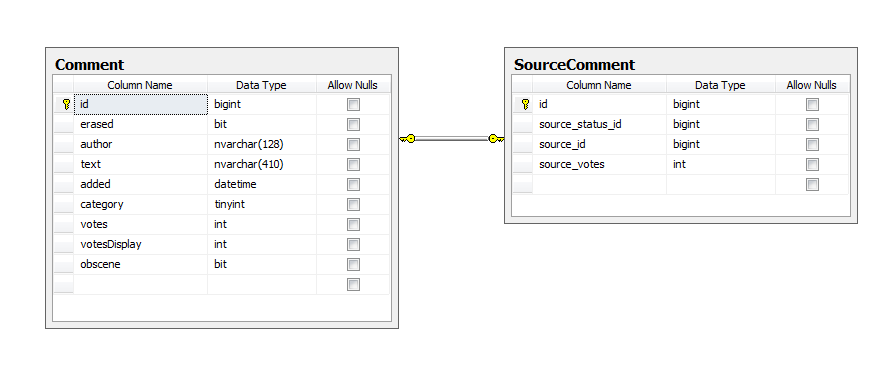
Есть БД. Сразу приведу ее схему:
Есть два похожих запроса, под которые нужно оптимизировать скорость выборки.
Под один получается оптимизировать, под второй — нет.
Вот собственно эти запросы:
1. Выполняется примерно за 10мс, что меня полностью устраивает.
Для него построен кластерный индекс.
set statistics time on;
SELECT TOP (15) *
FROM (select comment.*,
sourceComment.source_id as source_id,
sourceComment.source_status_id as source_status_id,
sourceComment.source_votes as source_votes,
ROW_NUMBER() OVER (ORDER BY [votesDisplay] DESC, added DESC) as sortColumn
from SourceComment sourceComment
inner join Comment comment
on sourceComment.id=comment.Id
where comment.erased=0
and comment.added>='2008-08-01 00:00:00'
and comment.added<'2010-12-04 00:00:00'
and (1=0 or comment.category=17)) as query /* эта запись означает, что категории может не быть */WHERE query.sortColumn > 3500
ORDER BY query.sortColumn
set statistics time off
2. Выполняется несколько секунд. Пробовал разные индексы, но это лучшее чего я смог добиться.
set statistics time on;
SELECT TOP (15) author,
sumVotes
FROM (select author,
SUM(votesDisplay) as sumVotes,
ROW_NUMBER() OVER(ORDER BY SUM(votesDisplay) DESC) as sortColumn
from Comment comment
where Erased = 0
and author != 'Аноним'
and Added >= '2008-08-18 00:00:00'
and Added < '2010-12-05 00:00:00'
group by author) as query
WHERE query.sortColumn > 3500
ORDER BY query.sortColumn
set statistics time off
Cкрипт для создания таблиц и индексов.
/* -------- Основная таблица. ~700k записей. */CREATE TABLE [Comment](
[id] [bigint] IDENTITY(1,1) NOT NULL,
[erased] [bit] NOT NULL,
[author] [nvarchar](128) NOT NULL,
[text] [nvarchar](410) NOT NULL,
[added] [datetime] NOT NULL,
[category] [tinyint] NOT NULL,
[votes] [int] NOT NULL,
[votesDisplay] [int] NOT NULL,
[obscene] [bit] NOT NULL,
CONSTRAINT [PK__STATUS] PRIMARY KEY NONCLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
/* -------- Вторая таблица */CREATE TABLE [SourceComment](
[id] [bigint] NOT NULL,
[source_status_id] [bigint] NOT NULL,
[source_id] [bigint] NOT NULL,
[source_votes] [int] NOT NULL,
CONSTRAINT [PK__SOURCESTATUS] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
/* -------- Foreign Key со второй таблицы на основную */ALTER TABLE [SourceComment] WITH CHECK ADD CONSTRAINT [FK__SOURCES_REFERENCE__STATUS] FOREIGN KEY([id])
REFERENCES [Comment] ([id])
GO
ALTER TABLE [SourceComment] CHECK CONSTRAINT [FK__SOURCES_REFERENCE__STATUS]
GO
/* -- ИНДЕКСЫ -- */
/* -------- Таблица [Comment] - кластерный индекс. */CREATE CLUSTERED INDEX [erased_category_votesDisplay_added_author] ON [Comment]
(
[erased] ASC,
[votesDisplay] DESC,
[added] DESC,
[author] DESC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
/* -------- Таблица [Comment] - не кластерный индекс. Нужен для запроса, который здесь не упоминается, но для полноты картины решил его привести */CREATE NONCLUSTERED INDEX [added] ON [Comment]
(
[added] DESC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
/* -------- Таблица [SourceComment] - не кластерный индекс. */CREATE UNIQUE NONCLUSTERED INDEX [id_in_source__and__source_id_index] ON [SourceComment]
(
[source_status_id] DESC,
[source_id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
Здравствуйте, Снег, Вы писали:
С>Я бы для начала посмотрел на план подзапроса, предварительно выкинув из него ROW_NUMBER.
Да, забыл сказать — у меня что-то сломалось в SQL Server'е и при попытке построить план выполнения (предполагаемый или актуальный)
вместо плана я вижу текст с ошибкой:
ROW_NUMBER нужен, т.к. запрос используется для получения страниц данных.
Может можно как-то без ROW_NUMBER, но я не знаю как.
Здравствуйте, Ocenochka, Вы писали:
O> Да, забыл сказать — у меня что-то сломалось в SQL Server'е и при попытке построить план выполнения (предполагаемый или актуальный) O> вместо плана я вижу текст с ошибкой:
Не могу найти сборку XXXX.dll.
Здравствуйте, Ocenochka, Вы писали:
O>1. Выполняется примерно за 10мс, что меня полностью устраивает. O> Для него построен кластерный индекс.
Есть подозрение, что этот запрос будет выполняться медленно в следующих случаях:
1) Когда требуемый номер начальной записи очень большой (например, query.sortColumn > 600000).
2) Когда в диапазон дат попадает очень мало записей либо sourceComment содержит мало записей, и значения поля votesDisplay в этих записях равномерно распределены по всему диапазону.
Проверять скорость выполнения нужно под нагрузкой, иначе сервер закэширует все данные в памяти, и время считывания с диска не будет учитываться. Нагрузку можно сымитировать, ограничив доступную серверу память или сделав рестарт сервера.
O>2. Выполняется несколько секунд. Пробовал разные индексы, но это лучшее чего я смог добиться.
Индексы практически не помогут, так как для вычисления этого запроса требуется обращение ко всем записям таблицы. Максимум, что можно сделать, это вынести поле author в отдельную таблицу, а в основной таблице оставить ссылку на автора через author_id, и сделать индекс по (erased, author_id, votesDisplay, added). Но сильного улучшения это не даст.
Если бы не было условия, ограничивающего выбор записей по дате, тогда можно было бы существенно ускорить этот запрос, используя материализованные представления.
Здравствуйте, Sergei MO, Вы писали:
SM>Здравствуйте, Ocenochka, Вы писали:
O>>1. Выполняется примерно за 10мс, что меня полностью устраивает. O>> Для него построен кластерный индекс.
SM>Есть подозрение, что этот запрос будет выполняться медленно в следующих случаях: SM>1) Когда требуемый номер начальной записи очень большой (например, query.sortColumn > 600000).
Да, есть такое. В моем случае sortColumn > 600000 CPU time = 2246 ms.
SM>2) Когда в диапазон дат попадает очень мало записей либо sourceComment содержит мало записей, и значения поля votesDisplay в этих записях равномерно распределены по всему диапазону.
Это не смог воспроизвести.
SM>Проверять скорость выполнения нужно под нагрузкой, иначе сервер закэширует все данные в памяти, и время считывания с диска не будет учитываться. Нагрузку можно сымитировать, ограничив доступную серверу память или сделав рестарт сервера.
База сейчас со всеми индексами ~400 МБ. Сильно расти не планирует, так что пока можно считать что она вся в оперативке.
Но если можно как-то это дело исправить без потери производительности, то с удовольствием попробую.
O>>2. Выполняется несколько секунд. Пробовал разные индексы, но это лучшее чего я смог добиться.
SM>Индексы практически не помогут, так как для вычисления этого запроса требуется обращение ко всем записям таблицы. Максимум, что можно сделать, это вынести поле author в отдельную таблицу, а в основной таблице оставить ссылку на автора через author_id, и сделать индекс по (erased, author_id, votesDisplay, added). Но сильного улучшения это не даст. SM>Если бы не было условия, ограничивающего выбор записей по дате, тогда можно было бы существенно ускорить этот запрос, используя материализованные представления.
Значит ничего нельзя сделать?
Вообще, в моем случае число диапазонов фиксированное (за все время, по годам, по месяцам, по дням), то за три года = 365*3 + 12*3 + 3 + 1 ~= 1100 диапазонов, но
как я понимаю это не сильно облегчает дело, т.к. на все диапазоны индексы не построить.
Здравствуйте, Снег, Вы писали:
С>Ну тогда хотя бы скажите, сколько строк отдают подзапросы query в обоих случаях. С>И сколько времени каждый из них работает.
В зависимости от указанного диапазона дат.
Если брать за весь диапазон (не ограничивать по дате) то:
Подзапрос первого запроса работает 22 секунды, возвращает все записи (~700k)
второго — работает около 1 секунды, возвращает ~100k.
(ограничивал оперативку до 128 МБ)
Люблю ставить оценки.
Re: [MSSQL] Как оптимизировать запрос?
От:
Аноним
Дата:
18.12.10 12:13
Оценка:
Здравствуйте, Ocenochka, Вы писали:
O>2. Выполняется несколько секунд. Пробовал разные индексы, но это лучшее чего я смог добиться.
O>
O>set statistics time on;
O>SELECT TOP (15) author,
O> sumVotes
O>FROM (select author,
O> SUM(votesDisplay) as sumVotes,
O> ROW_NUMBER() OVER(ORDER BY SUM(votesDisplay) DESC) as sortColumn
O> from Comment comment
O> where Erased = 0
O> and author != 'Аноним'
O> and Added >= '2008-08-18 00:00:00'
O> and Added < '2010-12-05 00:00:00'
O> group by author) as query
O>WHERE query.sortColumn > 3500
O>ORDER BY query.sortColumn
O>set statistics time off
O>
set statistics time on;
SELECT author,
sumVotes
FROM (select author,
SUM(votesDisplay) as sumVotes,
ROW_NUMBER() OVER(ORDER BY SUM(votesDisplay) DESC) as sortColumn
from Comment comment
where Erased = 0
and author != 'Аноним'
and Added >= '2008-08-18 00:00:00'
and Added < '2010-12-05 00:00:00'
group by author) as query
WHERE query.sortColumn > 3500 and query.sortColumn < 3516
set statistics time off
O> В зависимости от указанного диапазона дат. O> Если брать за весь диапазон (не ограничивать по дате) то:
Отбор по дате лучше оставить, если именно такой вариант используется в "боевой" системе.
Я так понимаю, проблема в переборе всех строк таблицы при отборе по дате вставки.
Я бы попробовал следущее:
1) создать индекс по id и added
2) написать подзапрос вида
select id from Comment where Added >= '2008-08-18 00:00:00' and Added < '2010-12-05 00:00:00'
выборка данных должна происходить из индекса (и работать быстро)
3) если такой подзапрос работает быстро, то остается переписать подзапрос query, заменив "and Added >= and Added < " на подзапрос из п.2
Здравствуйте, Ocenochka, Вы писали:
O> Но если можно как-то это дело исправить без потери производительности, то с удовольствием попробую.
В первом запросе лучше вынести join из подзапроса во внешний запрос, тогда подзапрос будет работать только по одному индексу.
И обязательно что-нибудь придумать с просмотром планов. Ну хотя бы использовать SET STATISTICS PROFILE ON.
O> Значит ничего нельзя сделать? O> Вообще, в моем случае число диапазонов фиксированное (за все время, по годам, по месяцам, по дням), то за три года = 365*3 + 12*3 + 3 + 1 ~= 1100 диапазонов, но O> как я понимаю это не сильно облегчает дело, т.к. на все диапазоны индексы не построить.
Можно использовать разные запросы, в зависимости от диапазона дат. Для одиночных дней количество записей будет очень ограниченным, поэтому можно построить запрос так, чтобы он сначала выбирал все записи за нужный день, а потом выполнял их анализ. Для месяцев, годов и всего времени построить соответствующее материализованное представление. Для 40 диапазонов это будет вполне нормально.
Я так понимаю, что различных авторов не очень много — порядка нескольких тысяч, плюс Аноним.
O>> Но если можно как-то это дело исправить без потери производительности, то с удовольствием попробую. SM>В первом запросе лучше вынести join из подзапроса во внешний запрос, тогда подзапрос будет работать только по одному индексу.
Помогло. При запросе с sortColumn > 600000 стало быстрее в три раза.
SM>И обязательно что-нибудь придумать с просмотром планов. Ну хотя бы использовать SET STATISTICS PROFILE ON.
Спасибо, не знал про это. Только пока знаний не хватает использовать эту информацию. Надо будет поэкспериментировать.
SM>Можно использовать разные запросы, в зависимости от диапазона дат. Для одиночных дней количество записей будет очень ограниченным, поэтому можно построить запрос так, чтобы он сначала выбирал все записи за нужный день, а потом выполнял их анализ. Для месяцев, годов и всего времени построить соответствующее материализованное представление. Для 40 диапазонов это будет вполне нормально.
Ясно, спасибо, буду пробовать.
SM>Я так понимаю, что различных авторов не очень много — порядка нескольких тысяч, плюс Аноним.
Здравствуйте, Аноним, Вы писали:
O>>2. Выполняется несколько секунд. Пробовал разные индексы, но это лучшее чего я смог добиться.
А>
А>set statistics time on;
А>SELECT author,
А> sumVotes
А>FROM (select author,
А> SUM(votesDisplay) as sumVotes,
А> ROW_NUMBER() OVER(ORDER BY SUM(votesDisplay) DESC) as sortColumn
А> from Comment comment
А> where Erased = 0
А> and author != 'Аноним'
А> and Added >= '2008-08-18 00:00:00'
А> and Added < '2010-12-05 00:00:00'
А> group by author) as query
А>WHERE query.sortColumn > 3500 and query.sortColumn < 3516
А>set statistics time off
А>
Спасибо! Так действительно стало в три раза быстрее.
Здравствуйте, Снег, Вы писали:
O>> В зависимости от указанного диапазона дат. O>> Если брать за весь диапазон (не ограничивать по дате) то: С>Отбор по дате лучше оставить, если именно такой вариант используется в "боевой" системе. С>Я так понимаю, проблема в переборе всех строк таблицы при отборе по дате вставки. С>Я бы попробовал следущее: С>1) создать индекс по id и added
Т.е. один индекс по двум полям в указанном порядке?
Уже есть два отдельных индекса на id и на added.
С>2) написать подзапрос вида С>
С>select id from Comment where Added >= '2008-08-18 00:00:00' and Added < '2010-12-05 00:00:00'
С>
С>выборка данных должна происходить из индекса (и работать быстро)
Разве имеющихся индексов:
1. id
2. added
3. erased_votesDisplay_added_author
не достаточно?
С>3) если такой подзапрос работает быстро, то остается переписать подзапрос query, заменив "and Added >= and Added < " на подзапрос из п.2
Честно говоря, не понял идею. Не могли бы Вы объяснить по шагам что мне нужно сделать?
Здравствуйте, Ocenochka, Вы писали:
O>Здравствуйте, Аноним, Вы писали:
O>>>2. Выполняется несколько секунд. Пробовал разные индексы, но это лучшее чего я смог добиться.
А>>
А>>set statistics time on;
А>>SELECT author,
А>> sumVotes
А>>FROM (select author,
А>> SUM(votesDisplay) as sumVotes,
А>> ROW_NUMBER() OVER(ORDER BY SUM(votesDisplay) DESC) as sortColumn
А>> from Comment comment
А>> where Erased = 0
А>> and author != 'Аноним'
А>> and Added >= '2008-08-18 00:00:00'
А>> and Added < '2010-12-05 00:00:00'
А>> group by author) as query
А>>WHERE query.sortColumn > 3500 and query.sortColumn < 3516
А>>set statistics time off
А>>
O> Спасибо! Так действительно стало в три раза быстрее.
Да не за что. Правда есть НО: в таком запросе порядок возвращаемых записей может быть разным. Если важно чтоб эти 15 записей возвращались отсортированными по sortColumn то надо добавить order by. Для 15 записей он не должен привести к заметному уменьшению времени запроса.
O> Т.е. один индекс по двум полям в указанном порядке? O> Уже есть два отдельных индекса на id и на added.
Отдельные индексы не помогут. Поиск по индексу (колонки индекса покрывают запрос) выполняется без обращения к самой таблице, что в ряде случаев сокращает время выполнения.
O> Честно говоря, не понял идею. Не могли бы Вы объяснить по шагам что мне нужно сделать?
А надо? Как я понял, задча уже решена.
Здравствуйте, Снег, Вы писали:
O>> Честно говоря, не понял идею. Не могли бы Вы объяснить по шагам что мне нужно сделать? С>А надо? Как я понял, задча уже решена.
Скорее появилось понимание, что ее не решить с помощью индексов.