Собственно хочется обсудить почему большинство систем сравнивают
каждое значение в отдельности, в то время как проще и удобнее гораздо сваливать
все первые аргументы Assert.IsEqual() в файл и сравнивать их с эталонным файлом целиком
Тогда и разницу сразу можно посмотреть детально и заменить все эталонные значения на новые,
и со сложными структурами данных проще.
Такой подход идеально подходит для тестирования веб-приложений, отчётов,
всяческих конверторов и т.п. где результатом итак является файл.
Для примера внутренняя система тестов mysql построена именно на сравнении файлов.
Хотя опять же внутрення система тестирования mysql-кластера, такого же по классу проекта
построена на Assert-ах.
Здравствуйте, vvaizh, Вы писали:
V>Собственно хочется обсудить почему большинство систем сравнивают V>каждое значение в отдельности, в то время как проще и удобнее гораздо сваливать V>все первые аргументы Assert.IsEqual() в файл и сравнивать их с эталонным файлом целиком
А какое сообщение nunit-а вас больше удовлетворит: Приложение работает неправильно, или Стоимость рассчитывается некорректно?
Здравствуйте, Lloyd, Вы писали:
L>Здравствуйте, vvaizh, Вы писали:
V>>Собственно хочется обсудить почему большинство систем сравнивают V>>каждое значение в отдельности, в то время как проще и удобнее гораздо сваливать V>>все первые аргументы Assert.IsEqual() в файл и сравнивать их с эталонным файлом целиком
L>А какое сообщение nunit-а вас больше удовлетворит: Приложение работает неправильно, или Стоимость рассчитывается некорректно?
меня удовлетворит сообщение в виде diff-а двух файлов который укажет конкретное место, которое неправильное, в вашем конкретном случае я увижу как раз стоимость..
C:\tmp>fc test.etalon.txt test.result.txt
Сравнение файлов test.etalon.txt и TEST.RESULT.TXT
***** test.etalon.txt
Вопросы с подковыркой : 1
Стоимость : 0
Готовые ответы : 1
***** TEST.RESULT.TXT
Вопросы с подковыркой : 1
Стоимость : 1 000 000 000
Готовые ответы : 1
*****
кроме того, если писать в файл, то можно получить не только стоимость но и вообще все отличающиеся значения
традиционные же unit-test ы вылетят сразу на стоимости, и чтобы узнать что ещё в тесте неправильно нужно будет сначала со стоимостью разобраться..
Здравствуйте, Eugene Beschastnov, Вы писали:
EB>Потому что файловый diff гораздо сложнее интегрировать в IDE (дебаггер, быстрая навигация по коду и т.д.), чем assert-ы.
Вообще говоря свежая мысль, как то об этом не думал..
(Я и nunit-ами пользуюсь не интегрируя их в среду)
Имеется в виду, что ассерт сразу покажет проблемную строчку кода?
тут несколько ответов:
1. проблема как правило всё равно совсем не в той строке кода, которая проверяет, а в той, которая меняет..
2. в теории можно предложить дописывать в строчку в файл и координаты строки кода, который сформировал эту строку, тогда можно будет и интегрировать нормально..
Здравствуйте, vvaizh, Вы писали:
L>>А какое сообщение nunit-а вас больше удовлетворит: Приложение работает неправильно, или Стоимость рассчитывается некорректно?
V>меня удовлетворит сообщение в виде diff-а двух файлов который укажет конкретное место, которое неправильное, в вашем конкретном случае я увижу как раз стоимость..
И зачем эта простыня верных значений. Человека запускающего тест это не должно интересовать. Ему важно лишь на чем упали тесты.
V>кроме того, если писать в файл, то можно получить не только стоимость но и вообще все отличающиеся значения V>традиционные же unit-test ы вылетят сразу на стоимости, и чтобы узнать что ещё в тесте неправильно нужно будет сначала со стоимостью разобраться..
Нет, не надо будет, если у вас тесты проверяют не все и сразу, а только стоимость.
Здравствуйте, Lloyd, Вы писали:
L>Здравствуйте, vvaizh, Вы писали:
L>>>А какое сообщение nunit-а вас больше удовлетворит: Приложение работает неправильно, или Стоимость рассчитывается некорректно?
V>>меня удовлетворит сообщение в виде diff-а двух файлов который укажет конкретное место, которое неправильное, в вашем конкретном случае я увижу как раз стоимость..
L>Так стоимость и есть неправильное значение. Куда ж конкретнее?
конкретнее в случае unit-test ов это увидеть не только что стоимость неправильная а увидеть конкретно почему она неправильная и при каких других значениях.. например составляющих этой стоимости..
V>>графически это выглядит примерно так:
V>>http://sourceforge.net/project/screenshots.php?group_id=171639
L>И зачем эта простыня верных значений. Человека запускающего тест это не должно интересовать. Ему важно лишь на чем упали тесты.
нормальный человек кинется проверять условия при котором посчиталась неверная стоимость, может быть посмотрит стоимость которая была скажем на предыдущей итерации и т.п.
файл и дифф всё это ему наглядно показывает..
это как stack-trace..
не будете же вы утверждать что и stack-trace не нужен а нужна лишь строка в которой упало..
V>>кроме того, если писать в файл, то можно получить не только стоимость но и вообще все отличающиеся значения V>>традиционные же unit-test ы вылетят сразу на стоимости, и чтобы узнать что ещё в тесте неправильно нужно будет сначала со стоимостью разобраться..
L>Нет, не надо будет, если у вас тесты проверяют не все и сразу, а только стоимость.
вырожденные случаи давайте откинем и будем рассматривать практические насущные потребности программистов..
а то мне что то пока не заказывали программу которая ничего кроме стоимости не считает..
Здравствуйте, vvaizh, Вы писали:
EB>>Потому что файловый diff гораздо сложнее интегрировать в IDE (дебаггер, быстрая навигация по коду и т.д.), чем assert-ы.
V>Вообще говоря свежая мысль, как то об этом не думал.. V>(Я и nunit-ами пользуюсь не интегрируя их в среду)
V>Имеется в виду, что ассерт сразу покажет проблемную строчку кода? V>тут несколько ответов:
V>1. проблема как правило всё равно совсем не в той строке кода, которая проверяет, а в той, которая меняет.. V>2. в теории можно предложить дописывать в строчку в файл и координаты строки кода, который сформировал эту строку, тогда можно будет и интегрировать нормально..
Насчёт nunit не знаю, но, например, в Smalltalk при провалившемся assert-е вываливаешься в дебаггер, а там можно посмотреть абсолютно всё, что захочешь, а заодно сразу исправить и прогнать тест заново.
Здравствуйте, vvaizh, Вы писали:
V>конкретнее в случае unit-test ов это увидеть не только что стоимость неправильная а увидеть конкретно почему она неправильная и при каких других значениях.. например составляющих этой стоимости..
Ну так выведи в Assert всю информацию которая тебе нужно и будет тебе счастье.
L>>И зачем эта простыня верных значений. Человека запускающего тест это не должно интересовать. Ему важно лишь на чем упали тесты.
V>нормальный человек кинется проверять условия при котором посчиталась неверная стоимость, может быть посмотрит стоимость которая была скажем на предыдущей итерации и т.п.
Не знаю что ты имеешь в виду под итерацией, но если это предыдущий запуск теста, то проблема явно надуманная, т.к. в предыдущий раз цена была равна тому, что у тебя прописано в Assert-е.
V>файл и дифф всё это ему наглядно показывает.. V>это как stack-trace..
Неверная аналогия.
L>>Нет, не надо будет, если у вас тесты проверяют не все и сразу, а только стоимость.
V>вырожденные случаи давайте откинем и будем рассматривать практические насущные потребности программистов.. V>а то мне что то пока не заказывали программу которая ничего кроме стоимости не считает..
Будь внимательнее. Я не писал тебе что программа должна считать только стоимость, я написал, что тест должен проверять не все сразу, а то что стоимость считается корректно.
Здравствуйте, Lloyd, Вы писали:
L>Здравствуйте, vvaizh, Вы писали:
V>>конкретнее в случае unit-test ов это увидеть не только что стоимость неправильная а увидеть конкретно почему она неправильная и при каких других значениях.. например составляющих этой стоимости..
L>Ну так выведи в Assert всю информацию которая тебе нужно и будет тебе счастье.
L>>>И зачем эта простыня верных значений. Человека запускающего тест это не должно интересовать. Ему важно лишь на чем упали тесты.
V>>нормальный человек кинется проверять условия при котором посчиталась неверная стоимость, может быть посмотрит стоимость которая была скажем на предыдущей итерации и т.п.
L>Не знаю что ты имеешь в виду под итерацией, но если это предыдущий запуск теста, то проблема явно надуманная, т.к. в предыдущий раз цена была равна тому, что у тебя прописано в Assert-е.
это не предыдущий запуск теста
это стоимость например для предыдущего месяца
V>>файл и дифф всё это ему наглядно показывает.. V>>это как stack-trace..
L>Неверная аналогия.
а по моему дык как раз верная..
что ты будешь делать когда увидишь что баланс не сошёлся?
смотреть конкретные счета..
L>>>Нет, не надо будет, если у вас тесты проверяют не все и сразу, а только стоимость.
V>>вырожденные случаи давайте откинем и будем рассматривать практические насущные потребности программистов.. V>>а то мне что то пока не заказывали программу которая ничего кроме стоимости не считает..
L>Будь внимательнее. Я не писал тебе что программа должна считать только стоимость, я написал, что тест должен проверять не все сразу, а то что стоимость считается корректно.
ИМХО такой подход как раз является причиной того что TDD до сих пор мало распространено "в народе"
Потому что не каждому хватит терпения прописывать Assert-ы для каждого элемента сложных структур
которые получаются на выходе..
Вообще, не понятна проблема..
Во главе угла ИМХО должно стоять удобство использования для программиста, а не то что вот конкретный тест для конкретного одного единственного значения..
давай лучше рассмотрим конкретный пример в котором удобнее традиционный Assert? я пока такого тут не вижу
вообще утверждение какое то логически неполное..
из того что тест проверяет всё сразу как раз следует что он проверяет и стоимость..
в чём проблема?
Здравствуйте, Lloyd, Вы писали:
L>Здравствуйте, vvaizh, Вы писали:
V>>конкретнее в случае unit-test ов это увидеть не только что стоимость неправильная а увидеть конкретно почему она неправильная и при каких других значениях.. например составляющих этой стоимости..
L>Ну так выведи в Assert всю информацию которая тебе нужно и будет тебе счастье.
ага..
в один и тот же Assert?
или в разные?
если в один и тот же то получится как раз твоё "значения не совпадают"..
в лучшем случае укажет с какого места они не совпадает..
если же в несколько ассертов, то упадёт всё равно на первом
Здравствуйте, Eugene Beschastnov, Вы писали:
EB>Здравствуйте, vvaizh, Вы писали:
EB>>>Потому что файловый diff гораздо сложнее интегрировать в IDE (дебаггер, быстрая навигация по коду и т.д.), чем assert-ы.
V>>Вообще говоря свежая мысль, как то об этом не думал.. V>>(Я и nunit-ами пользуюсь не интегрируя их в среду)
V>>Имеется в виду, что ассерт сразу покажет проблемную строчку кода? V>>тут несколько ответов:
V>>1. проблема как правило всё равно совсем не в той строке кода, которая проверяет, а в той, которая меняет.. V>>2. в теории можно предложить дописывать в строчку в файл и координаты строки кода, который сформировал эту строку, тогда можно будет и интегрировать нормально..
EB>Насчёт nunit не знаю, но, например, в Smalltalk при провалившемся assert-е вываливаешься в дебаггер, а там можно посмотреть абсолютно всё, что захочешь, а заодно сразу исправить и прогнать тест заново.
Здравствуйте, vvaizh, Вы писали:
L>>Не знаю что ты имеешь в виду под итерацией, но если это предыдущий запуск теста, то проблема явно надуманная, т.к. в предыдущий раз цена была равна тому, что у тебя прописано в Assert-е.
V>это не предыдущий запуск теста V>это стоимость например для предыдущего месяца
Мне кажется ты неверно понимаешь что такое тест. Такого типа проверки тест делать не должен (imho).
V>давай лучше рассмотрим конкретный пример в котором удобнее традиционный Assert? я пока такого тут не вижу
Давай лучше рассмотрим чем твой подход учше.
V>вообще утверждение какое то логически неполное.. V>из того что тест проверяет всё сразу как раз следует что он проверяет и стоимость.. V>в чём проблема?
Не, из этого следует другой вывод. Если он проверят все и сразу, то значит этот тест сложный, а сложность — ф топпку.
Здравствуйте, Lloyd, Вы писали:
L>Здравствуйте, vvaizh, Вы писали:
L>>>Не знаю что ты имеешь в виду под итерацией, но если это предыдущий запуск теста, то проблема явно надуманная, т.к. в предыдущий раз цена была равна тому, что у тебя прописано в Assert-е.
V>>это не предыдущий запуск теста V>>это стоимость например для предыдущего месяца
L>Мне кажется ты неверно понимаешь что такое тест. Такого типа проверки тест делать не должен (imho).
Он не должен такого делать как раз из-за ограниченности подхода с Assert-ами..
Для программиста ИМХО как раз удобнее чтобы он такие проверки делал..
Это уменьшит затраты на написание тестов и увеличит эффективность их использования
V>>давай лучше рассмотрим конкретный пример в котором удобнее традиционный Assert? я пока такого тут не вижу L>Давай лучше рассмотрим чем твой подход учше.
меньше тестов
можно менять одним махом сразу много эталонных образцов
скинув данные в файл можно проверять значения не скалярные а сложные аггрегатные (например всю результирующую html-страничку разом, или rtf-отчёт, или вообще любой файл на выходе)
поскольку файл — понятие которое есть везде можно реализовать систему так что среда будет позволять единообразное тестирование всех компонентов
от скриптов до хранимых процедур в СУБД
можно запускать тесты как отдельные прцессы и таким образом надёжно изолировать их друг от друга
(а то один тест дурной как положит в корку и себя и framework)
вообще, можно тестировать даже поток управления таким образом..
V>>вообще утверждение какое то логически неполное.. V>>из того что тест проверяет всё сразу как раз следует что он проверяет и стоимость.. V>>в чём проблема?
L>Не, из этого следует другой вывод. Если он проверят все и сразу, то значит этот тест сложный, а сложность — ф топпку.
ну вообще говоря это означает что один "сложный" тест ты заменяешь сотней маленьких
при том что сложный тест даёт те же результаты что и твоя сотня..
вообще так послушать дык можно прийти к тому что на один тест должен быть один Assert.IsEqual, а иначе это уже сложный тест..
Здравствуйте, vvaizh, Вы писали:
L>>Мне кажется ты неверно понимаешь что такое тест. Такого типа проверки тест делать не должен (imho).
V>Он не должен такого делать как раз из-за ограниченности подхода с Assert-ами.. V>Для программиста ИМХО как раз удобнее чтобы он такие проверки делал.. V>Это уменьшит затраты на написание тестов и увеличит эффективность их использования
Скажи, пожалуйста, как ты считаешь, что должен делать тест?
L>>Не, из этого следует другой вывод. Если он проверят все и сразу, то значит этот тест сложный, а сложность — ф топпку.
V>ну вообще говоря это означает что один "сложный" тест ты заменяешь сотней маленьких V>при том что сложный тест даёт те же результаты что и твоя сотня..
V>вообще так послушать дык можно прийти к тому что на один тест должен быть один Assert.IsEqual, а иначе это уже сложный тест..
Здравствуйте, Lloyd, Вы писали:
L>Скажи, пожалуйста, как ты считаешь, что должен делать тест?
да много чего
1. проверять соответствие того что программа делает тому что ожидается
2. помогать программистам находить ошибки
3. проверять отсутствие появления новых "побочных" ошибок в уже вроде бы отлаженом куске кода от изменений в другом куске
да вообще можно взять Фаулера да почитать
ну или ещё кого нибудь
Здравствуйте, vvaizh, Вы писали:
V>ага.. V>в один и тот же Assert? V>или в разные? V>если в один и тот же то получится как раз твоё "значения не совпадают".. V>в лучшем случае укажет с какого места они не совпадает..
V>если же в несколько ассертов, то упадёт всё равно на первом
Если тебе хочется сверить все значения в структуре, то напиши функцию проверяющую на равенство и вызови Assert.IsTrue и будет тебе счастье. В файло-то зачем пихать?
Здравствуйте, Lloyd, Вы писали:
L>Если тебе хочется сверить все значения в структуре, то напиши функцию проверяющую на равенство и вызови Assert.IsTrue и будет тебе счастье. В файло-то зачем пихать?
потому что :
1. функции сравнения файлов уже написаны
2. есть не только функции сравнения файлов, а ещё и функции нахождения diff-а между файлами.. то есть я увижу конкретные элементы структуры которые "не совпадают"
3. чтобы сравнить структу со структурой нужно эту эталонную структуру ещё заполнить/подготовить..
а с файлом всё просто..
один раз тест прогнал, получил результат..
посмотрел глазками что вроде как всё правильно, все поля совпадают..
заменил эталонный файл результирующим и всё..
гораздо проще чем описывать каждый раз сложный эталон в коде
а если вдруго понадобится эталон менять, то это опять же гораздо проще сделать
переписав файл-результат поверх эталонного..
Здравствуйте, vvaizh, Вы писали:
V> а с файлом всё просто.. V> один раз тест прогнал, получил результат.. V> посмотрел глазками что вроде как всё правильно, все поля совпадают.. V> заменил эталонный файл результирующим и всё.. V> гораздо проще чем описывать каждый раз сложный эталон в коде V> а если вдруго понадобится эталон менять, то это опять же гораздо проще сделать V> переписав файл-результат поверх эталонного..
О, кстати, еще один аргумент против использования файлового diff-а для unit-тестов: очень вероятна рассинхронизация кода и эталона. Да и автоматизированный рефакторинг осложняется. Скажем, захотел я изменить структуру возвращаемого объекта (переименовать, например, что-нибудь) — тогда при использовании assert-ов рефакторинг сможет пройти автоматически, а при использовании файлов — нет.
Здравствуйте, Eugene Beschastnov, Вы писали:
EB>О, кстати, еще один аргумент против использования файлового diff-а для unit-тестов: очень вероятна рассинхронизация кода и эталона. Да и автоматизированный рефакторинг осложняется. Скажем, захотел я изменить структуру возвращаемого объекта (переименовать, например, что-нибудь) — тогда при использовании assert-ов рефакторинг сможет пройти автоматически, а при использовании файлов — нет.
1. F5 — прогоняешь тесты, ГУИ среда выдаёт список всех отличающихся эталонов
2. кнопкой "вниз" пробегаешь по ним по всем (справа сразу отображается diff) — убеждаешься что всё в порядке, поменялось тольео то что ожидалось
3. Ctrl+A (выбрать все результаты)
3. Ctrl+F (переписать результаты вместо эталонов)
Здравствуйте, Lloyd, Вы писали:
V>>не так уж и много за столько преимуществ L>Да в чем преимущества-то?
я их уже перечислял..
1. меньше тестов
2. можно менять одним махом сразу много эталонных образцов
3. скинув данные в файл можно проверять значения не скалярные а сложные аггрегатные (например всю результирующую html-страничку разом, или rtf-отчёт, или вообще любой файл на выходе)
4. поскольку файл — понятие которое есть везде можно реализовать систему так что среда будет позволять единообразное тестирование всех компонентов
от скриптов до хранимых процедур в СУБД
5. можно запускать тесты как отдельные прцессы и таким образом надёжно изолировать их друг от друга
(а то один тест дурной как положит в корку и себя и framework)
6. вообще, можно тестировать даже поток управления таким образом..
Здравствуйте, vvaizh, Вы писали:
V>я их уже перечислял..
V>1. меньше тестов V>2. можно менять одним махом сразу много эталонных образцов V>3. скинув данные в файл можно проверять значения не скалярные а сложные аггрегатные (например всю результирующую html-страничку разом, или rtf-отчёт, или вообще любой файл на выходе) V>4. поскольку файл — понятие которое есть везде можно реализовать систему так что среда будет позволять единообразное тестирование всех компонентов V>от скриптов до хранимых процедур в СУБД V>5. можно запускать тесты как отдельные прцессы и таким образом надёжно изолировать их друг от друга V>(а то один тест дурной как положит в корку и себя и framework) V>6. вообще, можно тестировать даже поток управления таким образом..
А ты не путаешь модульное тестирование (unit test) с каким-нибудь другим способом тестирования (регрессионным тестированием или приемочным тестированием)? ИМХО твое описание больше подходит для них.
Здравствуйте, _ALeRT_, Вы писали:
_AL>А ты не путаешь модульное тестирование (unit test) с каким-нибудь другим способом тестирования (регрессионным тестированием или приемочным тестированием)? ИМХО твое описание больше подходит для них.
Вообще говоря конечно путаница есть
подход с диффами можно использовать и как unit-тестирование и как регрессионное и
как функциональное-приёмочное (т.е. вообще например тестовую утилиту как единую программу запускать)
просто unit-тесты наиболее узнаваемое словосочетание из всего вышеперечисленного , поэтому я использовал это название
ну и вообще я всё равно не вижу, почему такой подход хуже подхода с Assert-ами..
Здравствуйте, vvaizh, Вы писали:
V>я их уже перечислял..
V>1. меньше тестов
Как этот подход уменьшит кол-во тестов?
V>2. можно менять одним махом сразу много эталонных образцов
Нука-нука. Расскажи как? И почему то же самое нельзя делать с нормальными тестами.
V>3. скинув данные в файл можно проверять значения не скалярные а сложные аггрегатные (например всю результирующую html-страничку разом, или rtf-отчёт, или вообще любой файл на выходе)
Набросай побыстрому как ты будешь сравнивать два датасета, например.
V>4. поскольку файл — понятие которое есть везде можно реализовать систему так что среда будет позволять единообразное тестирование всех компонентов V>от скриптов до хранимых процедур в СУБД
поскольку код-понятие которое есть везде, ...
V>5. можно запускать тесты как отдельные прцессы и таким образом надёжно изолировать их друг от друга V>(а то один тест дурной как положит в корку и себя и framework)
Не вопрос. Заускай тесты поштучно.
V>6. вообще, можно тестировать даже поток управления таким образом..
Здравствуйте, vvaizh, Вы писали:
V>ну и вообще я всё равно не вижу, почему такой подход хуже подхода с Assert-ами.
ИМХО он не хуже, он просто другой и предназначен для других целей. Например внутренную функциональность часто удобнее проверять с помощью Assert'ов, так как с ними тест получается не такой громоздкий и его легче менять, рефакторить и т.д. Подход с diff'ом удобнее для тестирования (регрессионного или приемочного) системы в целом. В этом случаее тест обычно не меняется и в нем содержится большое колличество проверок, которые часто неудобно делать через Assert'ты.
Здравствуйте, _ALeRT_, Вы писали:
V>>ну и вообще я всё равно не вижу, почему такой подход хуже подхода с Assert-ами. _AL>ИМХО он не хуже, он просто другой и предназначен для других целей. Например внутренную функциональность часто удобнее проверять с помощью Assert'ов, так как с ними тест получается не такой громоздкий и его легче менять, рефакторить и т.д.
При достаточно большой системе тестов ИМХО это удобство практически совсем теряется
Здравствуйте, vvaizh, Вы писали:
V>При достаточно большой системе тестов ИМХО это удобство практически совсем теряется
Ну удобство — это конечно (в данном случае) вопрос вкуса. Лично я считаю, что даже в большой системе тестов сами тесты (которые unit tests) должны быть не большие (как функции — не больше экрана), а дальше — это вопрос качества кода (ИМХО должно быть удобно).
Здравствуйте, Lloyd, Вы писали:
L>Здравствуйте, vvaizh, Вы писали:
V>>я их уже перечислял..
V>>1. меньше тестов L>Как этот подход уменьшит кол-во тестов?
ну как как.. за счёт того что сразу много параметров можно пихать, и правильно разруливать какой из них глючит..
V>>2. можно менять одним махом сразу много эталонных образцов L>Нука-нука. Расскажи как? И почему то же самое нельзя делать с нормальными тестами.
потому что в случае с выводом первых результатов Assert-ов в файл я могу простым копированием результирующего файал поверх эталонного поменять все эталоны, в которых например поменялась большая буква на маленькую
а в случае Assert-ов я должен буду бегать по коду и менять в каждом ассерте большую букву на маленькую..
V>>3. скинув данные в файл можно проверять значения не скалярные а сложные аггрегатные (например всю результирующую html-страничку разом, или rtf-отчёт, или вообще любой файл на выходе) L>Набросай побыстрому как ты будешь сравнивать два датасета, например.
сделаю им xml-сериализацию (да хоть soap-вскую)
отформатирую так, чтобы каждое поле в отдельной строке было (XmlTestWriter с включенным Formatting-ом)
да и выкину в результирующий файл..
между прочим внутренние тесты mysql как я уже упомянал выше примерно так и устроены..
они именно датасеты и сравнивают! как тексты.. diff-ом..
V>>4. поскольку файл — понятие которое есть везде можно реализовать систему так что среда будет позволять единообразное тестирование всех компонентов V>>от скриптов до хранимых процедур в СУБД
L>поскольку код-понятие которое есть везде, ...
дык код то разный.. для разных языков..
нет пока для всех языков общей среды тестирования..
для java- отдельно
для .NET — отдельно
для smaltalk — отдельно
и т.п.
а тут можно общую забабашить
V>>5. можно запускать тесты как отдельные прцессы и таким образом надёжно изолировать их друг от друга V>>(а то один тест дурной как положит в корку и себя и framework) L>Не вопрос. Заускай тесты поштучно.
по умолчанию они вместе запускаются
V>>6. вообще, можно тестировать даже поток управления таким образом.. L>Подробнее, что ты имеешь в виду.
я имею ввиду trace программы..
который можно сравнивать с эталонным..
ну или log выполнения, как тебе понятнее..
Здравствуйте, _ALeRT_, Вы писали:
_AL>Здравствуйте, vvaizh, Вы писали:
V>>При достаточно большой системе тестов ИМХО это удобство практически совсем теряется
_AL>Ну удобство — это конечно (в данном случае) вопрос вкуса. Лично я считаю, что даже в большой системе тестов сами тесты (которые unit tests) должны быть не большие (как функции — не больше экрана), а дальше — это вопрос качества кода (ИМХО должно быть удобно).
Ну хорошо, а есть ли вообще системы которые автоматизируют тесты на основе diff-а?
и почему их видимо гораздо меньше чем xunit-вых систем?
Здравствуйте, vvaizh, Вы писали:
V>Ну хорошо, а есть ли вообще системы которые автоматизируют тесты на основе diff-а? V>и почему их видимо гораздо меньше чем xunit-вых систем?
Системы, с которыми я знаком основанны на Assert'тах. На сколько я понимаю на основе такой системы не сложно написать простой вариант системы тестирования на основе diff-а. Как-то мне попадалась система (http://fit.c2.com/wiki.cgi?IntroductionToFit), похожая на то о чем ты говоришь, но я в ней глубоко не разбирался.
Здравствуйте, vvaizh, Вы писали:
V>>>1. меньше тестов L>>Как этот подход уменьшит кол-во тестов?
V>ну как как.. за счёт того что сразу много параметров можно пихать, и правильно разруливать какой из них глючит..
Напиши функцию, кот сделать то же самое.
L>>Нука-нука. Расскажи как? И почему то же самое нельзя делать с нормальными тестами.
V>потому что в случае с выводом первых результатов Assert-ов в файл я могу простым копированием результирующего файал поверх эталонного поменять все эталоны, в которых например поменялась большая буква на маленькую
V>вообще, посмотри тут: V>http://izh-test.sourceforge.net/advantege_1.html
V>а в случае Assert-ов я должен буду бегать по коду и менять в каждом ассерте большую букву на маленькую..
Не аргумент.
V>>>3. скинув данные в файл можно проверять значения не скалярные а сложные аггрегатные (например всю результирующую html-страничку разом, или rtf-отчёт, или вообще любой файл на выходе) L>>Набросай побыстрому как ты будешь сравнивать два датасета, например.
V>сделаю им xml-сериализацию (да хоть soap-вскую) V>отформатирую так, чтобы каждое поле в отдельной строке было (XmlTestWriter с включенным Formatting-ом)
V>да и выкину в результирующий файл..
V>между прочим внутренние тесты mysql как я уже упомянал выше примерно так и устроены.. V>они именно датасеты и сравнивают! как тексты.. diff-ом..
То есть молимся, чтобы датасет не дай бог переставит строчки?
V>>>4. поскольку файл — понятие которое есть везде можно реализовать систему так что среда будет позволять единообразное тестирование всех компонентов V>>>от скриптов до хранимых процедур в СУБД
L>>поскольку код-понятие которое есть везде, ...
V>дык код то разный.. для разных языков.. V>нет пока для всех языков общей среды тестирования.. V>для java- отдельно V>для .NET — отдельно V>для smaltalk — отдельно V>и т.п.
V>а тут можно общую забабашить
Не забабашиш. Просто вводишь дополнительное звено. Тесты-то все-равно пишутся на прежнем языке.
V>>>5. можно запускать тесты как отдельные прцессы и таким образом надёжно изолировать их друг от друга V>>>(а то один тест дурной как положит в корку и себя и framework) L>>Не вопрос. Заускай тесты поштучно.
V>по умолчанию они вместе запускаются
Твои тесты по умолчанию у меня вообще не работают, ибо не стоят
V>>>6. вообще, можно тестировать даже поток управления таким образом.. L>>Подробнее, что ты имеешь в виду.
V>я имею ввиду trace программы.. V>который можно сравнивать с эталонным.. V>ну или log выполнения, как тебе понятнее..
Боюсь, без модификации кода программы это не так-то легко сделать.
Здравствуйте, Lloyd, Вы писали:
V>>>>1. меньше тестов L>>>Как этот подход уменьшит кол-во тестов? V>>ну как как.. за счёт того что сразу много параметров можно пихать, и правильно разруливать какой из них глючит.. L>Напиши функцию, кот сделать то же самое.
мне нужно на каждый такой случай функцию писать, думать..
потом будет много функций, а тут — универсальный подход позволяющий не напрягать особо мозги..
L>>>Нука-нука. Расскажи как? И почему то же самое нельзя делать с нормальными тестами. V>>потому что в случае с выводом первых результатов Assert-ов в файл я могу простым копированием результирующего файал поверх эталонного поменять все эталоны, в которых например поменялась большая буква на маленькую V>>вообще, посмотри тут: V>>http://izh-test.sourceforge.net/advantege_1.html V>>а в случае Assert-ов я должен буду бегать по коду и менять в каждом ассерте большую букву на маленькую.. L>Не аргумент.
аргумент
V>>сделаю им xml-сериализацию (да хоть soap-вскую) V>>отформатирую так, чтобы каждое поле в отдельной строке было (XmlTestWriter с включенным Formatting-ом) V>>да и выкину в результирующий файл..
L>То есть молимся, чтобы датасет не дай бог переставит строчки?
ставим сортировку явную, если такое возможно..
V>>а тут можно общую забабашить L>Не забабашиш. Просто вводишь дополнительное звено. Тесты-то все-равно пишутся на прежнем языке.
да, но они могут не подключать никаких дополнительных библиотек например..
для тех же хранимых прцедур это актуально..
да и вообще, нативную среду одну на всех написать да и не парится..
V>>по умолчанию они вместе запускаются L>Твои тесты по умолчанию у меня вообще не работают, ибо не стоят
дык и NUnit и JUnit нужно ставить..
V>>я имею ввиду trace программы.. V>>который можно сравнивать с эталонным.. V>>ну или log выполнения, как тебе понятнее.. L>Боюсь, без модификации кода программы это не так-то легко сделать.
ну во первых большинство сложных программ и так имеют развитую систему логов
а во вторых что с того что просто..
Здравствуйте, _ALeRT_, Вы писали:
_AL>Системы, с которыми я знаком основанны на Assert'тах. На сколько я понимаю на основе такой системы не сложно написать простой вариант системы тестирования на основе diff-а.
до определённого момента я тоже именно так и делал
заводил в NUnit-ах что то вроде файлового ассерта
но много времени уходило на анализ того чем отличаются файлы, копирование одного поверх другого и т.п.
среда NUnit тестов этого не позволяет..
вот в общем то тогда и написал http://sourceforge.net/projects/izh-test/
сейчас наоборот зачастую NUnit тесты не пишу, а пишу в ней
например есть у меня в рабочей программе пользовательская функция,
которая готовит некоторую информацию в виде пары xml-файлов
добавляет к ним отчёт в html формате, всё это пакует zip-ом для передачи дальше по почте
ну и как мне это в NUnit-ах тестировать ?
а для izh_test я просто написал консольную утилитку которая нужный файл готовит
izh_test сама эту утилитку вызывает, распаковывает файлы, показывает мне результат и
сравнивает с эталоном
_AL>Как-то мне попадалась система (http://fit.c2.com/wiki.cgi?IntroductionToFit), похожая на то о чем ты говоришь, но я в ней глубоко не разбирался.
да, идея похожа
но использование вордовского файла мне не внушает надежды
Здравствуйте, vvaizh, Вы писали:
V>Здравствуйте, Lloyd, Вы писали:
V>>>>>1. меньше тестов L>>>>Как этот подход уменьшит кол-во тестов? V>>>ну как как.. за счёт того что сразу много параметров можно пихать, и правильно разруливать какой из них глючит.. L>>Напиши функцию, кот сделать то же самое.
V>мне нужно на каждый такой случай функцию писать, думать.. V>потом будет много функций, а тут — универсальный подход позволяющий не напрягать особо мозги..
А код сериализации в файл у тебя зам появляется?
L>>Не аргумент.
V>аргумент
Для меня — нет.
V>>>сделаю им xml-сериализацию (да хоть soap-вскую) V>>>отформатирую так, чтобы каждое поле в отдельной строке было (XmlTestWriter с включенным Formatting-ом) V>>>да и выкину в результирующий файл..
L>>То есть молимся, чтобы датасет не дай бог переставит строчки?
V>ставим сортировку явную, если такое возможно..
Ну вот, начинается. Но что не сделаешь чтобы в фало записать и дифом воспользоваться.
V>>>а тут можно общую забабашить L>>Не забабашиш. Просто вводишь дополнительное звено. Тесты-то все-равно пишутся на прежнем языке.
V>да, но они могут не подключать никаких дополнительных библиотек например.. V>для тех же хранимых прцедур это актуально.. V>да и вообще, нативную среду одну на всех написать да и не парится..
Не понял что ты имеешь в виду. Какую среду? Вот пишу я на шарпе, как мне использовать эту "нативную" среду?
V>>>я имею ввиду trace программы.. V>>>который можно сравнивать с эталонным.. V>>>ну или log выполнения, как тебе понятнее.. L>>Боюсь, без модификации кода программы это не так-то легко сделать.
V>ну во первых большинство сложных программ и так имеют развитую систему логов
Приведи, пожалуйста полный список большинства сложных программ, о котором ты говоришь.
P.S. Давай рассмотрим гипотетическую ситуацию. Ты выполняешь какое-то действие и должен проверить что в логе появилась запись. Эта запись должна иметь отметку о времени совершенного действия. Приведи схематичный пример того, как ты это будешь делать с твоим дифом.
Здравствуйте, vvaizh, Вы писали:
V>например есть у меня в рабочей программе пользовательская функция, V>которая готовит некоторую информацию в виде пары xml-файлов V>добавляет к ним отчёт в html формате, всё это пакует zip-ом для передачи дальше по почте
ИМХО unit-test'ы (если мы все еще говорим о них) предназначены, преже всего, для тестирования внутренней логики программы (функции). Для того, чтобы это сделать не нужно выполнять всю ту сложную работу, которую ты описал. В данном случае стоит воспользоваться мок-объектами (mock objects), что позволит достаточно просто протестировать логику самой функции, а не работу всей программы в целом (что гораздо сложнее). Если же ты хочешь протестировать работу программы, то тебе подойдет регрессонное тестирование (оно-то и будет основанно на сравнении файлов).
Здравствуйте, _ALeRT_, Вы писали:
V>>например есть у меня в рабочей программе пользовательская функция, V>>которая готовит некоторую информацию в виде пары xml-файлов V>>добавляет к ним отчёт в html формате, всё это пакует zip-ом для передачи дальше по почте
_AL>ИМХО unit-test'ы (если мы все еще говорим о них) предназначены, преже всего, для тестирования внутренней логики программы (функции). Для того, чтобы это сделать не нужно выполнять всю ту сложную работу, которую ты описал. В данном случае стоит воспользоваться мок-объектами (mock objects), что позволит достаточно просто протестировать логику самой функции, а не работу всей программы в целом (что гораздо сложнее). Если же ты хочешь протестировать работу программы, то тебе подойдет регрессонное тестирование (оно-то и будет основанно на сравнении файлов).
ИМХО тут разделительная грань проходит не между регрессионным и unit тестированием
а между тестированием функций дающих небольшое количество скалярных значений,
и функций, результатом работы которых будет являться сложная аггрегатная структуры.
Вот я в одном проекте убедил людей что нужно использовать NUnit тесты и что..
они просто напросто стали для аггрегатных результатов функций писать проверку на то что это не нулл и всё..
на большее их не хватило
Кароче неважно, внутренняя это функция или это и есть вся программа..
количество ассертов которые приходится писать для тестирования сложной аггрегатной структуры а
также затраты на их сопровождение вполне сравнимо а то больше для Assert-ов чем для файлового сравнения..
кстати абсолютно внешняя нативная среда тут тоже не краеугольный камень..
вполне можно написать библиотеку для .NET когда можно будет писать без всяких внешних описаний в
стиле NUnit, описывая всю логику тестов аттрибутами..
Здравствуйте, Lloyd, Вы писали:
L>Здравствуйте, vvaizh, Вы писали: V>>Здравствуйте, Lloyd, Вы писали:
V>>>>>>1. меньше тестов L>>>>>Как этот подход уменьшит кол-во тестов? V>>>>ну как как.. за счёт того что сразу много параметров можно пихать, и правильно разруливать какой из них глючит.. L>>>Напиши функцию, кот сделать то же самое. V>>мне нужно на каждый такой случай функцию писать, думать.. V>>потом будет много функций, а тут — универсальный подход позволяющий не напрягать особо мозги.. L>А код сериализации в файл у тебя зам появляется?
It depends
Для целого ряда вариантов испогльзования он уже есть.. (отчёты, html странички, всякие конверторы)
В любом случае ИМХО печать в текстовый файл писать гораздо проще чем кучу сравнений
L>>>То есть молимся, чтобы датасет не дай бог переставит строчки? V>>ставим сортировку явную, если такое возможно.. L>Ну вот, начинается. Но что не сделаешь чтобы в фало записать и дифом воспользоваться.
целые статьи посвящены тому что нужно делать чтобы использовать NUnit тесты
тоже знаешь ли код часто приходится менять
V>>>>а тут можно общую забабашить L>>>Не забабашиш. Просто вводишь дополнительное звено. Тесты-то все-равно пишутся на прежнем языке.
V>>да, но они могут не подключать никаких дополнительных библиотек например.. V>>для тех же хранимых прцедур это актуально.. V>>да и вообще, нативную среду одну на всех написать да и не парится.. L>Не понял что ты имеешь в виду. Какую среду? Вот пишу я на шарпе, как мне использовать эту "нативную" среду?
на данный момент — писать консольную обвязку, вызывающую внутренние функции
хотя в плане — специальный адаптер, который позволит писать в стиле NUnit с аттрибутами
а загружатся будет "в среду" примерно так же как сейчас в NUnutGUI загружается
V>>>>я имею ввиду trace программы.. V>>>>который можно сравнивать с эталонным.. V>>>>ну или log выполнения, как тебе понятнее.. L>>>Боюсь, без модификации кода программы это не так-то легко сделать. V>>ну во первых большинство сложных программ и так имеют развитую систему логов L>Приведи, пожалуйста полный список большинства сложных программ, о котором ты говоришь.
зачем? полный?
все серверный и коммуникационные программы имеют логи
расчётные программы как правило тоже
многонитевые — как правило
и т.п.
L>P.S. Давай рассмотрим гипотетическую ситуацию. Ты выполняешь какое-то действие и должен проверить что в логе появилась запись. Эта запись должна иметь отметку о времени совершенного действия. Приведи схематичный пример того, как ты это будешь делать с твоим дифом.
ну ввожу как и в NUnit тестах специальный "тестовый" таймер который даёт "тестовое" время
что то вроде такого, но как я понимаю в секундах всё должно быть:
' <summary>тестовый класс для получения текущего времени (при каждом взятии возвращает время на день позже предыдущего)</summary>
Class TestTimeProvider
Implements ITimeProvider
' <summary>счётчик времени</summary>Public count As Integer = 0
' <summary>перезапустить счётчик времени</summary>Public Sub Reset()
count = 0
End Sub' <summary>получить текущее время</summary>Public ReadOnly Property Now() As DateTime Implements ITimeProvider.Now
Get
Dim ncount As Integer
ncount = count
count = count + 1
Return DateTime.Parse("03.02.1976").AddDays(ncount)
End Get
End Property
End Class
Ладно, задолбало спорить. Если тебе так понравился этот метод — исползуй его. Хозяин — барин. Я лично для себя не вижу в нем ничего интересного/полезного. Если будешь использовать, расскажи, что было удобно или неудобно в таком подходе.
Здравствуйте, vvaizh, Вы писали:
V>Собственно хочется обсудить почему большинство систем сравнивают каждое значение в отдельности, в то время как проще и удобнее гораздо сваливать все первые аргументы Assert.IsEqual() в файл и сравнивать их с эталонным файлом целиком
Хорошая мысль. Возял на вооружение.
Кстати автора Nemerle используют подобную систему.
... << RSDN@Home 1.1.4 stable SR1 rev. 568>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, WolfHound, Вы писали:
WH>Здравствуйте, vvaizh, Вы писали:
V>>Собственно хочется обсудить почему большинство систем сравнивают каждое значение в отдельности, в то время как проще и удобнее гораздо сваливать все первые аргументы Assert.IsEqual() в файл и сравнивать их с эталонным файлом целиком WH>Хорошая мысль. Возял на вооружение. WH>Кстати автора Nemerle используют подобную систему.
У них есть какая то инфраструктура для этого или что?
я по документации не нашёл ничего
Здравствуйте, vvaizh, Вы писали:
V>У них есть какая то инфраструктура для этого или что? V>я по документации не нашёл ничего
Их тесты примерно так выглядят. См конец.
Здравствуйте, WolfHound, Вы писали:
V>>У них есть какая то инфраструктура для этого или что? V>>я по документации не нашёл ничего WH>Их тесты примерно так выглядят. См конец.
Да, похоже на то
Но насколько я понимаю не проработан вопрос замены эталона реальным результатом
и просмотра результирующего файла каким нибудь вьюером (например html страницу целиком смотреть)
Кстати я тут подумал... ведь для этого можно прекрасно использовать SVN.
Ведь там есть все что нужно для такого тестирования... поиск изменений, добавление новых образцов, изменение текущих, удаление не нужных, распространение новых образцов всем челенам комманды.
Ставишь тортилку и у тебя есть практически готовый энжин для тестирования... все что нужно это чтобы файлы генерировались по нужным путям (можно задать иерархию... по папочкам разложить...).
... << RSDN@Home 1.1.4 stable SR1 rev. 568>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, WolfHound, Вы писали:
WH>Здравствуйте, vvaizh, Вы писали:
WH>Кстати я тут подумал... ведь для этого можно прекрасно использовать SVN. WH>Ведь там есть все что нужно для такого тестирования... поиск изменений, добавление новых образцов, изменение текущих, удаление не нужных, распространение новых образцов всем челенам комманды. WH>Ставишь тортилку и у тебя есть практически готовый энжин для тестирования... все что нужно это чтобы файлы генерировались по нужным путям (можно задать иерархию... по папочкам разложить...).
ну вообще говоря нечто похожее
хотя и не совсем
моя среда позволяет очень быстро (двухбуквенным шорткутом)
переключать режимы просмотра для каждого варианта:
— файл эталон
— файл — старый результат
— файл — разница (который диффом создан)
или в одном режиме опять же одной клавишей быстро просматривать все тличающиеся результаты
в тортойсе придётся оригинальную версию отдельно восстанавливать..
хотя да, подход применим и на NUnit ах без всяких лишних средств
(просто реализуешь функцию соответствующего файлового сравнения)
и у меня целый тестовый набор для ОРМ именно так и реализован (несколько сот тестов)
но не от хорошей жизни же я сел свою утилиту писать
надоело очень медленно сравнивать файлы используя традиционные средства..
кроме того, там отдельная песня — тестирование отчётов и прочих нагенерённых html-страниц..
для них у меня есть режим "броузер", когда я полученный файл просматриваю используя CHtmlView
у меня например очень удобно так php-шные страницы тестируются
я задаю на входе параметры запроса, состояние СУБД и состояние сессии
а на выходе тестирую html-страницу, состояние сессии и состояние базы
и все в виде текстовых файлов..
Здравствуйте, vvaizh, Вы писали:
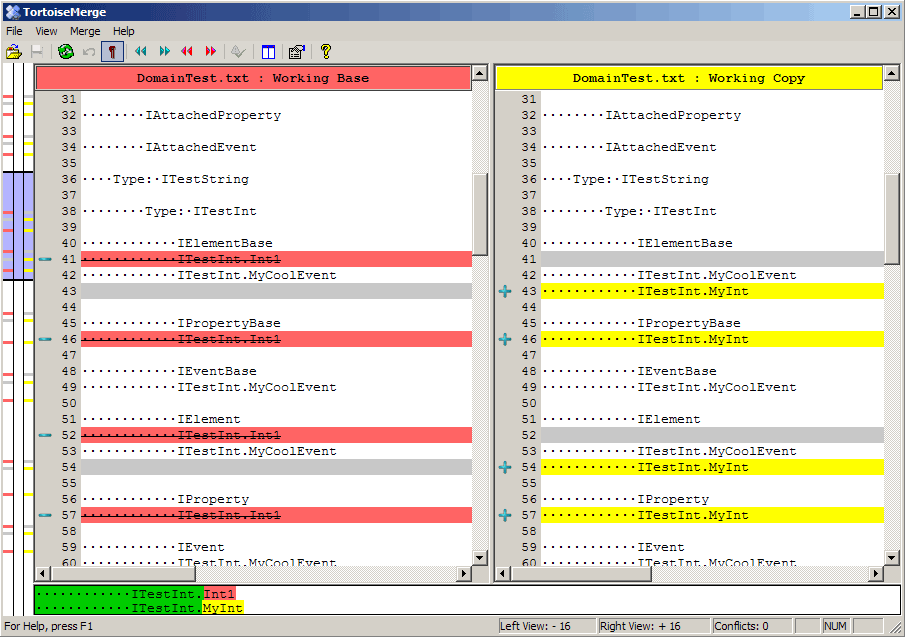
V>в тортойсе придётся оригинальную версию отдельно восстанавливать..
Зачем? Вот буквально сейчас тестирую одну программку.
В два клика получаю список изменившихся тестов. В одни клик открываю сравнение любого из файлов с эталоном. Тортилка показывает эталон и текущий файл. Причем различающияся куски раскрашены разным цветом. Все очень наглядно. Често говоря не понимаю в чем ты увидил проблему.
Никогда чтоли не пользовался тортилкой для того чтобы работать с обычнчми исходниками?
Тут главное не боятся писать результаты тестов прямо в рабочею копию... у нас ведь все это под контролем версионника...
... << RSDN@Home 1.1.4 stable SR1 rev. 568>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, WolfHound, Вы писали:
WH>Здравствуйте, vvaizh, Вы писали:
V>>в тортойсе придётся оригинальную версию отдельно восстанавливать.. WH>Зачем? Вот буквально сейчас тестирую одну программку. WH>В два клика получаю список изменившихся тестов. В одни клик открываю сравнение любого из файлов с эталоном. Тортилка показывает эталон и текущий файл. Причем различающияся куски раскрашены разным цветом. Все очень наглядно. Често говоря не понимаю в чем ты увидил проблему. WH>Никогда чтоли не пользовался тортилкой для того чтобы работать с обычнчми исходниками? WH>Тут главное не боятся писать результаты тестов прямо в рабочею копию... у нас ведь все это под контролем версионника...
Я не говорю что это не невозможно
я говорю что юзабилити специального приложения всё равно выше..
в смысле я надеюсь что то что у меня получилось — удобнее
но как грится на вкус и цвет..
я тоже с такого же примерно подхода начинал