Здравствуйте, Dair, Вы писали:
D>Блин, я и 11 так и не изучил по-человечески, а уже 14...
Не волнуйся, это багфикс-релиз. Примерно как С++03 для С++98. Реальных изменений по сравнению с С++11 немного и они в основном мелкие (наиболее заметные — это улучшения constexpr и полиморфная лямбда, которая наконец-то сделает Boost.Lambda ненужной): http://en.wikipedia.org/wiki/C%2B%2B14
Здравствуйте, uzhas, Вы писали:
U>Здравствуйте, zaufi, Вы писали:
Z>>поддержка раскраски синтаксиса по редакторам/IDE: Z>>kate/kdevelop
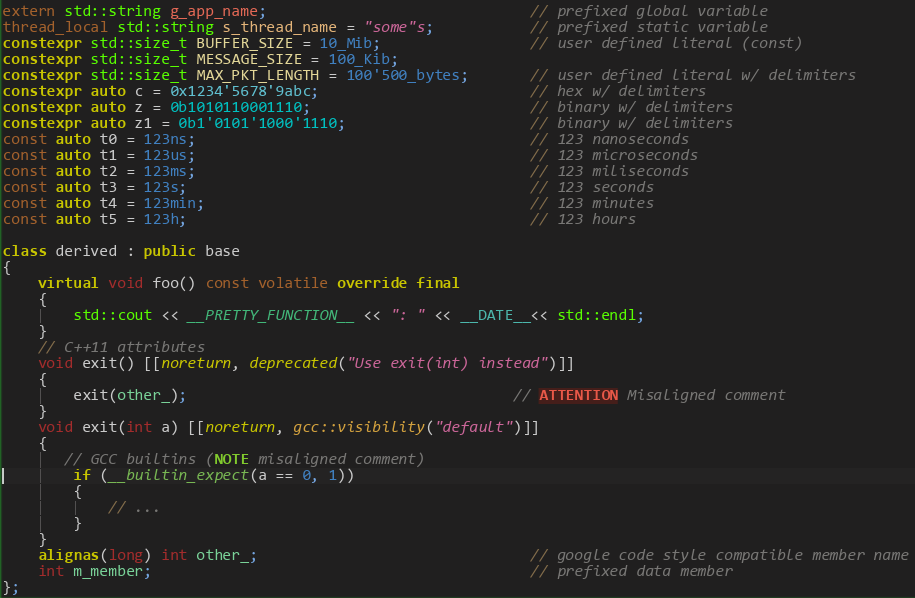
U>не подчеркивает опечатку в "miliseconds"
kate умеет проверять spelling в комментах и строковых литералах... но как правило они полны всяких имён переменных и прочих не очень английских слов, поэтому по умолчанию я её держу выключенной, чтобы не раздражали неизвестные "слова" %)
все классно, особенно полиморфные лямбды. Но все равно неясно, зачем писать [](auto x, auto y) { return x+y;}, почему не просто [](x, y){ return x+y; }
Здравствуйте, Alexander G, Вы писали:
AG>Здравствуйте, enji, Вы писали:
E>>почему не просто [](x, y){ return x+y; }
AG>как для "[](x,y)" понять, что x и y — имена параметров, а не типы? AG>(просто исходя из того, что типов x и y не видно — слишком хрупко)
[](x): x — параметр
[](x у): x — тип, у — параметр
[](x _): x — тип, _ — параметр, о неиспользуемости которого компилятор не ругается.
Некоторая несовместимость с обычными функциями, но зато 5 символов экономии на параметр в коротких лямбдах рулят...
...
E>скобки по моему тоже можно опустить
E>[](x, y) x+y;
E>и мы практически пришли к E>x, y -> x+y
Не думаю, что ради однострочных лямбд стоит так ломать синтаксис языка.
Тем более, краткость однострочных полиморфных лямбд решается на библиотечном уровне. Код с boost.lambda:
Здравствуйте, Кодт, Вы писали:
К>Здравствуйте, PM, Вы писали:
PM>>Найдено на Reddit
К>О! Это ж те самые продолжения, о которых столько говорили большевики. К>Теперь можно разгуляться и налепить монад и аппликативных фунторов от души.
А потом придут сами-знаете-кто и скажут, что С++ — отстой, и шаблонное метапрограммирование монады и аппликативные функторы в С++14 — просто побочный эффект лямбд, которые создавались сааавсем для другого
Здравствуйте, jazzer, Вы писали:
J>А потом придут сами-знаете-кто и скажут, что С++ — отстой, и шаблонное метапрограммирование монады и аппликативные функторы в С++14 — просто побочный эффект лямбд, которые создавались сааавсем для другого
Ну мы-то знаем, что лямбды создавались для эмблемы халфлайфа, а все эти Чёрчи — выдумка черчилля в восемнадцатом году.
Здравствуйте, enji, Вы писали:
AG>>как для "[](x,y)" понять, что x и y — имена параметров, а не типы? AG>>(просто исходя из того, что типов x и y не видно — слишком хрупко)
E>[](x): x — параметр
Совместимость с C++11 — в унитаз?
E>Некоторая несовместимость с обычными функциями, но зато 5 символов экономии на параметр в коротких лямбдах рулят...
E>[](x, y) { return x+y; } E>[](auto x, auto y) { return x+y; }
В дженерик коде часто приходится обеспечивать сохранность value category — lvalue/rvalue.
[](auto &&x, auto &&y) -> decltype(FORWARD(x)+FORWARD(y)) { return FORWARD(x)+FORWARD(y); }
В итоге auto не сильно много прибавляет к суммарной длине в процентном соотношении.
E>а если еще сделать так, что для лямбд из одного выражения return "подразумевается", то получается вообще супер
E>[](x, y) { x+y; }
Это снова ломает совместимость с C++11, потому что тип возврата с void может поменяться на что-то другое. И я не уверен, что многие будут счастливы писать
[](x, y) -> void { foo(x+y); }
всякий раз, когда нужен именно void.
E>скобки по моему тоже можно опустить
E>[](x, y) x+y;
Проблема такой нотации в том, что её тяжело парсить. Как ты предлагаешь интерпретировать выражение ниже?
f = [](x, y) noexcept(x+y) — (x+y), some_function();













 Перекуём баги на фичи!
Перекуём баги на фичи!

