GLM или Minimax M2 для написания кода не юзаете ? (говорят локальные модельки крупные почти не хуже топовых облачных)
Чаще использую Qwen3, MiniMax M2, GLM для кода, ну и практически все открытые модели Gemma, gpt-oss, deepseek, … для документов, текста и всякого поиска информации. Облачные мне не интересны — например у Claude подписка слишком дорогая, хотя модели и хорошие, я легко могу за день несколько сотен тысяч токенов нагенерить
Qwen3-Next если нужно длинный контекст и побыстрее, MiniMax M2, GLM, Qwen3-235B если нужно поумней или планирование, тут скорость до 22-25t/s снижается.
qwen3next 80B.A3B Q8_0 (78.98 GiB)
StrixHalo пока что больше как "игрушка", так у меня в основном 4 mi60 в сервере трудятся
>по сравнению с лидерами типа тех же ChatGPT и Claude.
Если для программирования, то GLM и MiniMax M2 отстают в целом незначительно. Если 200+ баксов в месяц на подписку не жалко и на "утечку" кода наплевать — то подписка вполне себе вариант.
vLLM умеет tensor parallelism — это на 4 картах даёт 2+ раза ускорение.
StrixHalo 128 GB медленнее в 1.5-2 раза, а так весьма неплохо, особенно учитывая 150вт против 1квт , ну и тише намного.
так что когда новое (мини-ПК) оборудование на 256 ГБ ОЗУ (а тем более на DDR6, хотя вроде Mac Studio (2025) и так 819 ГБ/с Bandwidth имеет против 256 GB/s Strix Halo) выйдет, то сервачки видимо отправятся почивать .. "недолго осталось" (c)
Здравствуйте, xma, Вы писали:
xma>GLM или Minimax M2 для написания кода не юзаете ? (говорят локальные модельки крупные почти не хуже топовых облачных)
А через какие agentic инструменты(Claude Code, Copilot, etc) эти "говорят" с ними работают? Это сейчас не менее важно чем качество LLM.
Re: GLM или MiniMax M2 для написания кода не юзаете? (локальные)
Здравствуйте, xma, Вы писали:
xma>AMD Radeon Instinct MI60 32GB HBM2 x4 = 128 GB (память отдельных ускорителей при инференсе суммируется, но не скорость ЕМНИП), 215 тыр за всё
Ну это немало же и не факт, что всё будет безгеморно работать.
Мне вот интересно- в свете что копилот клод имеет свойство быстро проедать токены, а скажем, кап 25usd в день это же 550usd в мес в худшем сценарии- имеет ли право на жизнь рент серверов у олламы по 200usd в мес, 5 и6стансов. Хз правда, шо там за инстансы т.е. сравнима ли мощь и vram с copilot-м железом.
Re[2]: GLM или MiniMax M2 для написания кода не юзаете? (локальные)
Здравствуйте, novitk, Вы писали:
N>А через какие agentic инструменты(Claude Code, Copilot, etc) эти "говорят" с ними работают?
да чё я, вопросы буду туда сюда таскать что ле зарегайся на хоботе да сам спроси, а потом нам расскажешь ..
Re[2]: GLM или MiniMax M2 для написания кода не юзаете? (локальные)
Здравствуйте, novitk, Вы писали: xma>GLM или Minimax M2 для написания кода не юзаете ? (говорят локальные модельки крупные почти не хуже топовых облачных)
Чтобы их локально юзать нужно железо на $10k. Очень хочется, но колется. N>А через какие agentic инструменты(Claude Code, Copilot, etc) эти "говорят" с ними работают? Это сейчас не менее важно чем качество LLM.
Claude Code CLI умеет в сторонние модели и при этом имеет (вроде как) самое полное покрытие MCP протокола. По крайней мере, такая важная фича как Elicitation в нем реализована, что позволяет human-in-the-loop.
Copilot я уже год не щупал. Он уже умеет полноценно мультиагентные задачи? До Claudex никак руки не доберутся.
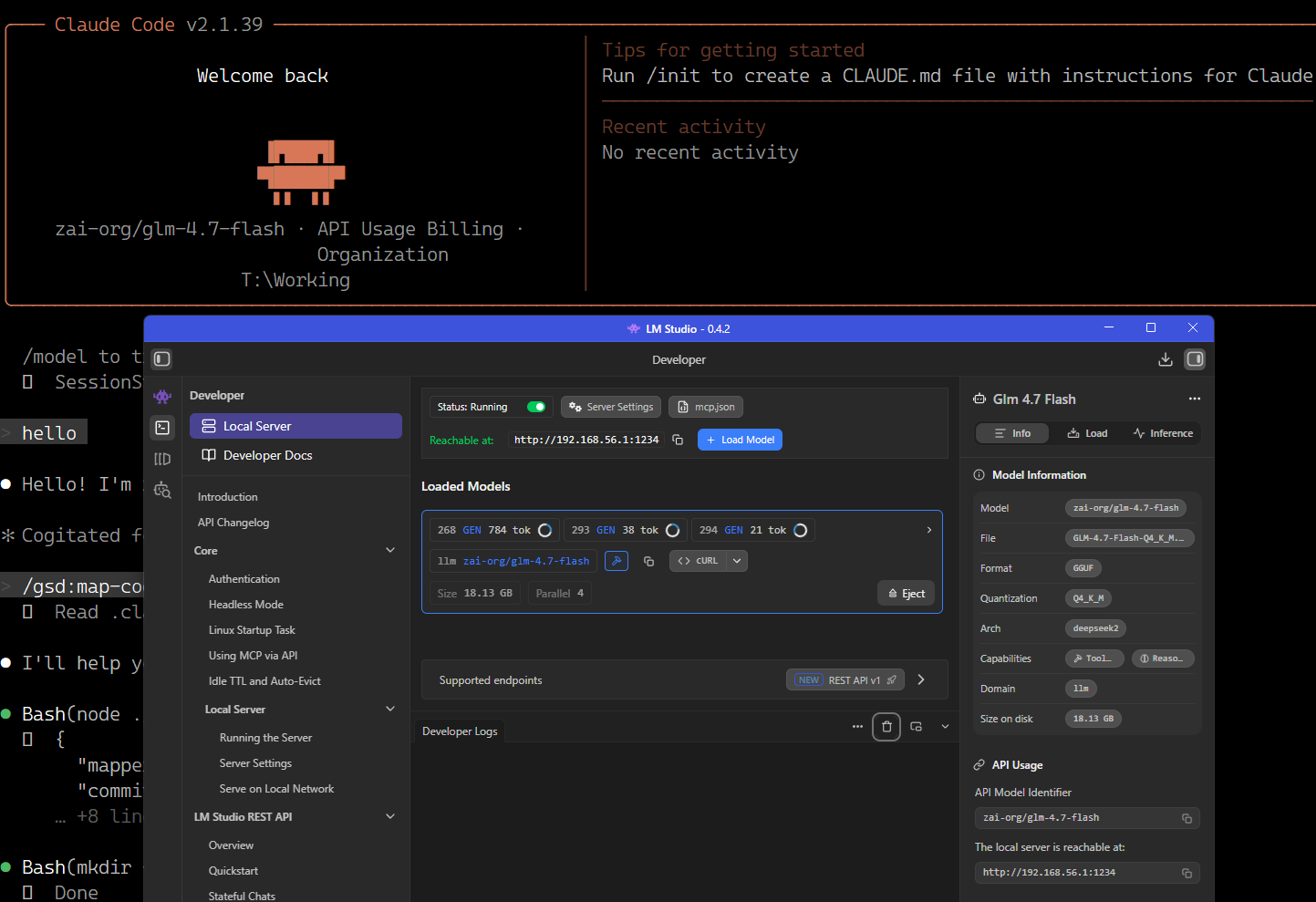
LMstudio использую для базовых моделей:
* gpt-oss-20b/mxfp4, qwen3-coder-30b/q5_k_m, glm-4.7-flash/q4_k_m влазят целиком и дают нормальную скорость
* qwen-coder-next/q4_k_m влазит частично — скорость генерации унылая и с ростом контекста стремительно падает
Но то что влазит в мои 32Гб+96Гб далековато от качества Клавдии. Локальные модели больше галлюцинируют, иногда впадают в циклы или рекурсии, иногда сильно уходят из контекста. Вывод модели приходится либо прогонять еще раз через верификатор, либо самому отслеживать (например, для относительного пути assets/templates/blabla.md вчера много где генерило `ssets/templates/blabla.md).
Вчера qwen-image-2512/df11 попробовал стандартным питоновским скриптом. Инициализация порядка 3 минут через RAM+SSD/swap и потом 3 минуты на картинку 1664х928 (50 итераций диффузора) уже на карте. Для разовых работ нормально, но для потока однозначно нужна карта побольше. Впрочем, для небольшой студии можно было бы развернуть в виде MCP сервера, чтоб не прогружать модель на каждый вызов или батч прикрутить.
Привет от ИИ. Пережал PNG 1.5Mb в JPEG
... --prompt "Little cute smiling animation girl in the white dress with shining blue RSDN label on the dress top looking upfront. Girl keeping coffee cup in the right hand. With the left hand shows greetings."
newbie
Re[3]: GLM или MiniMax M2 для написания кода не юзаете? (локальные)
Здравствуйте, pva, Вы писали:
N>>А через какие agentic инструменты(Claude Code, Copilot, etc) эти "говорят" с ними работают? Это сейчас не менее важно чем качество LLM. pva>Claude Code CLI умеет в сторонние модели и при этом имеет (вроде как) самое полное покрытие MCP протокола. По крайней мере, такая важная фича как Elicitation в нем реализована, что позволяет human-in-the-loop.
Они все умеют, но я просто не в курсе насколько просто подключиться к локальной LLM не из списка и не придется ли в этом случае все равно платить.
pva>Copilot я уже год не щупал. Он уже умеет полноценно мультиагентные задачи?
Гугл говорит что да, но я не пользовался.
Re[3]: GLM или MiniMax M2 для написания кода не юзаете? (локальные)
Здравствуйте, xma, Вы писали:
N>>А через какие agentic инструменты(Claude Code, Copilot, etc) эти "говорят" с ними работают? xma>да чё я, вопросы буду туда сюда таскать что ле зарегайся на хоботе да сам спроси, а потом нам расскажешь ..
Лень. Глянув на дискуссию, там обсуждают исключительно железо для запуска локальных моделей.
Re[4]: GLM или MiniMax M2 для написания кода не юзаете? (лок
Здравствуйте, novitk, Вы писали:
N>Лень. Глянув на дискуссию, там обсуждают исключительно железо для запуска локальных моделей.
там всё обсуждают чай язык не отсохнет спросить при необходимости ..
Здравствуйте, novitk, Вы писали: pva>>Claude Code CLI умеет в сторонние модели и при этом имеет (вроде как) самое полное покрытие MCP протокола. По крайней мере, такая важная фича как Elicitation в нем реализована, что позволяет human-in-the-loop. N>Они все умеют, но я просто не в курсе насколько просто подключиться к локальной LLM не из списка и не придется ли в этом случае все равно платить.
Не, не все. То что какая-то модель умеет в Tools, не значит что она умеет в них нормально. А любые ошибки в формировании запроса и начинается галиматья.
@echo off
set ANTHROPIC_AUTH_TOKEN=ollama
set ANTHROPIC_BASE_URL=http://localhost:12345
claude --model zai-org/glm-4.7-flash
Платить при этом не нужно. Оно просто выступает клиентом.
newbie
Re[5]: GLM или MiniMax M2 для написания кода не юзаете? (локальные)
Здравствуйте, pva, Вы писали:
pva>>>Claude Code CLI умеет в сторонние модели и при этом имеет (вроде как) самое полное покрытие MCP протокола. По крайней мере, такая важная фича как Elicitation в нем реализована, что позволяет human-in-the-loop. N>>Они все умеют, но я просто не в курсе насколько просто подключиться к локальной LLM не из списка и не придется ли в этом случае все равно платить. pva>Не, не все.
Сорян, я под "все" понимал, что во всех есть переключалка, включающая не только родные модели, а не именно возможность подключить что-то свое.
pva>То что какая-то модель умеет в Tools, не значит что она умеет в них нормально. А любые ошибки в формировании запроса и начинается галиматья.
Примерно так и думал, то есть весь стэк нормально работать не будет, а значит для кодинга смысла нет заморачиваться даже если железо есть. Спасибо.
Re[5]: GLM или MiniMax M2 для написания кода не юзаете? (лок
Здравствуйте, xma, Вы писали:
xma>там всё обсуждают чай язык не отсохнет спросить при необходимости ..
железячники там, прогеры тут. Вот pva тут ответил.
Re[6]: GLM или MiniMax M2 для написания кода не юзаете? (лок
Здравствуйте, novitk, Вы писали:
N>железячники там, прогеры тут. Вот pva тут ответил.
в старт посте это цитаты пользователя sip на хоботе (в той же теме), он это всё реально масштабно юзает для своих рабочих проектов (локально на своём сервере с x4 mi60), живёт кстате в San Jose (т.е. как сами понимаете не самый последний человек в ИТ индустрии, и в авангарде самых передовых технологий и достижений)
P.S.:
если вдруг кто не в курсе (он туда из Днепра переехал)
Сан-Хосе, сердце Силиконовой долины, является домом для крупнейших IT-гигантов мира, предлагающих широкие карьерные возможности.
впрочем, кому не нужно ежедневно задействовать кучу токенов (и пофиг на конфиденциальность), то подписка на Claude (или т.п.) более чем оправдана (вместо локального гиммороя)
выйдет «Medusa Halo» через пару лет и по экспериментируете (если будет интересно), ну кроме Артёмки (он от зарплаты до зарплаты живёт, "не до жиру" (c))
Re[7]: GLM или MiniMax M2 для написания кода не юзаете? (лок
Здравствуйте, xma, Вы писали:
xma>в старт посте это цитаты пользователя sip на хоботе (в той же теме), он это всё реально масштабно юзает для своих рабочих проектов (локально на своём сервере с x4 mi60), живёт кстате в San Jose (т.е. как сами понимаете не самый последний человек в ИТ индустрии, и в авангарде самых передовых технологий и достижений)
Вот мне и интересно, что подобное мотивирует. Есть предположенние, что им там не код писать надо, а интересно собрать свое решение.
xma>впрочем, кому не нужно ежедневно задействовать кучу токенов (и пофиг на конфиденциальность), то подписка на Claude (или т.п.) более чем оправдана (вместо локального гиммороя)
Для нищебродов подписка на Cоpilot стоит $100 в год и включает вполне приличные модели неограниченно, которые точно будут работать лучше чем его наколенно приклееные костыли. Иногда они не справляются да и тогда можно переключиться на SOTA от тех же Antropic, Google и OpenAI. Это будет точно бюджетней чем гонять 10К сервак дома.
Про конфиденциальность..., ну я не знаю. Если ты нищеброд в гараже, то тебе пофиг. А если нет, то у тебя есть деньги организовать любой уровень приватности.
Здравствуйте, novitk, Вы писали:
N>Это будет точно бюджетней чем гонять 10К сервак дома.
сервак в $3k ему обошёлся (за всю сборку за всё), если скорость x0.5-0.7 устраивает (относительно уровня сервака) — то можно и Strix Halo (мини-ПК) юзать (в лучшее время $1.5k стоил за 128 ГБ)
N>А если нет, то у тебя есть деньги организовать любой уровень приватности.
на Claude ? очень сомнительно ..
Re[9]: GLM или MiniMax M2 для написания кода не юзаете? (лок
Здравствуйте, xma, Вы писали:
N>>Это будет точно бюджетней чем гонять 10К сервак дома. xma>сервак в $3k ему обошёлся (за всю сборку за всё), если скорость x0.5-0.7 устраивает (относительно уровня сервака) — то можно и Strix Halo (мини-ПК) юзать (в лучшее время $1.5k стоил за 128 ГБ)
Качества нет. Инструментарий(copilot,claude code, geminiCLI,...) надо к каждой LLM адаптировать иначе выдачу он понять не может. А без инструментария жить сейчас нельзя. Почитай что в другой ветке мы с pva обсуждаем.
N>>А если нет, то у тебя есть деньги организовать любой уровень приватности. xma>на Claude ? очень сомнительно ..
Что сомнительно? У всех давно есть "enterprise tier" где прописано “no training on customer data and zero data retention”.
Здравствуйте, xma, Вы писали:
xma>сервак в $3k ему обошёлся (за всю сборку за всё), если скорость x0.5-0.7 устраивает (относительно уровня сервака)
MI60 практически нет в продаже. Даже на MI50 32Gb (4 штуки) в 3к уложиться можно с трудом. Скорее ближе к 4к. При производительности в ~2 раза ниже и потреблении 1.5+ кВт на сборку.
Впрочем, как рабочая лошадка — неплохое решение. Главное достоинство — много памяти.
newbie
Re[8]: GLM или MiniMax M2 для написания кода не юзаете? (лок
Здравствуйте, novitk, Вы писали:
N>Для нищебродов подписка на Cоpilot стоит $100 в год и включает вполне приличные модели неограниченно, которые точно будут работать лучше чем его наколенно приклееные костыли. Иногда они не справляются да и тогда можно переключиться на SOTA от тех же Antropic, Google и OpenAI. Это будет точно бюджетней чем гонять 10К сервак дома.
Это демпинг и подсаживание на иглу, далее таких цен естественно не будет. Далее будет 10X ценник чтобы хотябы электричество окупалось, и 100X чтобы стало прибыльным.
Дома можно запустить и за очень дешево даже полный DeepSeek — всего-то 1TB оперативы, даже воткнутый в двухсокет 2011-3 работает ибо 8 каналов и хоть и медленно но всеж чет надолго запустить и отойти- такой сценарий норм (увы, оператива даже тормозная DDR4 2400 скакнула тоже, но все еще не сверх дорого, никаких 10K$).
Если устраивает GLM / Qwen coder, то несколько штук 3090 чтобы видеопамяти хватало и это будет очень быстро, локально и крайне недорого. Дорого лишь запускать быстро самые большие модели, это скорее только Греф может себе домой купить для баловства с Gigachat риг на топовых Tesla, более ляма$.
P.S. Те сервисы что сейчас за копейки доступны — им просто деградируют качество ниже плинтуса (например сделав что-нибудь с контекстом — пожать, ограничить размер и т.п. То что самое дорогое обходится из железных ресурсов — порезать на сколько угодно можно.) Не будет таких халявных сервисов в будущем, работающих в полный убыток даже по электричеству!!!
Большой контекст да и еще на большой модели будет стоит в будущем скорее как электричество что потребляется, даже не учитываться будут железки используемые. Кто умеет малым контекстом обходится — засунуть самое важное, скорее сможет даже на локальных LLM показывать результат.
Здравствуйте, Артём, Вы писали:
Аё>Здравствуйте, novitk, Вы писали:
N>>подписка на Cоpilot стоит $100 в год и включает вполне приличные модели неограниченно,
Аё>claude sonnet 4.5 в копилоте ограниченное количество токенов в день и в месяц.
Там галочка есть "разрешить токены свыше тарифа" ("Premium request paid usage")
Тех которые в тарифе за $10 в месяц хватает всего на несколько дней.
Даже так все равно Клод через Копайлот сильно дешевле чем подписка Anthropic в лоб, Микрософт демпингует.
Из очевидных проблем копайлота IMHO только то, что нет поддержки "команд агентов", и контекст зарезан на 128К (вместо доступных теперь в 4.6 200K/1M).
Но в целом вполне юзабельно. И фишки перечисленные выше появились в Claude Code вот совсем недавно.
Здравствуйте, bnk, Вы писали:
bnk>Там галочка есть "разрешить токены свыше тарифа" ("Premium request paid usage")
Да, мне эту галочку выставили после просьбы удвоить лимит токенов. bnk>Тех которые в тарифе за $10 в месяц хватает всего на несколько дней.
Спасибо за поддержку, значит я за неделю высадил это ещё нормально.
Мой пойнт, что за "$100 в год всё включено" это бесполезно для изменений в промышленном коде.
bnk>Даже так все равно Клод через Копайлот сильно дешевле чем подписка Anthropic в лоб, Микрософт демпингует.
выше лимита вызов по цене API. у MS цена вызова API ниже, чем в лоб у антропика?
bnk>Из очевидных проблем копайлота IMHO только то, что нет поддержки "команд агентов", и контекст зарезан на 128К (вместо доступных теперь в 4.6 200K/1M). bnk>Но в целом вполне юзабельно. И фишки перечисленные выше появились в Claude Code вот совсем недавно.
За 1M контекст цена вызова API в 2 раза выше у антропика.
Re: GLM или MiniMax M2 для написания кода не юзаете? (локальные)
ИМХО, для более менее приличных проектов, где у одного агента начинает теряться контекст, все это не очень имеет смысл. Разве только для частных задач. Для большого проблема большее значение имеет возможность использовать несколько взаимодействующих между собой агентов, где каждый сфокусирован на своей области. Пока ничего лучше Claude с их экспериментальной фичей я ничего не видел. Я в свое время писал свою поделку, которая умеет оркестрировать несколько агентов (тоже клодовских), но дальше моей репы это не ушло, так как новый родной клодовский оказался более удобным и эффективным.
Re[2]: GLM или MiniMax M2 для написания кода не юзаете? (локальные)
Здравствуйте, MaximVK, Вы писали:
MVK>Для большого проблема большее значение имеет возможность использовать несколько взаимодействующих между собой агентов, где каждый сфокусирован на своей области. Пока ничего лучше Claude с их экспериментальной фичей я ничего не видел. Я в свое время писал свою поделку, которая умеет оркестрировать несколько агентов (тоже клодовских), но дальше моей репы это не ушло, так как новый родной клодовский оказался более удобным и эффективным.
Такая же фигня. Конструируешь, конструируешь какой-то пайплайн, а тебе бац! вторая смена. Выкатывают такую фичу в Клавдии. Ужасно геморно бегать наперегонки с компаниями.
Пока ковыряю интеграцию клавдии с бесплатными моделями, для локального инференца. Но, видимо, необходимо ждать пока устаканятся протоколы. Большинство моделей либо привязаны к своим CLI, либо слишком "тупы" для использования с MCP инструментами в том зоопарке что сейчас существует. С другой стороны, многие новые модели сильно зацензурированы.
Клавдия на днях выкатила юзер-ассистента для винды и для хрома плаг. Крупный шаг в сторону изменения пользовательского опыта взаимодействия с ПК.
newbie
Re: GLM или MiniMax M2 для написания кода не юзаете? (локаль
xma>GLM или Minimax M2 для написания кода не юзаете ? (говорят локальные модельки крупные почти не хуже топовых облачных)
народ в восторге так то (хотя на 2x RTX 6000 Pro за пару лямов чего в восторге не быть)
Да, это стоит того, чтобы об этом говорили. Я использую AWQ 4bit и fp8 kv и могу заставить Claude Code работать где-то между уровнем Sonnet 3.7 и 4, по моей оценке.