В системе есть объекты только двух размеров 64 и 128 байтов.
Нужен быстрейший менеджер памяти для динамической аллокации/деаллокации таких объектов, но память надо использовать экономно. Понятно, что быстрее всех будет всегда аллоцировать по 128 байтов, но тогда будет оверхед по расходу памяти в случае когда нужны лишь 64 байтные объекты.
Традиционный алгоритм объединяющий блоки вроде медленный (или нет?).
Существует ли эффективное решение для этого частного случая?
Пока в голову лезет идея размещать объекты размером 128 с одной стороны имеющегося куска памяти, а размера 64 с другой стороны.
При деаллокации "крайние" блоки можно возвращать обратно в "общую сырую память". А "некрайние" блоки ставить в список неиспользуемых (связный список организовать разумеется на самих же неиспользуемых блоках).
Правда экперименты на случайных данных показали, что возврат блоков в общую сырую память происходит крайне неохотно.
Какие ещё есть мысли?
Re: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Сергей Губанов, Вы писали:
СГ>Нужен быстрейший менеджер памяти для динамической аллокации/деаллокации таких объектов, но память надо использовать экономно. Понятно, что быстрее всех будет всегда аллоцировать по 128 байтов, но тогда будет оверхед по расходу памяти в случае когда нужны лишь 64 байтные объекты.
Хотелось бы узнать про сценарии работы. Хотя бы, сколько объектов в среднем и в пике, и известен ли вообще пик.
Почему возникло желание сделать одну общую кучу, а не две разных, под 64 и 128.
Почему не зарезервировать память сразу под пик количества.
Перекуём баги на фичи!
Re: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Сергей Губанов, Вы писали:
СГ>Нужен быстрейший менеджер памяти для динамической аллокации/деаллокации таких объектов, но память надо использовать экономно. Понятно, что быстрее всех будет всегда аллоцировать по 128 байтов, но тогда будет оверхед по расходу памяти в случае когда нужны лишь 64 байтные объекты.
Сделать два пула фиксированного размера, в каждом
1. кусок памяти для нарезки
2. массив номеров свободных блоков
3. число свободных блоков (оно же индекс в массив (2)).
быстрее и проще вряд-ли получится.
Re: Быстрейший менеджер памяти для двухтиповой системы
Насколько критично быстро надо?
Этот вопрос — так как придется писать свое и в зависимости от ответа можно выбрать алгоритм по проще в отладке.
И это у вас монопольный доступ или несколько потоков?
И насколько много могут запросить?
Самый быстрый это два статических массива со стеком свободных блоков. Два имеется ввиду один по 64, другой по 128.
Не все кто уехал, предал Россию.
Re: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Сергей Губанов, Вы писали:
СГ>Существует ли эффективное решение для этого частного случая?
1. Представить всю память, как последовательность 64-байтовых блоков
2. Завести битовый массив занятости, по биту на каждый 64-байтовый блок (можно по байту, для ускорения доступа)
3. Назовем "близнецами" два соседних 64-байтовых блока, если положение первого относительно начала памяти делится на 128. 128-байтные блоки выделять всегда, как пару 64-байтовых близнецов (удобнее начало памяти выровнять на 128, тогда можно работать с адресами блоков, а не со смещениями)
4. Завести 2 списка свободных блоков, один для 64-байтовых, другой — для 128-байтовых. Указатель на следующий хранить в самом свободном блоке
5. Изначально нарезать всю память на 128-байтовые блоки и поместить в соответствующий список
6. При аллокации 128-байтового блока смотрим на соответствующий список. Если там есть чего аллоцировать, аллоцируем
7. При аллокации 64-байтового блока смотрим сначала на соответствуюший список. Если там пусто, пытаемся зааллоцировать 128-байтовый блок, разрезаем его на две части, одну суем в список свободных 64-байтовых, вторую аллоцируем. В любом случае, если удалось зааллоцировать, помечаем блок, как занятый (в битовом массиве)
8. При освобождении 128-байтового блока просто суем его в соответствующий список
9. При освобождении 64-байтового блока смотрим в битовый массив, свободен ли его близнец. Если да, удаляем его из списка свободных 64-байтовых, и объединенный 128-байтовый засовываем в соответствующий список. Если нет, то просто засовываем освободившийся 64-байтовый блок в список свободный 64-байтовых, и помечаем, как свободный, в битовом массиве. Зная адрес 64-байтового блока, адрес близнеца вычислить несложно.
Списки понадобятся двунаправленные, чтобы можно было легко удалять элементы из середины.
Здравствуйте, Кодт, Вы писали:
К>Хотелось бы узнать про сценарии работы. Хотя бы, сколько объектов в среднем и в пике, и известен ли вообще пик. К>Почему возникло желание сделать одну общую кучу, а не две разных, под 64 и 128. К>Почему не зарезервировать память сразу под пик количества.
Одна куча желательна потому, что пропорция между количествами 64 и 128 байтными объектами динамическая. На всё есть примерно 256 Мб, это либо 2 миллиона по 128, либо 4 миллиона по 64. В среднем ожидается нагрузка в 1.5 миллиона объектов (и тех и других вместе). Пиковая нагрузка может быть больше, поэтому и возникает желание более экономного расхода памяти. Одно дело если мы выбросим объект потому что вся память кончилась (это значит случился форс мажор), и совершенно другое дело если мы выкинем объект потому что кончилась память в одном из массивов, а не вообще вся память (это значит мы сами дураки).
Ещё могу добавить, что среднестатистически время жизни 64 байтных объектов будет в 10 раз короче чем 128 байтных, но создаваться они будут в 10 раз чаще.
Re[3]: Быстрейший менеджер памяти для двухтиповой системы
Обычно про проектировании разделяют — "работу", которая должна быть быстрой и редкие события типа — требуется перераспределение памяти.
Вот из этого и исходите.
Если у вас например требуется быстрая реакция системы, то есть задача черезвычайно критическая по скрости, то делают что-то типа "прокси" которая максимально быстро выделяет и фиксирует освобождение блока. А в моменты когда нагрузка снижается или в фоне в пакете делается уже оптимизация памяти.
Насколько я помню (давно уже этим занимался), стандартный "malloc" или другой стандартный аллокатор в С++, сейчас использует один из самых лучших алгоритмов. То есть кардинально улучшить его можно только статическим аллокатором. Но тут придется пожертвовать возможно не оптимальным использованием памяти. Поэтому надо понять стоит оно того или нет.
Не все кто уехал, предал Россию.
Re[2]: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Andrew.W Worobow, Вы писали:
AWW>Насколько критично быстро надо?
Нужна минимизация количества обращений к памяти. Если один алгоритм будет обращаться к памяти N раз, а второй N+1 раз, то первый алгоритм получает существенное преимущество.
Re[3]: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Сергей Губанов, Вы писали:
СГ>Нужна минимизация количества обращений к памяти. Если один алгоритм будет обращаться к памяти N раз, а второй N+1 раз, то первый алгоритм получает существенное преимущество.
Тут скорее важно не сколько обращений, а насколько надо сделать быстрее чем есть в стандарте? И почему?
Не всегда на современных процессорах может оказаться алгоритм с N обращений к памяти быстрее по времени чем алгоритм с N+1. Всегда надо учитывать реализацию на железе.
Надо смотреть в профайлере всегда. И смотреть ассемблерный код.
Вообще самый быстрый алгорим как я уже писал — это массив с указателем последнего выделенного блока, куда кладут если стек свободных пуст, и сам стек куда кладут блоки когда освобождают блоки. Если размер стека стал равным номеру свободного блока то указатель "перематывают".
А вообще ИМХА ваш вопрос очень хорошо проработан, просто поищие в гугле.
Не все кто уехал, предал Россию.
Re[3]: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Сергей Губанов, Вы писали:
СГ>Одна куча желательна потому, что пропорция между количествами 64 и 128 байтными объектами динамическая. На всё есть примерно 256 Мб, это либо 2 миллиона по 128, либо 4 миллиона по 64. В среднем ожидается нагрузка в 1.5 миллиона объектов (и тех и других вместе). Пиковая нагрузка может быть больше, поэтому и возникает желание более экономного расхода памяти. Одно дело если мы выбросим объект потому что вся память кончилась (это значит случился форс мажор), и совершенно другое дело если мы выкинем объект потому что кончилась память в одном из массивов, а не вообще вся память (это значит мы сами дураки).
СГ>Ещё могу добавить, что среднестатистически время жизни 64 байтных объектов будет в 10 раз короче чем 128 байтных, но создаваться они будут в 10 раз чаще.
Интересна ещё цена ложного отказа.
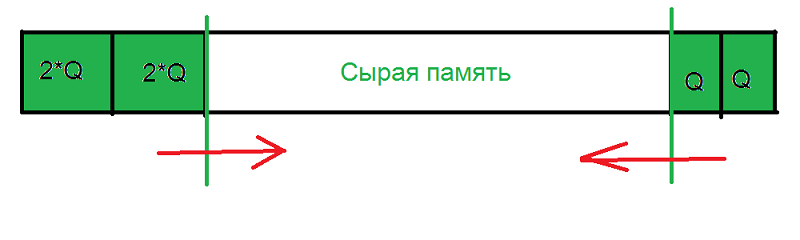
Допустим, у нас два пула объектов (как на исходной картинке — два стека; или два набора страниц вперемешку; или ещё как-то).
Если осталось место на 10 объектов, но это место находится в противоположном пуле, и поэтому мы обломали пользователя, — это сами дураки, или допустимо?
А если на 100 объектов? На 1000?
Насколько это плохо? Надо ли бороться до последнего байта?
Перекуём баги на фичи!
Re[3]: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Сергей Губанов, Вы писали:
СГ>Здравствуйте, Кодт, Вы писали:
К>>Хотелось бы узнать про сценарии работы. Хотя бы, сколько объектов в среднем и в пике, и известен ли вообще пик. К>>Почему возникло желание сделать одну общую кучу, а не две разных, под 64 и 128. К>>Почему не зарезервировать память сразу под пик количества.
СГ>Одна куча желательна потому, что пропорция между количествами 64 и 128 байтными объектами динамическая.
Сделайте одну кучу, разделите её на несколько чанков с размером, кратным 128. Каждый чанк хранит в себе объекты либо только по 64 байта, либо по 128 (т.е. положить в один чанк объекты двух разных типов будет невозможно). Изначально чанк чист и позволяет сохранить в себя любой тип. После очистки занятого чанка от всех его объектов он снова становится чистым (т.е. снова можно сохранить объект любого типа).
Конечно, в этом случае эффективность утилизации памяти падает, но нет нужды разносить "мальчики налево — девочки направо".
Re[4]: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Кодт, Вы писали:
К>Если осталось место на 10 объектов, но это место находится в противоположном пуле, и поэтому мы обломали пользователя, — это сами дураки, или допустимо? К>А если на 100 объектов? На 1000? К>Насколько это плохо? Надо ли бороться до последнего байта?
Это вопрос конкурентоспособности програмного продукта. Убегая от медведя с товарищем, достаточно бежать быстрее товарища, а не выдыхаться до последнего байта ставя абсолютный мировой рекорд. Да, сколько-то памяти профукать можно, но наши конкуренты быстро бегут, как бы не обогнали...
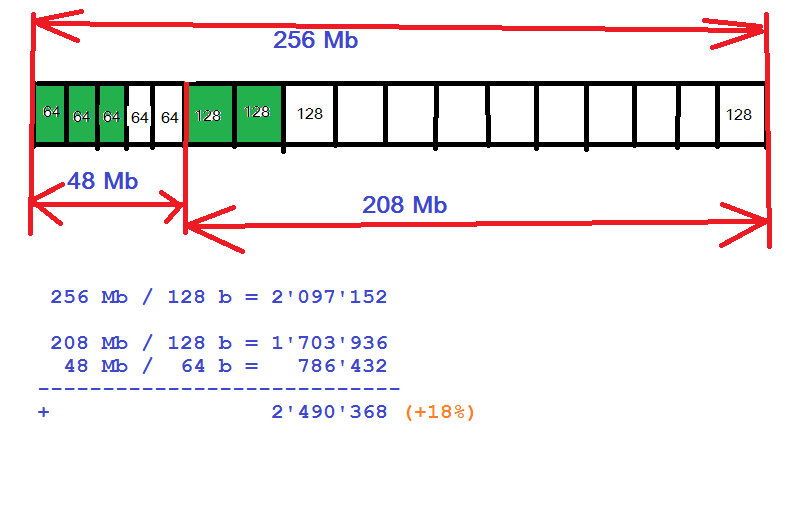
Вобщем, пока склоняюсь к следующему частному компромисному решению...
Заранее небольшое количество памяти нарезается для 64-байтных объектов, вся остальная память нарезается под 128-байтные объекты.
Все объекты помещаются в два односвязных списка свободных элементов (64 и 128 байтных). Списки организуются на памяти самих же свободных объектов.
Когда запрашивается 64 байта, тогда выдаётся элемент из списка 64-байтных, а когда этот список становится пустым, то, скрипя зубами, выдаётся, отрывается от сердца, элемент из списка 128 байтных блоков.
Как то так (число 48Mb взято просто для примера):
Когда указатель на 64 байтный объект возвращается, то одной проверкой if (p < 48Mb) выясняется кто он на самом деле: истинный 64 байтный или 128 байтовый. Соответственно, ставится в список свободных 64 или 128 байтных блоков.
Оптимальный размер памяти отдаваемый под 64 байтные объекты надо будет выяснить экспериментально.
Почему так, а не иначе:
1) Есть жёсткое ограничение на количество обращений к DDR3 памяти (пропускная способность контроллера памяти является "бутылочным горлышком" для нашего программного продукта).
2) Аллокация/деаллокация 64 байтных блоков происходит на порядок чаще чем 128 байтных.
Поэтому приходится отказываться от алгоритмов делающих слияние свободных блоков 64+64=128.
Если кто нибудь придумает как ещё больше сэкономить память не слишком сильно замедляя алгоритм, то это будет круто...
, поэтому получилось длинно.
Pzz>Даже полный buddy memory allocator, а не частный случай для двух размеров блоков, это достаточно короткая и довольно быстрая штука.
Pzz>И да, если тратить память не по 64/128, а по 65/130 байт, то бит занятости можно разместить в самом блоке.
Я вас понимаю, но, к сожалению, скован жёстким ограничением на минимизацию запросов к памяти DDR3. 64 — это размер кэш линии, то есть один запрос к памяти, 128 — два запроса к памяти. Все блоки расположены по адресам кратным 64. Флаг занятости разместить в самом блоке нельзя, так как пользователю нужны все 64 байта целиком. Размещать флаг занятости придётся в отдельно стоящем массиве, а значит придётся делать лишний запрос в память. Не важно что алгоритм становится на пять строк длиннее, а важно то, что он делает больше запросов к памяти. Мне даже можно на 70 тактов больше израсходовать на какие-нибудь вычисления, лишь бы в память не лазить лишний раз.
Здравствуйте, Сергей Губанов, Вы писали:
СГ>Здравствуйте, Pzz, Вы писали:
Pzz>>Слияние свободных блоков, это строк пять на Си
Pzz>>Просто я все очень подробно описал
, поэтому получилось длинно.
Pzz>>Даже полный buddy memory allocator, а не частный случай для двух размеров блоков, это достаточно короткая и довольно быстрая штука.
Pzz>>И да, если тратить память не по 64/128, а по 65/130 байт, то бит занятости можно разместить в самом блоке.
СГ>Я вас понимаю, но, к сожалению, скован жёстким ограничением на минимизацию запросов к памяти DDR3. 64 — это размер кэш линии, то есть один запрос к памяти, 128 — два запроса к памяти. Все блоки расположены по адресам кратным 64. Флаг занятости разместить в самом блоке нельзя, так как пользователю нужны все 64 байта целиком. Размещать флаг занятости придётся в отдельно стоящем массиве, а значит придётся делать лишний запрос в память. Не важно что алгоритм становится на пять строк длиннее, а важно то, что он делает больше запросов к памяти. Мне даже можно на 70 тактов больше израсходовать на какие-нибудь вычисления, лишь бы в память не лазить лишний раз.
При анализе обращений к памяти, учти кеш процессора.
Массив битов занятости — всего 16к.
Сколько тактов процессора пользователь тратит между захватами/освобождениями? очевидно не много, иначе требования к алокатору были бы не столь жесткие.
Re: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Сергей Губанов, Вы писали:
СГ>Какие ещё есть мысли?
Могу предложить вот такое решение.
В конце блока памяти выделяем блок равный одному биту на каждый 128байтовый блок. На 256М это будет всего 256 байт.
Из остальной памяти делаем список 128байтовых обьектов.
Если нужно 128: берем из 128 массива.
Если нужно 64:
— Берем из 64 массива и ставим бит в 1.
— Берем из 128 массива и добавляем остаток в 64.
Когда освобождается 128: добавляется в 128 массив.
Когда освобождается 64:
— Если бит в 1: добавляем блок в массив 64, ставим бит в 0.
— Если бит в 0: добавляем весь блок в массив 128.
Если и этот вариант сильно нагружен запросами к памяти, то можно скомбинировать его с вашим, когда 48 мегов идут на 64блоки, а остальное, в случае нехватки работает по алгоритму выше. Кстати, отличная идея, если вы сможете определить пространство, которое точно займут блоки по 64 байта. Пока они будут вариться в своем пространстве лишних обращений к памяти не будет вообще.
Римское правило. Тот, кто говорит, что Это не может быть сделано, никогда не должен мешать тому, кто Это делает.
Осень, ну вы поняли.
Зачем еще один код? А человек?
Re: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Сергей Губанов, Вы писали:
СГ>Какие ещё есть мысли?
Мысль тупая, но всё же — а рассматривал ли ты возможность переделать код использования 128 байтных блоков так, чтобы он использовал два блока по 64?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Re[2]: Быстрейший менеджер памяти для двухтиповой системы
СГ>>Какие ещё есть мысли?
.>Мысль тупая, но всё же — а рассматривал ли ты возможность переделать код использования 128 байтных блоков так, чтобы он использовал два блока по 64?
Мне не удалось придумать как это реализовать эффективно. Кроме того, возможно обострение проблемы с фрагментацией.
Re[3]: Быстрейший менеджер памяти для двухтиповой системы
Здравствуйте, Сергей Губанов, Вы писали:
СГ>>>Какие ещё есть мысли?
.>>Мысль тупая, но всё же — а рассматривал ли ты возможность переделать код использования 128 байтных блоков так, чтобы он использовал два блока по 64?
СГ>Мне не удалось придумать как это реализовать эффективно. Кроме того, возможно обостре ние проблемы с фрагментацией.
Это как? Фрагментации в принципе не будет, т.к. блоки одинакового размера.
А на счёт реализации, не знаю, тебе виднее. Если даже посто копировать в массив на 128байт на стеке и обратно,может получиться вполне эффективно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай


 Перекуём баги на фичи!
Перекуём баги на фичи!