Ещё в прошлом году дали в одной компании тестовое задание, которое мне показалось интересным сделать — во-первых, я на программиста не учился и сортировку файлов слиянием делать мне никогда не приходилось, только читал. Во-вторых, показалось, что в такой задаче можно как раз удачно поиграть с последними нововведениями в C# и dotnet и покапаться в спанах (может, в этом и была моя ошибка, подскажите).
Но так в открытую задание шарить не хотелось (чтобы не подводить компанию), а подготовить для общественного порицания своюь реализацию в более простом виде всё времени небыло, тормозил с этим
А раз уж аж видео-обзор этого задания вышел: Тестовое задание Senior .Net — критикуйте, то, думаю. не страшно, если я прям так. Если что, звиняйте.
Задание
На входе есть большой текстовый файл, где каждая строка имеет вид Number. String
Например:
415. Apple
30432. Something something something
1. Apple
32. Cherry is the best
2. Banana is yellow
Обе части могут в пределах файла повторяться. Необходимо получить на выходе другой файл, где
все строки отсортированы. Критерий сортировки: сначала сравнивается часть String, если она
совпадает, тогда Number.
Т.е. в примере выше должно получиться
1. Apple
415. Apple
2. Banana is yellow
32. Cherry is the best
30432. Something something something
Требуется написать две программы: Утилита для создания тестового файла заданного размера. Результатом работы должен быть
текстовый файл описанного выше вида. Должно быть какое-то количество строк с одинаковой
частью String.
Собственно сортировщик. Важный момент, файл может быть очень большой. Для тестирования
будет использоваться размер ~100Gb.
При оценке выполненного задания мы будем в первую очередь смотреть на результат
(корректность генерации/сортировки и время работы), во вторую на то, как кандидат пишет код.
Язык программирования: C#.
Решение моё интервьюеров не удовлетворило, говорят, что очень медленно работает: как обычно, у меня на лаптопе как раз всё летает, файл в 1Г сортируется за 13 с небольшим секунд, а у ревьюеров получилось 130c на файл 1 гиг Так мне написали.
Вот с тех пор мне интересно, где я мог пойти не тем путём: разница достаточно большаая, скорее всего на более медленном железе так плохо вышло не из-за каких-то микрооптимизаций, которые я не смог сделать, а в чём-то принципиальном. Но где
В целом как сделано: на вход программе сортировки подаётся путь к файлу и количество строк, на которые можно перед сортировкой разбить входной файл. Так мы можем подобрать, сколько памяти программа будет занимать.
Схематично, алгоритм такой: входной файл вычитывается PipeReader-ом: столько строк, сколько задано. Пока эти строки сохраняются в файл, начимаем вычитывать следующий буфер, дабы избежать простоя.
Затем открываем все созданные файлыб вычитываем по строке, сортируем, пишем в выходной файл меньшее значение и из этого файла вычитываем следующу строчку.
Буду брагодарем за объяснения, как это должно быть сделано правильно.
Сначала можно запустить GenerateFile.cmd, он создаст подпапку Results и в ней файл DataSort-1G.txt размером 1 гигабайт.
Командная строка:
@GenerateFile --FilePath "..\..\..\..\Results\DataSort-1G.txt" --RequiredLengthGiB 1
то есть путь к файлу и требуемый размер в гигабайтах. Размер можно указывать дробный, например 0.1 для 100-мегабайтного файла. Какие-то более тонкие настройки есть в AppSettings.json рядом с исполняемым файлом.
Потом (при необходимости нужно изменить текущую директорию снова на папку solution) можно запустить SortFile.cmd, он отсортирует файл, результат (единственный файл) будет в папке "Results\<guid>\"
Командная срока:
@SortFile --FilePath "..\..\..\..\Results\DataSort-1G.txt" --MaxReadLines 200000
Снова путь к файлу и количество строк, на которые можно перед сортировкой можно разбить входной файл. Этим параметром можно регулировать используемую оперативную память.
Так же, некоторые более тонкие настройки есть в AppSettings.json рядом с исполняемым файлом.
P.S. Мне показалось, что Алгоритмы более подходящий форум для этого обсуждения, но если нет — то давайте перенесём.
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, _FRED_, Вы писали:
_FR>Привет,
_FR>Вот с тех пор мне интересно, где я мог пойти не тем путём: разница достаточно большаая, скорее всего на более медленном железе так плохо вышло не из-за каких-то микрооптимизаций, которые я не смог сделать, а в чём-то принципиальном. Но где
Считаю, проблема в том, что у тебя MergeFilesAsync работает за O(N*K), где N — общее количество строк в исходном файле, и K — количество чанков.
Потому что на каждую строку ты меняешь список items с помощью операций Insert/RemoveAt.
А должно работать за O(N * log K)
Вероятно, проверяющий запускал тест с большим количество чанков (с меньшей потребляемой памятью).
_FR>В целом как сделано: на вход программе сортировки подаётся путь к файлу и количество строк, на которые можно перед сортировкой разбить входной файл. Так мы можем подобрать, сколько памяти программа будет занимать. _FR>Схематично, алгоритм такой: входной файл вычитывается PipeReader-ом: столько строк, сколько задано. Пока эти строки сохраняются в файл, начимаем вычитывать следующий буфер, дабы избежать простоя. _FR>Затем открываем все созданные файлыб вычитываем по строке, сортируем, пишем в выходной файл меньшее значение и из этого файла вычитываем следующу строчку.
_FR>Буду брагодарем за объяснения, как это должно быть сделано правильно.
Сам алгоритм норм, но реализация не очень.
Кроме кривой реализации merge еще добавлю:
— смешаны отслеживание прогресса и сам алгоритм, я бы разделил (с помощью хуков, например)
— возможно, не стоит использовать async. Это усложняет реализацию, но, по-моему не дает значимых плюсов. Почти все время работы алгоритмы — работа с диском. Сама сортировка в памяти — единицы процентов
— я использовал генераторы (yield), алгоритм упрощается. см. http://rsdn.org/forum/dotnet/8339349.1
Здравствуйте, Буравчик, Вы писали:
_FR>>Вот с тех пор мне интересно, где я мог пойти не тем путём: разница достаточно большаая, скорее всего на более медленном железе так плохо вышло не из-за каких-то микрооптимизаций, которые я не смог сделать, а в чём-то принципиальном. Но где Б>Считаю, проблема в том, что у тебя MergeFilesAsync работает за O(N*K), где N — общее количество строк в исходном файле, и K — количество чанков. Б>Потому что на каждую строку ты меняешь список items с помощью операций Insert/RemoveAt. Б>А должно работать за O(N * log K)
Спасибо. RemoveAt всегда удаляет последний элемент из списка, поэтому она сложности добавлять не должна.
Далее бинарным поиском находится, куда вставить новый элемент и это как раз и есть логарифм. Нет?
Экспериметы вроде это подтверждают: при разбиении гигабайтного файла на куски по 10,000 строк (198 файлов получается) время собственно мёрджа 00:00:07.6173967, при разбиении этого же файла на куски по 1000 строк (1,976 файлов) время мёрджа 00:00:13.2285478. Точно у меня там не логарифм?
P.S. Если вообще "отключить" сортировку, то есть удалять последний элемент списка и новую строку всегда добавляить в конец же, то 1,976 файлов сливаются за 8..9 секунд. Всё-таки кажется, что проблема не в этом.
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, _FRED_, Вы писали:
_FR>Спасибо. RemoveAt всегда удаляет последний элемент из списка, поэтому она сложности добавлять не должна. _FR>Далее бинарным поиском находится, куда вставить новый элемент и это как раз и есть логарифм. Нет?
Так еще insert есть, в середину
_FR>Экспериметы вроде это подтверждают: при разбиении гигабайтного файла на куски по 10,000 строк (198 файлов получается) время собственно мёрджа 00:00:07.6173967, при разбиении этого же файла на куски по 1000 строк (1,976 файлов) время мёрджа 00:00:13.2285478. Точно у меня там не логарифм?
Чтобы определить логарифм там или нет, надо мерять не весь этап мержа, а только on-CPU, т.е. только работу с items, без диска
P.S. Большая разница во времени могла также получиться из-за типа диска HDD/SSD/NVME
Best regards, Буравчик
Re[3]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>P.S. Если вообще "отключить" сортировку, то есть удалять последний элемент списка и новую строку всегда добавляить в конец же, то 1,976 файлов сливаются за 8..9 секунд. Всё-таки кажется, что проблема не в этом.
Ну, может и не в этом
А профайлер что говорит?
Best regards, Буравчик
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Буравчик, Вы писали:
_FR>>Спасибо. RemoveAt всегда удаляет последний элемент из списка, поэтому она сложности добавлять не должна. _FR>>Далее бинарным поиском находится, куда вставить новый элемент и это как раз и есть логарифм. Нет?
Б>Так еще insert есть, в середину
То есть вот это вот по сути имеет линейную сложность:
var index = list.BinarySearch(item);
list.Insert(index >= 0 ? index : ~index, item);
_FR>>Экспериметы вроде это подтверждают: при разбиении гигабайтного файла на куски по 10,000 строк (198 файлов получается) время собственно мёрджа 00:00:07.6173967, при разбиении этого же файла на куски по 1000 строк (1,976 файлов) время мёрджа 00:00:13.2285478. Точно у меня там не логарифм? Б>Чтобы определить логарифм там или нет, надо мерять не весь этап мержа, а только on-CPU, т.е. только работу с items, без диска Б>P.S. Большая разница во времени могла также получиться из-за типа диска HDD/SSD/NVME
Мне выдали такие вот:
Как ориентир по времени — 10Гб файл генерируется около 2,5 минут, сортируется — 9 (кстати, это не самое быстрое решение).
Дополнительный ориентир — при сортировке 1Гб используется 2-2,5 Гб памяти.
На моём стареньком лаптопе, хорошем, но совсем не геймерском с ССД ессно генерация файла в 10Г занимает 35 секунд, сортировка 140с (памяти при этом расходуется меньше гига).
Если мне сказали, что моя программа работает 130 секунд на гигабайтном файле и это медленно, значит у них есть программы, которые там же работают значительно быстрее.
Я подозреваю, что дело тут может быть или в работе с диском или в каком-то принципиально другом подходе, потому что иначе не вижу, почему вдруг мой код работает в 10 раз медленнее, чем их.
Вот и интересно, в чём же именно я так промахнулся.
Help will always be given at Hogwarts to those who ask for it.
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Буравчик, Вы писали:
_FR>>P.S. Если вообще "отключить" сортировку, то есть удалять последний элемент списка и новую строку всегда добавляить в конец же, то 1,976 файлов сливаются за 8..9 секунд. Всё-таки кажется, что проблема не в этом. Б>Ну, может и не в этом
Да точно не там. Половина времени (примерно, ±10%) у меня это разбивка большого файла на мелкие, другая половина — сборка обратно большого сортированного файла из этих мелких.
Б>А профайлер что говорит?
А я даже и не подозреваю на что ещё смотреть. Большая часть времени — работа с диском, что и вызывает подозрения или в неверном подходе к этим операциями (размеры буферов не верные, флаги не те) или может надо как-то иначе делать
Help will always be given at Hogwarts to those who ask for it.
Re: Как правильно сортировать содержимое больших файлов?
Решал эту задачу в реальном проекте в 2000-е. Но писал на C, поэтому мог позволить себе все. Да и исходный файл делал сам из других данных, так что мог его портить. Кроме того, надо было получить возможность доступа в порядке отсортированности, а собственно передвижение строк не требовалось.
Решение
Открываем file mapping и view на весь файл.
За линейное время проходим весь файл, заменяем разделитель внутри строки на '\0'. Конец строки тоже заменяем на '\0'. Одновременно строим массив указателей (смещение от начала файла + базовый адрес view) для каждой строки.
Этот массив и сортируем обычной qsort, используя strcmp в качестве int (*compare), так как строка заканчивается '\0'. Если strcmp возвращает 0 для первого критерия, strcmp по второму критерию.
Потом можно пройти файл заново, вернуть концы строк и разделители, но мне это было не нужно.
Если таки нужен выходной файл — пройти массив указателей линейно, переписывая строки в новый файл.
P.S. В действительности все было немного иначе. Полей в строке было 5-6 штук и надо было отсортировать по каждому полю. Так что массивов указателей было столько же и каждый сортировался.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Решал эту задачу в реальном проекте в 2000-е. Но писал на C, поэтому мог позволить себе все. Да и исходный файл делал сам из других данных, так что мог его портить. Кроме того, надо было получить возможность доступа в порядке отсортированности, а собственно передвижение строк не требовалось. PD>Решение PD>Открываем file mapping и view на весь файл. PD>За линейное время проходим весь файл, заменяем разделитель внутри строки на '\0'. Конец строки тоже заменяем на '\0'. Одновременно строим массив указателей (смещение от начала файла + базовый адрес view) для каждой строки.
Хм. У меня в файле на 10 гиг 19,759,295 строк. Получается, файл на 200 гиг может содержать порядка (x20) 395,185,900 строк. Уже, вроде, гига полтора интов.
PD>Этот массив и сортируем обычной qsort, используя strcmp в качестве int (*compare), так как строка заканчивается '\0'. Если strcmp возвращает 0 для первого критерия, strcmp по второму критерию.
Исходный файл:
415. Apple
30432. Something something something
1. Apple
32. Cherry is the best
2. Banana is yellow
после преобразования:
415
Apple
30432
Something something something
1
Apple
32
Cherry is the best
2
Banana is yellow
Если я правильно понял предлагаемый алгоритм, то после сортировки будет:
1
2
30432
32
415
Apple
Apple
Banana is yellow
Cherry is the best
Something something something
И как потом собрать из этого то, что должно получиться в итоге:
1. Apple
415. Apple
2. Banana is yellow
32. Cherry is the best
30432. Something something something
Не расскажете подробнее часть про сортировку, как в ней учесть порядок полей. по которым надо сортировать и как потом собрать результат обратно?
Help will always be given at Hogwarts to those who ask for it.
Re[3]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Хм. У меня в файле на 10 гиг 19,759,295 строк. Получается, файл на 200 гиг может содержать порядка (x20) 395,185,900 строк. Уже, вроде, гига полтора интов.
Тогда на них тоже file mapping. Хотя этого я не делал, за скорость не поручусь.
PD>>Этот массив и сортируем обычной qsort, используя strcmp в качестве int (*compare), так как строка заканчивается '\0'. Если strcmp возвращает 0 для первого критерия, strcmp по второму критерию.
_FR>Исходный файл: _FR>
_FR>415. Apple
_FR>30432. Something something something
_FR>1. Apple
_FR>32. Cherry is the best
_FR>2. Banana is yellow
_FR>
После преобразования будет
415\0Apple\0
30432\0Something something something\0
1\0Apple\0
32\0Cherry is the best\0
2\0Banana is yellow\0
(точки я убрал, но они погоды не делают)
А массив указателей — на начала каждой исходной строки : p[0] на 415, p[1] на 30432 и т.д.
И тогда p[i] — указатель на число в строке, а p[i] + strlen(p[i]) — указатель на текстовую часть строки
Ну и все. qsort на этот p. В compare сравниваем как нам надо. Строки не переставляем, только p[i] будут переставлены.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Этот массив и сортируем обычной qsort, используя strcmp в качестве int (*compare), так как строка заканчивается '\0'. Если strcmp возвращает 0 для первого критерия, strcmp по второму критерию.
Такой вариант будет медленнее, чем merge-сорт. Потому что кардинально поменяется работа с диском, вместо sequential read&write будет выполняться random read&write.
Best regards, Буравчик
Re: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>После преобразования будет PD>415\0Apple\0 PD>30432\0Something something something\0 PD>1\0Apple\0 PD>32\0Cherry is the best\0 PD>2\0Banana is yellow\0
PD>(точки я убрал, но они погоды не делают)
Тогда не понял: вы ранее писали, что "Конец строки тоже заменяем на '\0'.". Что такое "конец строки"? В винде это два символа \r\n. Каждый из них нужно заменить на \0 или только какой-то один?
PD>А массив указателей — на начала каждой исходной строки : p[0] на 415, p[1] на 30432 и т.д. PD>И тогда p[i] — указатель на число в строке, а p[i] + strlen(p[i]) — указатель на текстовую часть строки PD>Ну и все. qsort на этот p. В compare сравниваем как нам надо. Строки не переставляем, только p[i] будут переставлены.
Это часть понял, спасибо. Действительно, не могу представить, что случайные перескакивания по файлу, размер которого значительно больше объёма оперативной памяти, будут быстрее.
Help will always be given at Hogwarts to those who ask for it.
Re[5]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Тогда не понял: вы ранее писали, что "Конец строки тоже заменяем на '\0'.". Что такое "конец строки"? В винде это два символа \r\n. Каждый из них нужно заменить на \0 или только какой-то один?
Вообще не нужно ничего заменять. Достаточно сохранять индекс начала строки. А еще лучше сохранять индексы начала и длину строки, но потребуется чуть больше памяти.
Заменялось на \0, наверное, для того, чтобы использовать библиотечную оптимизированную strcmp. В задаче данного топика это не дает такой выгоды.
Best regards, Буравчик
Re[6]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Буравчик, Вы писали:
_FR>>Тогда не понял: вы ранее писали, что "Конец строки тоже заменяем на '\0'.". Что такое "конец строки"? В винде это два символа \r\n. Каждый из них нужно заменить на \0 или только какой-то один? Б>Вообще не нужно ничего заменять. Достаточно сохранять индекс начала строки. А еще лучше сохранять индексы начала и длину строки, но потребуется чуть больше памяти. Б>Заменялось на \0, наверное, для того, чтобы использовать библиотечную оптимизированную strcmp. В задаче данного топика это не дает такой выгоды.
Да, в таком разрезе это понятно: при каждом сравнении так сможем распарсить всю строку и сравнить как нужно.
Help will always be given at Hogwarts to those who ask for it.
Re[5]: Как правильно сортировать содержимое больших файлов?
_FR>Тогда не понял: вы ранее писали, что "Конец строки тоже заменяем на '\0'.". Что такое "конец строки"? В винде это два символа \r\n. Каждый из них нужно заменить на \0 или только какой-то один?
Первый, то есть \r. Мне надо, чтобы каждая строка исходного файла превратилась в 2 строки ASCIIZ. Что будет после второй ASCIIZ — не важно, так как использоваться не будет
Исходно
415 Apple
То есть
415 Apple\r\n
После преобразования
415\0Apple\0\n
Имеем 2 строки ASCIIZ и указатель на первую из них. Если к нему прибавить strlen(первой) + 1, получим указатель на вторую, она тоже ASCIIZ. А что там за вторым нулем — мне совсем не важно.
With best regards
Pavel Dvorkin
Re[6]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Буравчик, Вы писали:
Б>Заменялось на \0, наверное, для того, чтобы использовать библиотечную оптимизированную strcmp. В задаче данного топика это не дает такой выгоды.
Да. Я же писал, там в действительности было 5 или 6 полей. Записал \0 в конец каждого и stricmp
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Нашел у себя этот код, и даже замеры времени. PD>Файл размером примерно в 1 Гбайт. Максимальное количество строк 1 миллион. Время на сортировку в разных случаях от 1-2 минут до 5-10 минут. PD>Писал я это в 2002 году. Pentium III, 666 Mhz, 256 Мб ОП, винчестер на 80 Гб. Хорошая была машинка, на тот момент одна из лучших в университете
О, так может удастся запустить сейчас, можно будет и померить?
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, _FRED_, Вы писали:
_FR>О, так может удастся запустить сейчас, можно будет и померить?
Увы, запустить не удастся. Эти csv файлы делаются из других, а тех у меня уже давно нет. Да и не помню я, что и как именно там запускалось — все же 20 лет прошло.
With best regards
Pavel Dvorkin
Re: Как правильно сортировать содержимое больших файлов?
1. это не merge sort, там есть вставка в середину.
2. а это вообще работает на объеме файла, который не влазит в память? Т.е. у тестеров оно могло просто свалиться в использование файла подкачки.
3. asynс здесь могут сослужить очень плохую службу, вместо этого руками запускать потоков (тасков) ровно столько, сколько есть ядер (для серверного кода это неприемлемо, но тут у нас выдуманное окружение).
В соревнованиях по сортировке (есть и такие, да) при merge sort вроде бы используют heap.
Типа, делать "heapify" оказывается быcтрее, чем из раза в раз пробегать по списку указателей на сегмент и выбирать сегмент с наименьшей головой.
Re[2]: Как правильно сортировать содержимое больших файлов?
Вы же это мне отвечали, на стартовое сообщение, верно?
AC>1. это не merge sort, там есть вставка в середину.
Где?
AC>2. а это вообще работает на объеме файла, который не влазит в память? Т.е. у тестеров оно могло просто свалиться в использование файла подкачки.
А почему не должно? в какой момент времени в памяти может оказаться количество данных, пропорциональное размеру входного файла?
AC>3. asynс здесь могут сослужить очень плохую службу, вместо этого руками запускать потоков (тасков) ровно столько, сколько есть ядер (для серверного кода это неприемлемо, но тут у нас выдуманное окружение).
Help will always be given at Hogwarts to those who ask for it.
Re[3]: Как правильно сортировать содержимое больших файлов?
_FR>Вы же это мне отвечали, на стартовое сообщение, верно?
На стоартовое.
_FR>Где? _FR>А почему не должно? в какой момент времени в памяти может оказаться количество данных, пропорциональное размеру входного файла?
Тогда я фигово понял ваше решение.
"Правильное" решение, думаю, такое:
1. Читаем файл по секциям, каждую секцию параллельно сортируем обычным List.Sort, сохраняем в новые файлы
1.1. Читаем и пишем в одином потоке;
1.2. Сортируем в потоках, равных количеству ядер (скорее всего с учетом гипер-трединга);
2. Делаем merge sort, т.е. пока все секции не кончатся, выбираем наилучшую.
2.1 Как хорошо организовать буферизацию тут я не знаю, но, вероятно, поможет mmf, особенно если они "совместимы" с Memory и Span. Типа, может можно легко избежать аллоцирования managed-памяти для каждой строки.
2.2. Если секций много, вероятно, вместо того, чтобы каждый раз из списка выбирать лучшую секцию, можно использовать heap. Heap, естественно, делать каннонично, на массиве, а не дереве с указетелями
Re[4]: Как правильно сортировать содержимое больших файлов?
AC>>"Правильное" решение, думаю, такое: AC>>1. Читаем файл по секциям, …
_FR>А как это? Что в вашем понимании секция и как их найти в файле?
Завести очередь несортированных списков List<List<string>>. Запустить поток, который этот список пополняет, посто последовательно читая из stream.
Запустить поток, который смотрит на этот списко и запускает потоки сортировки (не больше, чем ядер). Отсортированные списки строк складываются в новую очередь.
Первый поток поток (который читает), пишет отсортированные списки во временные файлы (вероятно, совмещать чтение и запись именно в одном потоке не обязательно; цель, не перемежать обращения к диску).
Может быть можно сделать код проще: запускать одновременно тасков по числу ядрер.
В каждом таске "захватываем чтение-запись" (просто lock на любом объекте), читаем кусок из stream.
Сортируем.
"Захватываем чтение-запись", пишем во временный файл.
Таких тасков можно запустить, чуть больше, чем ядер, и там, где "сортируем" сделать блокировку через семафор по числу ядер.
Наверное, так.
Re: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Решение моё интервьюеров не удовлетворило, говорят, что очень медленно работает: как обычно, у меня на лаптопе как раз всё летает, файл в 1Г сортируется за 13 с небольшим секунд, а у ревьюеров получилось 130c на файл 1 гиг Так мне написали.
Диски могут быть разные (особенно весело, если тестируется в docker/kubernetes с настройками по-умолчанию, там все оооочень медленно). И локальная память. Сколько у вас на машине памяти? Вдруг окажется, что все записанные файлы потом читаются не с диска, а из дискового кэша? Хорошо бы было писать на диск. За неимением диска попробуйте хотя бы флешку (внешний жесткий диск будет идеальным решением). Там случайный доступ не так плох, как в блинных конструкциях, но скорость — низкая. Если промахнулись с буферами, может быть заметно. И если на машине много памяти — перезагружайтесь между этапами (генерация->разбиение->слияние), чтобы данные из кэша удалялись. Или отмонтируйте/примонтируйте ее, только сравните скорость с перезагрузкой.
_FR>В целом как сделано: на вход программе сортировки подаётся путь к файлу и количество строк, на которые можно перед сортировкой разбить входной файл.
Разбивать было бы правильно динамически, исходя из доступной/выделенной памяти. Т.е. быть более агрессивным в ее использовании.
_FR>Схематично, алгоритм такой: входной файл вычитывается PipeReader-ом: столько строк, сколько задано... Пока эти строки сохраняются в файл, начимаем вычитывать следующий буфер, дабы избежать простоя.
Вот здесь на дисковой подсистеме у вас начинаются сложности. Писать и читать одновременно — это лишние позиционирования головок диска. Очень хорошо было бы их разделять. Т.е. сначала читаем порцию данных (это рабочая порция). (*) Начинаем читать следующую порцию данных. Пока данные читаются, сортируем рабочую порцию. Дожидаемся завершения чтения "следующей порции". Записываем рабочую порцию. Устанавливаем "текущую порцию" в "следующую порцию". Повторяем начиная с (*). В этом случае чтение может быть вообще линейным. Запись линейной не будет никогда (пишутся данные, потом метадата). Буферизация вроде бы нормально настроена. Можно еще сказать CanSeek: false.
_FR>Буду брагодарем за объяснения, как это должно быть сделано правильно.
Для начала — выкинуть всю асинхронность. У вас все равно весь код работает последовательно. Если все сделано правильно, то он утыкается в производительность ввода/вывода. Этим вводом управляете вы, так что загрузить дисковую систему можете. Все эти async/await усложняют код и добавляют накладные расходы на управление асинхронностью. А тольку — только немного от выделения сортировки. Далее — стоит все читать StreamReader'ом (и буфер ему можно дать). Вот какой смысл заморачиваться с PipeReader, Encoder и всем остальным? Я даже посмотрел его исходники и соответствующие ему исходники StreamPipeReader. Так вот, я не вижу, чтобы ReadAsync запускал упреждающую операцию чтения следующего буфера пока мы разбираем текущие данные. Т.е. вы ничего по сравнению с StreamReader.nextLine() не выигрываете.
Далее. Строки стоит разобрать в объекты/записи со строкой и числом. Иначе вы на каждое сравнение сканируете префикс. Какая там длина среднего случайно распределенного числа? 7-8 символов? При этом сравнение строк имеет хорошие шансы закончиться на первом/втором символе. Ну и не нужно будет parseInt делать для сравнения. Ну и тут же еще одно замечание. Вы уверены, что list.clear() хоть в чем-то лучше создания нового списка?
После разбора/чтения/записи можно делать слияние. У вас там тоже все очень последовательно (и можно сделать синхронно). Кстати, как раз там у вас используется StreamReader, зачем в других местах нужно было все усложнять? В слиянии стоит использовать правильную структуру. Ну хотя бы начать с PriorityQueue. Потом можно вручную сделать heap. На ручном heap можно уменьшить количество балансировок (вместо двух — на извлечение и на добавление можно делать одну — после извлечения и добавления нового состояния). Решающим для скорости это быть не должно, но все же.
Вот уже после этого можно оптимизировать. Например, вынести сортировку в отдельный поток. Отдельный поток — это Thread.Start(), Thread.Join(), никаких тасков и асинхронности. Замерить увеличение скорости (при работе с флешкой, ага ). Потом сделать параллельно чтение с записью, оценить прибавку скорости. На данном этапе оно может дать небольшую прибавку, так как у вас все же есть небольшие промежутки, когда производятся вычисление. А может вызвать замедление (на жестком диске). Но даже если и есть, прибавка в теории должна быть небольшая (единицы процентов).
Re[6]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, AtCrossroads, Вы писали:
AC>>>"Правильное" решение, думаю, такое: AC>>>1. Читаем файл по секциям, … _FR>>А как это? Что в вашем понимании секция и как их найти в файле?
AC>Завести очередь несортированных списков List<List<string>>. Запустить поток, который этот список пополняет, посто последовательно читая из stream. AC>Запустить поток, который смотрит на этот списко и запускает потоки сортировки (не больше, чем ядер). Отсортированные списки строк складываются в новую очередь. AC>Первый поток поток (который читает), пишет отсортированные списки во временные файлы (вероятно, совмещать чтение и запись именно в одном потоке не обязательно; цель, не перемежать обращения к диску).
Я почему-то думал, что чтение из файла будет медленнее сортировки списка и сохранения его в отдельный файл, поэтому сделал только два списка, которые меня по очереди.
Сейчас поэксперементировал и таки да, видимо, сохранение медленнее и можно сохранять одновременно больше файлов. Над этим поработаю, спасибо.
AC>Может быть можно сделать код проще: запускать одновременно тасков по числу ядрер. AC>В каждом таске "захватываем чтение-запись" (просто lock на любом объекте), читаем кусок из stream.
А как это вяжется с необходимостью находить начала-конца строк в файле? Как нам гарантировать, что "кусок из stream" начнётся с начала строки?
Help will always be given at Hogwarts to those who ask for it.
Re: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Вот с тех пор мне интересно, где я мог пойти не тем путём: разница достаточно большаая, скорее всего на более медленном железе так плохо вышло не из-за каких-то микрооптимизаций, которые я не смог сделать, а в чём-то принципиальном. Но где
Попробовал запустить на линукс. Программа ест 2-3 Гб оперативки (назависимо от размера файла).
Конечно, может это особенность .NET на линукс. Но если также работает и на windows, то программа может банально уходить в своп.
Best regards, Буравчик
Re[2]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, maxkar, Вы писали:
_FR>>Решение моё интервьюеров не удовлетворило, говорят, что очень медленно работает: как обычно, у меня на лаптопе как раз всё летает, файл в 1Г сортируется за 13 с небольшим секунд, а у ревьюеров получилось 130c на файл 1 гиг Так мне написали. M>Диски могут быть разные (особенно весело, если тестируется в docker/kubernetes с настройками по-умолчанию, там все оооочень медленно). И локальная память. Сколько у вас на машине памяти? Вдруг окажется, что все записанные файлы потом читаются не с диска, а из дискового кэша? Хорошо бы было писать на диск. За неимением диска попробуйте хотя бы флешку (внешний жесткий диск будет идеальным решением). Там случайный доступ не так плох, как в блинных конструкциях, но скорость — низкая. Если промахнулись с буферами, может быть заметно. И если на машине много памяти — перезагружайтесь между этапами (генерация->разбиение->слияние), чтобы данные из кэша удалялись. Или отмонтируйте/примонтируйте ее, только сравните скорость с перезагрузкой.
Спасибо, это я учту, поэксперементировать со флешкой не догадался.
_FR>>В целом как сделано: на вход программе сортировки подаётся путь к файлу и количество строк, на которые можно перед сортировкой разбить входной файл. M>Разбивать было бы правильно динамически, исходя из доступной/выделенной памяти. Т.е. быть более агрессивным в ее использовании.
Это мне показалость излишним для тестового задания, ибо 1) тут можно долго подбирать хорошую эвристику и 2) если вдруг код будут запускать на машинке в большим объёмом памяти, то показать, как она умеет работать с малым будет сложно.
_FR>>Схематично, алгоритм такой: входной файл вычитывается PipeReader-ом: столько строк, сколько задано... Пока эти строки сохраняются в файл, начимаем вычитывать следующий буфер, дабы избежать простоя. M>Вот здесь на дисковой подсистеме у вас начинаются сложности. Писать и читать одновременно — это лишние позиционирования головок диска.
Наверное да, показалось странным работать с большими файлами в шаше время на ХДД (но тогда и на памяти экономить, наверное, было бы и не нужно).
M>Очень хорошо было бы их разделять. Т.е. сначала читаем порцию данных (это рабочая порция). (*) Начинаем читать следующую порцию данных. Пока данные читаются, сортируем рабочую порцию. Дожидаемся завершения чтения "следующей порции". Записываем рабочую порцию. Устанавливаем "текущую порцию" в "следующую порцию". Повторяем начиная с (*). В этом случае чтение может быть вообще линейным. Запись линейной не будет никогда (пишутся данные, потом метадата). Буферизация вроде бы нормально настроена.
Спасибо, интересная идея, это попробую.
M>Можно еще сказать CanSeek: false.
Где это можно сказать?
_FR>>Буду брагодарем за объяснения, как это должно быть сделано правильно. M>Для начала — выкинуть всю асинхронность. У вас все равно весь код работает последовательно. Если все сделано правильно, то он утыкается в производительность ввода/вывода. Этим вводом управляете вы, так что загрузить дисковую систему можете. Все эти async/await усложняют код и добавляют накладные расходы на управление асинхронностью.
Неужели накладные расходы на асинхронность будут сравнимы в вашем понимании с накладными расходами на ввод-вывод или на вручную щзапущенные потоки?
M>А тольку — только немного от выделения сортировки.
Нет: async вызван использованием PipeReader-а, а он выбран как средство, позволяющее минимизировать объём используемой памяти (по сравнению, например, со StreamReader::ReadLine()).
M>Далее — стоит все читать StreamReader'ом (и буфер ему можно дать). Вот какой смысл заморачиваться с PipeReader, Encoder и всем остальным?
Я сделал реализацию на StreamReader::ReadLine(), чтобы увидеть, что смысл есть и разница в скорости (на выделении памяти под строки) и в самой используемой памяти мне понравилась.
M>Я даже посмотрел его исходники и соответствующие ему исходники StreamPipeReader. Так вот, я не вижу, чтобы ReadAsync запускал упреждающую операцию чтения следующего буфера пока мы разбираем текущие данные. Т.е. вы ничего по сравнению с StreamReader.nextLine() не выигрываете.
В PipeReader мы управляем тем, сколько ему вычитывать и куда. Мои эксперементы показали, что с ним можно прочитать файл быстрее и потратить меньше памяти.
M>Далее. Строки стоит разобрать в объекты/записи со строкой и числом. Иначе вы на каждое сравнение сканируете префикс. Какая там длина среднего случайно распределенного числа? 7-8 символов? При этом сравнение строк имеет хорошие шансы закончиться на первом/втором символе. Ну и не нужно будет parseInt делать для сравнения.
Хм, спасибо, подумаю. Тут идея та же: не тратить память повторно. Строковая часть может быть достаточно большой и дублировать её совсем не хотелось.
M>Ну и тут же еще одно замечание. Вы уверены, что list.clear() хоть в чем-то лучше создания нового списка?
Конечно. Списки-то большие, а вся идея была в том, что бы потратить как можно меньше памяти.
M>После разбора/чтения/записи можно делать слияние. У вас там тоже все очень последовательно (и можно сделать синхронно). Кстати, как раз там у вас используется StreamReader, зачем в других местах нужно было все усложнять? В слиянии стоит использовать правильную структуру. Ну хотя бы начать с PriorityQueue. Потом можно вручную сделать heap. На ручном heap можно уменьшить количество балансировок (вместо двух — на извлечение и на добавление можно делать одну — после извлечения и добавления нового состояния). Решающим для скорости это быть не должно, но все же.
Да, сортировка на время операций влияния почти не оказывает. Вам кажется, что она будет выглядеть легче/понятнее, чем BinarySerach/Insert в список? Зачем тогда менять?
M>Вот уже после этого можно оптимизировать. Например, вынести сортировку в отдельный поток. Отдельный поток — это Thread.Start(), Thread.Join(), никаких тасков и асинхронности. Замерить увеличение скорости (при работе с флешкой, ага ). Потом сделать параллельно чтение с записью, оценить прибавку скорости. На данном этапе оно может дать небольшую прибавку, так как у вас все же есть небольшие промежутки, когда производятся вычисление. А может вызвать замедление (на жестком диске). Но даже если и есть, прибавка в теории должна быть небольшая (единицы процентов).
Это всё не так прозаично интересно. Мне интересно, как должен выглядеть алгоритм, который работает быстрее на порядок.
Help will always be given at Hogwarts to those who ask for it.
Re[2]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Буравчик, Вы писали:
_FR>>Вот с тех пор мне интересно, где я мог пойти не тем путём: разница достаточно большаая, скорее всего на более медленном железе так плохо вышло не из-за каких-то микрооптимизаций, которые я не смог сделать, а в чём-то принципиальном. Но где
Б>Попробовал запустить на линукс. Программа ест 2-3 Гб оперативки (назависимо от размера файла). Б>Конечно, может это особенность .NET на линукс. Но если также работает и на windows, то программа может банально уходить в своп.
На сколько строк разбивали файл (второй параметр командной строки)? Размер потребляемой памяти должен записеть не от размера входного файла, а от этого параметра.
Help will always be given at Hogwarts to those who ask for it.
Re[2]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Буравчик, Вы писали:
_FR>>Вот с тех пор мне интересно, где я мог пойти не тем путём: разница достаточно большаая, скорее всего на более медленном железе так плохо вышло не из-за каких-то микрооптимизаций, которые я не смог сделать, а в чём-то принципиальном. Но где
Б>Попробовал запустить на линукс. Программа ест 2-3 Гб оперативки (назависимо от размера файла). Б>Конечно, может это особенность .NET на линукс. Но если также работает и на windows, то программа может банально уходить в своп.
Поправил ошибку в конфигурации
Можно обновиться, поправить локально или указать дополнительный параметр "--File:MergeFileWriteBufferSizeMiB 1"
Help will always be given at Hogwarts to those who ask for it.
Re[5]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Если мне сказали, что моя программа работает 130 секунд на гигабайтном файле и это медленно, значит у них есть программы, которые там же работают значительно быстрее.
Интересно, они сравнивают со своим велосипедом или с UNIX-утилитой sort? Эта утилита портирована под Windows.
Re[3]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, Буравчик, Вы писали:
_FR>>>Вот с тех пор мне интересно, где я мог пойти не тем путём: разница достаточно большаая, скорее всего на более медленном железе так плохо вышло не из-за каких-то микрооптимизаций, которые я не смог сделать, а в чём-то принципиальном. Но где
Б>>Попробовал запустить на линукс. Программа ест 2-3 Гб оперативки (назависимо от размера файла). Б>>Конечно, может это особенность .NET на линукс. Но если также работает и на windows, то программа может банально уходить в своп.
_FR>Поправил ошибку в конфигурации _FR>Можно обновиться, поправить локально или указать дополнительный параметр "--File:MergeFileWriteBufferSizeMiB 1"
Запустил с новой конфигурацией
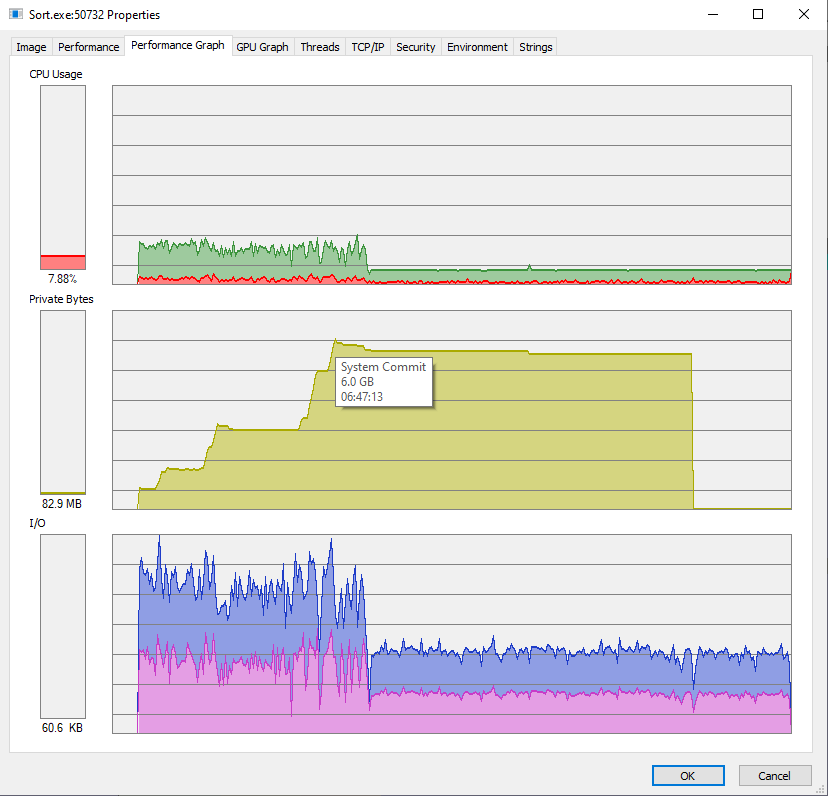
Чанки по 10_000 строк
File "DataSort-10G.txt" sorted as "DataSort-10G-1981.txt" in 00:02:35.0843764.
Command being timed: "nocache ./SortFile --FilePath /home/USER/DataSort-10G.txt --MaxReadLines 10000"
User time (seconds): 139.03
System time (seconds): 23.07
Percent of CPU this job got: 104%
Elapsed (wall clock) time (h:mm:ss or m:ss): 2:35.59
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 2186664
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 102
Minor (reclaiming a frame) page faults: 1934872
Voluntary context switches: 350870
Involuntary context switches: 2089
Swaps: 0
File system inputs: 41969328
File system outputs: 41950936
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
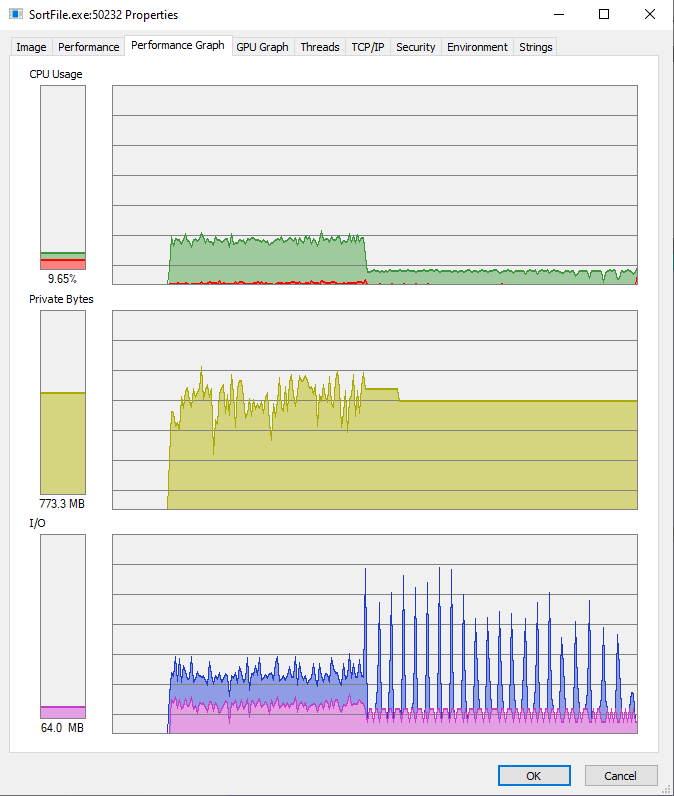
Чанки по 100_000 строк. Да, потребление уменьшилось
Command being timed: "nocache ./SortFile --FilePath /home/USER/DataSort-10G.txt --MaxReadLines 100000"
User time (seconds): 115.12
System time (seconds): 22.52
Percent of CPU this job got: 106%
Elapsed (wall clock) time (h:mm:ss or m:ss): 2:09.62
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 675316
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 106
Minor (reclaiming a frame) page faults: 2260903
Voluntary context switches: 329002
Involuntary context switches: 1429
Swaps: 0
File system inputs: 41963448
File system outputs: 41943816
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
Но все равно потребление памяти большое.
Для сравнения — вывод сортировки на питоне для чанков 10_000 строк.
Работает чуть быстрее, потребляет меньше памяти. Это в один поток, без асинков
User time (seconds): 89.14
System time (seconds): 36.63
Percent of CPU this job got: 87%
Elapsed (wall clock) time (h:mm:ss or m:ss): 2:23.48
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 111604
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 7
Minor (reclaiming a frame) page faults: 27239
Voluntary context switches: 240699
Involuntary context switches: 1086
Swaps: 0
File system inputs: 41961088
File system outputs: 41950944
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
Best regards, Буравчик
Re[3]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Спасибо, это я учту, поэксперементировать со флешкой не догадался.
На линуксе есть утилиты, которые сбрасывают кэш, а также могут ограничить кэширование любого процесса. Может и под виндой такое есть.
M>>Очень хорошо было бы их разделять. Т.е. сначала читаем порцию данных (это рабочая порция). (*) Начинаем читать следующую порцию данных. Пока данные читаются, сортируем рабочую порцию. Дожидаемся завершения чтения "следующей порции". Записываем рабочую порцию. Устанавливаем "текущую порцию" в "следующую порцию". Повторяем начиная с (*). В этом случае чтение может быть вообще линейным. Запись линейной не будет никогда (пишутся данные, потом метадата). Буферизация вроде бы нормально настроена.
_FR>Спасибо, интересная идея, это попробую.
Это достигается с помощью асинков. Нужно только уменьшить их количество.
Асинхронными должны быть задачи, работающие с целыми чанками, а не строками.
Другой вариант — очереди.
При разбиении — один поток пишет в очередь, другой (или несколько) сортирует и записывает чанки.
При мерже — один поток читает и сортирует, второй пишет результирующий файл
_FR>В PipeReader мы управляем тем, сколько ему вычитывать и куда. Мои эксперементы показали, что с ним можно прочитать файл быстрее и потратить меньше памяти.
Имхо системных буферов достаточно, зачем это все настраивать?
M>>Ну и тут же еще одно замечание. Вы уверены, что list.clear() хоть в чем-то лучше создания нового списка? _FR>Конечно. Списки-то большие, а вся идея была в том, что бы потратить как можно меньше памяти.
Согласен, это может быть лучше для GC
M>>После разбора/чтения/записи можно делать слияние. У вас там тоже все очень последовательно (и можно сделать синхронно). Кстати, как раз там у вас используется StreamReader, зачем в других местах нужно было все усложнять? В слиянии стоит использовать правильную структуру. Ну хотя бы начать с PriorityQueue. Потом можно вручную сделать heap. На ручном heap можно уменьшить количество балансировок (вместо двух — на извлечение и на добавление можно делать одну — после извлечения и добавления нового состояния). Решающим для скорости это быть не должно, но все же.
_FR>Да, сортировка на время операций влияния почти не оказывает. Вам кажется, что она будет выглядеть легче/понятнее, чем BinarySerach/Insert в список? Зачем тогда менять?
Это спорное утверждение.
Я думаю, не влияет за счет асинхронности. Потому что чанк мержится быстрее, чем записывается на диск.
M>>Вот уже после этого можно оптимизировать. Например, вынести сортировку в отдельный поток. Отдельный поток — это Thread.Start(), Thread.Join(), никаких тасков и асинхронности. Замерить увеличение скорости (при работе с флешкой, ага ). Потом сделать параллельно чтение с записью, оценить прибавку скорости. На данном этапе оно может дать небольшую прибавку, так как у вас все же есть небольшие промежутки, когда производятся вычисление. А может вызвать замедление (на жестком диске). Но даже если и есть, прибавка в теории должна быть небольшая (единицы процентов).
_FR>Это всё не так прозаично интересно. Мне интересно, как должен выглядеть алгоритм, который работает быстрее на порядок.
Лучший алгоритм Вы реализовали — external merge sort.
Это IO-bound задача. Нужно просто загрузить диск на 100% последовательным доступом.
На порядок улучшить нельзя имхо.
Ваша реализация работает достаточно быстро (хотя написана сложно, на мой взгляд). И почему-то жрет память.
У проверяющих что-то пошло не так. Возможно из-за этого жора.
Best regards, Буравчик
Re[7]: Как правильно сортировать содержимое больших файлов?
AC>>Может быть можно сделать код проще: запускать одновременно тасков по числу ядрер. AC>>В каждом таске "захватываем чтение-запись" (просто lock на любом объекте), читаем кусок из stream.
_FR>А как это вяжется с необходимостью находить начала-конца строк в файле? Как нам гарантировать, что "кусок из stream" начнётся с начала строки?
хм.. ну просто StreamReader.ReadLine
К чтению в момент времени имеет доступ только один таск.
Выяснить, есть ли какой-нибудь способ не аллоцировать строки, а держать их в одной области памяти и иметь на них ссылку в виде, например Memory<>.
Если есть, это может дать очень существенный выигрыш при сортировке. Не из-за аллокакий, а из-за уменьшения кэшмиссов.
Re[3]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Наверное да, показалось странным работать с большими файлами в шаше время на ХДД (но тогда и на памяти экономить, наверное, было бы и не нужно).
В наше время можно было бы загрузить этот "большой файл" в Azure и отсортировать его в памяти. Микрософт достаточно широкую линейку предлагает, есть машины с большим количеством памяти и достаточно средним процессором.
M>>Можно еще сказать CanSeek: false. _FR>Где это можно сказать?
Я исходники не дочитал, его нельзя установить . Он где-то внутри FileStream инициализируется. Может быть, установить SequentialScan на запись? Хотя не знаю, можно ли так и поможет ли оно.
_FR>Неужели накладные расходы на асинхронность будут сравнимы в вашем понимании с накладными расходами на ввод-вывод или на вручную щзапущенные потоки?
Сравнимы быть не должны. Хотя зависит от диска. Потому что асинхронность требует какой-то реализации. В лучшем случае это инструкции чтения напрямую из памяти. В худшем — системные вызовы вроде мьютексов. При этом у вас асинхронности очень много. Грубо говоря, каждая строка разбирается асинхронно. Это создает лишние синхронизации/барьеры и все остальное. В предлагаемом мной решении (сортировка в отдельном потоке) у нас имеется один системный вызов на запуск потока, один — на остановку (Join в конце). Все остальное работает независимо и параллельно. Как Буравчик ниже предлагает, нужно работать с более крупными блоками без лишних расходов.
M>>А тольку — только немного от выделения сортировки. _FR>Нет: async вызван использованием PipeReader-а, а он выбран как средство, позволяющее минимизировать объём используемой памяти (по сравнению, например, со StreamReader::ReadLine()).
Это не совсем та память, которую нужно оптимизировать. Ваш reader и прочие буфера имеют размер порядка мегабайтов. Причем это именно рабочие буфера. Когда вы делаете Encoder.ToString(), данные из буфера все равно копируются. Рабочий набор для сортировки должен быть порядка сотен мегабайт. Т.е. вы оптимизируете по памяти часть, занимающую проценты от общего потребления.
_FR>Хм, спасибо, подумаю. Тут идея та же: не тратить память повторно. Строковая часть может быть достаточно большой и дублировать её совсем не хотелось.
Там очень временное дублирование получается. В .NET сборщик мусора с поколениями. Наличие поколений говорит о том, что в целом платформа хорошо справляется с небольшими короткоживущими объектами. У вас "следующая строка" — короткоживущий объект. Из нее парсится число и делается substring. Всё. Из дополнительных расходов — struct для хранения числа и строки и дополнительное копирование строковых данных в Substring. Временно (на время работы Substring) — да, память в двойном размере строки.
M>>Ну и тут же еще одно замечание. Вы уверены, что list.clear() хоть в чем-то лучше создания нового списка? _FR>Конечно. Списки-то большие, а вся идея была в том, что бы потратить как можно меньше памяти.
Вроде бы задача отсортировать быстро а не потратить меньше памяти? Про список вопросы про GC в первую очередь. Но да, наверное, clear лучше. Список в итоге все равно окажется где-то в старших поколениях, там переиспользование оправдано.
_FR>Да, сортировка на время операций влияния почти не оказывает. Вам кажется, что она будет выглядеть легче/понятнее, чем BinarySerach/Insert в список? Зачем тогда менять?
Да, лучше. Хотя-бы читабельнее. Например, в текущем коде мне очень не хватает комментария о том, почему мы экономим количество сравнений но не экономим количество копирований. Допустим, у нас массив короткий (5-10 элементов). Зачем нам вообще нужен двоичный поиск? Можно просто последовательно сравнивать элементы и копировать, пока не найдем позицию (типичный insertion sort). Больше сравнений, меньше ветвлений. Нет, я понимаю, что у вас сравнение тяжелое. Но сочетание двоичного поиска и линейной вставки выглядит странно.
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Буравчик, Вы писали:
Б>И почему-то жрет память.
А это просто. Там на каждый входной файл выделяется буфер в как минимум 1Мб. Это внутренний буфер FileStream, используется для того, чтобы уменьшить количество вызовов в ядро. Т.е. пользователь FileStream может читать единицы/десятки байт, а переключения контекстов будут выполняться редко. Но при большом количестве файлов таких буферов становится много. Это же показывают и ваши эксперименты — чем больше файлов, тем выше потребление. По умолчанию (без настройки) в FileStream вообще 4Кб буфер. Мегабайт там, наверное, много. Я не уверен, что даже самый агрессивный prefetch будет столько вычитывать. Что-то порядка 16-32Кб может быть идеальным вариантом.
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, maxkar, Вы писали:
_FR>>Да, сортировка на время операций влияния почти не оказывает. Вам кажется, что она будет выглядеть легче/понятнее, чем BinarySerach/Insert в список? Зачем тогда менять? M>Да, лучше. Хотя-бы читабельнее. Например, в текущем коде мне очень не хватает комментария о том, почему мы экономим количество сравнений но не экономим количество копирований. Допустим, у нас массив короткий (5-10 элементов). Зачем нам вообще нужен двоичный поиск? Можно просто последовательно сравнивать элементы и копировать, пока не найдем позицию (типичный insertion sort). Больше сравнений, меньше ветвлений.
Мне это показалось логичным: если у нас разбивка происходин на небольшое число файлов, то и такая программа скорее всего не нужна, памяти у нас относительно много и операцию мы так и этак относительно быстро можем завершить.
Такие программы, для сортировки больших файлов с использованием ограниченной памяти, имеет смысл запускать на действительно больших файлах, которые во много раз больше имеющейся оперативки. Соответственно файлов будет много… я рассчитываю на тысячи.
M>Нет, я понимаю, что у вас сравнение тяжелое. Но сочетание двоичного поиска и линейной вставки выглядит странно.
Мне казалось, что это весьма распространённая практика — когда имеется сортированный список и нужно добавить в него элемент так, что бы список остался бы отсортированным
Help will always be given at Hogwarts to those who ask for it.
Re[5]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, maxkar, Вы писали:
Б>>И почему-то жрет память. M>А это просто. Там на каждый входной файл выделяется буфер в как минимум 1Мб. Это внутренний буфер FileStream, используется для того, чтобы уменьшить количество вызовов в ядро. Т.е. пользователь FileStream может читать единицы/десятки байт, а переключения контекстов будут выполняться редко. Но при большом количестве файлов таких буферов становится много. Это же показывают и ваши эксперименты — чем больше файлов, тем выше потребление. По умолчанию (без настройки) в FileStream вообще 4Кб буфер. Мегабайт там, наверное, много. Я не уверен, что даже самый агрессивный prefetch будет столько вычитывать. Что-то порядка 16-32Кб может быть идеальным вариантом.
Да, я обычно в повседневной работе файлы так пачками не вычитаваю. поэтому привык сразу выделять большой буфер. Тут пожалуй надо в килобайтак задавать размер буфера.
Help will always be given at Hogwarts to those who ask for it.
Re: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Привет,
_FR>Ещё в прошлом году дали в одной компании тестовое задание, которое мне показалось интересным сделать — во-первых, я на программиста не учился и сортировку файлов слиянием делать мне никогда не приходилось, только читал. Во-вторых, показалось, что в такой задаче можно как раз удачно поиграть с последними нововведениями в C# и dotnet и покапаться в спанах (может, в этом и была моя ошибка, подскажите).
Очень интересная задачка. Помимо упомянутого:
— HDD или SSD? HDD не умеет параллелить чтения и записи, дорогой seek.
— Насколько рандомные строки? Возможно, имеет смысл при записи чанков на диск сжимать данные
— формат строк и условие сортировки прямо подталкивает к другому формату данных для сортировки. zero-terminated string и число dword-ом. Помимо скорости сравнения, это еще и экономия памяти.
— хранить сортируемые данные непрерывными областями в памяти и сортировать смещения, аллокация каждой строчки в хипе — неэффективно.
— сделать эффективный мердж сотен чанков не так-то просто и может быть неэффективно на HDD, нужно поиграться с кол-вом мерджей
Re: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Привет,
Так в итоге на что задача? radix sort? бакет сорт? внешняя сортировка? По строкам хэши считаем и сравниваем их?
Sic luceat lux!
Re[2]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Kernan, Вы писали:
K>Так в итоге на что задача? radix sort? бакет сорт? внешняя сортировка? По строкам хэши считаем и сравниваем их?
Во время очного интервью мы эту задачу совсем и не обсуждали (мне сказали, что её будут смотреть или смотрели другие люди), потом только после настойчивой просьбы я получил скупую строку о том, что "хорошо то, плохо это, а, вообще, медленно"
Help will always be given at Hogwarts to those who ask for it.
Re: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Решение моё интервьюеров не удовлетворило, говорят, что очень медленно работает: как обычно, у меня на лаптопе как раз всё летает, файл в 1Г сортируется за 13 с небольшим секунд, а у ревьюеров получилось 130c на файл 1 гиг Так мне написали. _FR>Вот с тех пор мне интересно, где я мог пойти не тем путём: разница достаточно большаая, скорее всего на более медленном железе так плохо вышло не из-за каких-то микрооптимизаций, которые я не смог сделать, а в чём-то принципиальном. Но где
Я думаю дело в том, что их код, как и код на питоне упомянутый в этой теме, не работает со строками. Он работает с массивами байт.
При отказе от строк любая реализация на .NET ускоряется в 8-10 раз и потребление тоже падает.
На этапе получения задания надо было уточнить какие именно строки имеются ввиду и как их сравнивать.
Re[2]: Как правильно сортировать содержимое больших файлов?
Сделал сначала наивное решение с асинхронным IO как полагается. Получилось в 2 раза медленнее вашего. Начал "оптимизировать" переводя все на работу с Memory и Span вместо string. Кроме того распараллелил IO с сортировкой, добавил MemoryPool чтобы уменьшить аллокации.
Смог сделать на решение, которое было на 15% медленнее вашего. Причем ускорилась фаза разбиения, а слияние почти ничего не выиграло.
Я понял что не туда копаю, я прочитал весь тред и все по ссылкам, позапускал ваш вариант и питоновский код, в итоге выпилил асинхронность и написал самое простое решение, которое только может быть.
Разбиение на куски
Encoding encoding;
List<string> tempFiles;
using (var reader = new StreamReader(file, true))
{
encoding = reader.CurrentEncoding;
tempFiles = reader
.EnumerateLines()
.Chunk(chunkSize)
.Select(chunk => {
Array.Sort(chunk, comparer);
var tempFileName = Path.GetTempFileName();
File.WriteAllLines(tempFileName, chunk);
return tempFileName;
}).ToList();
}
public static IEnumerable<string> EnumerateLines(this StreamReader reader)
{
while (!reader.EndOfStream)
{
yield return reader.ReadLine()!;
}
}
Объединение кусков:
var files = tempFiles
.Select(f => File.OpenText(f))
.ToList();
File.WriteAllLines(file, files.Select(f => f.EnumerateLines()).MergeLines(comparer), encoding);
files.ForEach(f => f.Dispose());
tempFiles.ForEach(f => File.Delete(f));
public static IEnumerable<string> MergeLines(this IEnumerable<IEnumerable<string>> sources, IComparer<string> comparer)
{
var enumerators = ( from source in sources
let e = source.GetEnumerator()
where e.MoveNext()
select e ).ToList();
while (enumerators.Any())
{
var min = enumerators.MinBy(e => e.Current, comparer);
yield return min.Current;
if (!min.MoveNext())
{
enumerators.Remove(min);
min.Dispose();
}
}
}
Внезапно оно показало лишь немного проиграло вашему коду, но значительно проиграло коду на питоне.
Далее я сделал две вещи: добавил .AsParallel() в фазу разбиения, чтобы чанки разбивались и записывались в несколько потоков и поменял реализацию MergeLines на использование PriorityQueue.
Много нового для себя узнал:
1) async медленный, не надо все подряд делать async, особенно в консольном приложении.
2) Диски достаточно быстрые, чтобы программа которая пишет 50-100мб\сек упиралась в скорость работы кода, а не в IO.
3) Алгоримты рулят. У меня было подозрение что поиск наименьшего значения из итераторов медленно работает, но я не думал что замена на PriorityQueue ускорит слияние почти в три раза.
4) Обогнать StreamReader\StreamWriter можно, но смысла нет, это не дает заметного прироста
5) Строки это дорого, особенно когда они не влезают в оперативную память.
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, gandjustas, Вы писали:
G>>Обогнал вашу версию, работает примерно как версия на питоне. Полный код тут: https://github.com/gandjustas/HugeFileSort
_FR>Круто, спасибо! Пока не могу посмотреть и запустить.
_FR>А что с расходом памяти? Например, если файл в 10 гигов разбиватт на 200 кусков по ~50 метров?
Сегодня тестил на 100М строк 14 ГБ, сортировка по дефлоту разбивает на куски по 100к строк, примерно 150мб кусок. Потребление памяти с параллелизмом до 3 гб на моей машине.
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, gandjustas, Вы писали: G>>>Обогнал вашу версию, работает примерно как версия на питоне. Полный код тут: https://github.com/gandjustas/HugeFileSort _FR>>А что с расходом памяти? Например, если файл в 10 гигов разбиватт на 200 кусков по ~50 метров? G>Сегодня тестил на 100М строк 14 ГБ, сортировка по дефлоту разбивает на куски по 100к строк, примерно 150мб кусок. Потребление памяти с параллелизмом до 3 гб на моей машине.
Мне всё-таки кажется, что это не совсем правильный подход к решению данной задачи.
Я рассуждаю так: если задача сортировки файла в условиях недлостаточной памяти возникла. значимт при решении задачи нам нужно в первую очередь экономить память, а во-вторую уже ускорять.
Если я правильно понял ваши вводные: исходный файл на 14Г из 100М строк, каждая строка до 256 символов + строковое представление инта
разбивается на файлы по 100к строк, каждый кусок по 150М
Я как-нибудь попробую. Я себе условия взял пожёсче: строка до 1024 символов и UInt64 впереди. В файле чуть меньше 20М строк и 10Г (для точности 19,759,397 строк и 10,737,419,483 байт)
разбивается на файлы по 100л строк, выходит по ~54М (54,350,975 байт)
Разбиение занимает 00:01:06, слияние 00:01:10, всё вместе (видимо, добавляется удаление файлов) 00:02:20, при этом памяти в пике потратилось до 500М
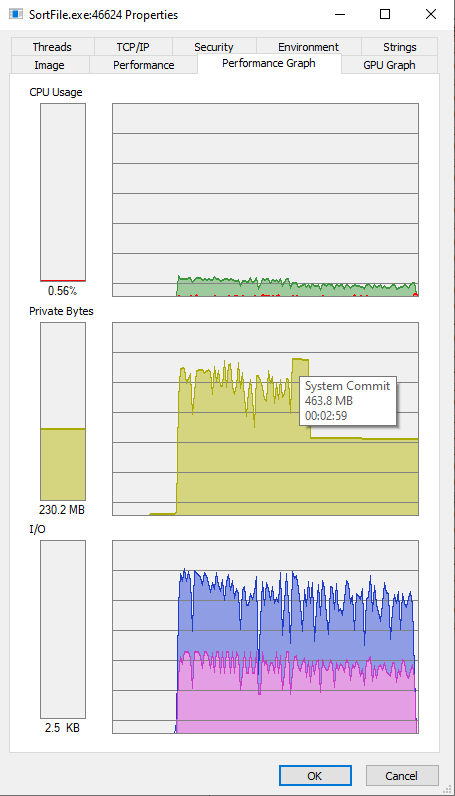
Картинка Performance Graph
Если при разбиении файла вместо всего двух буферов под данные использовать больше, по числу процессоров, как выше предложили, скорость разбиения улучшается на 20..25 процентов, а память возрастает вдвое, поэтому пока это не так интересно.
Интересно будет ваш и мой код запустить на одном и том же файле на одной и той же машине и сравнить память/время.
Help will always be given at Hogwarts to those who ask for it.
Re[5]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, gandjustas, Вы писали:
G>>>>Обогнал вашу версию, работает примерно как версия на питоне. Полный код тут: https://github.com/gandjustas/HugeFileSort _FR>>>А что с расходом памяти? Например, если файл в 10 гигов разбиватт на 200 кусков по ~50 метров? G>>Сегодня тестил на 100М строк 14 ГБ, сортировка по дефлоту разбивает на куски по 100к строк, примерно 150мб кусок. Потребление памяти с параллелизмом до 3 гб на моей машине.
_FR>Мне всё-таки кажется, что это не совсем правильный подход к решению данной задачи. _FR>Я рассуждаю так: если задача сортировки файла в условиях недлостаточной памяти возникла. значимт при решении задачи нам нужно в первую очередь экономить память, а во-вторую уже ускорять.
Не "в условиях недостаточной памяти", а "размер файла заведомо превышает объем ОП", это разные условия.
В исходной задаче какой-либо речи об "экономии" не шло.
_FR>Разбиение занимает 00:01:06, слияние 00:01:10, всё вместе (видимо, добавляется удаление файлов) 00:02:20, при этом памяти в пике потратилось до 500М
По чистому времени сложно судить, сильно от характеристик диска зависит.
У меня генерация файла в 10Г выполняется 2 минуты.
_FR>Если при разбиении файла вместо всего двух буферов под данные использовать больше, по числу процессоров, как выше предложили, скорость разбиения улучшается на 20..25 процентов, а память возрастает вдвое, поэтому пока это не так интересно.
Почему 25%? Если берем SSD, то подготовка чанка занимает времени примерно столько же, сколько сортировка. Запись на SSD параллелится почти 100%.
25% это наверное актуально для HDD. Но тогда как записать 10Г за минуту, если средняя скорость линейной записи и чтения 100-120 мб\сек?
_FR>Интересно будет ваш и мой код запустить на одном и том же файле на одной и той же машине и сравнить память/время.
Вам ничего не мешает. Питоновский код Буравчика тоже запустите заодно.
Re[6]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, gandjustas, Вы писали:
_FR>>Мне всё-таки кажется, что это не совсем правильный подход к решению данной задачи. _FR>>Я рассуждаю так: если задача сортировки файла в условиях недлостаточной памяти возникла. значимт при решении задачи нам нужно в первую очередь экономить память, а во-вторую уже ускорять. G>Не "в условиях недостаточной памяти", а "размер файла заведомо превышает объем ОП", это разные условия. G>В исходной задаче какой-либо речи об "экономии" не шло.
Ну эт по меньшей мере странно так решать: Ведь о том, сколько есь памяти в условии тоже ни слова, при этом единственный смысл в такой сортировке, как мы делаем — это экономия памяти, потому чемь меньше тем лучше. Я вот сейчас играюсь с размерами буферов для файлов, пока доигрался до того, что разбивая тот же исходный файл на пачки по 50к строк / 27М (396 файлов) укладываюсь в 00:02:22 и 250М оперативной памяти Вы, запуская мой код не пробовали параметры подобрать такие, чтобы тоже 3Г тратилось бы?
_FR>>Разбиение занимает 00:01:06, слияние 00:01:10, всё вместе (видимо, добавляется удаление файлов) 00:02:20, при этом памяти в пике потратилось до 500М G>По чистому времени сложно судить, сильно от характеристик диска зависит. G>У меня генерация файла в 10Г выполняется 2 минуты.
Если будет интересно: попробуйте у себя заменить int на ulong и максимальную сдлину строки выставить в 1024 и сравнить с моей.
_FR>>Если при разбиении файла вместо всего двух буферов под данные использовать больше, по числу процессоров, как выше предложили, скорость разбиения улучшается на 20..25 процентов, а память возрастает вдвое, поэтому пока это не так интересно. G>Почему 25%? Если берем SSD, то подготовка чанка занимает времени примерно столько же, сколько сортировка. Запись на SSD параллелится почти 100%. G>25% это наверное актуально для HDD. Но тогда как записать 10Г за минуту, если средняя скорость линейной записи и чтения 100-120 мб\сек?
Нет, у меня SSD. Я просто сравнил 51 секунду в реализации с очередью из ProcessorCount списков и 66 секунд в моей первой реализации с двумя списками.
Help will always be given at Hogwarts to those who ask for it.
Re[6]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, gandjustas, Вы писали: G>>>>>Обогнал вашу версию, работает примерно как версия на питоне. Полный код тут: https://github.com/gandjustas/HugeFileSort _FR>>>>А что с расходом памяти? Например, если файл в 10 гигов разбиватт на 200 кусков по ~50 метров? G>>>Сегодня тестил на 100М строк 14 ГБ, сортировка по дефлоту разбивает на куски по 100к строк, примерно 150мб кусок. Потребление памяти с параллелизмом до 3 гб на моей машине. _FR>>Интересно будет ваш и мой код запустить на одном и том же файле на одной и той же машине и сравнить память/время. G>Вам ничего не мешает.
Запускал на лаптопе с 32Г оперативки и 6х2 ядрами
Собрал ваш код. Добавил вывод в консоль времени выполнения, поменял сравнение строк на Ordinal, потому как заметно быстрее и стал сохранять результат в новый файл, а не перезаписывать исходный:
Генерация файла на 100М строк (3.8 GB (14,898,287,710 bytes)) на моём лаптопе заняла 04:47:54. // Имя файла "DataSort-10G.txt", хотя его размер 14Г
Сортировка этого файла с настройками по-умолчанию (файл разбивается на пачки по 100к строк):
Splitted in 00:02:26.8240463
Merged in 00:04:16.3986896
Sorted in 00:06:45.3281167
по мелочи причесал
перевёл на .NET 7.0
сделал настраиваемое число буферов, в которые может вычитываться исходный файл во время разбиения. В тесте использовал 4 буфера.
Подобрал размеры буферов для размеров промежуточных файлов (по 300к строк и чуть меньше 45М) и для используемых стримов
В итоге тот же исходный файл на том же лаптопе со всей асинхронностью:
Split to 334 files / 100,000,000 lines in 00:02:01.6797598
Merge 334 files in 00:02:44.2937083
File "DataSort-10G.txt" sorted as "DataSort-10G-335.txt" in 00:04:46.7148925.
Памяти использовалось около одного гигабайта, но на картинке ниже тултип не запечатлелся :о(
Performance Graph
В общем я не увидел описанных вами выше преимуществ :
С асинками у меня быстрее, а если добавить в Merge PriorityQueue<,> то становится медленнее. Ручное вычитывание и разбор строки позволили сэкономить дастаточно много — в 6 раз меньше, памяти (и, за счёт памяти же, видимо, и времени).
Будет сильно интересно, если кто-то ещё погоняет и поделится результатами. G>Питоновский код Буравчика тоже запустите заодно.
Это как-нить потом, когда будет время разобраться, как его запускать. Мне показалось, что этот код Тестовое задание Senior .Net — критикуйте так же не особенно старается экономить память. Но я в пайтоне не силён.
Help will always be given at Hogwarts to those who ask for it.
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Буравчик, Вы писали:
Б>Ваша реализация работает достаточно быстро (хотя написана сложно, на мой взгляд). И почему-то жрет память.
Наверно потому, что у вас числа в начале короткие. А у _FRED_а они длиннее самой строки:
Здравствуйте, Буравчик, Вы писали:
A>>Наверно потому, что у вас числа в начале короткие. А у _FRED_а они длиннее самой строки:
Б>Я тестировал на одном и том же файле, который был сгенерирован кодом _FRED_
В релизе же? У меня сильно по-разному это работает в зависимости от конфигурации.
В Дебаге строки короче и заканчиваются пайпом | для облегчения отладки и понимания, что строки вычитались правильно.
Я обязательно найду время запустить ваш код.
Help will always be given at Hogwarts to those who ask for it.
Re: Как правильно сортировать содержимое больших файлов?
К сожалению, ваша прога крешится без каких-либо сообщений. Проверял на 100 млн. записей, 13,8 Гб, который сгенерил этой прогой https://github.com/gandjustas/HugeFileSort
Хотел сравнить скорость — но увы! Ваша прога создала 1000 файлов, потом начала мерждить, дошла до 100% (или почти 100%, не помню). Все красиво так. А потом опа — и просто закрывается, когда доходит до 100%
Т.е. вам нужно как минимум добавить текст ошибки или лог, чтобы был шанс понять в чем проблема.
Re: Как правильно сортировать содержимое больших файлов?
Мое: https://github.com/artelk/RowsSort
Сделано в предположение, что файлы ASCII, числа укладываются в ulong, стоки длиной от 2 до 256 и строки случайны (!).
Последний пункт используется, чтобы примерно равномерно поделить строки по первым символам.
Агоритм:
1. Разбиваем строки на множество чанков. Критерий разбивки — первый символ плюс старшие 3 бита второго символа.
2. Строки в чанки пишутся в бинарном формате: <strLenByte><string><num8bytes>. Это нужно, чтоб размер файлов немного уменьшить. Первый символ у строк отрезается, т.к. он общий у всех строк чанка. Лишний пробел, точка и \r\n тоже не пишется. Экономим на спичках
Если размер алфавита маленький, можно было бы как-то меньшим числом битов символы кодировать, чтобы еще сильнее сжать.
3. По очереди читаем файлы чанков в лексикографическом порядке, сортируем их и записываем в результирующий файл.
Для сортировки чанков реализовал Radix Sort. Чанки открываются как memory mapped files. Много unsafe и указателей
На моем железе сортировшик FREDа на файле 1Гб работает за 2 минуты, а мой за 40 секунд.
Возможно, на другом железе будет обратная картина, т.к. я ничего не параллелил и на моем ноуте узкое место это HDD (хотя саму сортировку можно было бы как-то в параллель IO сделать).
На Очень больших файлах размер чанков может оказаться слишком большим и не влезать в память, так что алгоритм разбивки придется доточить.
A>Сделано в предположение, что файлы ASCII, числа укладываются в ulong, стоки длиной от 2 до 256 и строки случайны (!). A>Последний пункт используется, чтобы примерно равномерно поделить строки по первым символам.
Мне кажется, это довольно вольная трактовка задания, про случайность строк ничего сказано не было.
A>На моем железе сортировшик FREDа на файле 1Гб работает за 2 минуты, а мой за 40 секунд. A>Возможно, на другом железе будет обратная картина, т.к. я ничего не параллелил и на моем ноуте узкое место это HDD (хотя саму сортировку можно было бы как-то в параллель IO сделать).
О, это уже похоже на то, что было у проверяющих.
Вы запускали релиз?
С каким файлом (созданным моим же генератором или) или другой?
По сколько строк разбивали исходный файл?
Можете показать вывод программы и расход памяти (гистограмму из процесс эксплорера или таск менеджера)?
A>Просьба кому не лень погонять у себя и рассказать
Я на днях погоняю
Help will always be given at Hogwarts to those who ask for it.
Re[2]: Как правильно сортировать содержимое больших файлов?
S>Хотел сравнить скорость — но увы! Ваша прога создала 1000 файлов, потом начала мерждить, дошла до 100% (или почти 100%, не помню). Все красиво так. А потом опа — и просто закрывается, когда доходит до 100%
Отлично! Во-первых, она получается почти смёрджила! Покажите её лог с консоли пожалуйста ну и сколько времени она проработала до того как упасть?
Просто Стас в свой файл в конец записывает финальный перенос строки, а я не записываю. Возможно проблема с этим.
Или может вы батник запускали по Enter и просто не увидели результутов? Моя программа как всё сделала, пишет в консоль время и закрывается. Запустите вручную из консоли или добавьте строчку с @Pause в конец батника.
Вы запускали у меня релиз? С ветки main или use-read-buffers-queue?
У меня ошибок этот лишний перенос строки не вызывает, но может оставаться лишний "пустой" файл, поэтому интересно узнать, что за ошибка. Запустите Release конфигурацию под отладчиком пожалуйсита и посмотрите, что за ошибка и где?
S>Т.е. вам нужно как минимум добавить текст ошибки или лог, чтобы был шанс понять в чем проблема.
Здравствуйте, artelk, Вы писали:
A>Здравствуйте, _FRED_, Вы писали:
A>Мое: https://github.com/artelk/RowsSort A>Сделано в предположение, что файлы ASCII, числа укладываются в ulong, стоки длиной от 2 до 256 и строки случайны (!). A>Последний пункт используется, чтобы примерно равномерно поделить строки по первым символам.
Имхо слишком сильные допущения. Что будет если попробовать отсортировать файл в 50ГБ одинаковых строк?
Кстати почему выбрано 256? Если будет не 265, а 1024 на что повлияет?
Re[3]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, gandjustas, Вы писали:
A>>Мое: https://github.com/artelk/RowsSort A>>Сделано в предположение, что файлы ASCII, числа укладываются в ulong, стоки длиной от 2 до 256 и строки случайны (!). G>Кстати почему выбрано 256? Если будет не 265, а 1024 на что повлияет?
У меня тоже 1024. Это необходимо, что бы выбрать буфер подходящего развера для вычитывания строк. Мне использование подобной константы (или параметра) кажется оправданным.
Help will always be given at Hogwarts to those who ask for it.
Re[3]: Как правильно сортировать содержимое больших файлов?
Спасибо. Подозреваю, что основной эффект дало именно сжатие за счет бинарного формата. На файле FREDа, с огромными числами слева, чанки сжимались примерно в два раза.
У bucket+merge sort потенциала в этом смысле больше. После сортировки чанка там могут подряд идти много строк с одним довольно длинным префиксом, что можно как-то более компактно упаковать.
Re[3]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, artelk, Вы писали:
A>>Сделано в предположение, что файлы ASCII, числа укладываются в ulong, стоки длиной от 2 до 256 и строки случайны (!). A>>Последний пункт используется, чтобы примерно равномерно поделить строки по первым символам.
_FR>Мне кажется, это довольно вольная трактовка задания, про случайность строк ничего сказано не было.
В треде в dotnet форуме вроде было
A>>На моем железе сортировшик FREDа на файле 1Гб работает за 2 минуты, а мой за 40 секунд. A>>Возможно, на другом железе будет обратная картина, т.к. я ничего не параллелил и на моем ноуте узкое место это HDD (хотя саму сортировку можно было бы как-то в параллель IO сделать).
_FR>О, это уже похоже на то, что было у проверяющих. _FR>Вы запускали релиз?
да
_FR>С каким файлом (созданным моим же генератором или) или другой?
вашим
_FR>По сколько строк разбивали исходный файл?
не ограничивал, сколько получилось после разбиения по первому символу + 3 бита второго символа. На 1Гб файле там нескольно мегабайт на чанк было.
_FR>Можете показать вывод программы и расход памяти (гистограмму из процесс эксплорера или таск менеджера)?
покажу на днях
Здравствуйте, gandjustas, Вы писали:
G>Здравствуйте, artelk, Вы писали:
A>>Здравствуйте, _FRED_, Вы писали:
A>>Мое: https://github.com/artelk/RowsSort A>>Сделано в предположение, что файлы ASCII, числа укладываются в ulong, стоки длиной от 2 до 256 и строки случайны (!). A>>Последний пункт используется, чтобы примерно равномерно поделить строки по первым символам. G>Имхо слишком сильные допущения. Что будет если попробовать отсортировать файл в 50ГБ одинаковых строк?
умрет G>Кстати почему выбрано 256? Если будет не 265, а 1024 на что повлияет?
в бинарном формате чанка отдаю только один байт на длину каждой строки
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, artelk, Вы писали:
_FR>>По сколько строк разбивали исходный файл? A>не ограничивал, сколько получилось после разбиения по первому символу + 3 бита второго символа. На 1Гб файле там нескольно мегабайт на чанк было.
Я имею в виду мою реализацию — с какими параметрами запускали? Не указывать число строк, на которые нужно сначала попилить исходный файл моей программе нельзя (параметр MaxReadLines).
Help will always be given at Hogwarts to those who ask for it.
Re[5]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, artelk, Вы писали:
_FR>>>По сколько строк разбивали исходный файл? A>>не ограничивал, сколько получилось после разбиения по первому символу + 3 бита второго символа. На 1Гб файле там нескольно мегабайт на чанк было.
_FR>Я имею в виду мою реализацию — с какими параметрами запускали? Не указывать число строк, на которые нужно сначала попилить исходный файл моей программе нельзя (параметр MaxReadLines).
Аа, 50000, как в SortFile.cmd было
Re: Как правильно сортировать содержимое больших файлов?
Но мне таки кажется, что правильный способ взять RDBMS, создать базу с двумя таблицами.
Первая таблица с одной колонкой для строк, она же primary key.
Вторая колонка с foreign key на первую таблицу, int32 или int64 колонкой для чисел, и например secondary key из колонки для чисел.
Последовательно прочитать один раз файл.
Для каждой строки найти или добавить её в первую таблицу, потом добавить строку во вторую таблицу.
Потом один раз прочитать всю базу, и в цикле написать выходной файл.
Для RDBMS лучше всего взять SQLite, потому что оно in-process, и в идеале понастраивать его для максимальной производительности и минимальной durability.
Или если не хочется тащить dependencies, а на компьютере Windows, можно ESENT ещё.
Остальные способы изрядно хуже.
Стандартные коллекции вроде List или Dictionary поддерживают максимум 2 миллиарда значений (потому что число элементов int32), 100GB файл скорее всего будет больше.
Кроме того, даже если хранить по 8 байт на строчку, для объёмов в той задаче вероятно падение с out of memory.
Если что-то самому колхозить на тему временных файлов на диске, скорее всего получится или сильно медленнее, или адски сложное.
Таблицы в базах данных состоят из B-trees, хорошо подходят для задачи, но самому их запилить изрядно сложно.
Здравствуйте, Константин, Вы писали:
К>Я не знаю, чего именно от тебя хотели.
Я рассчитывал, что это будет просто предмет для обсуждения на очном интервью. Србственно, других задач для тестового задания мне сложно представить. Когда это смотрится так "в тёмную"
К>Но мне таки кажется, что правильный способ взять RDBMS, создать базу с двумя таблицами.
Тут тоже, мне кажется, возможны ньюансы, так что самое простое — взять и продемонстрировать
Help will always be given at Hogwarts to those who ask for it.
Re: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Константин, Вы писали:
К>Я не знаю, чего именно от тебя хотели.
К>Но мне таки кажется, что правильный способ взять RDBMS, создать базу с двумя таблицами. К>Первая таблица с одной колонкой для строк, она же primary key. К>Вторая колонка с foreign key на первую таблицу, int32 или int64 колонкой для чисел, и например secondary key из колонки для чисел.
Тебе кажется.
К>Последовательно прочитать один раз файл.
Это O(N) чтений
К>Для каждой строки найти или добавить её в первую таблицу, потом добавить строку во вторую таблицу.
Это O(N * log N) чтений для поиска места вставки + O(N*log N) записей, так как древовидный индекс будет перестраиваться (правда логарифм будет по большому основанию)
К>Потом один раз прочитать всю базу, и в цикле написать выходной файл.
Это O(N) чтений из таблиц + O(N) записей в результирующий файл
К>Если что-то самому колхозить на тему временных файлов на диске, скорее всего получится или сильно медленнее, или адски сложное.
Покочто все решения где "самому колхозить" получаются быстрее так как требуют:
Это O(N) чтений для исходного файла
+ O(N) записей в промежуточный файл + O(N*Log N) операций сравнения в памяти для сортировки
+ O(N) записей в файл результата * O(Log K) сравнений в памяти для операций слияния
Даже сравнение асимптотик говорит что рукопашный алгоритм будет быстрее. А реальные накладные расходы
К>Таблицы в базах данных состоят из B-trees, хорошо подходят для задачи, но самому их запилить изрядно сложно.
Есть готовая эффективная реализация B-деревьев в .NET ?
Вообще рассуди логически:
БД это индекс. Построение индекса в том или ином виде это сортировка. Но так как размер индекса заведомо превышает размер ОП, то сортировать записи надо будет на диске, что даст минимум O(N*log N) записей. Тогда как алгоритмы внешней сортировки сортируют куски в памяти, то записей будет всего O(N), а сортировка и слияние отсортированных кусков будет выполняться в памяти без дополнительных записей на диск.
Re[3]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, gandjustas, Вы писали:
G>Даже сравнение асимптотик говорит что рукопашный алгоритм будет быстрее.
Сам же написал выше, что не будет: то же самое O(N*Log N) в обоих случаях.
G>А реальные накладные расходы
Да, и вот тут будет win у традиционных баз данных.
У них под капотом B-trees, которые десятилетиями оптимизированы для таких случаев, как запись строки в середину таблицы.
Сортировка слиянием скорее всего будет медленнее из-за I/O bandwidth.
Когда вставляем строчку в SQL таблицу, если такая строчка уже была в базе, SQL найдёт в таблице старую, даже несмотря на то, что таблица не влезает в память.
На практике это очень быстро потому что кеш диска во всех современных ОС использует всю свободную оперативную память. Верхние уровни того дерева попадут в кеш и останутся там на время работы программы, потому что из них читают постоянно.
Если разбить данные на куски влезующие в память и потом мёрджить отсортированные куски, если такая строчка уже была в предыдущем куске данных, код её не найдёт.
Будут идентичные строчки в двух кусках данных.
Merge понятно потом уберёт дубликаты, но эти дубликаты занимают место на диске и жгут IO bandwidth.
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Константин, Вы писали:
К>Здравствуйте, gandjustas, Вы писали:
G>>Даже сравнение асимптотик говорит что рукопашный алгоритм будет быстрее. К>Сам же написал выше, что не будет: то же самое O(N*Log N) в обоих случаях.
Только в случае БД на диске, а в случае внешней сортировки — в памяти. Разница примерно в 100 000 раз.
Это как бы не tradeoff, а просто замедление работы.
G>>А реальные накладные расходы К>Да, и вот тут будет win у традиционных баз данных. К>У них под капотом B-trees, которые десятилетиями оптимизированы для таких случаев, как запись строки в середину таблицы.
Ну как не оптимизируй, а сортировка в памяти будет быстрее, чем на диске. То есть база данных будет на диск писать гарантированно не меньше лююбого варианта внешней сортировки.
К>Сортировка слиянием скорее всего будет медленнее из-за I/O bandwidth.
Нет конечно. Потому что решение с БД будет больше писать на диск. При чем тут I/O bandwidth — не понятно.
К>Когда вставляем строчку в SQL таблицу, если такая строчка уже была в базе, SQL найдёт в таблице старую, даже несмотря на то, что таблица не влезает в память.
Это O(logN) чтений с диска. Хоть и логарифм будет по большом основанию, все равно поиск места вставки потребует чтений.
К>На практике это очень быстро потому что кеш диска во всех современных ОС использует всю свободную оперативную память. Верхние уровни того дерева попадут в кеш и останутся там на время работы программы, потому что из них читают постоянно.
И что?
К>Если разбить данные на куски влезующие в память и потом мёрджить отсортированные куски, если такая строчка уже была в предыдущем куске данных, код её не найдёт.
А вы точно знаете как B-деревья работают, особенно в случаях вставки не в конец? Про page split не слышали? И какие затраты на вставку в произвольное место в B-дереве?
К>Будут идентичные строчки в двух кусках данных.
Считайте для верности что строчек идентичных не будет. По факту в исходной задаче число в начале делает все строки уникальными.
К>Merge понятно потом уберёт дубликаты, но эти дубликаты занимают место на диске и жгут IO bandwidth.
А вы точно знаете как merge sort работает?
Re[2]: Как правильно сортировать содержимое больших файлов?
бредовей вариант не придумать. особенно с однопоточным sqllite, он многие часы будет загружать 14 гб csv и раздует до 50 гб датафайлы и индексы, после чего до кого-то дойдет, что никто не обещал уникальность в строках файла.
даже тупой мап-редюс на пару дней обгонит вариант с однопоточным sqllite.
Здравствуйте, _FRED_, Вы писали:
_FR>А попробуйте сгенерить файл моей же и на нём проверить?
Проверил с новой версией. Общее время 13:44 с тем же файлом данных и вашими настройками для 10 Гб.
Т.е. у вас быстрее чем версия gandjustas (15,5 мин), но медленнее чем artelk (6,36 мин). Хотя это все условно — artelk жестко привязался к ASCII.
Мое мнение как это может выглядеть со стороны.
Вы делали решение как законченный продукт, как-будто где-то его будут реально применять, а не как тестовое задание. Там и архитектура и даже различные конфигурации для сборки.
Слишком много чести, как по мне. Вряд ли это было оценено.
Скорее всего победила какая-то версия типа artelk, только еще и с 4 байтными числами, ведь в Т.З. не указывали размерность чисел и ничего не сказали про кодировку. Притом что вашу версию могли запустить не в той конфигурации и не с теми параметрами, которые подходят 10 Гб файлов.
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Shmj, Вы писали:
S>Проверил с новой версией. Общее время 13:44 с тем же файлом данных и вашими настройками для 10 Гб. S>Т.е. у вас быстрее чем версия gandjustas (15,5 мин), но медленнее чем artelk (6,36 мин). Хотя это все условно — artelk жестко привязался к ASCII.
Я немного оптимизировал алгоритмы и параметры чтения\записи, запусти на том же файле на своей машине актуальную версию https://github.com/gandjustas/HugeFileSort, сколько покажет по времени?
В режиме сортировки ordinal используется RadixSort (подсмотрел у artelk), которая опирается на то что строки равномерно распределены и количество разных символов небольшое.
с такими "оптимизациями" я на своей машине смог за 57 мин отсортировать 104 гб, генерация файла заняла 20 минут.
S>Скорее всего победила какая-то версия типа artelk, только еще и с 4 байтными числами, ведь в Т.З. не указывали размерность чисел и ничего не сказали про кодировку. Притом что вашу версию могли запустить не в той конфигурации и не с теми параметрами, которые подходят 10 Гб файлов.
Это зависело бы от файла. Если программе artelk скормить файл из 100гб одинаковых строк, то упадет.
Какими критериями руководствовались те, кто проверял тестовое задание, мы не узнаем. Но в любом случае было бы неплохо уточнить требования — какие строки имеются ввиду, и какие требования по быстродействию и использованию ресурсов.
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Shmj, Вы писали:
_FR>>А попробуйте сгенерить файл моей же и на нём проверить? S>Проверил с новой версией. Общее время 13:44 с тем же файлом данных и вашими настройками для 10 Гб. S>Т.е. у вас быстрее чем версия gandjustas (15,5 мин), но медленнее чем artelk (6,36 мин). Хотя это все условно — artelk жестко привязался к ASCII.
А на расход памяти вы не посмотрели?
Все эти скорости без привязки к тому, сколько памяти потребовалось ничего не стоят
Help will always be given at Hogwarts to those who ask for it.
Re[5]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, Shmj, Вы писали:
_FR>>>А попробуйте сгенерить файл моей же и на нём проверить? S>>Проверил с новой версией. Общее время 13:44 с тем же файлом данных и вашими настройками для 10 Гб. S>>Т.е. у вас быстрее чем версия gandjustas (15,5 мин), но медленнее чем artelk (6,36 мин). Хотя это все условно — artelk жестко привязался к ASCII.
_FR>А на расход памяти вы не посмотрели? _FR>Все эти скорости без привязки к тому, сколько памяти потребовалось ничего не стоят
Да, нужно договорится об условиях и ограничениях, чтобы было интересно сравнивать.
Предлагаю такие: Строки Utf-8 со случайной (равномерно распределенной) длиной [0, 1024). Состоят из символов, которые, после декодирования, укладываются в двухбайтный char. Почти все символы ASCII-7. Закладываться на случайность и равномерную распределенность символов нельзя
Числа слева тоже случайны в интервале [0, UInt64.Max)
Разделитель строк: \n
Нужно уметь сравнивать строки разными компарерами. При сравнении реализаций проверяем время для Ordinal и InvariantCultureIgnoreCase.
Ограничение на память "живых" объектов (мусор GC не включаем): 200Мб (должно передаваться параметром командной строки).
Включая 24..26-байтные заголовки у объектов в куче (для .Net) и 8-байтные ссылки на них.
Включая память на буферы чтения\записи файлов.
Ограничение не слишком жесткое, можно, например, закладываться на среднюю длину строки и что почти все символы ASCII-7.
PS
Думаю, что строки в памяти можно хранить как utf-8 массивы байт. А простое их побайтное сравнение эквивалентно Ordinal сравнению, так?
Здравствуйте, artelk, Вы писали:
A>Мое: https://github.com/artelk/RowsSort A>Сделано в предположение, что файлы ASCII, числа укладываются в ulong, стоки длиной от 2 до 256 и строки случайны (!). A>Последний пункт используется, чтобы примерно равномерно поделить строки по первым символам.
Вот ещё на что обратил внимание — у меня в задании явно было сказано, что
Обе части могут в пределах файла повторяться.
И мой генератор как раз такой файл генерит (сто строк пробублированы).
A>Просьба кому не лень погонять у себя и рассказать
Вообще, скорость и потребление памяти у меня в тестах оказались суперскими
Тестировал на файле со 100М строк, сгенерированным программой Стаса, раз уж и ваше и его задание понимают только этот формат (у меня строки подлинее, чем ваше решение ожидает и числа 64 бита, чего не ожидает решение Стаса). Диск SSD.
Моё (памяти 2Г, не подбирал параметры, сразу так получилось, что расход чуть меньше, чем у Стаса):
Split: 00:01:47.5316319
Merge: 00:04:55.1813633
Total: 00:06:48.3150451 (это суммарно разбивка / слияние плюс ещё всякие мелкие операции типа удаление временных файлов)
Я пока решил кой-чего у себя докрутить: чтобы было болеек правильное сравнение, не писать в выходной файл заголовок кодировки и, наоборотЮ, писать в конце перевод строки, потому что без этого сложно сравнивать результирующие файлы.
Так же появились ещё идеи ,как можно ускорить, но не знаю, будет ли от них толк.
Что смутило: отсортированный файл у нас с вами получился похожим:
1575399668. 0 ipAo897o0SQCH PvhO eqQqifGCSqokwZ6jAp0Lt7I9EdlMN 9zi5IXnRzZK c cNiXCzBo9cVs 7 7 PtPrq sSJ2Opx Al r pFo J9 aic QMlMOAVD9 yZWw4wF iX 8IdsAk 2 X2Jk B 7 T911M j UQ2UiHyrWz2YFuI5 0rDNu 0Pek6c6z GsZ f1n Q3X2G3r b4kfo9iv XupONj fYnuHh X
1960802704. 0 BYFo5dqJzrDa67vJTNQ 8H2B1ZgoNu uWsLeBogbRTUYN m0 Bx1 QNYS4wGEHZpCSiBTBE2He4U2xncm1HKO7K6nFCZTmm 0lsJlmY VwVN ODH h3sQtf Ybf35eCxaBHfVtaWnp iZZ vBP
1029441457. 0 HXTtM 5ScPB51y5R0kR JqoVYWCQBZojI Tqwsg1 LUZp6qK e S4Xalb 7sGpyu yBmpFlWFF02h Lp7 B00pnLV8yJkwWgc px3DR6JPZYoj8MQwIE sT Kug BKu HvuWmCT zgaD1vuB pUHMG9mjJn4
218998971. 0 IOsJymXGecMsGev AF4l CohACapuf GRbJxBHqFbeFE s1wSI8Q1ScLhz1E89c 7mZ1gIVxR t654F8 qA8aOlNi Zac
69500093. 0 T3O8cNRNPdzSmcgJ4kGBjtYQR3cEO9pplec1pe0 qz0A07h1YePb8jiEnOx wtTSZ iIOTPyhsKT9 kh YnsCCjwzD H UoXBO4vT 8i95bJit4d xxJUTp8LY oATYaQ v Z0GY1sHK5Y4cHzLawhkXDM 8tEIikie1 X1xCzKNkx sM 1KesIITA4RGQ Uy kGwNzrY m0keM 06 LsGcxKyuP
…
2009983243. zzzzgrgCD K1y uLcw4trIwETR2sa7PrE4e3rQG Eh4nWzfhrO rMR G tEHg vL 9SVo3DDmqcfpAQsOAFbG4aNk7oNVQOXZT6EcGUg 1677FIB6S AYo d icqppohXors3uzU3 n6a Yg G6w OgXegkDWO rqSp9NUZj shej5XaUA
19509282. zzzzl BLqUiyz4Y 5 UlX V5QNcQKodT w LIpJArcFvgoG aupAPkFYYYK9 UL8BmYJgO q 5 iIkKYk0 eLQo nJKyqZ o Bzk8 988 Y nK U8Kz0KuC17VVQ7
661649546. zzzzrE9TYEZ7xI qKHEF8hmqD1SL sm9o W eQ lIWnuENs03f3RJ
673120082. zzzzttmlaSyWDolu R45aVKf1 L1e 2NWcKEdobEo9arL ed pchwSQ VHoEilc 6gXmMC5plaT4 i6jkLT RBS5
486393267. zzzzwTqF55fuu bE3F4 cY dqrzXDrRPhi5TkUzHpRpoe ESnH W n 7j 7NexNHbf i NbLCRBfw n PnyipETUDRD0xTeXLEby0xeh8LY2
А у Стаса другой (вроде как тот же дефолтовый Ordinal компаратор используется)
1029441457. 0 HXTtM 5ScPB51y5R0kR JqoVYWCQBZojI Tqwsg1 LUZp6qK e S4Xalb 7sGpyu yBmpFlWFF02h Lp7 B00pnLV8yJkwWgc px3DR6JPZYoj8MQwIE sT Kug BKu HvuWmCT zgaD1vuB pUHMG9mjJn4
1602172648. 0 1Gw Ql8bof I jMe9qx 9wc dk QNl NtDzjrM5g 26rR87gVLReF4 knv sg80 w8r6 5Opi 2ERX1jEIN ccg9umf2q f1XE WQTNtnvkl mjSCJCVTTf svNqN9QEy0rD jsYf3 jNjvo4mDqns0m 485fjITPOh Su wROnfTyWhO6RH6xz5 Bvmy19 eVy 3xXN8 XVyvmvKoqD8wdBE8zDpgqClqWN
642615666. 0 AbLJz rmAe b s HftsOwuIG 6FMt6Dxz aVJaCnvxxQxrnsHHtdMHbPqe 0Na5 w oFv4nEc w2VZ6RSJAarLBjDa1XLkKm3QonmYjBxB39jDxOIZLqVrD rZbfjeX E Gzt3f e5i lS L4UUjCD O Ui oLQmhWdymxFLax BKkPiqDUKn BKgMH8Nu OOVS
350610828. 0 PFRbc2BArP DeqB jVEyaVHif VZi fwQ A4 RiDD b HDE8CTSFm 43DKAjcyU 3 9dEKz0FVHOtz79zjE ETlB97TJ0WXkHYQcguukSHl1Z2q4lZynPCb6O BD1Evn MLuN58Gz5U5tfH 5 93Uqw
677987283. 0 T3 5DNLp9 X9wLdTL4X6wTtMrkQ5HawfcGi uN9bc 1eD4 iS P9 V6Itgtg M3iOk9mXLpD4 5 A3mhnAzs YeN8iaB N 4Nhqv4nT vsi2 ONbVmNPOq1Vhrlg5 R5 vCR0cbHejuwnctJSPd7h OL4wy Cuj ilcFOXr5miHu a5y FK8OXvuMve Iehwu7
…
661649546. zzzzrE9TYEZ7xI qKHEF8hmqD1SL sm9o W eQ lIWnuENs03f3RJ
19509282. zzzzl BLqUiyz4Y 5 UlX V5QNcQKodT w LIpJArcFvgoG aupAPkFYYYK9 UL8BmYJgO q 5 iIkKYk0 eLQo nJKyqZ o Bzk8 988 Y nK U8Kz0KuC17VVQ7
673120082. zzzzttmlaSyWDolu R45aVKf1 L1e 2NWcKEdobEo9arL ed pchwSQ VHoEilc 6gXmMC5plaT4 i6jkLT RBS5
451221061. zzzwzDQVrX OLTYpDbbRLCNej38d cY8aC0 Z1h626NCsblbH GQL za VxpjZ Mt tCJzNPIN2FDBpU1FSMgOMHauIaQEa lu 70vVmFPPogU6 28g aoOLkTneKK jIluHEILuJm gk
486393267. zzzzwTqF55fuu bE3F4 cY dqrzXDrRPhi5TkUzHpRpoe ESnH W n 7j 7NexNHbf i NbLCRBfw n PnyipETUDRD0xTeXLEby0xeh8LY2
Help will always be given at Hogwarts to those who ask for it.
Re: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Вот с тех пор мне интересно, где я мог пойти не тем путём: разница достаточно большаая, скорее всего на более медленном железе так плохо вышло не из-за каких-то микрооптимизаций, которые я не смог сделать, а в чём-то принципиальном. Но где
В целом вот чего сделал:
1) FileStream для чтения (не учитывает преамбулу для UTF-16, но это легко добавить)
2) Программа получает ключи сортировки строк и сохраняет их во временном файле
3) Применяет сжатие временных файлов
4) Параллельно выполняет шаги алгоритма разбиения
Re: Как правильно сортировать содержимое больших файлов?
Ну или можно держать ограниченную длину строки, а при сравнении если сроки одинаковы уже лезть в файл по смещению.
А проще для этого БД какую нибудь использовать
и солнце б утром не вставало, когда бы не было меня
S>А по индексам создаем новый файл. S>индекс= Строка,смещение. Сортировка по строка.
В теории многие так "решили" задачу, а на практике — никто.
S> Ну или можно держать ограниченную длину строки, а при сравнении если сроки одинаковы уже лезть в файл по смещению.
Это плохо работает. Проверил, даже код есть.
S>А проще для этого БД какую нибудь использовать
С этим тоже успехов что-то не видно.
Re[3]: Как правильно сортировать содержимое больших файлов?
S>>А по индексам создаем новый файл. S>>индекс= Строка,смещение. Сортировка по строка. G>В теории многие так "решили" задачу, а на практике — никто.
В БД это все решено
S>> Ну или можно держать ограниченную длину строки, а при сравнении если сроки одинаковы уже лезть в файл по смещению. G>Это плохо работает. Проверил, даже код есть.
И на какой длине строки проверял? Стандартный Б+ индекс 8 кб.
Сделай свой в 64 кб. Это если памяти не хватает. А по моему длины даже в 500 байт достаточно.
И это если памяти не хватает. Когда речь идет о 1ГБ это даже не смешно.
Вот когда файлы действительно огромные которые не вмещаются в память, Б+ деревья ооочень эффективны.
Особенно если используются SSD.
Причем можно создавать страницы с переменной длиной строки.
То есть страница загружается в память, выбираются данные в память, а потом двоичным поиском уже идет поиск.
Так или иначе нужно будет обращение к диску если страница незакэширована в памяти.
Обращение же к диску если строки равны и длина их больше чем половина страницы, то будет обращение к диску.
Скорость чтения SSD для 4 кб 500 тыщ в секунду. Вполне себе быстро.
S>>А проще для этого БД какую нибудь использовать G>С этим тоже успехов что-то не видно.
Да ну? А как же они работают то БД?
и солнце б утром не вставало, когда бы не было меня
Re[4]: Как правильно сортировать содержимое больших файлов?
S>>>А по индексам создаем новый файл. S>>>индекс= Строка,смещение. Сортировка по строка. G>>В теории многие так "решили" задачу, а на практике — никто. S> В БД это все решено
Нужно не теоретическое решение задачи сортировки большого файла, а практическое.
S>Скорость чтения SSD для 4 кб 500 тыщ в секунду. Вполне себе быстро.
А если не SSD?
S>>>А проще для этого БД какую нибудь использовать G>>С этим тоже успехов что-то не видно. S> Да ну? А как же они работают то БД?
БД отлично работают, а пока никто ен отсортировал файл в 100гб с помощью БД за разумное время.
Re[5]: Как правильно сортировать содержимое больших файлов?
S>>>>А по индексам создаем новый файл. S>>>>индекс= Строка,смещение. Сортировка по строка. G>>>В теории многие так "решили" задачу, а на практике — никто. S>> В БД это все решено G>Нужно не теоретическое решение задачи сортировки большого файла, а практическое.
Там кстати сравнение по скорости есть при работе в памяти
Число слов в тексте=528124
Количество слов 20359
Заполнение QuickDictionary (прямой доступ) 0.08363381379477
Заполнение TLSD (прямой доступ) 0.368364694395517
Заполнение Б+-дерева (прямой доступ) 0.461643030049909
А вот результаты сортировки 25 миллионного массива на Delphi
QuickSort 5.5 сек
MergeSort 5.8 сек.
Было это почти 20 лет тому назад!
Но интересно посмотреть при работе с диском.
На основании его можно сделать дерево с хранением на диске. Причем верхние уровни можно хранить в памяти.
При этом как и писал на странице хранить строки по их длине без лишнего места.
То есть длина строки, строка, смещение в файле, реальная длина строки.
Все это упаковано последовательно на странице.
S>>Скорость чтения SSD для 4 кб 500 тыщ в секунду. Вполне себе быстро. G>А если не SSD?
А если не SSD, то сортировкой слияния от чтения диска не обойтись.
S>>>>А проще для этого БД какую нибудь использовать G>>>С этим тоже успехов что-то не видно. S>> Да ну? А как же они работают то БД? G>БД отлично работают, а пока никто ен отсортировал файл в 100гб с помощью БД за разумное время.
Это зависит от свободной памяти. Сейчас сервера и с терробайтами памяти реальная вещь и еще с SSD.
Но вот чем тебе мое решение не нравится с переменной длиной строки? Индексы будут содержать больше полезной информации, а значит и высота дерева будет меньше и меньше чтения диска.
Хотя скорее всего сортировка слиянием будет быстрее.
и солнце б утром не вставало, когда бы не было меня