У меня возникла следующая проблема: есть множество некоторых объектов. У каждого объекта есть некоторая информация о нем + достаточно большой (около 1000) массив чисел, который и характеризизует данный объект (некий внутренний дескриптор, отражающий форму объекта). Два объекта можно сравнить между собой, используя их дескрипторы, с помощью некой метрики (для простоты обычное евклидово расстояние). Надо реализовать следующее: от клиентской части приходит запрос в виде дескриптора. Серверная часть должна просмотреть все объекты и выдать обратно список объектов упорядоченный по увеличению расстояния до запроса (первые N элементов). Сразу скажу, что все числа в дескрипторе равнозначны и врядли можно придумать какой-то индекс для них. Они по сути сами являются индексом для формы объекта.
Т.е. в псевдокоде хочется получить что-то вроде: SELECT first N FROM table ORDER BY distance_to(query)
Собственно вопрос: как лучше это реализовать, если хранить дескрипторы в базе (а не просто в памяти). СУБД — пока что SQLite, но в дальнейшем возможен переход на MSSQL. Объектов в базе при среднем использовании 20-50.000 Но должно работать с приемлимой скоростью и на 100.000 объектов. Приемлимая скорость это 1-2 секунды для одного запроса при 20.000 объектов. И какие механизмы можно использовать для решения проблемы (хранимые процедуры, курсоры и т.д.)? Или все-таки самым простым выходом будет при инициализации приложения выбрать все дескрипторы в память и самому искать по ним? И кстати, какой расход памяти будет при использовании SQLite в таком случае? Ведь декрипторы будут и у меня в памяти и в базе.
_DK>Два объекта можно сравнить между собой, используя их дескрипторы, с помощью некой метрики (для простоты обычное евклидово расстояние).
это очень важно. если ваша реальная дистанция не является евклидовой (точнее его обобщением, не помню как завут) то многое из того что вам будут предлагать работать не будет.
но в целом если размерность пространства равна 1000 дело труба.
Что-то мне подсказывает, что база данных здесь нужна лишь для хранения информации (сериализации объектов) в промежутках между запусками приложения. Не?
Многие и рады были бы испытать когнитивный диссонанс, но нечем.
Re: Сложный поиск объектов в базе - Эталонный объект
_DK>Т.е. в псевдокоде хочется получить что-то вроде: SELECT first N FROM table ORDER BY distance_to(query)
Можно создать эталонный объект и предварительно вычислить расстояние до него для всех хранимых объектов. В запросе на выборку задавать не дескриптор, а расстояние до эталона.
Здравствуйте, paucity, Вы писали:
P>Здравствуйте, _DeKa_, Вы писали:
P>Что-то мне подсказывает, что база данных здесь нужна лишь для хранения информации (сериализации объектов) в промежутках между запусками приложения. Не?
Ну вообще-то любая база нужна для хранения информации в промежутках между запусками приложения, но это скорее философский вопрос. Мне было интересно, возможно ли сделать такой поиск какими-либо штатными средствами СУБД или нет?
Re[2]: Сложный поиск объектов в базе - Эталонный объект
Здравствуйте, dmotion, Вы писали:
_DK>>Т.е. в псевдокоде хочется получить что-то вроде: SELECT first N FROM table ORDER BY distance_to(query)
D>Можно создать эталонный объект и предварительно вычислить расстояние до него для всех хранимых объектов. В запросе на выборку задавать не дескриптор, а расстояние до эталона.
А не могли бы вы пояснить немного свою мысль? Т.е. допустим я создал какой-то абстрактный объект и вычислил расстояние от него до всех объектов в базе. Затем мне приходит реальный запрос на поиск. Я вычисляю расстояние от запроса до эталонного объекта и...? Дальше что?
Re[3]: Сложный поиск объектов в базе - Эталонный объект
_DK>А не могли бы вы пояснить немного свою мысль? Т.е. допустим я создал какой-то абстрактный объект и вычислил расстояние от него до всех объектов в базе. Затем мне приходит реальный запрос на поиск. Я вычисляю расстояние от запроса до эталонного объекта и...? Дальше что?
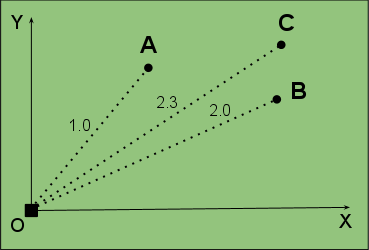
Набросок для двух измерений.
A, B — объекты в базе, координаты (x, y)
O — эталонный объект
C — объект-запрос
Пусть функцией будет расстояние объекта до O. Для A и B получим 1.0 и 2.0.
Пришёл запрос с объектом С. f(O, C) = 2.3. Вычисляем разницу (расстояние объекта С до ост. объектов):
CA = 2.3 — 1.0 = 1.3
CB = 2.3 — 2.0 = 0.3
=> объект С ближе к B, чем к A.
Результат можно формировать на сервере в виде (временной?) таблицы ключей-расстояний. Это если остановили свой выбор на SQL-базах. Клиенту возвращать шапку результата.
Здравствуйте, _DeKa_, Вы писали:
_DK>Т.е. в псевдокоде хочется получить что-то вроде: SELECT first N FROM table ORDER BY distance_to(query)
ООО! _DK>Собственно вопрос: как лучше это реализовать, если хранить дескрипторы в базе (а не просто в памяти). СУБД — пока что SQLite, но в дальнейшем возможен переход на MSSQL. Объектов в базе при среднем использовании 20-50.000 Но должно работать с приемлимой скоростью и на 100.000 объектов. Приемлимая скорость это 1-2 секунды для одного запроса при 20.000 объектов.
Ну, по большому счёту, современная наука для случая высоких размерностей ничего интересного предложить не может.
Для двух- и трёхмерного случая есть R-tree индексы; они немножко помогают. Но для высоких размерностей древовидные индексы быстро начинают сливать (АФАИК, уже при 10-12 измерениях линейный поиск получается быстрее).
Поэтому, если хочется получить реальное решение, то стоит копать в сторону оптимизации линейного просмотра.
Давайте прикинем: вот у нас 1*10^5 объектов, 1*10^3 атрибутов. Итого — 1*10^8. Если атрибуты вещественные, т.е. 8 байт, то характерный размер всей кучи — 10^9 байт, или около одного гига. В принципе, ничего военного при нынешних размерах ОП на серверах.
То есть, можно заточиться на то, что весь кэш помещается в память, и плясать от этого. Померьте, хватит ли современного процессора для обеспечения приемлемого быстродействия.
Преимущество решения — можно относительно быстро наколбасить прототип, который будет работать. Потом можно относительно неспешно заниматься оптимизацией серверной части, сохраняя протокол взаимодействия с клиентом.
Здравствуйте, dmotion, Вы писали:
_DK>>А не могли бы вы пояснить немного свою мысль? Т.е. допустим я создал какой-то абстрактный объект и вычислил расстояние от него до всех объектов в базе. Затем мне приходит реальный запрос на поиск. Я вычисляю расстояние от запроса до эталонного объекта и...? Дальше что?
D>Набросок для двух измерений. D>
D>A, B — объекты в базе, координаты (x, y) D>O — эталонный объект D>C — объект-запрос
D>Пусть функцией будет расстояние объекта до O. Для A и B получим 1.0 и 2.0. D>Пришёл запрос с объектом С. f(O, C) = 2.3. Вычисляем разницу (расстояние объекта С до ост. объектов): D>CA = 2.3 — 1.0 = 1.3 D>CB = 2.3 — 2.0 = 0.3 D>=> объект С ближе к B, чем к A.
D>Результат можно формировать на сервере в виде (временной?) таблицы ключей-расстояний. Это если остановили свой выбор на SQL-базах. Клиенту возвращать шапку результата.
Вы меня, конечно, извините, но предложенный вами алгоритм не сильно рабочий. Простой пример: точка А(1,0), точка В(0,2). Тогда ОА=1, ОВ=2. Берем точку С(2,0), ОС=2. Считаем расстояния: |ОА-ОС|=1, |OB-OC|=0. Из ваших рассуждений следует, что точка С намного ближе к В, чем к А, что в корне неверно.
Здравствуйте, Sinclair, Вы писали:
S>Ну, по большому счёту, современная наука для случая высоких размерностей ничего интересного предложить не может. S>Для двух- и трёхмерного случая есть R-tree индексы; они немножко помогают. Но для высоких размерностей древовидные индексы быстро начинают сливать (АФАИК, уже при 10-12 измерениях линейный поиск получается быстрее).
Полностью согласен!
S>Поэтому, если хочется получить реальное решение, то стоит копать в сторону оптимизации линейного просмотра. S>Давайте прикинем: вот у нас 1*10^5 объектов, 1*10^3 атрибутов. Итого — 1*10^8. Если атрибуты вещественные, т.е. 8 байт, то характерный размер всей кучи — 10^9 байт, или около одного гига. В принципе, ничего военного при нынешних размерах ОП на серверах. S>То есть, можно заточиться на то, что весь кэш помещается в память, и плясать от этого. Померьте, хватит ли современного процессора для обеспечения приемлемого быстродействия. S>Преимущество решения — можно относительно быстро наколбасить прототип, который будет работать. Потом можно относительно неспешно заниматься оптимизацией серверной части, сохраняя протокол взаимодействия с клиентом.
Собственно говоря, это уже сейчас сделано и нормально работает на тестах. Т.е. все дескрипторы нормально помещаются в память и скорость линейного сравнения, в принципе, устраивает.
Просто у каждого объекта есть еще информация, которая очень хорошо ложится в реляционную структуру. Поэтому и возникла идея все хранить в БД вместе с дескрипторами. Т.е. вопрос в следующем: можно ли организовать такой же линейный поиск, если данные лежат именно в таблице БД? И что конкретно использовать?
S>Дальше я бы копал в сторону кластерного анализа. В первую очередь — в сторону иерархической кластеризации. http://en.wikipedia.org/wiki/Hierarchical_clustering, S>http://www.cs.gsu.edu/~wkim/index_files/papers/sibson.pdf
Это тоже понятно, но с иерархической кластеризацией проблема в том, что при каждом добавлении нового объекта надо перестраивать дерево (в теории дерево может полностью измениться). Кроме того, для ее расчета необходима матрица расстояний каждый с каждым (ну либо пересчет на каждом шаге). При большом количестве объектов это не влезет ни в память, ни в адекватное время. Поправьте меня, если я ошибаюсь.
Здравствуйте, _DeKa_, Вы писали:
_DK>Собственно говоря, это уже сейчас сделано и нормально работает на тестах. Т.е. все дескрипторы нормально помещаются в память и скорость линейного сравнения, в принципе, устраивает. _DK>Просто у каждого объекта есть еще информация, которая очень хорошо ложится в реляционную структуру. Поэтому и возникла идея все хранить в БД вместе с дескрипторами. Т.е. вопрос в следующем: можно ли организовать такой же линейный поиск, если данные лежат именно в таблице БД? И что конкретно использовать?
Если вы используете что-то постреляционное, например MS SQL, то есть возможность определить custom datatypes и в них реализовать свои функции сравнения. Всё равно будет медленнее, чем в чистой памяти, но может работать более-менее приемлемо.
Для остальных бы ситуаций я бы рекомендовал просто держать в памяти write-through кэш, который поднимать при необходимости из базы.
_DK>Это тоже понятно, но с иерархической кластеризацией проблема в том, что при каждом добавлении нового объекта надо перестраивать дерево (в теории дерево может полностью измениться).
Полностью — вряд ли. Это из интуитивных соображений. Но я могу ошибаться.
_DK>Кроме того, для ее расчета необходима матрица расстояний каждый с каждым (ну либо пересчет на каждом шаге).
Ну, если всё более-менее хорошо, то высоки шансы быстро найти один из существующих кластеров и вставиться в него.
Тут же всё сильно зависит от частоты изменений относительно запросов на поиск — "индексы" всегда ускоряют чтения и замедляют записи.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[5]: Сложный поиск объектов в базе - Эталонный объект
_DK>Вы меня, конечно, извините, но предложенный вами алгоритм не сильно рабочий. Простой пример: точка А(1,0), точка В(0,2). Тогда ОА=1, ОВ=2. Берем точку С(2,0), ОС=2. Считаем расстояния: |ОА-ОС|=1, |OB-OC|=0. Из ваших рассуждений следует, что точка С намного ближе к В, чем к А, что в корне неверно.
Здравствуйте, Аноним, Вы писали:
А>простите невежество, это не Kd-tree?
K-d-tree — это только один из вариантов кластеризации. Не очень хороший.
As a general rule, if the dimensionality is k, the number of points in the data, N, should be N >> 2k. Otherwise, when k-d trees are used with high-dimensional data, most of the points in the tree will be evaluated and the efficiency is no better than exhaustive search,[4] and approximate nearest-neighbour methods are used instead.
R-tree — другой способ кластеризации; при нём вместо деления гиперпространства гиперплоскостями используются ограничивающие параллелепипеды.
Есть для высоких размерностей (наш случай) ещё X-tree; но я про них даже не читал
Уйдемте отсюда, Румата! У вас слишком богатые погреба.