Здравствуйте, MitjaT, Вы писали:
MT>Здравствуйте!
MT>Как вам такой письменный вопрос на собеседовании? MT>Как правильно на него ответить?
MT>
MT>Чем плох такой запрос? Как можно его оптимизировать?
MT>select T1.F1, T2.F1
MT>from Table1 T1
MT>left join Table2 T2 on T1.F2=T2.F2 or T1.F3=T2.F3
or в джойне.
select
T1.F1,
T2.F1
from
Table1 T1
left join
Table T2
on
T1.F2 = T2.F2
union all
select
T1.F1,
T2.F1
from
Table1 T1
left join
Table T2
on
T1.F3 = T2.F3
;
Re[2]: Вопрос на собеседовании (как надо было ответить?)
Здравствуйте, _d_m_, Вы писали:
___>or в джойне.
___>
___>select
___> T1.F1,
___> T2.F1
___>from
___> Table1 T1
___> left join
___> Table T2
___> on
___> T1.F2 = T2.F2
___>union all
___>select
___> T1.F1,
___> T2.F1
___>from
___> Table1 T1
___> left join
___> Table T2
___> on
___> T1.F3 = T2.F3
___>;
___>
Результат может быть неверным. В результирующий набор может попасть дважды одна и та же строка из декартова произведения двух таблиц, в том случае, если T1.F2 = T2.F2 and T1.F3 = T1.F3.
Надо в этом случае дополнительно ввести условие, что "сведет на нет" такую оптимизацию.
Re[3]: Вопрос на собеседовании (как надо было ответить?)
Здравствуйте, MitjaT, Вы писали: MT>Надо в этом случае дополнительно ввести условие, что "сведет на нет" такую оптимизацию.
Сведет ли? Насколько я понимаю, or может помешать использовать при джойне индексы, что (в случае больших исходных таблиц и небольшого предполагаемого количества строк в результате) значительно сильнее ударит по перфомансу, чем необходимость выбрать distinct из результата юниона.
Чем гадать — лучше бы поглядели план запроса на интересующей Вас базе и запостили сюда.
Re[4]: Вопрос на собеседовании (как надо было ответить?)
Здравствуйте, MitjaT, Вы писали: MT>Запросы идентичны.
Вот и ответ. MSSQL может припахать индексы при or. Возможно, так могут не все базы, и в этом была суть вопроса. Или от Вас хотели услышать, что в общем и целом сложные функции в условии джойна стоит вручную упрощать.
Или мы действительно не туда копаем.
Re[2]: Вопрос на собеседовании (как надо было ответить?)
Здравствуйте, MitjaT, Вы писали:
MT>Как вам такой письменный вопрос на собеседовании?
Смотря на какую позицию, может конкретно разработчик баз данных и должен знать, остальные — сомневаюсь.
MT>Чем плох такой запрос?
Хз.
MT>Как можно его оптимизировать?
Хз.
В общем лично я бы на вопрос не ответил, если вам интересно такое мнение со стороны.
Re[3]: Вопрос на собеседовании (как надо было ответить?)
Здравствуйте, nikov, Вы писали:
N>Здравствуйте, _d_m_, Вы писали:
___>>or в джойне.
N>Неужто оптимизатор сам не просекает?
ИИ?
Запрос на самом деле уродский — этакий сферический конь в вакууме, такой в реальной жизни не встречался мне никогда. Такую структуру данных даже не придет в голову создать начинающему разработчику с особо извращенной фантазией.
Re[4]: Вопрос на собеседовании (как надо было ответить?)
Здравствуйте, ilya_ny, Вы писали:
_>>неверно, это не эквивалентные запросы
Ах да, извиняюсь поспешил. Ладно, вот вам пища для размышлений:
DDL:
CREATE TABLE dbo.Table1(
F1 int NOT NULL IDENTITY (1, 1),
F2 int NOT NULL,
F3 int NOT NULL
)
GO
ALTER TABLE dbo.Table1 ADD CONSTRAINT PK_Table1 PRIMARY KEY CLUSTERED (F1)
GO
CREATE TABLE dbo.Table2(
F1 int NOT NULL IDENTITY (1, 1),
F2 int NOT NULL,
F3 int NOT NULL
)
GO
ALTER TABLE dbo.Table2 ADD CONSTRAINT PK_Table2 PRIMARY KEY CLUSTERED (F1)
GO
CREATE NONCLUSTERED INDEX [IX_Table2.F2] ON dbo.Table2 (F2)
GO
CREATE NONCLUSTERED INDEX [IX_Table2.F3] ON dbo.Table2 (F3)
GO
Наполнение данными:
set nocount on;
GO
-- Создаем записи которые не будут попадать под условие запросаdeclare @i int;
set @i = 0;
begin tran;
while @i < 90000 begin
insert Table2(F2, F3) values(@i, @i + 100000);
set @i = @i + 1;
end;
commit;
insert
Table1(
F2,
F3
)
select top 2000
F2 + 200000,
F2 + 300000
from
Table2
order by
F1
;
-- Создаем записи которые будут попадать под условие запроса F2 = F2set @i = 90000;
begin tran;
while @i < 92000 begin
insert Table1(F2, F3) values(@i, @i + 100000);
insert Table2(F2, F3) values(@i, @i + 200000);
set @i = @i + 1;
end;
commit;
-- Создаем записи которые будут попадать под условие запроса F3 = F3set @i = 92000;
begin tran;
while @i < 94000 begin
insert Table1(F2, F3) values(@i + 100000, @i);
insert Table2(F2, F3) values(@i + 200000, @i);
set @i = @i + 1;
end;
commit;
-- Создаем записи которые будут попадать под условие запроса F2 = F2 = F3 = F3set @i = 94000;
begin tran;
while @i < 96000 begin
insert Table1(F2, F3) values(@i, @i);
insert Table2(F2, F3) values(@i, @i);
set @i = @i + 1;
end;
commit;
Запросы (исходный и эквивалентный более правильный):
select
T1.F1,
T2.F1
from
Table1 T1
left join
Table2 T2
on
T1.F2 = T2.F2 or T1.F3 = T2.F3
;
select
T1F1,
max(T2F1)
from
(select
T1.F1 as T1F1,
T2.F1 as T2F1
from
Table1 T1
inner join
Table2 T2
on
T1.F2 = T2.F2
union all
select
T1.F1,
T2.F1
from
Table1 T1
inner join
Table2 T2
on
T1.F3 = T2.F3
union all
select
T1.F1,
null
from
Table1 T1
) as T
group by
T1F1
;
А теперь план. Исходный запрос выполнялся более 5 мин, эквивалентный правильный — менее секунды:
Re[5]: Вопрос на собеседовании (как надо было ответить?)
Здравствуйте, MitjaT, Вы писали:
MT>Здравствуйте, Mr.Cat, Вы писали:
MC>>Чем гадать — лучше бы поглядели план запроса на интересующей Вас базе и запостили сюда.
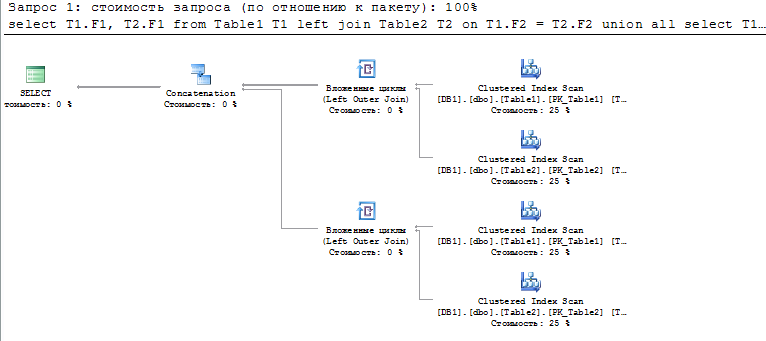
MT>Пожалуйста: MT> MT>
MT>Запросы идентичны.
Неверно.
Вот первых: Чтобы сравнить запросы их надо ставить в одном батче.
Во вторых: Что с индексами? Там кроме кластерного суррогатного первичного ключа, по моему больше нихрена нет.
Re[6]: Вопрос на собеседовании (как надо было ответить?)
Здравствуйте, Mr.Cat, Вы писали:
MC>Здравствуйте, MitjaT, Вы писали: MT>>Запросы идентичны.
Нет.
MC>Вот и ответ. MSSQL может припахать индексы при or. Возможно, так могут не все базы, и в этом была суть вопроса. Или от Вас хотели услышать, что в общем и целом сложные функции в условии джойна стоит вручную упрощать.
Где индексы? Там на планах сканирование кластерного индекса == сканирование таблицы.
MC>Или мы действительно не туда копаем.
Это — да.
Re[5]: Вопрос на собеседовании (как надо было ответить?)
MitjaT пишет:
> Чем плох такой запрос? Как можно его оптимизировать? > > select T1.F1, T2.F1 > from Table1 T1 > left join Table2 T2 on T1.F2=T2.F2 or T1.F3=T2.F3
плох тем, что JOIN по OR может быть плохо воспринят
оптимизатором и не будет использован индекс при выполнении JOIN-а.
Но это — только один из возможных вариантов
развития событий. Думаю, многие оптимизаторы поймут эту
ситуацию правильно и сами сделают правильную переформулировку запроса.
Кроме того, ещё всё зависит от расклада данных в таблицах,
для каких -то раскладов данных даже если не будет использован
индекс при JOIN-е, ничего страшного не произойдёт.
Так что вопрос, если говорить строго формально, не правомерен.
Но если при этом сделать огооврку, что типа "какие плохие
ситуации могут возникать при выполнении этого запроса на
практике", то в общем и ничего.
А переписать надо было бы так:
select T1.F1, case when T2_1.F1 then T2_1.F1 else T2_2.F1 end as T2F1
from Table1 T1
left join Table2 T2_1 on T1.F2=T2.F2
left join Table2 T2_2 on T1.F3=T2.F3