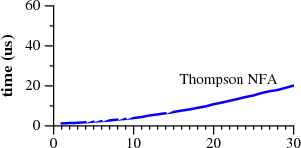
Как известно, секрет правильного приготовления движков по выполнению регулярных выражений был когда-то промышленностью изобретён (grep, awk), утерян (Perl, Python, PHP, Ruby), и изобретён вновь.
Проект Google Re2 (C++) — успешная попытка [вос]создать промышленный regex движок, свободный от экспоненциальной зависимости от входных данных. Этот проект, выполненный Рассом Коксом (Russ Cox), дал возможность гуглу эффективно выполнять поиск по регулярным выражениям в программном коде, найденном гуглом в интернете. В качестве ценнейшего артефакта были порождены три статьи про построение движков регулярок, давая интересный исторический контекст и описание эффективной имплементации.
<...>
Здравствуйте, Кодт, Вы писали:
К>http://lionet.livejournal.com/68807.html?style=mine К>[q] К>Как известно, секрет правильного приготовления движков по выполнению регулярных выражений был когда-то промышленностью изобретён (grep, awk), утерян (Perl, Python, PHP, Ruby), и изобретён вновь.
Мне казалось, в Perl, Python, PHP, Ruby регэкспы просто более мощные и по своим возможностям уже не влезают в НКА. Ну, было бы круто, конечно, динамически определять, и выбирать НКА-шную реализацию, когда это можно, но видимо поленились.
Здравствуйте, SergH, Вы писали:
SH>Мне казалось, в Perl, Python, PHP, Ruby регэкспы просто более мощные и по своим возможностям уже не влезают в НКА. Ну, было бы круто, конечно, динамически определять, и выбирать НКА-шную реализацию, когда это можно, но видимо поленились.
Перловые регекспы (с расширениями) — то ли подмножество контекстно-свободных, то ли даже контекстно-зависимых языков.
Для КС — судя по пьесе, тоже можно построить матчер.
Впрочем, бизон ведь тоже парсит за линейное время, без откатов.
Интересное место вот здесь: http://lionet.livejournal.com/68807.html?thread=1868999#t1868999
Получается, что кодогенерация поверх построенного дерева регекспов рвёт даже тузика (я сделал на шаблонах, у меня что-то все в 10 раз разогналось...). В десять раз — это типа 7.5 m chars/sec. Сразу возникает вопрос — а что, если строить матчер в виде Expression<...>, а потом делать ему compile? По идее, получим специализированный матчер с асимптотикой n*m и при этом с хорошей константой перед ними.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, SergH, Вы писали:
SH>Здравствуйте, Кодт, Вы писали:
К>>http://lionet.livejournal.com/68807.html?style=mine К>>[q] К>>Как известно, секрет правильного приготовления движков по выполнению регулярных выражений был когда-то промышленностью изобретён (grep, awk), утерян (Perl, Python, PHP, Ruby), и изобретён вновь.
SH>Мне казалось, в Perl, Python, PHP, Ruby регэкспы просто более мощные и по своим возможностям уже не влезают в НКА. Ну, было бы круто, конечно, динамически определять, и выбирать НКА-шную реализацию, когда это можно, но видимо поленились.
Если регэкспы не влезают в НКА, то это уже не регэкспы, а извращение. Для нерегулярных языков придуманы другие формализмы.
Также, не понятно, зачем используют NFA вместо DFA.
Здравствуйте, Aleх, Вы писали:
A>Если регэкспы не влезают в НКА, то это уже не регэкспы, а извращение. Для нерегулярных языков придуманы другие формализмы.
Здравствуйте, Кодт, Вы писали:
SH>>Мне казалось, в Perl, Python, PHP, Ruby регэкспы просто более мощные и по своим возможностям уже не влезают в НКА. Ну, было бы круто, конечно, динамически определять, и выбирать НКА-шную реализацию, когда это можно, но видимо поленились. К>Перловые регекспы (с расширениями) — то ли подмножество контекстно-свободных, то ли даже контекстно-зависимых языков.
В Перле в регэкспы можно любой код вставлять
Здравствуйте, Sinclair, Вы писали:
S>Интересное место вот здесь: S>http://lionet.livejournal.com/68807.html?thread=1868999#t1868999 S>Получается, что кодогенерация поверх построенного дерева регекспов рвёт даже тузика (я сделал на шаблонах, у меня что-то все в 10 раз разогналось...). В десять раз — это типа 7.5 m chars/sec. Сразу возникает вопрос — а что, если строить матчер в виде Expression<...>, а потом делать ему compile? По идее, получим специализированный матчер с асимптотикой n*m и при этом с хорошей константой перед ними.
Да, это один из древнейших баянов. Я где-то видел матчер регэкспов с компиляцией в SSE-код. Рвал на куски ВСЁ.
Здравствуйте, SergH, Вы писали:
SH>Здравствуйте, Кодт, Вы писали:
К>>http://lionet.livejournal.com/68807.html?style=mine К>>[q] К>>Как известно, секрет правильного приготовления движков по выполнению регулярных выражений был когда-то промышленностью изобретён (grep, awk), утерян (Perl, Python, PHP, Ruby), и изобретён вновь.
SH>Мне казалось, в Perl, Python, PHP, Ruby регэкспы просто более мощные и по своим возможностям уже не влезают в НКА. Ну, было бы круто, конечно, динамически определять, и выбирать НКА-шную реализацию, когда это можно, но видимо поленились.
Здравствуйте, Cyberax, Вы писали:
C>Да, это один из древнейших баянов. Я где-то видел матчер регэкспов с компиляцией в SSE-код. Рвал на куски ВСЁ.
непонятно только одно: почему все остальные не вымерли.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
C>>Да, это один из древнейших баянов. Я где-то видел матчер регэкспов с компиляцией в SSE-код. Рвал на куски ВСЁ. S>непонятно только одно: почему все остальные не вымерли.
Так смысл-то какой? Ну будут регэкспы немного быстрее, но они являются узким местом только в сверхмалой части приложений.
Есть вот XML-парсер от того же товарища: http://parabix.costar.sfu.ca Реально рвёт все другие парсеры. Только тоже особо никого не заморачивает это, хотя XML-парсинг намного чаще bottleneck'и даёт.
Ещё помню аналогичную историю с динамической компиляцией регэкспа времён LISP'а.
09.08.2010 20:19, Aleх пишет:
> Также, не понятно, зачем используют NFA вместо DFA.
Видимо потому что большинство библиотек регекспов используются не
только для matching, но и для нахождения subgroup. Для алгоритма
backtracking (обход в глубину) это реализуется в лоб, но попадаем на
экспоненциальное время разбора в худших случаях (насколько часты такие
случаи кстати).
Submatching можно реализовать на NFA также с помошью обхода в ширину
(линейное время в худшем случае, если считать количество состояний
константой), но это уже не реализуется в лоб.
Submatching можно реализовать и на DFA только тут уже надо прилагать
особые усилия при преобразовании автомата (чтоб не потерять привязку к
группам).
ЗЫ Как мне кажется, неплохо было бы иметь супер быструю библиотеку
только для match, что-то посложнее для submatching без backreference и
прочих расширений, и perl-монстра со всеми расширениями и прочим. В
гугловом RE2 вроде даже по этому пути и пошли (распознают тип регекспа и
используют разные реализации автомата).
Здравствуйте, ettcat, Вы писали:
E> Видимо потому что большинство библиотек регекспов используются не E>только для matching, но и для нахождения subgroup.
Да ничего там сложного нет. К состояниям и переходам привязываешь атрибуты и сохраняешь их при слияниях и минимизации автмоматов. Мы на работе такое написали за пару недель.

 Перекуём баги на фичи!
Перекуём баги на фичи!