Здравствуйте, _FRED_, Вы писали:
_FR>Привет,
Так в итоге на что задача? radix sort? бакет сорт? внешняя сортировка? По строкам хэши считаем и сравниваем их?
Sic luceat lux!
Re[2]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Kernan, Вы писали:
K>Так в итоге на что задача? radix sort? бакет сорт? внешняя сортировка? По строкам хэши считаем и сравниваем их?
Во время очного интервью мы эту задачу совсем и не обсуждали (мне сказали, что её будут смотреть или смотрели другие люди), потом только после настойчивой просьбы я получил скупую строку о том, что "хорошо то, плохо это, а, вообще, медленно"
Help will always be given at Hogwarts to those who ask for it.
Re: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Решение моё интервьюеров не удовлетворило, говорят, что очень медленно работает: как обычно, у меня на лаптопе как раз всё летает, файл в 1Г сортируется за 13 с небольшим секунд, а у ревьюеров получилось 130c на файл 1 гиг Так мне написали. _FR>Вот с тех пор мне интересно, где я мог пойти не тем путём: разница достаточно большаая, скорее всего на более медленном железе так плохо вышло не из-за каких-то микрооптимизаций, которые я не смог сделать, а в чём-то принципиальном. Но где
Я думаю дело в том, что их код, как и код на питоне упомянутый в этой теме, не работает со строками. Он работает с массивами байт.
При отказе от строк любая реализация на .NET ускоряется в 8-10 раз и потребление тоже падает.
На этапе получения задания надо было уточнить какие именно строки имеются ввиду и как их сравнивать.
Re[2]: Как правильно сортировать содержимое больших файлов?
Сделал сначала наивное решение с асинхронным IO как полагается. Получилось в 2 раза медленнее вашего. Начал "оптимизировать" переводя все на работу с Memory и Span вместо string. Кроме того распараллелил IO с сортировкой, добавил MemoryPool чтобы уменьшить аллокации.
Смог сделать на решение, которое было на 15% медленнее вашего. Причем ускорилась фаза разбиения, а слияние почти ничего не выиграло.
Я понял что не туда копаю, я прочитал весь тред и все по ссылкам, позапускал ваш вариант и питоновский код, в итоге выпилил асинхронность и написал самое простое решение, которое только может быть.
Разбиение на куски
Encoding encoding;
List<string> tempFiles;
using (var reader = new StreamReader(file, true))
{
encoding = reader.CurrentEncoding;
tempFiles = reader
.EnumerateLines()
.Chunk(chunkSize)
.Select(chunk => {
Array.Sort(chunk, comparer);
var tempFileName = Path.GetTempFileName();
File.WriteAllLines(tempFileName, chunk);
return tempFileName;
}).ToList();
}
public static IEnumerable<string> EnumerateLines(this StreamReader reader)
{
while (!reader.EndOfStream)
{
yield return reader.ReadLine()!;
}
}
Объединение кусков:
var files = tempFiles
.Select(f => File.OpenText(f))
.ToList();
File.WriteAllLines(file, files.Select(f => f.EnumerateLines()).MergeLines(comparer), encoding);
files.ForEach(f => f.Dispose());
tempFiles.ForEach(f => File.Delete(f));
public static IEnumerable<string> MergeLines(this IEnumerable<IEnumerable<string>> sources, IComparer<string> comparer)
{
var enumerators = ( from source in sources
let e = source.GetEnumerator()
where e.MoveNext()
select e ).ToList();
while (enumerators.Any())
{
var min = enumerators.MinBy(e => e.Current, comparer);
yield return min.Current;
if (!min.MoveNext())
{
enumerators.Remove(min);
min.Dispose();
}
}
}
Внезапно оно показало лишь немного проиграло вашему коду, но значительно проиграло коду на питоне.
Далее я сделал две вещи: добавил .AsParallel() в фазу разбиения, чтобы чанки разбивались и записывались в несколько потоков и поменял реализацию MergeLines на использование PriorityQueue.
Много нового для себя узнал:
1) async медленный, не надо все подряд делать async, особенно в консольном приложении.
2) Диски достаточно быстрые, чтобы программа которая пишет 50-100мб\сек упиралась в скорость работы кода, а не в IO.
3) Алгоримты рулят. У меня было подозрение что поиск наименьшего значения из итераторов медленно работает, но я не думал что замена на PriorityQueue ускорит слияние почти в три раза.
4) Обогнать StreamReader\StreamWriter можно, но смысла нет, это не дает заметного прироста
5) Строки это дорого, особенно когда они не влезают в оперативную память.
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, gandjustas, Вы писали:
G>>Обогнал вашу версию, работает примерно как версия на питоне. Полный код тут: https://github.com/gandjustas/HugeFileSort
_FR>Круто, спасибо! Пока не могу посмотреть и запустить.
_FR>А что с расходом памяти? Например, если файл в 10 гигов разбиватт на 200 кусков по ~50 метров?
Сегодня тестил на 100М строк 14 ГБ, сортировка по дефлоту разбивает на куски по 100к строк, примерно 150мб кусок. Потребление памяти с параллелизмом до 3 гб на моей машине.
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, gandjustas, Вы писали: G>>>Обогнал вашу версию, работает примерно как версия на питоне. Полный код тут: https://github.com/gandjustas/HugeFileSort _FR>>А что с расходом памяти? Например, если файл в 10 гигов разбиватт на 200 кусков по ~50 метров? G>Сегодня тестил на 100М строк 14 ГБ, сортировка по дефлоту разбивает на куски по 100к строк, примерно 150мб кусок. Потребление памяти с параллелизмом до 3 гб на моей машине.
Мне всё-таки кажется, что это не совсем правильный подход к решению данной задачи.
Я рассуждаю так: если задача сортировки файла в условиях недлостаточной памяти возникла. значимт при решении задачи нам нужно в первую очередь экономить память, а во-вторую уже ускорять.
Если я правильно понял ваши вводные: исходный файл на 14Г из 100М строк, каждая строка до 256 символов + строковое представление инта
разбивается на файлы по 100к строк, каждый кусок по 150М
Я как-нибудь попробую. Я себе условия взял пожёсче: строка до 1024 символов и UInt64 впереди. В файле чуть меньше 20М строк и 10Г (для точности 19,759,397 строк и 10,737,419,483 байт)
разбивается на файлы по 100л строк, выходит по ~54М (54,350,975 байт)
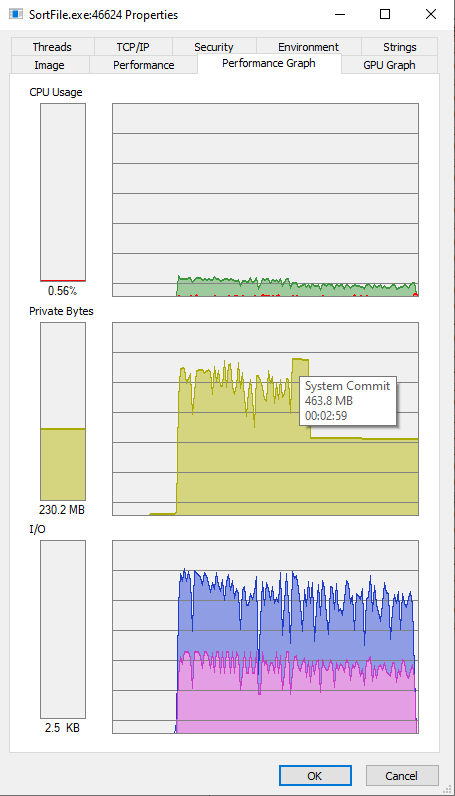
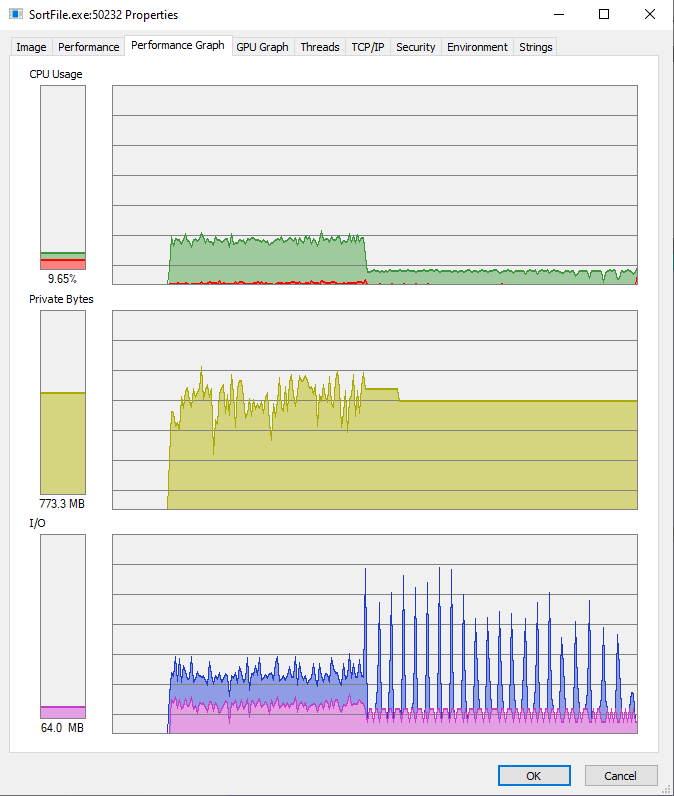
Разбиение занимает 00:01:06, слияние 00:01:10, всё вместе (видимо, добавляется удаление файлов) 00:02:20, при этом памяти в пике потратилось до 500М
Картинка Performance Graph
Если при разбиении файла вместо всего двух буферов под данные использовать больше, по числу процессоров, как выше предложили, скорость разбиения улучшается на 20..25 процентов, а память возрастает вдвое, поэтому пока это не так интересно.
Интересно будет ваш и мой код запустить на одном и том же файле на одной и той же машине и сравнить память/время.
Help will always be given at Hogwarts to those who ask for it.
Re[5]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, gandjustas, Вы писали:
G>>>>Обогнал вашу версию, работает примерно как версия на питоне. Полный код тут: https://github.com/gandjustas/HugeFileSort _FR>>>А что с расходом памяти? Например, если файл в 10 гигов разбиватт на 200 кусков по ~50 метров? G>>Сегодня тестил на 100М строк 14 ГБ, сортировка по дефлоту разбивает на куски по 100к строк, примерно 150мб кусок. Потребление памяти с параллелизмом до 3 гб на моей машине.
_FR>Мне всё-таки кажется, что это не совсем правильный подход к решению данной задачи. _FR>Я рассуждаю так: если задача сортировки файла в условиях недлостаточной памяти возникла. значимт при решении задачи нам нужно в первую очередь экономить память, а во-вторую уже ускорять.
Не "в условиях недостаточной памяти", а "размер файла заведомо превышает объем ОП", это разные условия.
В исходной задаче какой-либо речи об "экономии" не шло.
_FR>Разбиение занимает 00:01:06, слияние 00:01:10, всё вместе (видимо, добавляется удаление файлов) 00:02:20, при этом памяти в пике потратилось до 500М
По чистому времени сложно судить, сильно от характеристик диска зависит.
У меня генерация файла в 10Г выполняется 2 минуты.
_FR>Если при разбиении файла вместо всего двух буферов под данные использовать больше, по числу процессоров, как выше предложили, скорость разбиения улучшается на 20..25 процентов, а память возрастает вдвое, поэтому пока это не так интересно.
Почему 25%? Если берем SSD, то подготовка чанка занимает времени примерно столько же, сколько сортировка. Запись на SSD параллелится почти 100%.
25% это наверное актуально для HDD. Но тогда как записать 10Г за минуту, если средняя скорость линейной записи и чтения 100-120 мб\сек?
_FR>Интересно будет ваш и мой код запустить на одном и том же файле на одной и той же машине и сравнить память/время.
Вам ничего не мешает. Питоновский код Буравчика тоже запустите заодно.
Re[6]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, gandjustas, Вы писали:
_FR>>Мне всё-таки кажется, что это не совсем правильный подход к решению данной задачи. _FR>>Я рассуждаю так: если задача сортировки файла в условиях недлостаточной памяти возникла. значимт при решении задачи нам нужно в первую очередь экономить память, а во-вторую уже ускорять. G>Не "в условиях недостаточной памяти", а "размер файла заведомо превышает объем ОП", это разные условия. G>В исходной задаче какой-либо речи об "экономии" не шло.
Ну эт по меньшей мере странно так решать: Ведь о том, сколько есь памяти в условии тоже ни слова, при этом единственный смысл в такой сортировке, как мы делаем — это экономия памяти, потому чемь меньше тем лучше. Я вот сейчас играюсь с размерами буферов для файлов, пока доигрался до того, что разбивая тот же исходный файл на пачки по 50к строк / 27М (396 файлов) укладываюсь в 00:02:22 и 250М оперативной памяти Вы, запуская мой код не пробовали параметры подобрать такие, чтобы тоже 3Г тратилось бы?
_FR>>Разбиение занимает 00:01:06, слияние 00:01:10, всё вместе (видимо, добавляется удаление файлов) 00:02:20, при этом памяти в пике потратилось до 500М G>По чистому времени сложно судить, сильно от характеристик диска зависит. G>У меня генерация файла в 10Г выполняется 2 минуты.
Если будет интересно: попробуйте у себя заменить int на ulong и максимальную сдлину строки выставить в 1024 и сравнить с моей.
_FR>>Если при разбиении файла вместо всего двух буферов под данные использовать больше, по числу процессоров, как выше предложили, скорость разбиения улучшается на 20..25 процентов, а память возрастает вдвое, поэтому пока это не так интересно. G>Почему 25%? Если берем SSD, то подготовка чанка занимает времени примерно столько же, сколько сортировка. Запись на SSD параллелится почти 100%. G>25% это наверное актуально для HDD. Но тогда как записать 10Г за минуту, если средняя скорость линейной записи и чтения 100-120 мб\сек?
Нет, у меня SSD. Я просто сравнил 51 секунду в реализации с очередью из ProcessorCount списков и 66 секунд в моей первой реализации с двумя списками.
Help will always be given at Hogwarts to those who ask for it.
Re[6]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, gandjustas, Вы писали: G>>>>>Обогнал вашу версию, работает примерно как версия на питоне. Полный код тут: https://github.com/gandjustas/HugeFileSort _FR>>>>А что с расходом памяти? Например, если файл в 10 гигов разбиватт на 200 кусков по ~50 метров? G>>>Сегодня тестил на 100М строк 14 ГБ, сортировка по дефлоту разбивает на куски по 100к строк, примерно 150мб кусок. Потребление памяти с параллелизмом до 3 гб на моей машине. _FR>>Интересно будет ваш и мой код запустить на одном и том же файле на одной и той же машине и сравнить память/время. G>Вам ничего не мешает.
Запускал на лаптопе с 32Г оперативки и 6х2 ядрами
Собрал ваш код. Добавил вывод в консоль времени выполнения, поменял сравнение строк на Ordinal, потому как заметно быстрее и стал сохранять результат в новый файл, а не перезаписывать исходный:
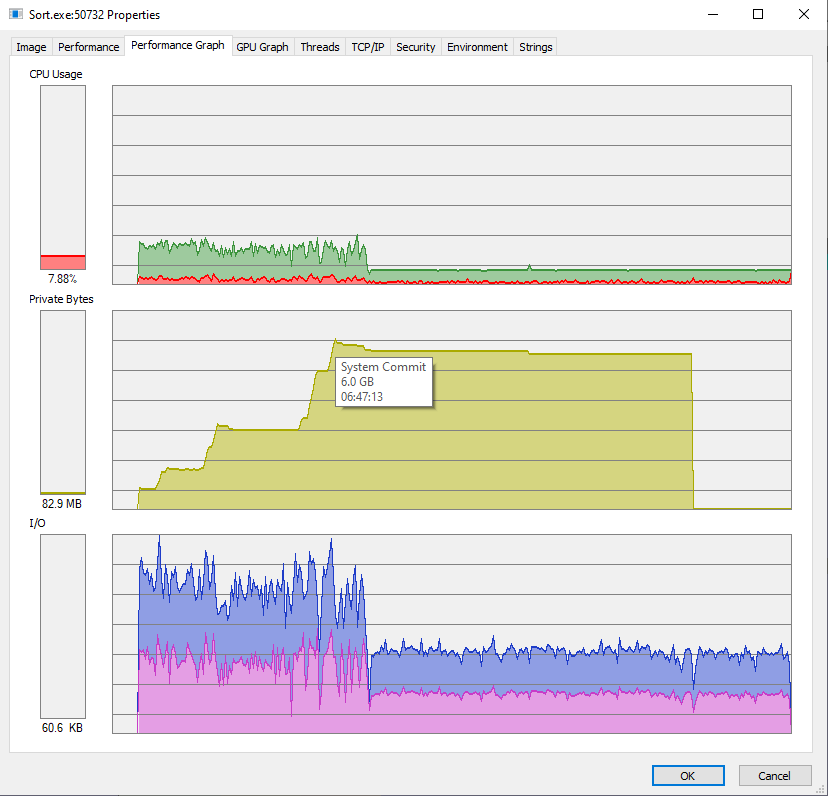
Генерация файла на 100М строк (3.8 GB (14,898,287,710 bytes)) на моём лаптопе заняла 04:47:54. // Имя файла "DataSort-10G.txt", хотя его размер 14Г
Сортировка этого файла с настройками по-умолчанию (файл разбивается на пачки по 100к строк):
Splitted in 00:02:26.8240463
Merged in 00:04:16.3986896
Sorted in 00:06:45.3281167
по мелочи причесал
перевёл на .NET 7.0
сделал настраиваемое число буферов, в которые может вычитываться исходный файл во время разбиения. В тесте использовал 4 буфера.
Подобрал размеры буферов для размеров промежуточных файлов (по 300к строк и чуть меньше 45М) и для используемых стримов
В итоге тот же исходный файл на том же лаптопе со всей асинхронностью:
Split to 334 files / 100,000,000 lines in 00:02:01.6797598
Merge 334 files in 00:02:44.2937083
File "DataSort-10G.txt" sorted as "DataSort-10G-335.txt" in 00:04:46.7148925.
Памяти использовалось около одного гигабайта, но на картинке ниже тултип не запечатлелся :о(
Performance Graph
В общем я не увидел описанных вами выше преимуществ :
С асинками у меня быстрее, а если добавить в Merge PriorityQueue<,> то становится медленнее. Ручное вычитывание и разбор строки позволили сэкономить дастаточно много — в 6 раз меньше, памяти (и, за счёт памяти же, видимо, и времени).
Будет сильно интересно, если кто-то ещё погоняет и поделится результатами. G>Питоновский код Буравчика тоже запустите заодно.
Это как-нить потом, когда будет время разобраться, как его запускать. Мне показалось, что этот код Тестовое задание Senior .Net — критикуйте так же не особенно старается экономить память. Но я в пайтоне не силён.
Help will always be given at Hogwarts to those who ask for it.
Re[4]: Как правильно сортировать содержимое больших файлов?
Здравствуйте, Буравчик, Вы писали:
Б>Ваша реализация работает достаточно быстро (хотя написана сложно, на мой взгляд). И почему-то жрет память.
Наверно потому, что у вас числа в начале короткие. А у _FRED_а они длиннее самой строки:
Здравствуйте, Буравчик, Вы писали:
A>>Наверно потому, что у вас числа в начале короткие. А у _FRED_а они длиннее самой строки:
Б>Я тестировал на одном и том же файле, который был сгенерирован кодом _FRED_
В релизе же? У меня сильно по-разному это работает в зависимости от конфигурации.
В Дебаге строки короче и заканчиваются пайпом | для облегчения отладки и понимания, что строки вычитались правильно.
Я обязательно найду время запустить ваш код.
Help will always be given at Hogwarts to those who ask for it.
Re: Как правильно сортировать содержимое больших файлов?
К сожалению, ваша прога крешится без каких-либо сообщений. Проверял на 100 млн. записей, 13,8 Гб, который сгенерил этой прогой https://github.com/gandjustas/HugeFileSort
Хотел сравнить скорость — но увы! Ваша прога создала 1000 файлов, потом начала мерждить, дошла до 100% (или почти 100%, не помню). Все красиво так. А потом опа — и просто закрывается, когда доходит до 100%
Т.е. вам нужно как минимум добавить текст ошибки или лог, чтобы был шанс понять в чем проблема.
Re: Как правильно сортировать содержимое больших файлов?
Мое: https://github.com/artelk/RowsSort
Сделано в предположение, что файлы ASCII, числа укладываются в ulong, стоки длиной от 2 до 256 и строки случайны (!).
Последний пункт используется, чтобы примерно равномерно поделить строки по первым символам.
Агоритм:
1. Разбиваем строки на множество чанков. Критерий разбивки — первый символ плюс старшие 3 бита второго символа.
2. Строки в чанки пишутся в бинарном формате: <strLenByte><string><num8bytes>. Это нужно, чтоб размер файлов немного уменьшить. Первый символ у строк отрезается, т.к. он общий у всех строк чанка. Лишний пробел, точка и \r\n тоже не пишется. Экономим на спичках
Если размер алфавита маленький, можно было бы как-то меньшим числом битов символы кодировать, чтобы еще сильнее сжать.
3. По очереди читаем файлы чанков в лексикографическом порядке, сортируем их и записываем в результирующий файл.
Для сортировки чанков реализовал Radix Sort. Чанки открываются как memory mapped files. Много unsafe и указателей
На моем железе сортировшик FREDа на файле 1Гб работает за 2 минуты, а мой за 40 секунд.
Возможно, на другом железе будет обратная картина, т.к. я ничего не параллелил и на моем ноуте узкое место это HDD (хотя саму сортировку можно было бы как-то в параллель IO сделать).
На Очень больших файлах размер чанков может оказаться слишком большим и не влезать в память, так что алгоритм разбивки придется доточить.
A>Сделано в предположение, что файлы ASCII, числа укладываются в ulong, стоки длиной от 2 до 256 и строки случайны (!). A>Последний пункт используется, чтобы примерно равномерно поделить строки по первым символам.
Мне кажется, это довольно вольная трактовка задания, про случайность строк ничего сказано не было.
A>На моем железе сортировшик FREDа на файле 1Гб работает за 2 минуты, а мой за 40 секунд. A>Возможно, на другом железе будет обратная картина, т.к. я ничего не параллелил и на моем ноуте узкое место это HDD (хотя саму сортировку можно было бы как-то в параллель IO сделать).
О, это уже похоже на то, что было у проверяющих.
Вы запускали релиз?
С каким файлом (созданным моим же генератором или) или другой?
По сколько строк разбивали исходный файл?
Можете показать вывод программы и расход памяти (гистограмму из процесс эксплорера или таск менеджера)?
A>Просьба кому не лень погонять у себя и рассказать
Я на днях погоняю
Help will always be given at Hogwarts to those who ask for it.
Re[2]: Как правильно сортировать содержимое больших файлов?
S>Хотел сравнить скорость — но увы! Ваша прога создала 1000 файлов, потом начала мерждить, дошла до 100% (или почти 100%, не помню). Все красиво так. А потом опа — и просто закрывается, когда доходит до 100%
Отлично! Во-первых, она получается почти смёрджила! Покажите её лог с консоли пожалуйста ну и сколько времени она проработала до того как упасть?
Просто Стас в свой файл в конец записывает финальный перенос строки, а я не записываю. Возможно проблема с этим.
Или может вы батник запускали по Enter и просто не увидели результутов? Моя программа как всё сделала, пишет в консоль время и закрывается. Запустите вручную из консоли или добавьте строчку с @Pause в конец батника.
Вы запускали у меня релиз? С ветки main или use-read-buffers-queue?
У меня ошибок этот лишний перенос строки не вызывает, но может оставаться лишний "пустой" файл, поэтому интересно узнать, что за ошибка. Запустите Release конфигурацию под отладчиком пожалуйсита и посмотрите, что за ошибка и где?
S>Т.е. вам нужно как минимум добавить текст ошибки или лог, чтобы был шанс понять в чем проблема.
Здравствуйте, artelk, Вы писали:
A>Здравствуйте, _FRED_, Вы писали:
A>Мое: https://github.com/artelk/RowsSort A>Сделано в предположение, что файлы ASCII, числа укладываются в ulong, стоки длиной от 2 до 256 и строки случайны (!). A>Последний пункт используется, чтобы примерно равномерно поделить строки по первым символам.
Имхо слишком сильные допущения. Что будет если попробовать отсортировать файл в 50ГБ одинаковых строк?
Кстати почему выбрано 256? Если будет не 265, а 1024 на что повлияет?