Есть матрица (массив) 10000х10000.
Заполнение всех элементов матрицы (m[i,j] = value) на моей машине выполняется 0.5 сек.
(Половина времени уходит на цикл for, половина на присвоение).
Можно ли как-то теоретически уменьшить скорость обработки?
Здравствуйте, Vladimir, Вы писали:
V>Есть матрица (массив) 10000х10000. V>Заполнение всех элементов матрицы (m[i,j] = value) на моей машине выполняется 0.5 сек. V>(Половина времени уходит на цикл for, половина на присвоение). V>Можно ли как-то теоретически уменьшить скорость обработки?
Одно из решений: минимизировать промахи кеша. Перебирать матрицу по строкам, а не по столбцам.
А так — надо смотреть как оно реализовано, что хранится и как измерялось (надеюсь, не в дебаге?).
_____________________
С уважением,
Stanislav V. Zudin
Здравствуйте, Vladimir, Вы писали:
V>Есть матрица (массив) 10000х10000. V>Заполнение всех элементов матрицы (m[i,j] = value) на моей машине выполняется 0.5 сек. V>(Половина времени уходит на цикл for, половина на присвоение). V>Можно ли как-то теоретически уменьшить скорость обработки?
0) Вы замеряет время на оптимизированной версии или на debug?
1) А каков тип данных элементов (int/double)? Какого он размера на вашем компиляторе?
2) Нужно понять не упираетесь ли в пропускную способность шины?
3) Как организованна матрица (подряд хранятся элементы одного столбца или одной строки)?
Поменять вложенность циклов, так чтобы идти по памяти подряд.
4) Попробовать:
4.1) Готовые функции заполнения массивов (std::fill)
4.2) Готовые функции заполнения массивов sscal_/scopy_ из mkl (или других реализаций BLAS).
4.3) написать циклы вручную с использованием SSE (тип данных __m128)
(требует, чтобы при аллокации матрицы память была правильно выровнена).
V>Есть матрица (массив) 10000х10000.
Не очень большая матрица V>Заполнение всех элементов матрицы (m[i,j] = value) на моей машине выполняется 0.5 сек.
Что-то многовато V>(Половина времени уходит на цикл for, половина на присвоение). V>Можно ли как-то теоретически уменьшить скорость обработки?
1. заполнять по строкам — минимизирует смену кеша.
2. Распараллелить по количеству ядер
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Здравствуйте, Vladimir, Вы писали:
V>Есть матрица (массив) 10000х10000. V>Заполнение всех элементов матрицы (m[i,j] = value) на моей машине выполняется 0.5 сек. V>(Половина времени уходит на цикл for, половина на присвоение). V>Можно ли как-то теоретически уменьшить скорость обработки?
Здравствуйте, Vladimir, Вы писали:
V>Есть матрица (массив) 10000х10000. V>Заполнение всех элементов матрицы (m[i,j] = value) на моей машине выполняется 0.5 сек. V>(Половина времени уходит на цикл for, половина на присвоение). V>Можно ли как-то теоретически уменьшить скорость обработки?
1) матрица чего?
2) чем заполняешь?
Лучший способ ускорить заполнение твоей матрицы, это превратить твой цикл for в memset. Но возможность осуществления этого плана зависит от ответов на эти вопросы.
Здравствуйте, Stanislav V. Zudin, Вы писали:
SVZ>Одно из решений: минимизировать промахи кеша. Перебирать матрицу по строкам, а не по столбцам. SVZ>А так — надо смотреть как оно реализовано, что хранится и как измерялось (надеюсь, не в дебаге?).
Это не промахи кэша. В названии RAM, Random Access Memory, слово Random является большим преувеличением. Современная память в разы (если не на порядки) работает быстрее при последовательном доступе, чем при произвольном. И это не только на уровне интерфейса между процессором и памятью (там, где влияет кэш), это и сама память так устроена.
Так скорость доступа, которая указывается в спецификации памяти, она достигается именно при строго последовательном доступе.
Здравствуйте, Stanislav V. Zudin, Вы писали:
SVZ>Одно из решений: минимизировать промахи кеша. Перебирать матрицу по строкам, а не по столбцам. SVZ>А так — надо смотреть как оно реализовано, что хранится и как измерялось (надеюсь, не в дебаге?).
using ulong = unsigned long;
ulong m[w][h] <=> m[w*h];
Двумерную матрицу можно представить как одномерный массив. Порядок как перебирать, по строкам или столбцам, не важно.
Здравствуйте, Vladimir, Вы писали:
V>Двумерную матрицу можно представить как одномерный массив. Порядок как перебирать, по строкам или столбцам, не важно.
Важно. Кеширование.
Забег поперёк кеша будет на каждый новый элемент грузить целую линейку, а поскольку линеек меньше, чем строк, то кешмисс будет ровно на каждом элементе.
Те, кто занимается быстрой работой с большими матрицами, — изрядно упарываются по алгоритмам и структурам данных, минимизирующим промахи.
Например, представляют матрицу в блочном виде, так, чтобы соседние элементы как по рядам, так и по строкам оказывались в одной линейке. (Z-порядок представления матриц).
Умножение матриц в наивной реализации убивает производительность из-за кешмиссов. А какой-нибудь там Intel MKL, зная устройство кеша конкретного процессора, рвёт и мечет всех как тузик грелку.
Причём ещё и устройство виртуальной памяти играет.
Когда делаешь большой malloc, то система выделяет адресное пространство, но не физическую память. А физическую выделяет по мере использования. И это всё сопровождается исключениями защиты памяти и проваливанием в сисколлы.
Забег поперёк такого массива — это сперва очень медленно, а потом быстро. Забег вдоль массива — это быстро с кратковременными тормозами.
Здравствуйте, Pzz, Вы писали:
Pzz>Это не промахи кэша. В названии RAM, Random Access Memory, слово Random является большим преувеличением. Современная память в разы (если не на порядки) работает быстрее при последовательном доступе, чем при произвольном. И это не только на уровне интерфейса между процессором и памятью (там, где влияет кэш), это и сама память так устроена.
У Мыщьха в какой-то книге или статье есть огромная глава про это (про переключение страниц памяти). Тут главное последовательно матрицу в памяти заполнять. А то на запись ячейки памяти уходит условно два такта процессора, а на переключение 4KB страницы, вроде, что-то около 20000+
Вот фрагмент из его книги "Техника оптимизации программ. Эффективное использование памяти", тут оптимизаторы подсказали. Эксперименты с большими массивами у него в третьей главе, с наскока полный текст первой главы нашёл.
Какие многомерные массивы? Какие кэш-промахи? Здесь у нас и близко нет ни того, ни другого! Судя по всему, мы столкнулись с грубой ошибкой Инструктора (шаблонный поиск дает о себе знать!), но все же не поленимся, и заглянем в предлагаемый Инструктором пример, памятуя о том, что всегда в первую очередь следует искать ошибку у себя, а не у окружающих. Быть может, это мы чего-то недопонимаем:
Original Code Optimized Code
int b[200][120]; int b[200][120];
void xmpl17(int *a) void ympl17(int *a)
{ {
int i, j; int i, j;
for (i = 0; i < 120; i++) int atemp;
for (j = 0; j < 200; j++) for (j = 0; j < 200; j++)
for (i = 0; i < 120;i++)
b[j][i]=b[j][i]+a[2*j];
} b[j][i]=b[j][i]+a[2*j];
}
Ну вот, все правильно. Приводимый профилировщиком VTune фрагмент кода наглядно демонстрирует, что двухмерные массивы лучше обрабатывать по строкам, а не столбцам (см. "Часть III. Подсистема кэш-памяти"). Но ведь у нас нет двухмерных массивов, а, стало быть, и слушаться Инструктора в данном случае не надо.
UPD.
Нашёл, я её в своё время скачал в полном виде.
Здравствуйте, Vladimir, Вы писали:
V>Здравствуйте, kov_serg, Вы писали:
_>>Что у вас выводит такой код? V>cold dt = 617[ms] speed=1.20683 Gb/s V>warm dt = 308[ms] speed=2.41684 Gb/s
А что за компилятор? Вы оптимизацию включали? Что за процессор память и ос?
Ваши цифры соответствуют примерно DDR2-400 в одноканальном режиме.
Что пишут всякие тесты типа AIDA64 memory and cache benchmark
Здравствуйте, Maniacal, Вы писали:
Pzz>>Это не промахи кэша. В названии RAM, Random Access Memory, слово Random является большим преувеличением. Современная память в разы (если не на порядки) работает быстрее при последовательном доступе, чем при произвольном. И это не только на уровне интерфейса между процессором и памятью (там, где влияет кэш), это и сама память так устроена.
M>У Мыщьха в какой-то книге или статье есть огромная глава про это (про переключение страниц памяти). Тут главное последовательно матрицу в памяти заполнять. А то на запись ячейки памяти уходит условно два такта процессора, а на переключение 4KB страницы, вроде, что-то около 20000+
Ох. Все сломалось в доме у Смешанских.
На скорость памяти влияет много всяких разных штук. И промахи мимо кеша, и промахи мимо TLB (те самые переключения страниц) и еще много чего.
Но даже без учета этих факторов, сама по себе память очень медленная при произвольном (не последовательном) доступе.
В любом случае, вывод верен, надо заполнять по строкам, да.
Здравствуйте, Stanislav V. Zudin, Вы писали:
SVZ>Одно из решений: минимизировать промахи кеша. Перебирать матрицу по строкам, а не по столбцам. SVZ>А так — надо смотреть как оно реализовано, что хранится и как измерялось (надеюсь, не в дебаге?).
Кеш по строкам и по строкам. С трудом, но с Вами согласен. Но у меня частный случай: всегда квадратная матрица! Читай ее хоть вдоль, хоть поперек.
С памятью не понятно. Один раз выделяю, один раз удаляю.
DWORD *m = new DWORD[w * h];
clock_t start = clock();
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++)
m[i*w+j] = i * w + j;
clock_t stop = clock();
printf("%d ms\n", stop - start);
delete [] m;
Здравствуйте, Pzz, Вы писали:
Pzz>Но даже без учета этих факторов, сама по себе память очень медленная при произвольном (не последовательном) доступе.
Pzz>В любом случае, вывод верен, надо заполнять по строкам, да.
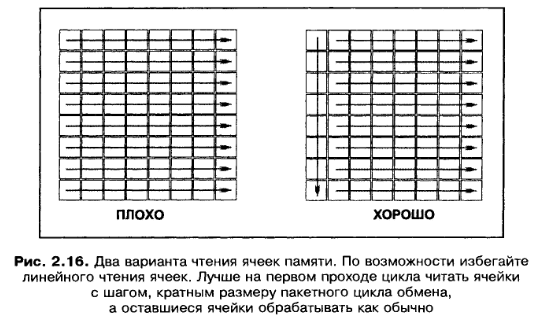
Пример как нужно читать матрицу размером 64 байта
Крис писал, что это заставляет и кэш задействовать и немного распараллелить чтение на уровне контроллера памяти.
Здравствуйте, Vladimir, Вы писали:
V>Есть матрица (массив) 10000х10000. V>Заполнение всех элементов матрицы (m[i,j] = value) на моей машине выполняется 0.5 сек. V>(Половина времени уходит на цикл for, половина на присвоение). V>Можно ли как-то теоретически уменьшить скорость обработки?
1. Заполнять по строкам/столбцам так, чтоб адреса увеличивались линейно
(последовательная запись в память);
2. Компилятор в принципе это сделает и сам, но:
2.1. развернуть цикл (на 8-16-32-64 итерации);
2.2. избавиться от индексной адресации в пользу указателей;
2.3. избавиться от счётчика цикла в пользу сравнения с адресом конца;
4. Распараллелить запись в память одним из следующих путей:
4.1. путём использования векторных инструкций;
4.2. путём использования более широкого типа данных (uint64_t вместо uint32_t);
5. Само собой начало массива обязательно должно быть выравнено на размер кеш-линии
(или по меньшей мере на размер элемента или группы элементов из п. 4.1 и 4.2);
6. указать компилятору конкретный тип процессора для оптимизации тела цикла
(компилятор должен учесть какие инструкции могут исполняться параллельно).
Здравствуйте, Maniacal, Вы писали:
M>Здравствуйте, Pzz, Вы писали:
Pzz>>Но даже без учета этих факторов, сама по себе память очень медленная при произвольном (не последовательном) доступе.
Pzz>>В любом случае, вывод верен, надо заполнять по строкам, да.
M>Пример как нужно читать матрицу размером 64 байта M>Image: Безымянный5.png
M>Крис писал, что это заставляет и кэш задействовать и немного распараллелить чтение на уровне контроллера памяти.
Крис это писал на основе данных уже 15-летней давности, в основном P4. Процессоры заметно улучшились.
Сейчас можно и достаточно эффективно сделать, например, prefetch на пачку ячеек наперёд.








 Перекуём баги на фичи!
Перекуём баги на фичи!