Решил озадачится этим вопросом. Прочитал с форумов rsdn про фасеты, решил использовать из набора boost: utf8_codecvt_facet. Чтение решил выполнить по алгоритму:
Соответственно вопрос: Как же скомпилить нормально тест? Компиляция проваливается так:
g++ test.cpp -o test.exe
/home/vostok/tmp/ccfvenOQ.o: In function `boost::archive::detail::utf8_codecvt_facet::utf8_codecvt_facet(unsigned int)':
test.cpp.text._ZN5boost7archive6detail18utf8_codecvt_facetC1Ej[boost::archive::detail::utf8_codecvt_facet::utf8_codecvt_facet(unsigned int)]+0x19): undefined reference to `vtable for boost::archive::detail::utf8_codecvt_facet'
collect2: ld returned 1 exit status
Здравствуйте, Vostok, Вы писали:
V>Решил озадачится этим вопросом. Прочитал с форумов rsdn про фасеты, решил использовать из набора boost: utf8_codecvt_facet.
В большинстве случаев UTF-8 можно читать в char и работать так же, как и с ASCII.
Здравствуйте, Roman Odaisky, Вы писали:
RO>Здравствуйте, Vostok, Вы писали:
V>>Решил озадачится этим вопросом. Прочитал с форумов rsdn про фасеты, решил использовать из набора boost: utf8_codecvt_facet.
RO>В большинстве случаев UTF-8 можно читать в char и работать так же, как и с ASCII.
Да, конечно, полностью с вами согласен. Я так сначала и сделал. Но возникла следующая проблема. У меня в файле с кодировкой utf8 (это данность, к сожалению, а может и благо) содержатся английские и русские слова, а так же числа и прочая разнородная информация. Далее я делю файл на лексемы и получаю массивы русских/английских слов. Ну и, естественно, когда я пытаюсь определить длину слов, которые хранятся в виде string, то для русских слов размер, конечно, определяется некорректно. Вот и я решил исправить всё кардинально: читать всё в utf8 в wstring и получать правильные длины слов.
Здравствуйте, Vostok, Вы писали:
V>Решил озадачится этим вопросом. Прочитал с форумов rsdn про фасеты, решил использовать из набора boost: utf8_codecvt_facet. Чтение решил выполнить по алгоритму:
V>http://www.gamedev.ru/code/forum/?id=73328 — 4-ый комментарий.
V>Соответственно вопрос: Как же скомпилить нормально тест? Компиляция проваливается так: V>g++ test.cpp -o test.exe V>/home/vostok/tmp/ccfvenOQ.o: In function `boost::archive::detail::utf8_codecvt_facet::utf8_codecvt_facet(unsigned int)': V>test.cpp:(.text._ZN5boost7archive6detail18utf8_codecvt_facetC1Ej[boost::archive::detail::utf8_codecvt_facet::utf8_codecvt_facet(unsigned int)]+0x19): undefined reference to `vtable for boost::archive::detail::utf8_codecvt_facet' V>collect2: ld returned 1 exit status
Разобрался с помощью друга:
g++ test.cpp -lboost_wserialization -o test.exe
Но читает/выводит? всё равно неправильно — русские символы выводятся знаками "?" в консоли..
Смотрите UTF8-CPP — простая библиотечка, конвертация UTF-8 <-> UTF-16 <-> UTF-32, все удовольствие в трех заголовочных файлах. Принцип следующий — все сохраняем в UTF-8, читаем тоже в UTF-8, внутри программы храним все в UTF-16 или в UTF-32 — зависит от платформы, узнаем по sizeof(wchar_t), используем std::wstring.
Здравствуйте, Vostok, Вы писали:
V>Ну и, естественно, когда я пытаюсь определить длину слов, которые хранятся в виде string, то для русских слов размер, конечно, определяется некорректно. Вот и я решил исправить всё кардинально: читать всё в utf8 в wstring и получать правильные длины слов.
Не получишь ты правильные длины слов подсчетом количества Unicode code points.
Здравствуйте, Roman Odaisky, Вы писали:
RO>Здравствуйте, Ytz, Вы писали:
RO>>>В большинстве случаев UTF-8 можно читать в char и работать так же, как и с ASCII. Ytz>>Только с англоязычным текстом.
RO>Отнюдь.
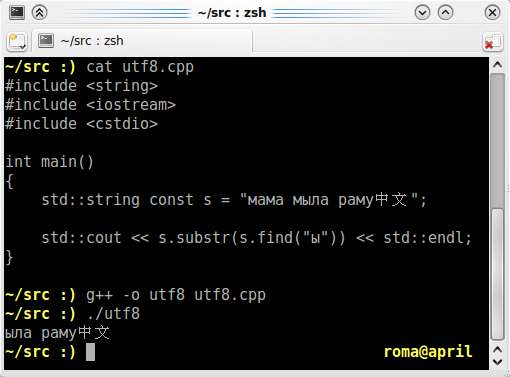
Помимо того, что показанное Вами решение не переносимо, так оно еще и не работает так как надо. Например посмотрите, что выдаст s.length()
Здравствуйте, Ytz, Вы писали:
RO>>>>В большинстве случаев UTF-8 можно читать в char и работать так же, как и с ASCII. Ytz>>>Только с англоязычным текстом. RO>>Отнюдь. RO>>http://files.rsdn.ru/48787/washing-windows-4.3.png Ytz>Помимо того, что показанное Вами решение не переносимо,
Оно непереносимо только в том смысле, что в исходниках на C++ допустимы только символы из ASCII. А читать UTF-8 в char[], обрабатывать и выводить вполне можно.
Ytz>так оно еще и не работает так как надо. Например посмотрите, что выдаст s.length()
Выдаст количество байтов в строке. std::wstring::length выдала бы количество Unicode code points, что было бы не более информативно (ну зачем, зачем считать уникодные символы?!).
Здравствуйте, Ytz, Вы писали: Ytz>Смотрите UTF8-CPP — простая библиотечка, конвертация UTF-8 <-> UTF-16 <-> UTF-32, все удовольствие в трех заголовочных файлах.
Ytz, а можно link на эту библиотечку?
"Дайте мне возможность выпускать и контролировать деньги в государстве и – мне нет дела до того, кто пишет его законы." (c) Мейер Ансельм Ротшильд , банкир.
Здравствуйте, Roman Odaisky, Вы писали:
RO>Здравствуйте, Vostok, Вы писали:
V>>Ну и, естественно, когда я пытаюсь определить длину слов, которые хранятся в виде string, то для русских слов размер, конечно, определяется некорректно. Вот и я решил исправить всё кардинально: читать всё в utf8 в wstring и получать правильные длины слов.
RO>Не получишь ты правильные длины слов подсчетом количества Unicode code points.
RO>Café (U+0043 U+0061 U+0066 U+00E9) — сколько букв? (Правильный ответ: 4.) RO>Café (U+0043 U+0061 U+0066 U+0065 U+0301) — сколько букв? (Правильный ответ: 4.)
RO>Shuffle (U+0053 U+0068 U+0075 U+0066 U+0066 U+006C U+0065) — сколько букв? (Правильный ответ: 7.) RO>Shuffle (U+0053 U+0068 U+0075 U+FB04 U+0065) — сколько букв? (Правильный ответ: 7.)
RO>Encyclopædia (U+0045 U+006E U+0063 U+0079 U+0063 U+006C U+006F U+0070 U+00E6 U+0064 U+0069 U+0061) — сколько букв? (Правильный ответ: 13.)
RO>Ударе́ние (U+0423 U+0434 U+0430 U+0440 U+0435 U+0301 U+043D U+0438 U+0435) — сколько букв? (Правильный ответ: 8.)
RO>(В шрифте Verdana диакритические знаки сползают)
Хм, а я сделал следующим образом: после курения доков посетила прекрасное знание, что wstring хранит всё в UCS-2. Взял конвертацию UTF-8 -> UCS-2 и длина слов wstring стала считаться верно.. Чего я и добивался.
Но проблему с wcout пока не осилил. Как я понимаю, надо перед выводом всё обратно в utf-8 гнать, либо wcout выставлять ucs-2. Но что-то с наскока не получилось.
Здравствуйте, zaufi, Вы писали:
Z>альтернативный способ: читать в char* буффер (из обыкновенного ifstream) и потом сконверить его в wcharы с помощью mbstowcs...
Это второе что я попробовал (после iconv). Результат нулевой.
Здравствуйте, Rakafon, Вы писали:
Ytz>>Смотрите UTF8-CPP — простая библиотечка, конвертация UTF-8 <-> UTF-16 <-> UTF-32, все удовольствие в трех заголовочных файлах.
R>Ytz, а можно link на эту библиотечку?