАН сразу. хрен вам они помогут только гагага. зиг>Итак, проблема следующая. есть Запрос, который работает медленно если в первый раз запускаешь. Вторые и последующие запуски (даже с изменением параметров запроса) уже более-менее быстрые — то есть видать что-то там оракл кладет в кэш. Хотелось бы чтоб запрос работал более стабильно! зиг>План вообще какой-то неинформативный как по мне — кост очень небольшой. То есть непонятно что там улучшать, оно типа и так все хорошо. зиг>Запрос: зиг>
зиг>select B.* from (select A.*, rownum as rn from (select C.COMPANYNAME, C.COMPANYID as CLIENT, P.INSTRUMENT, P.VALID_FROM, P.FREQUENCY, P.DETAILEDFREQUENCY, cf.VAL_DATE ,
зиг>(select max(vv.val_date) from tableE vv
зиг> where vv.REQUEST = p.PKEY and vv.VALID = 'Y' and vv.dealer=8
зиг> ) as ASOF from tableN c
зиг> inner join tableD dp on c.companyId=dp.companyId and dp.dealer=8
зиг> inner join tableC p on p.VALID = 'Y' and p.SINGLE = 'Y' and p.OWNER = c.COMPANYID
зиг> inner join VM_CALENDAR_FREQUENCIES cf on cf.FREQUENCY=p.FREQUENCY and cf.DETAILEDFREQUENCY=p.DETAILEDFREQUENCY and cf.VAL_DATE between '20150427' and '20150427' and cf.REGIONALHUB in ('ALL',c.REGIONALHUB)
зиг> inner join VM_IDS i on i.ID_KEY = P.INSTRUMENT and i.VALID = 'Y'
зиг> inner join tableA b on i.BOND = b.PKEY and b.VALID = 'Y'
зиг> inner join tableB_DEFAULT_PERMS pd on pd.dealer=12584 and pd.VALID ='Y' and
зиг> (pd.START_DATE is null or '20150427' > pd.START_DATE) and(pd.END_DATE is null or '20150727' < pd.END_DATE)
зиг> and pd.client=p.owner and ( (pd.bond_type=b.type and pd.bond_type in ('Sov','Corp','StatBody')) or ( pd.bond_type = 'Unclassified' and (b.type not in ('Sov','Corp','StatBody') or b.type is null ) ) ) left outer join tableB_REQUEST_PERMS pm on pm.instrument = p.instrument and pm.CLIENT = p.owner
зиг> and pm.DEALER = 12584 and pm.VALID = 'Y' and pm.request_id=p.pkey and (pm.START_DATE is null or '20150427' > pm.START_DATE) and(pm.END_DATE is null or '20150427' < pm.END_DATE) where (c.ISCURRENT = 'Y' and c.ISDEALER = 'N' and c.REGIONALHUB in ('BLA', 'BLU', 'BLE', 'BBB', 'YY')) and ((pm.permission in ('A','B','M','Y') ) or ( (pm.permission is null or pm.permission ='P') and (pd.permission in ('A','B','M','Y') ) )) order by c.COMPANYNAME Asc nulls first , c.COMPANYNAME, cf.VAL_DATE asc ) A where rownum <= 30) B where rn > 1
зиг>
Вы позлобствовать пришли или как?
Я бы за такие джойны
inner join tableB_DEFAULT_PERMS pd on pd.dealer=12584 and pd.VALID ='Y' and зиг> (pd.START_DATE is null or '20150427' > pd.START_DATE) and(pd.END_DATE is null or '20150727' < pd.END_DATE) зиг> and pd.client=p.owner and ( (pd.bond_type=b.type and pd.bond_type in ('Sov','Corp','StatBody')) or......
руки отбил сразу
Здравствуйте, зиг, Вы писали:
зиг>Внимание, опубликую и запрос и ПЛАН сразу. хрен вам они помогут только гагага. зиг>Итак, проблема следующая. есть Запрос, который работает медленно если в первый раз запускаешь. Вторые и последующие запуски (даже с изменением параметров запроса) уже более-менее быстрые — то есть видать что-то там оракл кладет в кэш. Хотелось бы чтоб запрос работал более стабильно!
Это нормальная ситуация, ничего страшного в этом нет.
Это не значит, что запрос работает нестабильно.
зиг>План вообще какой-то неинформативный как по мне — кост очень небольшой. То есть непонятно что там улучшать, оно типа и так все хорошо.
Вполне возможно, что улучшать нечего.
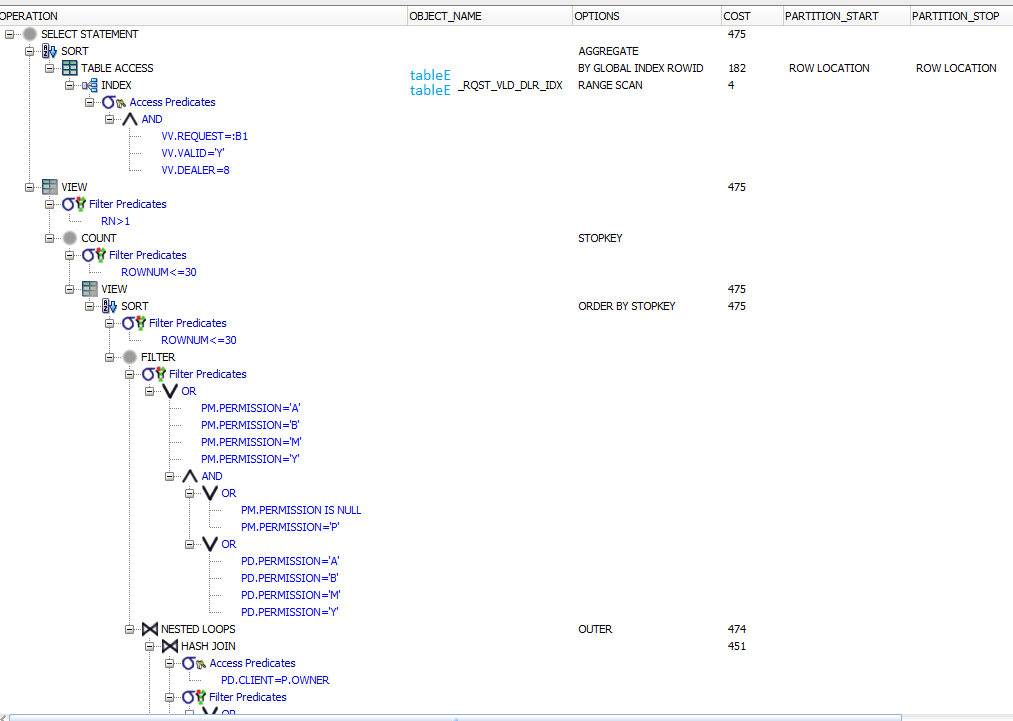
зиг>[cut=План (частичка, ибо длинный):]
Частичка -- это всё равно что нет плана.
Выложи план в текстовом виде, но ВЕСЬ, его можно там получить.
Здравствуйте, londinium, Вы писали:
L>Вы позлобствовать пришли или как? L>Я бы за такие джойны L>inner join tableB_DEFAULT_PERMS pd on pd.dealer=12584 and pd.VALID ='Y' and зиг>> (pd.START_DATE is null or '20150427' > pd.START_DATE) and(pd.END_DATE is null or '20150727' < pd.END_DATE) зиг>> and pd.client=p.owner and ( (pd.bond_type=b.type and pd.bond_type in ('Sov','Corp','StatBody')) or...... L>руки отбил сразу
для начала допустите что код писала не я и прекратите злобствтовать сами.
почему руки отбивать — из-за того что такие джойны плохо читаются или такие джойны на производительность _в ОРАКЛЕ_ влияет?
Здравствуйте, MasterZiv, Вы писали:
MZ>Здравствуйте, зиг, Вы писали:
зиг>>Внимание, опубликую и запрос и ПЛАН сразу. хрен вам они помогут только гагага. зиг>>Итак, проблема следующая. есть Запрос, который работает медленно если в первый раз запускаешь. Вторые и последующие запуски (даже с изменением параметров запроса) уже более-менее быстрые — то есть видать что-то там оракл кладет в кэш. Хотелось бы чтоб запрос работал более стабильно! MZ>Это нормальная ситуация, ничего страшного в этом нет. MZ>Это не значит, что запрос работает нестабильно.
мне кажется тут однозначно что-то не так. Еще заметки: в разных енвайронментах этот запрос работает по-разному. на продакшне лучше всего, а вот на девовском енв вообще супер медленно. hardware одинаковый
прямо чешется за что-нибудь напинать DBAщиков, такое ощущение что это во всем они виноваты. но мне нужны конкретные факты и обоснованные подозрения прежде чем к ним идти.
MZ>Частичка -- это всё равно что нет плана. MZ>Выложи план в текстовом виде, но ВЕСЬ, его можно там получить.
дело в том что самая гигантская таблица — это tableE, которая как раз вверху плана. ну и тотал кост тоже же виден. остальные таблицы настолько маленькие что ими всеми можно пренебречь. Алсо, если убрать вот эту подлую часть с этой таблицей Е:
( select max(vv.val_date) from tableE vv
where vv.REQUEST = p.PKEY and vv.VALID = 'Y' and vv.dealer=8
) as ASOF
то запрос начинает летать (ну как бы что и ожидалось).
И вообще меня больше волнует почему запрос работает медленно а кост у плана быстрый? разве тут не что-то не так?
Здравствуйте, Milena, Вы писали:
M>Опишу свои мысли: M>Несколько таблиц, вероятно больших, джойнятся между собой, а потом результат сильно усекается условиями, т.е. получается, например, 2.000X2.000=4.000.000 M>строк и потом условия по этому множеству дают всего 200 строчек, то есть 99% данных, выбранных из базы, на которые было истрачено время, просто M>выкидываются. Вместо этого проще перебрать условиями каждую из таблиц и потом джойнить маленькие остатки. Будет в разы быстрее. Например, вот этот кусок:
поняла вашу мысль. дело в том что я всегда думала что оракл не дурак и сам может оценить что вот по этим условиям вернется мало результатов, поэтому можно заранее их выполнить отдельно, а джойнить уже потом.
то есть оракл выступает не тупо интерпертатором того что написано в запросе и НЕ выполняет все согласно тому порядку в каких скобочках там что написал программист. а вначале анализирует запрос, и выполняет его все равно так как захочет. ну и погода на марсе
но я попробую поприменять это на практике..
ну и все равно в данном случае там все таблицы сравнительно маленькие кроме одной — tableE , и вся медленность возникает из-за этого кусочка:
(select max(vv.val_date) from tableE vv
where vv.REQUEST = p.PKEY and vv.VALID = 'Y' and vv.dealer=8
) as ASOF
Здравствуйте, зиг, Вы писали:
зиг>>Итак, проблема следующая. есть Запрос, который работает медленно если в первый раз запускаешь. Вторые и последующие запуски (даже с изменением параметров запроса) уже более-менее быстрые — то есть видать что-то там оракл кладет в кэш. Хотелось бы чтоб запрос работал более стабильно! зиг>>План вообще какой-то неинформативный как по мне — кост очень небольшой. То есть непонятно что там улучшать, оно типа и так все хорошо.
Так в чём проблема-то? Если только в этом, т.е. "кэш-не кэш" -- это вообще не проблема, и разговаривать не о чем.
О запросе и плане -- запрос непростой, и в него надо вникать, так сходу ничего не понятно, и надо знать данные и их
распределение, естественно.
Вот кстати он немного более аккуратно сформатированный:
select B.* from
(select A.*, rownum as rn from
(select C.COMPANYNAME, C.COMPANYID as CLIENT, P.INSTRUMENT, P.VALID_FROM, P.FREQUENCY, P.DETAILEDFREQUENCY, cf.VAL_DATE ,
(select max(vv.val_date)
from tableE vv
where vv.REQUEST = p.PKEY and vv.VALID = 'Y' and vv.dealer=8
) as ASOF
from tableN c
inner join tableD dp on c.companyId=dp.companyId and dp.dealer=8
inner join tableC p on p.VALID = 'Y' and p.SINGLE = 'Y' and p.OWNER = c.COMPANYID
inner join VM_CALENDAR_FREQUENCIES cf on cf.FREQUENCY=p.FREQUENCY and cf.DETAILEDFREQUENCY=p.DETAILEDFREQUENCY and cf.VAL_DATE between '20150427' and '20150427' and cf.REGIONALHUB in ('ALL',c.REGIONALHUB)
inner join VM_IDS i on i.ID_KEY = P.INSTRUMENT and i.VALID = 'Y'
inner join tableA b on i.BOND = b.PKEY and b.VALID = 'Y'
inner join tableB_DEFAULT_PERMS pd on pd.dealer=12584 and pd.VALID ='Y' and
(pd.START_DATE is null or '20150427' > pd.START_DATE) and(pd.END_DATE is null or '20150727' < pd.END_DATE)
and pd.client=p.owner and ( (pd.bond_type=b.type and pd.bond_type in ('Sov','Corp','StatBody'))
or ( pd.bond_type = 'Unclassified' and (b.type not in ('Sov','Corp','StatBody') or b.type is null ) )
)
left outer join tableB_REQUEST_PERMS pm on pm.instrument = p.instrument and pm.CLIENT = p.owner
and pm.DEALER = 12584
and pm.VALID = 'Y'
and pm.request_id=p.pkey
and (pm.START_DATE is null or '20150427' > pm.START_DATE)
and(pm.END_DATE is null or '20150427' < pm.END_DATE)
where (c.ISCURRENT = 'Y' and c.ISDEALER = 'N' and c.REGIONALHUB in ('BLA', 'BLU', 'BLE', 'BBB', 'YY'))
and ((pm.permission in ('A','B','M','Y') )
or ( (pm.permission is null or pm.permission ='P') and (pd.permission in ('A','B','M','Y') ) )
)
order by c.COMPANYNAME Asc nulls first, c.COMPANYNAME, cf.VAL_DATE asc ) A
where rownum <= 30) B
where rn > 1;
Очевидно, что в нём много альтернативных вариантов выполнения, от них нужно избавляться -- выполнять несколько разных запросов в разных случаях.
Также строковые литералы дат нужно оборачивать в to_date( но это к производительности не относится).
SARG-и только c.ISCURRENT = 'Y' and c.ISDEALER = 'N' and c.REGIONALHUB in ('BLA', 'BLU', 'BLE', 'BBB', 'YY')
Если они отбирают мало записей, то надо на них строить индексы и всё ОК,
если много -- ну, значит запрос такой.
Ну и ещё я бы уплощил бы запрос (убрал ненужные тут вложенные запросы ) или это пейджинг такой делается ? Тогда его надо на клиенте делать, а не так.
Если это не пейджинг, а аналитика, то для неё строк-то маловато, у тебя там HASH JOIN светится в куске плана -- это для 30 строк накладно,
тут можно ORDER индексом попробовать оптимизировать, и получать только 30 записей (ну или чуть больше).
зиг>ну то есть какой помощи от вас я прошу. не чтоб вы мне тут запрос переписали, или с индексами помогли — понятно что это невозможно без всех знаний всех таблиц и всего что там находится. зиг>мне нужен совет — в каком направлении пнуть наших DBA которые базу майнтейнят. может быть тут очевидная какая-то недоработка с их стороны? типа если кост запроса небольшой а фактически выполняется он долго — значит , я не знаю, статистика там хреново обновляется например. или что-нибудь аналогичное же. зиг>если б хотя бы план отображал действительную картину — тогда было бы уже легче инвестигировать. то есть я так понимаю проблему надо начинать решать с этой стороны?
Не похоже. Т.е. даже если статистика плоха, ты можешь всобачить HINT и статистика будет уже по-боку.
Явно тут напрашивается хинт first_rows(30), тогда может HASH JOIN уйдёт. Но надо весь план смотреть.
Здравствуйте, londinium, Вы писали:
L>Я бы за такие джойны
inner join tableB_DEFAULT_PERMS pd
on pd.dealer=12584
and pd.VALID ='Y'
and (pd.START_DATE is null or '20150427' > pd.START_DATE)
and (pd.END_DATE is null or '20150727' < pd.END_DATE)
and pd.client=p.owner
and ((pd.bond_type=b.type and pd.bond_type in ('Sov','Corp','StatBody')) or ...... )
L>руки отбил сразу
По-моему, это автосгенеренный запрос, т.е. поддерживать сам sql никто не собирается. Если нет — то это ппц конечно.
Ну а если автосгенеренный — что там в условиях в джойне такого страшного?
Оптимизатор в последних версия MS SQL такие извраты вполне нормально прожёвывает, планы условий джойна в from clause и в where clause как правило не отличаются.
С ораклом давно не работал, он менее терпим к записи условий как попало?
Единственно, если кто-то сдуру заменит inner на outer... от тогда руки действительно отрывать надо
Здравствуйте, зиг, Вы писали:
зиг>дело в том что самая гигантская таблица — это tableE, которая как раз вверху плана. ну и тотал кост тоже же виден.
Да он не очень и информативен. (total cost)
остальные таблицы настолько маленькие что ими всеми можно пренебречь. Алсо, если убрать вот эту подлую часть с этой таблицей Е: зиг>
зиг>( select max(vv.val_date) from tableE vv
зиг> where vv.REQUEST = p.PKEY and vv.VALID = 'Y' and vv.dealer=8
зиг> ) as ASOF
зиг>
зиг>то запрос начинает летать (ну как бы что и ожидалось).
Если в этой огромной таблице
tableE vv
на условия vv.REQUEST = p.PKEY and vv.VALID = 'Y' and vv.dealer=8
есть индекс и там мало записей по этому условию, то ничего страшного в этом нет.
зиг>И вообще меня больше волнует почему запрос работает медленно а кост у плана быстрый? разве тут не что-то не так?
cost лучше вообще не смотреть, я напр. даже не знаю, в каких попугаях он мериится.
Смотреть надо на cardinality.
Здравствуйте, зиг, Вы писали:
MZ>>Это не значит, что запрос работает нестабильно. зиг>мне кажется тут однозначно что-то не так.
Напротив, на этот счёт можете успокоится.
Стандартное 100% предстазуемое и неизбежное поведение.
Что два разных сервера работают по-разному -- тоже не сюрприз, разные данные -- разные планы.
зиг>поняла вашу мысль. дело в том что я всегда думала что оракл не дурак и сам может оценить что вот по этим условиям вернется мало результатов, поэтому можно заранее их выполнить отдельно, а джойнить уже потом.
Оракл -- не дурак. Можешь на этот счёт даже не беспокоиться.
Фактически совет тот процитированный -- общее место, которое может иметь место (извиняюсь за тавтологию) в данном случае, а может и не иметь.
Чтобы это проверить, надо по шагам плана идти от первого к последнему и смотреть cardinality на входе шага.
Если оно прыгает вверх, а потом вниз -- да, это оно. Если нет -- то нет.
т.е. в результате всеё равно надо смотреть план, данные и думать.
Про OR-ы в JOIN-ах вам тоже правильно сказали -- безобразие.
Надо их убирать. Проверяешь условие (на PL/SQL), и выполняешь такой запрос или другой.
Или генерация кода запроса в виде текста и EXECUTE IMEDIATE.
Здравствуйте, MasterZiv, Вы писали:
MZ>Да он не очень и информативен. (total cost)
поняла спс
MZ>остальные таблицы настолько маленькие что ими всеми можно пренебречь. Алсо, если убрать вот эту подлую часть с этой таблицей Е: зиг>>
зиг>>( select max(vv.val_date) from tableE vv
зиг>> where vv.REQUEST = p.PKEY and vv.VALID = 'Y' and vv.dealer=8
зиг>> ) as ASOF
зиг>>
зиг>>то запрос начинает летать (ну как бы что и ожидалось).
MZ>Если в этой огромной таблице MZ>tableE vv MZ>на условия vv.REQUEST = p.PKEY and vv.VALID = 'Y' and vv.dealer=8 MZ>есть индекс и там мало записей по этому условию, то ничего страшного в этом нет.
есть индекс, а на каждый отдельный vv.request — ну тяжело сказать мало или не мало. 5000 это мало?
MZ>cost лучше вообще не смотреть, я напр. даже не знаю, в каких попугаях он мериится. MZ>Смотреть надо на cardinality.
а как сделать чтоб кардиналити выводился?
пользуюсь pl/sql developer.
Здравствуйте, зиг, Вы писали:
зиг>Внимание, опубликую и запрос и ПЛАН сразу. хрен вам они помогут только гагага.
Довольно интересное отношение к аудитории. Попробую ответить в том же ключе.
зиг>Итак, проблема следующая. есть Запрос, который работает медленно если в первый раз запускаешь. Вторые и последующие запуски (даже с изменением параметров запроса) уже более-менее быстрые — то есть видать что-то там оракл кладет в кэш. Хотелось бы чтоб запрос работал более стабильно!
Внезапно, для таких убогих запросов так быть и должно.
Для тех, кто одарён ничего не знает о СУБД:
Когда СУБД получает запрос на SQL она не знает что с ним делать — может у вас есть индексы, может вы выбираете 100% записей из таблиц и т.д. Что бы понять, как оптимальным образом применить ресурсы сервера к именно вашим данным (ориентируясь на структуру запроса, статистики, структуру данных) СУБД строит кучу планов запросов соответствующих вашему SQL запросу и пытается найти наилучший из них. Прекращается это действо когда он найден (если запрос нормальный) или по таймауту (если запрос как выше + примерно тоже в структуре таблиц) когда найден квази оптимальный план. Когда вы выполняете запрос повторно, хотя возможно и с другими данными — наилучший план запроса уже найден и если он подходит (нет кардинальных отличий в селективности) то используется. Поэтому первый запрос выполняется медленней последующих.
Другой вопрос, что у нормальных DBA при вменяемых данных и запросах такого не происходит, поскольку число потенциальных планов мало ==> их перебор оказываться незаметен.
Как решить: проанализировать, на чем спотыкается оптимизатор и:
1. Упростить запрос (выше пример давали) сохранив его суть.
2. Добавить метаданные (индексы, статистику и т.д.) — кто его знает, что у вас в базе твориться
3. Добавить хинты (не ваш случай) 4. Обновить статистики
5. Прочитать наконец то книжку Тома Кайта.
Поскольку вы указываете на разницу между боевыми серверами и серверами разработки советую обратить внимание на 4 пункт, часто спотыкаются на нем.
Если планируете пользоваться инструментом, то его не плохо бы изучить, с этим может помочь пункт 5.
Здравствуйте, 11molniev, Вы писали:
1>Как решить: проанализировать, на чем спотыкается оптимизатор и: 1>1. Упростить запрос (выше пример давали) сохранив его суть.
чей конкретно пример вы имеете ввиду?
1>2. Добавить метаданные (индексы, статистику и т.д.) — кто его знает, что у вас в базе твориться
индексы все есть, статистика наверное должна вестись
1>3. Добавить хинты (не ваш случай)
наверное не наш, т.к. судя по плану индексы уже нужные используются
1>4. Обносить статистики 1>5. Прочитать наконец то книжку Тома Кайта.
1>Поскольку вы указываете на разницу между боевыми серверами и серверами разработки советую обратить внимание на 4 пункт, часто спотыкаются на нем. 1>Если планируете пользоваться инструментом, то его не плохо бы изучить, с этим может помочь пункт 5.
а что такое "Обносить статистики", как это по английски будет? пункт 5 мне без надобности, все равно меня к серверам и не допустят, у меня правов нет да я и не испытываю желания этим заниматься, у нас специальные люди для этого. только их надо пинать. щас вот пойду попинаю только скажите как будет по англиски.
а вообще погодите, вот вы там написали что происходит это все потому что оптимизатор пытается перебирает ищет нужный план выполнения. Но, когда я в сиквель девелопере запускаю просто посмотреть план запроса (тот самый который я в первом сообщение демонстрировала) — он его показывает мгновенно. какже так? противоречьице?
Здравствуйте, MasterZiv, Вы писали:
зиг>>поняла вашу мысль. дело в том что я всегда думала что оракл не дурак и сам может оценить что вот по этим условиям вернется мало результатов, поэтому можно заранее их выполнить отдельно, а джойнить уже потом. MZ>Оракл -- не дурак. Можешь на этот счёт даже не беспокоиться.
хыхы
MZ>Фактически совет тот процитированный -- общее место, которое может иметь место (извиняюсь за тавтологию) в данном случае, а может и не иметь. MZ>Чтобы это проверить, надо по шагам плана идти от первого к последнему и смотреть cardinality на входе шага.
MZ>Если оно прыгает вверх, а потом вниз -- да, это оно. Если нет -- то нет. MZ>т.е. в результате всеё равно надо смотреть план, данные и думать. MZ>Про OR-ы в JOIN-ах вам тоже правильно сказали -- безобразие.
ааа, так это было про ОР-ы.. а чем они плохи? влияют на производительность?
MZ>Надо их убирать. Проверяешь условие (на PL/SQL), и выполняешь такой запрос или другой.
а как это, не поняла?
Здравствуйте, Sinix, Вы писали:
S>По-моему, это автосгенеренный запрос, т.е. поддерживать сам sql никто не собирается. Если нет — то это ппц конечно. S>Ну а если автосгенеренный — что там в условиях в джойне такого страшного? S>Оптимизатор в последних версия MS SQL такие извраты вполне нормально прожёвывает, планы условий джойна в from clause и в where clause как правило не отличаются. S>С ораклом давно не работал, он менее терпим к записи условий как попало?
S>Единственно, если кто-то сдуру заменит inner на outer... от тогда руки действительно отрывать надо
извините что вклиниваюсь в вашу беседы про отрубание рук — а чем именно так плохи условия в данном запросе? при условии что таблица о которой речь крошечная (сравнительно). ну и в данном случае иннер с аутером будут одинаково работать.
Здравствуйте, зиг, Вы писали:
1>>1. Упростить запрос (выше пример давали) сохранив его суть. зиг>чей конкретно пример вы имеете ввиду?
Эта ветка: http://rsdn.ru/forum/db/6030605
1>>2. Добавить метаданные (индексы, статистику и т.д.) — кто его знает, что у вас в базе твориться зиг>индексы все есть, статистика наверное должна вестись
Важен не факт наличия индексов, а как они используются запросами.
Статистика то есть, вопрос в том насколько она актуальна.
1>>3. Добавить хинты (не ваш случай) зиг>наверное не наш, т.к. судя по плану индексы уже нужные используются
Не ваш, потому как их использование без полного понимания может привести к катастрофическому падению производительности. Но ими можно практически руками указать собственно план, тем самым сократив описанный мной процесс.
1>>4. Обносить статистики
1>>Поскольку вы указываете на разницу между боевыми серверами и серверами разработки советую обратить внимание на 4 пункт, часто спотыкаются на нем. 1>>Если планируете пользоваться инструментом, то его не плохо бы изучить, с этим может помочь пункт 5.
зиг>а что такое "Обносить статистики", как это по английски будет? пункт 5 мне без надобности, все равно меня к серверам и не допустят, у меня правов нет да я и не испытываю желания этим заниматься, у нас специальные люди для этого. только их надо пинать. щас вот пойду попинаю только скажите как будет по англиски.
Опечатка: обновить. Update statistics.
Книжка нужна, для понимания последствий своих запросов.
зиг>а вообще погодите, вот вы там написали что происходит это все потому что оптимизатор пытается перебирает ищет нужный план выполнения. Но, когда я в сиквель девелопере запускаю просто посмотреть план запроса (тот самый который я в первом сообщение демонстрировала) — он его показывает мгновенно. какже так? противоречьице?
Мало исходных данных.
Если такой запрос уже выполнялся (в том числе с другими данными) — план вы получили из описанного кеша ("аилучший план запроса уже найден и если он подходит то используется").
Если такого запрос не выполнялось, план получаем сразу, а первый запрос к реальным данным отрабатывает медленно ==> холодная база. Еще более канонический случай. Блоки данных которые надо прочесть отсутствуют в памяти (ещё не разу не читались с момента старта базы или были вытеснены более востребованными) — следствие их чтение из файлов/ASM, при последующих запросах, пока не будут вытеснены будут читаться из памяти ==> быстро.
S>>Единственно, если кто-то сдуру заменит inner на outer... от тогда руки действительно отрывать надо зиг> чем именно так плохи условия в данном запросе? при условии что таблица о которой речь крошечная (сравнительно).
Потому что запрос очень сложно поддерживать будет. Если код одноразовый или генерируется автоматически — всё ещё куда ни шло. Иначе тут целое поле граблей.
S>ну и в данном случае иннер с аутером будут одинаково работать.
для затравки:
SELECT * FROM A
INNER JOIN B ON A.Id = B.A_id
WHERE A.Name = '123' -- OK
-- =>SELECT * FROM A
LEFT JOIN B ON A.Id = B.A_id
WHERE A.Name = '123' -- OK
-- vsSELECT * FROM A
INNER JOIN B ON A.Id = B.A_id
AND A.Name = '123' -- so-so
-- =>SELECT * FROM A
LEFT JOIN B ON A.Id = B.A_id
AND A.Name = '123' -- oops
Если непонятно, в чём косяк с последним вариантом — запустите любой похожий запрос и посмотрите на результаты