Здесь инфа по алгоритму SIFT для нахождения объекта на картинке.
Вкратце алгоритм состоит из следующих этапов:
1. Извлекаются Feature Points (наборы точек на изображении).
Насколько я понимаю, вначале по исходному изображению объекта получается многоуровневое изображение объекта
каждый уровень получается путем размытия исходного изображения с помощью Гауссова шума. Затем для n уровней строится n-1 разностных изображений, каждое для двух смежных уровней. Затем среди этих разностных изображений ищутся нужные нам контрольные точки как максимум или минимум среди своих 26 соседей. По 1 пункту такие вопросы:
— Как производится Гауссово размытие картинки для каждого уровня? Используется формула ил накладывается маска [I x I] , где I это номер уровня? Как будет правильней?
— Ищутся ли контрольные точки в крайних (1 и n-1) разностных изображениях?
2. Для каждой строится дескриптор SIFT.
Для контрольной точки в том разностном изображении, где она найдена ищутся градиенты.
Затем по градиентам вычисляется локальный десктриптор точки.Чем больше область мы берем вокруг точки, тем больше вычислений и тем больше шансов получить хороший дескриптор (насколько я понимаю дескриптор предназначен для того, чтобы унифицировать контрольную точку) По 2 пункту такие вопросы:
— Градиенты задаются двумя параметрами: magnitude & orientation, как они вычисляются -- не совсем понятно.
— Какой физичечкий смысл этих двух параметров?
— Как строится дескриптор вроде понятно. Изменяется ли он впоследствии? То есть хранятся все 128 направлений или в каждом секторе выбирается доминирующее?
3. Набор точек одного изображения и второго сравнивается с учетом Геометрии.
Здесь пока совсем непонятно. Поразбираюсь еще, вопросы скорее всего появятся.
Главное, что непонятно это как сравниваются дескрипторы для контрольных точек.
Если я что-то неправильно или некорректно изложил -- поправьте пожалуйста.
Заранее благодарен за помощь.
Здравствуйте, tinytjan, Вы писали:
T>Здесь инфа по алгоритму SIFT для нахождения объекта на картинке. T>Вкратце алгоритм состоит из следующих этапов:
T>1. Извлекаются Feature Points (наборы точек на изображении).
T>Насколько я понимаю, вначале по исходному изображению объекта получается многоуровневое изображение объекта T>каждый уровень получается путем размытия исходного изображения с помощью Гауссова шума.
Поправка: фильтра (соотв. маской свертки)
T>Затем для n уровней строится n-1 разностных изображений, каждое для двух смежных уровней. Затем среди этих разностных изображений ищутся нужные нам контрольные точки как максимум или минимум среди своих 26 соседей. T>По 1 пункту такие вопросы: T> — Как производится Гауссово размытие картинки для каждого уровня? Используется формула ил накладывается маска [I x I] , где I это номер уровня? Как будет правильней?
Скорее всего имеется фиксированная маска свертки (с дисперсией допустим 2.0), которая применяется итеративно, то есть: берем картинку, делаем свертку — получаем 2 уровень (1 — само изображение), выкидываем каждый второй отсчет, редуцируем изображение (следствие из теоремы котельникова), повторяем процесс с той же маской, получаем еще один уровень и так пока не надоест до квадрата с постоянной магнитудой цвета равной матожиданию в этой картинке (кажись). На каждом этаме свертки мы теряем высокие частоты, так как фильтр гаусса — низкочастотный, следовательно — каждый раз мы упрощаем картинку, оставляя наиболее значимые низкочастотные компоненты.
T> — Ищутся ли контрольные точки в крайних (1 и n-1) разностных изображениях?
ты всегда можешь добавить с обоих сторон изображения идентичные краям (банально повторить), если это вдруг понадобится, может несколько упростить алгоритм.
T>2. Для каждой строится дескриптор SIFT.
T> Для контрольной точки в том разностном изображении, где она найдена ищутся градиенты. T> Затем по градиентам вычисляется локальный десктриптор точки.Чем больше область мы берем вокруг точки, тем больше вычислений и тем больше шансов получить хороший дескриптор (насколько я понимаю дескриптор предназначен для того, чтобы унифицировать контрольную точку) T>По 2 пункту такие вопросы: T> — Градиенты задаются двумя параметрами: magnitude & orientation, как они вычисляются -- не совсем понятно.
Градиент это вектор, в данном случае, _вектор_ найбольшей скорости возрастания яркости, обычно раскладывается на компоненты по оси x и y изображения, по которым производные считаются. Магнитуда вектора корень из суммы квадратов его координат (ну или модуль). Для цветного наверное там делается для каждого канала в отдельности.
T> — Какой физичечкий смысл этих двух параметров? T> — Как строится дескриптор вроде понятно. Изменяется ли он впоследствии? То есть хранятся все 128 направлений или в каждом секторе выбирается доминирующее?
T>3. Набор точек одного изображения и второго сравнивается с учетом Геометрии.
T>Здесь пока совсем непонятно. Поразбираюсь еще, вопросы скорее всего появятся. T>Главное, что непонятно это как сравниваются дескрипторы для контрольных точек.
T>Если я что-то неправильно или некорректно изложил -- поправьте пожалуйста. T>Заранее благодарен за помощь.
На вопросы 1. и 2. Trean ответил.
Физический смысл magnitude & orientation понятен из их названия,- модуль и направление градиента. Хранятся все 128 значений. Дескриптор представляет собой трехмерную гистограмму с прямоугольной сеткой по окну просмотра и дискретизацией направления градиента до 8 направлений.
Что касается пункта 3. На данном этапе требуется сравнить дескрипторы точек интереса для разных изображений. Возможны 3 основных подхода: 1) Считать дескрипторы совпадающими, если расстояние между ними меньше поргового. 2) Сначала находить ближайший дескриптор на втором изображении и считать его совпадающим, если расстояние между дескрипторами меньше порогового 3)Сравнивать соотношение между первым и вторым ближайшим соседом на втором изображении. В алгоритме Lowe используется( если я не ошибаюсь) второй подход. Для дальнейшего избавления от ложных совпадений проверяется все ли сопоставленные точки интереса соответствуют единому афинному преобразованию одного изображения в другое.
Здравствуйте, Lafkadio, Вы писали:
L>На вопросы 1. и 2. Trean ответил. L>Физический смысл magnitude & orientation понятен из их названия,- модуль и направление градиента. Хранятся все 128 значений. Дескриптор представляет собой трехмерную гистограмму с прямоугольной сеткой по окну просмотра и дискретизацией направления градиента до 8 направлений.
Мне интересно откуда берется инвариантность к повороту. Разве при изменении угла поворота камеры или угла поворота самого изображения дескрипторы не будут изменяться(ориентация градиентов)?
По первому, второму пункту.
Насколько я понял с Гауссовым фильтром можно делать что угодно делать.
А от этого 'что угодно' зависит качество и количество контрольных точек, правильно?
Lafkadio, Вы писали:
L>Что касается пункта 3. На данном этапе требуется сравнить дескрипторы точек интереса для разных изображений. Возможны 3 основных подхода: 1) Считать дескрипторы совпадающими, если расстояние между ними меньше поргового. 2) Сначала находить ближайший дескриптор на втором изображении и считать его совпадающим, если расстояние между дескрипторами меньше порогового 3)Сравнивать соотношение между первым и вторым ближайшим соседом на втором изображении. В алгоритме Lowe используется( если я не ошибаюсь) второй подход. Для дальнейшего избавления от ложных совпадений проверяется все ли сопоставленные точки интереса соответствуют единому афинному преобразованию одного изображения в другое.
Вот здесь непонятки остаются.
Локальные дескипторы ИЗНАЧАЛЬНО инвариантны к преобразованиям что ли?
Иначе просто нельзя сравнивать их по критерию обычного евклидового расстояния.
Существуют ли другие способы создания дескриптора, основанные не на градиентах наибольшего изменения цвета?
Здравствуйте, SunSonnet, Вы писали: SS>Мне интересно откуда берется инвариантность к повороту. Разве при изменении угла поворота камеры или угла поворота самого изображения дескрипторы не будут изменяться(ориентация градиентов)?
Вы правы, ориентация градиентов изменяется при повороте. В связи с этим для достижения инвариантности к повороту, для выбранной точки интереса считается доминирующее направление градиента, и все последующие вычисления локальных градиентов считаются уже относительно доминирующего направления. Цитирую Lowe: "Each key location is assigned a canonical orientation so that the image descriptors are invariant to rotation".
Здравствуйте, tinytjan, Вы писали:
T>Прежде всего всем спасибо за ответы.
T>Насколько я понял с Гауссовым фильтром можно делать что угодно делать. T>А от этого 'что угодно' зависит качество и количество контрольных точек, правильно?
Не понимаю вопроса. Фильтр Гаусса используется для сглаживания изображения, параметр(sigma) влияет на размер области усреднения(Правило 3-х сигм для нормального распределения). При использовании разности двух сглаженных изображенний с различными сигмами(DoG) или при последующем применении фильтра Лапласа(LoG) можно выделить перепады яркости.
T>Вот здесь непонятки остаются. T>Локальные дескипторы ИЗНАЧАЛЬНО инвариантны к преобразованиям что ли? T>Иначе просто нельзя сравнивать их по критерию обычного евклидового расстояния. T>Существуют ли другие способы создания дескриптора, основанные не на градиентах наибольшего изменения цвета?
Локальные дескрипторы инвариантны не изначально. Для достижения инвариантности к масштабированию на этапе полученя регионов для вычисления дескриптора, регион вычисляется нормализованным по масштабу. Для достижения инвариантности к повороту, ориентация градиентов ситается относительно доминирующего направления градиента. Для достижения инвариантности к изменениям освещенности производится нормализация модуля градиента при вычисление дескриптора.
Да, существует большое число других способов формирования дескрипторов(не меньше 10, от вычисления моментов различного порядка для изображения, до результатов свертки с различными фильтрами), но пока проведенные исследования показывают большое превосходствео дескриптора SIFT и его различных модификаций над всеми остальными дескрипторами.
L>Да, существует большое число других способов формирования дескрипторов(не меньше 10, от вычисления моментов различного порядка для изображения, до результатов свертки с различными фильтрами), но пока проведенные исследования показывают большое превосходствео дескриптора SIFT и его различных модификаций над всеми остальными дескрипторами.
Точнее сказать из пуплично известных , мы же не говорим про дескрипторы которые использует БУЖУ ? или REALVIS или еще куча ОЧЕНЬ дорогого картографического софта. Еще раз повторюсь у меня есть знакомые которые добились лучших результатов даже раньше чем Давид.
Но из публично известных и задокументированных лучше разве что PCASIFT и т.д.
Здравствуйте, minorlogic, Вы писали:
M>Точнее сказать из пуплично известных , мы же не говорим про дескрипторы которые использует БУЖУ ? или REALVIS или еще куча ОЧЕНЬ дорогого картографического софта. Еще раз повторюсь у меня есть знакомые которые добились лучших результатов даже раньше чем Давид.
1. Конечно, я беру лишь публично известные. А что такое БУЖУ?.
2. Если у Ваших знакомых есть печатные работы на эту тему, был бы очень интересно на них взглянуть.
M>Но из публично известных и задокументированных лучше разве что PCASIFT и т.д.
Последняя модификация,- GLOH, где вместо прямоугольной сетки, для формирования дескриптора используется полярная логарифмическая сетка, и вроде бы он еще немного обгоняет и PCA-SIFT и сам SIFT.
Здравствуйте, Lafkadio, Вы писали:
L>Здравствуйте, tinytjan, Вы писали:
T>>Насколько я понял с Гауссовым фильтром можно делать что угодно делать. T>>А от этого 'что угодно' зависит качество и количество контрольных точек, правильно? L>Не понимаю вопроса. Фильтр Гаусса используется для сглаживания изображения, параметр(sigma) влияет на размер области усреднения(Правило 3-х сигм для нормального распределения). При использовании разности двух сглаженных изображенний с различными сигмами(DoG) или при последующем применении фильтра Лапласа(LoG) можно выделить перепады яркости.
Я просто имел в виду то, что при различной сигме после применения фильтра могут получаться различные контрольные точки (они ведь считаются как локальные максимумы и минимумы на разностных изображениях, или я опять что-то напутал?) То есть от выбора сигмы зависит в конечном итоге набор контрольных точек, которые мы получаем.
Да, фильтр Лапласа, если я не ошибаюсь, вторая производная по яркости.
L=a[n-1]+a[n+1]-2*a[n] (или все-таки ошибаюсь?)
Если не ошибаюсь, то какой фильтр(простая разность соседних пикселов или фильтр Лапласа) лучше использовать?
Здравствуйте, Trean, Вы писали:
T>Скорее всего имеется фиксированная маска свертки (с дисперсией допустим 2.0), которая применяется итеративно, то есть: берем картинку, делаем свертку — получаем 2 уровень (1 — само изображение)
С этим я разобрался. Имеется начальная маска (т.е. начальное значение параметра сигма= а ).
Размытием получаем первый уровень.
Второй уровень получается размытием не первого уровня, а начальной картинки, с дисперсией равной k*a, где k принимает значение от 1 до 2^0.5.
Соответственно третий k*k*a и так далее.
T>, выкидываем каждый второй отсчет, редуцируем изображение (следствие из теоремы котельникова),
Что это значит? уменьшаем размер изображения или как, что-то я не догоняю.
T>>2. Для каждой строится дескриптор SIFT. T>> Для контрольной точки в том разностном изображении, где она найдена ищутся градиенты.
Я наверное ошибся, дескрипторы строятся на оригинальном изображении. Подвергается ли изображение модификации или мы работаем с оригиналом?
T>Градиент это вектор, в данном случае, _вектор_ найбольшей скорости возрастания яркости, обычно раскладывается на компоненты по оси x и y изображения, по которым производные считаются. Магнитуда вектора корень из суммы квадратов его координат (ну или модуль). Для цветного наверное там делается для каждого канала в отдельности.
Где используется градиент? При фильтрации точек, при построении дескриптора или и там и там?
Здравствуйте, tinytjan, Вы писали:
T>Здравствуйте, Trean, Вы писали:
T>>Скорее всего имеется фиксированная маска свертки (с дисперсией допустим 2.0), которая применяется итеративно, то есть: берем картинку, делаем свертку — получаем 2 уровень (1 — само изображение)
T>С этим я разобрался. Имеется начальная маска (т.е. начальное значение параметра сигма= а ). T>Размытием получаем первый уровень. T>Второй уровень получается размытием не первого уровня, а начальной картинки, с дисперсией равной k*a, где k принимает значение от 1 до 2^0.5. T>Соответственно третий k*k*a и так далее.
Ну если k!=2 то можно и так, иначе маску можно и не менять.
T>>, выкидываем каждый второй отсчет, редуцируем изображение (следствие из теоремы котельникова),
T>Что это значит? уменьшаем размер изображения или как, что-то я не догоняю.
Типа того, просто когда ты размываешь изображение, у тебя избыточность данных получается, например с sigma=2.0 можно спокойно каждый второй отсчет отбрасывать — алиасинга не будет. При меньшем значении сигмы, надо быть осторожнее, все зависит от того какая максимальная частота на изображении (есть ли резкие переходы). Для чего это нужно? — для скорости, уменьшение размерности задачи.
T>>>2. Для каждой строится дескриптор SIFT. T>>> Для контрольной точки в том разностном изображении, где она найдена ищутся градиенты.
T>Я наверное ошибся, дескрипторы строятся на оригинальном изображении. Подвергается ли изображение модификации или мы работаем с оригиналом?
Я статью посмотрел только краем глаза, дескрипторы я уверен вычисляются для разных масштабов (детализации) изображения, чтобы получить робастный результат, для этого (получения разной детализации) я так понял гауссовая фильтрация и применяется.
T>>Градиент это вектор, в данном случае, _вектор_ найбольшей скорости возрастания яркости, обычно раскладывается на компоненты по оси x и y изображения, по которым производные считаются. Магнитуда вектора корень из суммы квадратов его координат (ну или модуль). Для цветного наверное там делается для каждого канала в отдельности.
T>Где используется градиент? При фильтрации точек, при построении дескриптора или и там и там?
При вычислении дескрипторов, так как градиент в данном случае это local feature, т.е. некоторая особенность в локальной области изображения. Для каждой точки изображения ты получаешь дескриптор или набор дескрипторов, я уж тонкостей не знаю.
Здравствуйте, Trean, Вы писали:
T>Типа того, просто когда ты размываешь изображение, у тебя избыточность данных получается, например с sigma=2.0 можно спокойно каждый второй отсчет отбрасывать — алиасинга не будет. При меньшем значении сигмы, надо быть осторожнее, все зависит от того какая максимальная частота на изображении (есть ли резкие переходы). Для чего это нужно? — для скорости, уменьшение размерности задачи.
Я думал, это применяется для получения следующей октавы изображений.
Кстати, что такое октава, и каким образом из текущей октавы мы получаем следующую?
Насколько я понял следующий уровень получается уменьшением изображения путем убирания избыточных данных. Но из каких картинок получается чледующая октава? Если из картинок текущей, то почему при переходе в следующую октаву, кроме уменьшения размеров в 2 раза, также увеличивается радиус тоже в 2 раза? Или уменьшается, вот это непонятно.
Еще непонятен такой момент. Как я написал ранее дескрипторыы для контрольных точек ищутся на оригинальном изображении. Дескрипторы ищутся в той октаве, где была найдена точка или для оригинального изоббражения?
И еще контрольные точки ищутся во всех октавах или нет?
T>При вычислении дескрипторов, так как градиент в данном случае это local feature, т.е. некоторая особенность в локальной области изображения. Для каждой точки изображения ты получаешь дескриптор или набор дескрипторов, я уж тонкостей не знаю.
Тогда по какому принципу происходит начальное отсеивание контрольных точек по порогу перед построением дескрипторов?
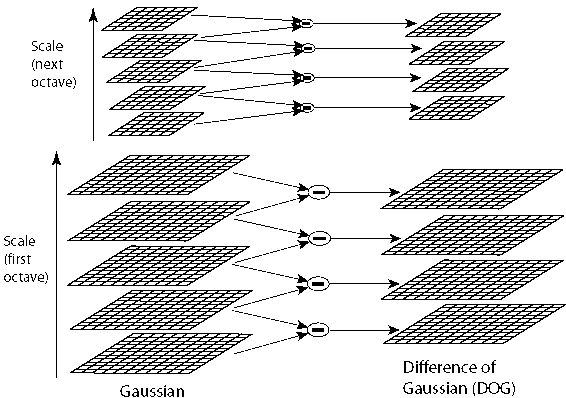
Это картинка описывает принцип построения пирамиды.
Первая октава (внизу слева) получается путем наложения Гауссова фильтра.
Из нее мы получаем Гауссову разницу(внизу справа) которая получается как разница между двумя смежными уровнями первой октавы (причем здесь фильтр Лапласа ?)
Затем получаем вторую октаву. Получается она из размытых картинок первой октавы(каким образом ?)
Из нее мы получаем Гауссову разницу(вверху справа) которая получается как разница между двумя смежными уровнями второй октавы (причем здесь фильтр Лапласа ?)
И так далее.
Чем больше октав, тем больше контрольных точек мы найдем. (Или они используются не для этого ?)
Здравствуйте, tinytjan, Вы писали:
T>Здравствуйте, Trean, Вы писали:
T>>Типа того, просто когда ты размываешь изображение, у тебя избыточность данных получается, например с sigma=2.0 можно спокойно каждый второй отсчет отбрасывать — алиасинга не будет. При меньшем значении сигмы, надо быть осторожнее, все зависит от того какая максимальная частота на изображении (есть ли резкие переходы). Для чего это нужно? — для скорости, уменьшение размерности задачи.
T>Я думал, это применяется для получения следующей октавы изображений. T>Кстати, что такое октава, и каким образом из текущей октавы мы получаем следующую?
Разумеется. Октава это расстояние в сигмах между двумя гауссовыми изображениями :
p.7.: We choose to divide each octave of scale space (i.e., doubling of sigma)
в данном случае sigma_factor=2.0. Причем первое изображение более высокой октавы меньше в 2 раза первого изображения предыдущей. Каждая октава разбивается на группу изображений L. Допустим есть исходное изображение I, ты делаешь свертку I*G с sigma=1.0 и уменьшаешь в два раза получаешь первое изображение из первой октавы, затем домножаешь sigma на k опять делаешь свертку с I*G и уменьшаешь в два раза, получаешь второе изображение из октавы и тд, кол-во уровней в октаве определяется так :
We choose to divide each octave
of scale space (i.e., doubling of sigma) into an integer number, s, of intervals, so k = 2^1/s:
We must produce s + 3 images in the stack of blurred images for each octave, so that final
extrema detection covers a complete octave.
Но либо я торможу либо они какую-то фигню написали, но я лично не понял почему k = 2^1/s а не k = 2/s и почему s + 3.
T>Насколько я понял следующий уровень получается уменьшением изображения путем убирания избыточных данных. Но из каких картинок получается чледующая октава? Если из картинок текущей, то почему при переходе в следующую октаву, кроме уменьшения размеров в 2 раза, также увеличивается радиус тоже в 2 раза? Или уменьшается, вот это непонятно.
либо sigma увеличивается в 2 раза при переходе на новую октаву и производится свертка с исходным изображением, либо сигма остается фиксированной = 1.0 и свертку ты делаешь с первым уровнем из предыдущей октавы. Свертка операция линейная — две последовательные свертки с sigma=1.0 равны по результату свертке с sigma=2.0 У тебя ж код есть можешь сам проверить. Именно поэтому мне и не понятно почему они k так хитро считают.
Дальше пока не разбирался. У тебя сорсы в каком-нить виде есть этого SIFT'a?
T>Еще непонятен такой момент. Как я написал ранее дескрипторыы для контрольных точек ищутся на оригинальном изображении. Дескрипторы ищутся в той октаве, где была найдена точка или для оригинального изоббражения?
T>И еще контрольные точки ищутся во всех октавах или нет?
T>>При вычислении дескрипторов, так как градиент в данном случае это local feature, т.е. некоторая особенность в локальной области изображения. Для каждой точки изображения ты получаешь дескриптор или набор дескрипторов, я уж тонкостей не знаю.
T>Тогда по какому принципу происходит начальное отсеивание контрольных точек по порогу перед построением дескрипторов?
Здравствуйте, tinytjan, Вы писали:
T>>Здравствуйте, Trean,
T>Маленькое дополнение:
T> T>Это картинка описывает принцип построения пирамиды. T>Первая октава (внизу слева) получается путем наложения Гауссова фильтра. T>Из нее мы получаем Гауссову разницу(внизу справа) которая получается как разница между двумя смежными уровнями первой октавы (причем здесь фильтр Лапласа ?)
фильтр Лапласа, он же LoG он же G*[-1 0 1] или G*[-1 1], он же аппроксимация первой производной функции Гаусса. Но так как у них еще и sigma переменная между двумя соседними уровнями, и производная считается достаточно сложно, они аппрокимируют sigma^2*nabla^2G используя DoG (difference-of-Gaussian)
T>Затем получаем вторую октаву. Получается она из размытых картинок первой октавы(каким образом ?)
Смотри пред. пост
T>Из нее мы получаем Гауссову разницу(вверху справа) которая получается как разница между двумя смежными уровнями второй октавы (причем здесь фильтр Лапласа ?)
см выше.
T>И так далее. T>Чем больше октав, тем больше контрольных точек мы найдем. (Или они используются не для этого ?)
В принципе уже что-то получается. Возник такой вопрос.
Если на изображении располагается много однотипных объектов (окна многоэтажгого дома), то задав одно из них в качестве шаблона для поиска, метод находит на изображении его (т.е. оригинал). Какие параметры необходимо покрутить чтобы метод находил все похожие объекты (все одинаковые окна).
Здравствуйте, SunSonnet, Вы писали:
SS>Если на изображении располагается много однотипных объектов (окна многоэтажгого дома), то задав одно из них в качестве шаблона для поиска, метод находит на изображении его (т.е. оригинал). Какие параметры необходимо покрутить чтобы метод находил все похожие объекты (все одинаковые окна).
В качестве исходных данных, у вас есть множество дескрипторов исходного изображения и множество дескрипторов эталона. Простейшим способом решения данной задачи является следующий подход:
После того как вы получили первое сопоставление, удалить из множества дескрипторов исходного изображения сопоставленные дескрипторы, после чего повторить процедуру сопоставления. И так до тех пор пока будут находиться новые сопоставления. Реализация простая, но затраты по времени достаточно велики, так как процедура поиска сопоставления дескрипторов будет вызвана n+1 раз , где n — число вхождений эталона в исходное изображение.
Для сокращения времени можно попытаться реализовать следующую схему работы. Lowe в своей статье ориентируется на nearest neighbor matching, то есть дескрипторы считаются совпадающими, если они являются ближайшими соседями по расстоянию между ними и при этом растояние между ними меньше порогового. Можно модифицировать эту схему: Для каждого дексриптора исходного изображения сопоставленного с помощью nearest neighbor matching(D_NNM), хранить список дескрипторов, расстояние с которыми для него меньше порогового D_Thrsh[i],i=1...K.
Итак если мы в ходе nearest neighbor matching получили M дескриторов то у нас появляется список D_NNM[i], i=1...M, и для каждого D_NNM[i], ассоциированный с ним список D_Thrsh[j],j=1...Ki.
После проведения RANSAC пo результатам nearest neighbor matching(D_NNM), Вы получите сопоставленные модели одного из вхождений эталона в исходном изображении и самого эталона, но при этом с каждым из сопоставленных дескрипторов исходного изображения у Вас будет проассоциирован список дескрипторов, которые близки к нему по расстоянию(D_Thrsh[j], j=1..Ki). Таким образом если у вас будет 5 вхождений эталона, то в каждом списке будет не менее 5 дескрипторов.
Поскольку они соответствуют одному эталону, то афинное преобразование точки интереса D_NNM[i] к точке интереса D_Thrsh[i][j] будет одинаково, для всех сопоставленных дескрипторов принадлежащих одной модели эталона. Следовательно процедура работы имеет следующий вид:
1.Считаем афинное преобразование точки интереса D_NNM[1] к D_Thrsh[1][1] для первого сопоставленного дескриптора на исходном изображении2.Для каждого из следующих сопоставленных дескрипторов D_NNM[i1] на исходном изображении ищем D_Thrsh[i1][j1] из ассоциированного с ним списка, с такими же параметрами преобразования точки интереса D_NNM[i1] к D_Thrsh[i1][j1] как и D_NNM[1] к D_Thrsh[1][1].3.Повторяем те же действия для каждого из K1 дескрипторов D_Thrsh[1][j] из асоциировнного списка к первому дескритору.
В данную процедуру должны быть внесены небольшие усложнения для учета того факта, что в списках D_Thrsh[i][j] могут появиться дескрипторы не соответсвующие вхождениям эталона в исходное изображение. Но они могут быть отсеяны на основании того факта, что для них просто не будут найдены совпадающие коэффициенты афииных преобразований.