CS>std::string это тоже unicode.
CS>там может лежать например utf-8 или например koi8. CS>И то и то есть способ хранить unicode code points.
Я не уверен, что в std::string можно хранить utf-8. Поведение методов типа length и всех от него зависимых не будет учитывыть UTF-8 кодировку и будет возвращать неверные значения.
Re[3]: std::wstring vs. ATL::CString vs. _bstr_t ?
Здравствуйте, shrecher, Вы писали:
S>Здравствуйте, c-smile, Вы писали:
CS>>std::string это тоже unicode.
CS>>там может лежать например utf-8 или например koi8. CS>>И то и то есть способ хранить unicode code points.
S>Я не уверен, что в std::string можно хранить utf-8. Поведение методов типа length и всех от него зависимых не будет учитывыть UTF-8 кодировку и будет возвращать неверные значения.
неверные значения чего?
length() в случае std::string даст длину в utf-8 code units — сиречь байтах.
А std::wstring::length() под windows даст длину в utf-16 code units — т.е. words (a.k.a. int16).
Как и _bstr_t/CStringW кстати.
Не забываем что:
1) LPCWSTR это UTF-16 в XP/Vista
2) UNICODE code point это на сегодняшний день 21-bit number.
Если говорить про строки то нужно четко специфицировать набор операций и для чего они будут использоваться.
Если например хранить html/xml текст то utf-8 это оптимальный вариант. Если строки для рисования то в формате
платформы — например utf-16.
Также важен набор операций со строками. Просто хранение текста — это одно. Манипуляции — это другое.
Здравствуйте, _Ursus_, Вы писали:
_U_>Я тут подумал... _U_>какой класс лучше всего использовать для UNICODE строк: _U_>- std::wstring _U_>- ATL::CString _U_>- _bstr_t _U_>- что-то самописное ?
_U_>Если основные требования — скорость и UNICODE. _U_>Чем пользуетесь вы? Только аргументированно, плиз.
Кстати, для работы с юникодом офигенно удобно использовать QString из qt. Из недостатков — довольно "толстый" класс, но зато, всё что нужно уже есть. Плюс в библиотеки есть набор кодеков, позволяющий конвертировать в юникод и обратно из здорового набора разных кодировок.
"To protect people you must slay people. To let people live you must let people die. This is the true teaching of the sword."
-Seijuro Hiko, "Rurouni Kensin"
Re[3]: std::wstring vs. ATL::CString vs. _bstr_t ?
Здравствуйте, shrecher, Вы писали:
S>Я не уверен, что в std::string можно хранить utf-8. Поведение методов типа length и всех от него зависимых не будет учитывыть UTF-8 кодировку и будет возвращать неверные значения.
В 150-й раз.
Зачем тебе вообще нужен std::string::size()?! Для чего ты собираешься использовать это число? Зачем тебе знать, из скольки Unicode code points состоит твоя строка?!
До последнего не верил в пирамиду Лебедева.
Re[2]: std::wstring vs. ATL::CString vs. _bstr_t ?
Здравствуйте, c-smile, Вы писали:
CS>Скорость чего конкретно?
Скорее, имеется ввиду overall performance, ну, вы понимаете
Т.е., вот есть у меня проект, доставшийся в наследство от другой команды, и в нем дикая мешанина из std::string, std::wstring, CString и _bstr_t.
Это жутко нервирует, и хочется все привести к единообразию — чтобы класс для строк был ОДИН.
Re[4]: std::wstring vs. ATL::CString vs. _bstr_t ?
Здравствуйте, c-smile, Вы писали:
S>>Я не уверен, что в std::string можно хранить utf-8. Поведение методов типа length и всех от него зависимых не будет учитывыть UTF-8 кодировку и будет возвращать неверные значения.
CS>неверные значения чего?
неверные значения длинны стоки. Она будет возвращена в байтах, а не символах. К примеру
Здравствуйте, Roman Odaisky, Вы писали:
RO>Здравствуйте, shrecher, Вы писали:
S>>Я не уверен, что в std::string можно хранить utf-8. Поведение методов типа length и всех от него зависимых не будет учитывыть UTF-8 кодировку и будет возвращать неверные значения.
RO>В 150-й раз.
RO>Зачем тебе вообще нужен std::string::size()?! Для чего ты собираешься использовать это число? Зачем тебе знать, из скольки Unicode code points состоит твоя строка?!
Где ты видищь size? Я про length писал. Зачем нужно знать сколько длинна строки в символах? Дык это давольно частая операция. К примеру если распарсить что-то надо.
Re[4]: std::wstring vs. ATL::CString vs. _bstr_t ?
Здравствуйте, _Ursus_, Вы писали:
_U_>Здравствуйте, c-smile, Вы писали:
CS>>Скорость чего конкретно?
_U_>Скорее, имеется ввиду overall performance, ну, вы понимаете _U_>Т.е., вот есть у меня проект, доставшийся в наследство от другой команды, и в нем дикая мешанина из std::string, std::wstring, CString и _bstr_t. _U_>Это жутко нервирует, и хочется все привести к единообразию — чтобы класс для строк был ОДИН.
напиши свой собственный велосипед и в нем сделай все, что тебе нужно.
Re[5]: std::wstring vs. ATL::CString vs. _bstr_t ?
Здравствуйте, shrecher, Вы писали:
S>>>Я не уверен, что в std::string можно хранить utf-8. Поведение методов типа length и всех от него зависимых не будет учитывыть UTF-8 кодировку и будет возвращать неверные значения.
RO>>В 150-й раз. RO>>Зачем тебе вообще нужен std::string::size()?! Для чего ты собираешься использовать это число? Зачем тебе знать, из скольки Unicode code points состоит твоя строка?!
S>Где ты видищь size? Я про length писал. Зачем нужно знать сколько длинна строки в символах? Дык это давольно частая операция. К примеру если распарсить что-то надо.
std::string::size() и std::string::length() — это одно и то же. Лучше использовать size(), потому что он так называется и в других контейнерах.
Так вот, приведи, пожалуйста, хоть один пример, где нужен std::string::size() (или length()).
(Кстати, если речь о парсинге чего-нибудь, то кодировка тебя интересует в последнюю очередь. Если ты хочешь разделить, к примеру, путь на компоненты, то слеш выглядит одинаково что в ASCII, что в UTF-8, а то, что между слешами, — просто последовательность байт.)
До последнего не верил в пирамиду Лебедева.
Re[5]: std::wstring vs. ATL::CString vs. _bstr_t ?
Здравствуйте, shrecher, Вы писали:
S>>>Я не уверен, что в std::string можно хранить utf-8. Поведение методов типа length и всех от него зависимых не будет учитывыть UTF-8 кодировку и будет возвращать неверные значения.
CS>>неверные значения чего?
S>неверные значения длинны стоки. Она будет возвращена в байтах, а не символах. К примеру S>в тоже время, для std::wstring все будет работать ок в utf-16.
Здравствуйте, shrecher, Вы писали:
CS>>неверные значения чего? S>неверные значения длинны стоки. Она будет возвращена в байтах, а не символах. К примеру
S>
S>в тоже время, для std::wstring все будет работать ок в utf-16.
Не будет! UTF-16 с тем же успехом содержит символы, которые занимают больше двух байт. Только они встречаются реже, что создает видимость отсутствия проблемы, но никак не решает ее.
Фиг тебе. У тебя строка на русском и совпадает кодировка, попробуй вставить китайский иероглиф, получишь warning C4566.
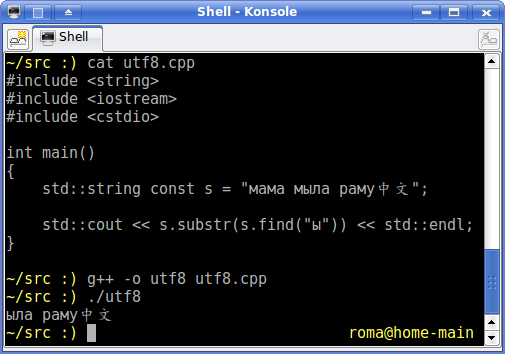
Все проблема в том, внутри std::string использует strlen, которая не заботится о uft8 представлении. Поэтому когда один символ занимает 2 байта strlen вернет 2, не один.
Вот кусок кода считывающий из файла uft8. Файлы содеражат 4 китайских иероглифа. Первый пример некорректно печатает длинну как 15 символов, а другой работает в uft16 и печатает 4 (корректно)
S>>в тоже время, для std::wstring все будет работать ок в utf-16.
RO>Не будет! UTF-16 с тем же успехом содержит символы, которые занимают больше двух байт. Только они встречаются реже, что создает видимость отсутствия проблемы, но никак не решает ее.
Ух загнул!
Re[6]: std::wstring vs. ATL::CString vs. _bstr_t ?
Здравствуйте, Roman Odaisky, Вы писали:
RO>Так вот, приведи, пожалуйста, хоть один пример, где нужен std::string::size() (или length()).
твой пример вполне подходит RO>Если ты хочешь разделить, к примеру, путь на компоненты, то слеш выглядит одинаково что в ASCII, что в UTF-8, а то, что между слешами, — просто последовательность байт.)
Здесь проблема не в англ. "\", в том, что какой-нибудь китайский иероглиф кодируется как 2 два символа, где один совпадет с кодом слэша. К примеру \5. В этом случае, стока пути будет выглядеть как "c:\....\5...\", здесь второй слэш это часть символа, а не разделитель пути. Поэтому если ты используешь str::string и его метод "s.find( "\\" );", то результат будет неверный, т.к std::string не заботится о кодировке, а просто рассматривает строку как набор символов.
Re[7]: std::wstring vs. ATL::CString vs. _bstr_t ?
Здравствуйте, shrecher, Вы писали:
S> Здесь проблема не в англ. "\", в том, что какой-нибудь китайский иероглиф кодируется как 2 два символа, где один совпадет с кодом слэша.
Это невозможно.
Может стоит-таки прочитать про UTF-8, а не придумывать фигню?
Здравствуйте, shrecher, Вы писали:
S>Вот кусок кода считывающий из файла uft8. Файлы содеражат 4 китайских иероглифа. Первый пример некорректно печатает длинну как 15 символов, а другой работает в uft16 и печатает 4 (корректно)
А сколько символов вот в этой строке: "Lux æterna finale"?
Здравствуйте, _Ursus_, Вы писали:
_U_>Скорее, имеется ввиду overall performance, ну, вы понимаете _U_>Т.е., вот есть у меня проект, доставшийся в наследство от другой команды, и в нем дикая мешанина из std::string, std::wstring, CString и _bstr_t.
_U_>Это жутко нервирует, и хочется все привести к единообразию — чтобы класс для строк был ОДИН.
Рекомендую оставить все как есть.
Скорее всего, на это мешанину есть причины, программисты ведь обычно не делают абстракное зло.
Например:
— std::wstring -> работа с какой-нибудь библиотекой (из boost?), которая ничего кроме std::wstring не хочет
— CString -> анологично, MFC/ATL/WTL
— bstr_t -> работа с COM через директиву #import, тоже без вариантов.
То есть, класс строк который вы используете, определяется в основном тем, какие библиотеки вы используете.
Здравствуйте, shrecher, Вы писали:
RO>>...и он выведет строку в точности.
S>Фиг тебе. У тебя строка на русском и совпадает кодировка, попробуй вставить китайский иероглиф, получишь warning C4566.
С чего бы это? Тем более, что я выше по течению приводил другой фрагмент кода, в котором в строке были как русские буквы, так и французские (с диакритическими знаками).
S>Все проблема в том, внутри std::string использует strlen, которая не заботится о uft8 представлении. Поэтому когда один символ занимает 2 байта strlen вернет 2, не один.
S>Вот кусок кода считывающий из файла uft8. Файлы содеражат 4 китайских иероглифа. Первый пример некорректно печатает длинну как 15 символов, а другой работает в uft16 и печатает 4 (корректно)
Ну и что?!
В третий раз спрашиваю: зачем тебе знать размер строки в Unicode code points?!
Кстати, проведи эксперимент. Положи в свой текстовый файл, к примеру, скрипичный ключ (U+1D11E) и запусти свою программу. Сколько символов она насчитает?
P. S. UTF, не «UFT»: Unicode Transformation Format.