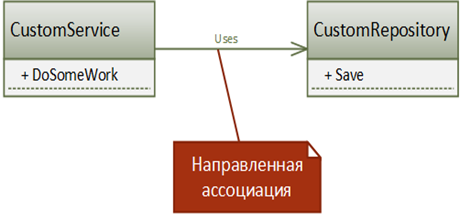
Рисунок 1. Отношение ассоциации
Приложите все усилия для того, чтобы вы управляли зависимостями в приложении, а не зависимости управляли вами. Мнение автора статьи по поводу зависимостей
Основной способ борьбы со сложностью сводится к тому, чтобы в один момент времени мы могли сосредоточиться на минимальном количестве сущностей или абстракций. В основном этот принцип исходит из двух предпосылок: во-первых, средний человек не в состоянии держать в голове одновременно слишком большое количество понятий (обычно говорится о цифре семь, плюс минус две), и при увеличении их количества приходится сохранять избыточную информацию и анализировать каждый из ее кусков повторно. Во-вторых, при увеличении количества сущностей, которыми мы оперируем в один момент времени, увеличивается и суммарная сложность их поведения: достаточно попытаться объединить в одном месте кэширование и обычную бизнес-логику, чтобы понять, что это значит.
Проблема вся в том, что при увеличении количества понятий (сущностей, абстракций) в одном месте сложность растет экспоненциально, что приводит к невозможности удерживать задачу в голове даже при минимальном ее усложнение. Как следствие, это приводит к появлению ненужных ошибок, неучтенных граничных условий и проблем сопровождения, поскольку кроме автора уже никто не в состоянии оценить всю глубину глубин и понять, что в этом коде происходит.
Все принципы ООП, включая Принцип Единой Ответственности, понятия связности и связанности (cohesion и coupling), и многие другие, призваны бороться с неотъемлемой сложностью (essential complexity) нашей бизнес-области и сводить случайную сложность (accidental complexity) к минимуму. Все наши продуманные абстракции, хитроумные паттерны и высокоуровневые языки программирования призваны акцентировать внимание на естественной сложности задачи, скрывая несущественные подробности.
У каждого из нас есть интуитивное представление о том, что является зависимостью, и что ею не является. Так, например, с параноидальной точки зрения любая сущность, используемая нашим классом, является зависимостью, включая примитивные типы языка программирования и другие типы стандартной библиотеки. С другой стороны, очевидно, что даже в стандартной библиотеке есть классы, использование которых напрямую может «связать» наш класс слишком тесно с некоторым окружением и сделает невозможным, например, модульное тестирование.
Марк Cиман (Mark Seeman) в своей книге “Dependency Injection in .NET” именно по этой причине выделяет два типа зависимостей: с одной стороны у нас есть стабильные зависимости (stable dependencies), «абстрагироваться» от которых нет особого смысла, поскольку они доступны «из коробки», являются стандартом «де факто» в вашей команде, и их поведение не меняется в зависимости от состояния окружения.
Кроме этого, есть изменчивые зависимости (volatile dependencies), реализация (или даже публичный интерфейс) которых может измениться в будущем, либо их поведение может измениться «самостоятельно» без нашего ведома, поэтому их нужно выделить в отдельную абстракцию и ограничить их использование. К такому классу зависимостей относятся библиотеки сторонних разработчиков, собственный код, область применения которого хорошо бы ограничить. К этому же типу зависимости относятся зависимости, завязанные на текущее окружение, такие как файлы, сокеты, базы данных и так далее. И хотя интерфейс таких зависимостей едва ли изменится в будущем, их «изменчивость» проявляется в том, что их поведение может измениться без изменения пользовательского кода.
|
На самом деле, ограничение использования любой зависимости является идеальным способом борьбы с изменениями. Ведь чем в меньшем количестве мест в вашем коде используется некоторый класс или интерфейс, тем меньше стоимость его изменения или ошибки в его реализации. Если вы считаете, что нечто может измениться в будущем, то сделайте это деталью реализации, сведя, таким образом, область изменений к минимуму. |
И хотя названия этих двух типов зависимостей с первого взгляда могут показаться не вполне точными, лично меня эти термины вполне устраивают. Главное, чтобы это разделение было у нас в голове: есть зависимости, от которых нужно абстрагироваться, а есть такие, которые можно использовать напрямую, и в этом нет ничего страшного!
Кроме того, одну и ту же зависимость (например, все тот же FileStream) можно в одном контексте рассматривать как стабильную, а в другом – как изменчивую. С другой стороны, само использование класса FileStream говорит о некотором «персистентном» хранилище или чем-то подобным. Возможно, разумнее будет абстрагироваться не просто от файловых операций, а выделить некоторую бизнес-сущность, типа IConfigurationLoader, и «протаскивать» уже ее, а не низкоуровневые сущности, типа IStream или собственного IFileStream.
Каждый раз, когда мы выделяем зависимость в самостоятельную абстракцию, мы преследуем определенную цель (или несколько целей).
В-первых, путем выделения зависимости мы можем повысить уровень абстракции и оградить весь остальной код от ненужных подробностей. Для этого, например, мы можем выделить отдельные интерфейсы/ классы для доступа к удаленным сервисам, слою доступа данных и т.п. Мы просто хотим думать не в терминах реализации (WCF, NHibernate), а в терминах абстракции (AbstractService, CustomRepostory). Не нужно быть гуру в современных новомодных принципах разработки, чтобы прийти к выводу, что подобные операции стоит спрятать куда-нибудь поглубже, и не размазывать их использование ровным слоем по всему приложению.
Во-вторых, возможно, мы хотим получить «конфигурируемость» поведения путем использования паттернов «Стратегия», «Абстрактная фабрика» и тому подобных. То есть мы с самого начала знаем, что у нас будет несколько реализаций, и создаем соответствующий дизайн с самого начала.
| ПРИМЕЧАНИЕ Марк Сииман в своей книге приводит очень интересное наблюдение, подтвержденное и моей собственной практикой. Многие разработчики и архитекторы забывают, что у любого решения есть и обратная сторона, и гибкость в этом вопросе не исключение. На самом деле, не такое уж много приложений требует гибкой настройки своего поведения путем переконфигурирования приложения. Обычно повторное развертывание приложения с заменой текущей реализации может быть достаточно «гибким» решением, особенно когда это развертывание происходит на собственных серверах. Поэтому, прежде чем закладываться на настраиваемость всего и вся, подумайте о том, насколько это вам действительно нужно. |
В-третьих, мы можем выделять зависимость для того, чтобы протестировать логику нашего класса в изоляции без внешнего окружения. Для этого первым шагом является выделение набора операций в абстрактный интерфейс с «протаскиванием» его через конструктор класса.
В последнее время мода на использование интерфейсов распространилась так, что очень часто их начинают выделять «автоматом», считая это залогом «слабосвязанного дизайна» и тестируемости приложения. И хотя правильное выделение зависимостей и использование абстракций (интерфейсов и абстрактных классов), а не конкретных реализаций (конкретных классов), и правда приводит к слабой связанности (low coupling), чрезмерное их использование может привести к обратному результату.
Сколько раз вы видели класс, принимающий 10 зависимостей в конструкторе? Или класс, который принимает в конструкторе сервис-локатор или DI-контейнер, и дергает потом из него зависимости при необходимости? И хотя в таком случае мы не завязываемся на конкретные классы, такой дизайн едва ли можно назвать слабосвязанным, ведь для того, чтобы разобраться в том, что же он требует на вход, придется проанализировать всю его реализацию.
Скотт Мейерс (гуру С++) самым важным принципом проектирования считает следующий: ваш класс или модуль должно быть легко использовать правильно и сложно использовать неправильно. Классом же с десятком параметром правильно пользоваться весьма сложно; точнее, достаточно просто пользоваться им в давно отконфигурированном приложении с использованием DI-контейнеров, но создать и «угодить» ему с нуля – дело совсем не простое.
Именно поэтому использование сервис-локатора или внедрение обязательных зависимостей через свойства являются антипаттернами. В этом случае невероятно просто использовать класс неправильно и сложно использовать правильно.
Сам факт наличия у класса большого количества зависимостей говорит о проблемах с дизайном и либо о нарушении принципа Единственной Ответственности и нечетком контракте класса, либо о неправильной группировке операций по интерфейсам, либо о чрезмерной гибкости, которая, возможно, так и не понадобилась.
Даже если ваш класс завязан лишь на абстракции (т.е. на интерфейсы) – это не значит, что связанность отсутствует, просто вместо явной зависимости от конкретных реализаций, вы получили неявную зависимость (implicit coupling) на множество «абстракций», на порядок их создания, на их состояние в момент использования, на определенные «детали» их реализации, на стабильность их интерфейсов, что делает сложным понимание того, «как же вся эта хрень работает».
Выделение зависимости в интерфейс добавляет в приложение «шов» (seam), благодаря которому мы можем «вклиниться» в существующее поведение. Подобные швы дают определенную гибкость, но делают это не бесплатно – если швов слишком много, то мы получаем слишком сложное решение, более сложное в понимании и сопровождении.
Зависимости сами по себе не являются чем-то плохим, пока они используются в ограниченном количестве мест, позволяют легко сопровождать код и писать для него Unit-тесты, и основной способ борьбы с ними сводится не столько к выделению интерфейсов, сколько к ограничению их области применения. При этом помните, что параноидальное выделение интерфейсов и протаскивание их десятками с помощью контейнеров не делает дизайн слабосвязанным и понятным. Код остается формально тестируемым, но стоимость его сопровождения (и стоимость сопровождения тестов) будет не меньше, чем у исходного якобы «монолитного» дизайна с мелкими конкретными классами.
Между двумя классами/объектами возможны разные типы отношений. Самым базовым типом отношений является ассоциация (association). Это означает, что два класса как-то связаны между собой, и мы пока не знаем точно, в чем эта связь выражена, и собираемся уточнить ее в будущем. Обычно это отношение используется на ранних этапах дизайна, чтобы показать, что зависимость между классами существует, и двигаться дальше.
Рисунок 1. Отношение ассоциации
Более точным типом отношений является отношение открытого наследования (отношение «является», IS A Relationship), которое говорит, что все, что справедливо для базового класса, справедливо и для его наследника. Именно с его помощью мы получаем полиморфное поведение, абстрагируемся от конкретной реализации классов, имея дело лишь с абстракциями (интерфейсами или базовыми классами), и не обращаем внимание на детали реализации.
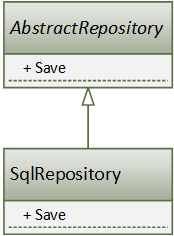
Рисунок 2. Отношение наследование
И хотя наследование является отличным инструментом в руках любого ОО-программиста, его явно недостаточно для решения всех типов задач. Во-первых, далеко не все отношения между классами определяются отношением «является», а во-вторых, наследование является самой сильной связью между двумя классами, которую невозможно разорвать во время исполнения (это отношение является статическим и в строго типизированных языках определяется во время компиляции).
В этом случае на помощь приходит другая пара отношений: композиция (composition) и агрегация (aggregation). Оба они моделируют отношение «является частью» (HAS-A Relationship) и обычно выражаются в том, что класс целого содержит поля (или свойства) своих составных частей. Грань между ними достаточно тонкая, но важная, особенно в контексте управления зависимостями.
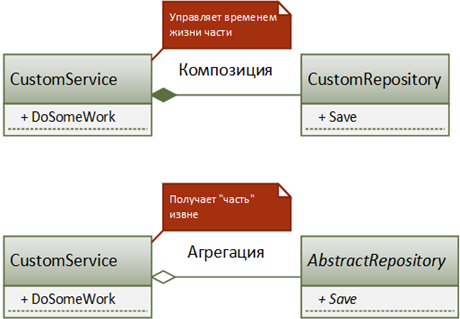
Рисунок 3. Отношение композиции и агрегации
| СОВЕТ Пара моментов, чтобы легче запомнить визуальную нотацию: (1) ромбик всегда находится со стороны целого, а простая линия – со стороны составной части; (2) закрашенный ромб означает более сильную связь – композицию, не закрашенный ромб показывает более слабую связь – агрегацию. |
Разница между композицией и агрегацией заключается в том, что в случае композиции целое явно контролирует время жизни своей составной части (часть не существует без целого), а в случае агрегации целое хоть и содержит свою составную часть, время их жизни не связано (например, составная часть передается через параметры конструктора).
class CompositeCustomService
{
// Композиция
private readonly CustomRepository _repository
= new CustomRepository();
public void DoSomething()
{
// Используем _repository
}
}
class AggregatedCustomService
{
// Агрегация
private readonly AbstractRepository _repository;
public AggregatedCustomService(AbstractRepository repository)
{
_repository = repository;
}
public void DoSomething()
{
// Используем _repository
}
} |
CompositeCustomService для управления своими составными частями использует композицию, аAggregatedCustomService – агрегацию. При этом явный контроль времени жизни обычно приводит к более высокой связанности между целым и частью, поскольку используется конкретный тип, тесно связывающий участников между собой.
С одной стороны, такая жесткая связь может не являться чем-то плохим, особенно когда зависимость является стабильной (см. раздел «Стабильные и изменчивые зависимости» выше). С другой стороны, мы можем использовать композицию и контролировать время жизни объекта, не завязываясь на конкретные типы. Например, с помощью абстрактной фабрики:
internal interface IRepositoryFactory
{
AbstractRepository Create();
}
class CustomService
{
// Композиция
private readonly IRepositoryFactory _repositoryFactory;
public CustomService(IRepositoryFactory repositoryFactory)
{
_repositoryFactory = repositoryFactory;
}
public void DoSomething()
{
var repository = _repositoryFactory.Create();
// Используем созданный AbstractRepository
}
} |
В данном случае мы не избавляемся от композиции (CustomService все еще контролирует время жизни AbstractRepository, но делает это не напрямую, а с помощью дополнительной абстракции – абстрактной фабрики). Поскольку такой подход требует удвоения количества классов наших зависимостей, то его стоит использовать, когда явный контроль времени жизни является необходимым условием.
Интересной особенностью разных отношений между классами является то, что логичность их использования может зависеть от точки зрения проектировщика, от того, с какой стороны он смотрит на задачу, и какие вопросы он задает себе при ее анализе. Именно поэтому одну и ту же задачу можно решить десятком разных способов, при этом в одном случае мы получим сильно связанный дизайн с большим количеством наследования и композиции, а в другом случае эта же задача будет разбита на более автономные строительные блоки, объединяемые между собой с помощью агрегации.
Например, нашу задачу с сервисами и репозитариями можно решить множеством разных способов. Кто-то скажет, что здесь подойдет наследование и сделает SqlCustomService наследником отAbstractCustomService; другой скажет, что этот подход неверен, поскольку CustomService у нас один, а иерархия должна быть у репозитариев.
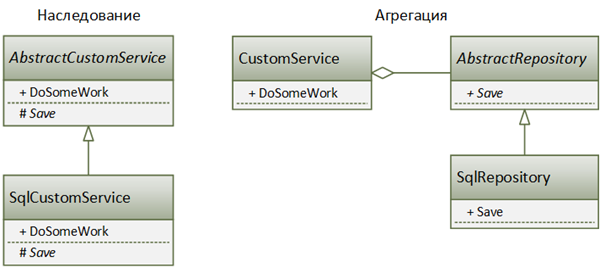
Рисунок 4. Наследование vs Агрегация
Все варианты приводят к одному и тому же конечному результату, при этом связанность изменяется от очень высокой (при наследовании) к очень слабой (при агрегации).
Суть инверсии зависимостей сводится к тому, что класс перекладывает ответственность за создание зависимости или получение ее экземпляра на более высокий уровень, в результате чего он сам не создает экземпляр конкретного класса, а получает его от более высокоуровневого кода через конструктор
В некоторых случаях «где-то выше» может быть непосредственно вызывающим кодом, когда речь заходит о локальных стратегиях. В этом случае вызывающий код точно знает, какая стратегия ему требуется и использует ее напрямую (как, например, в случае с сортировкой):
// Стратегия сортировки
var sortedArray = new SortedList<int, string>(
new CustomComparer()); |
Существует вариация предыдущего случая, когда вызывающий код не создает зависимость напрямую, но знает о классе/объекте, которые могут в этом помочь. Иногда более высокоуровневый код знает о некотором локальном или глобальном контексте, недоступном низкоуровневому классу, с помощью которого можно получить экземпляр требуемой зависимости.
var wcfTracer = new WcfTracer(Logger.GetLogger()); |
Вызываемый код (класс
Оба эти варианта достаточно простые и, если возможно, то стоит использовать именно их, поскольку в этом случае наш «граф» объектов не размазывается по всему приложению, а ограничивается лишь несколькими классами.
| ПРИМЕЧАНИЕ Может показаться, что этот совет противоречит общепринятым DI-практикам, однако это не так. Помните разговор об |
Любая зависимость – это шов на теле приложения. Чем он будет короче, тем легче его скрыть и от него избавиться; некоторые зависимости являются деталями реализации модуля и выставление их наружу может нарушить инкапсуляцию модуля.
Далеко не всегда вызывающий класс может получить экземпляр зависимости самостоятельно. Если это невозможно, то он поступает аналогичным образом – перекладывает решение о создании или получении зависимости на еще более высокий уровень. Здесь тоже есть несколько вариантов. Более высокоуровневый класс может потребовать эту же зависимость от своего вызывающего класса (через конструктор или свойство) или поднять уровень абстракции, сгруппировав несколько абстракций в одну, требуя от своего «верхнего уровня» абстрактную фабрику или объект с набором зависимостей.
Достаточно очевидно, что такое перекладывание ответственности не может продолжаться вечно, поскольку кто-то в конечном итоге должен принять решение о том, какие конкретные классы соответствуют каким интерфейсам приложения. В разных типах приложений это место выглядит по-разному, но не зависимо от этого, оно имеет одно название – Composition Root.
| ПРИМЕЧАНИЕ И опять может показаться, что проблема постоянного перекладывания ответственности имеет простое решение – использование контейнера напрямую. В результате контейнер будет выступать в роли Service Locator-а, что многими экспертами считается анти-паттерном (и подробнее об этом мы еще поговорим). |
Любое приложение содержит точку входа, с которой начинается его исполнение. В идеальном случае эта точка содержит всего несколько строк кода, которые сводятся к созданию одного (или нескольких) экземпляров самых высокоуровневых классов, представляющих основную логику приложения. Именно здесь нам придется решить, какие абстракции требуются нашим модулям верхнего уровня, и именно точка входа приложения является идеальным местом для разрешения всех зависимостей.
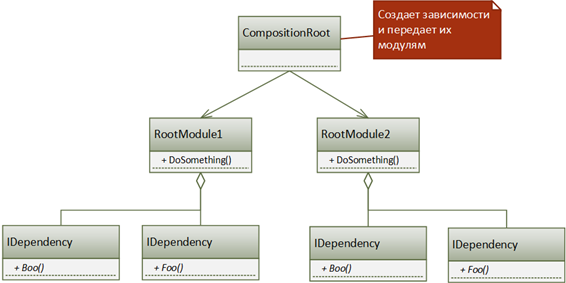
У разных типов приложений точка входа выглядит по-разному: для консольного приложения это метод Main, для WPF приложения – App.xaml, для Web-приложения – Global.asax, для NT-сервиса – класс-наследник
Независимо от того, какая стратегия конфигурирования выбрана (код, xml-конфигурация, convention-based), именно в Composition Root должна располагаться логика конфигурирования приложения. И, по сути, это должно быть единственным местом использования самого контейнера:
var container = BuildContainer();
var rootModule = container.Resolve<RootModule>();
// используем rootModule
container.Release(rootModule); |
В реальном приложении процесс конфигурирования контейнера будет несколько сложнее. Даже средней сложности приложение может содержать десятки, если не сотни, зависимостей, конфигурирование которых в одном месте сделает Composition Root слишком сложным. В этом плане могут помочь DI-контейнеры, большая часть которых поддерживают идею модульности (Modules
Несмотря на то, что конфигурация контейнера может быть размазана по нескольким модулям, его использование для получения зависимостей должно быть ограниченным.
Существуют некоторые зависимости, которые используются десятками классов. В этом случае попытка передать их через конструкторы приведет к тому, что каждый класс будет содержать не менее 3-4 параметров, а классы более высокого уровня будут вынуждены знать о десятке зависимостей, требуемых на несколько уровней ниже. В этом случае можно воспользоваться паттерном под названием Ambient Context (глобальный или внешний контекст).
По своей сути, Ambient Context очень похож на синглтон, в том плане, что он содержит статический член (обычно свойство), через который можно получить и установить некоторую зависимость. Ключевое отличие заключается в том, что Ambient Context оперирует абстракцией (интерфейсом или абстрактным классом), а не реализацией (конкретным классом):
interface ILogger {}
class LogManager
{
public static ILogger GetLogger() {}
}
interface IJobProvider {}
class JobProvider
{
static JobProvider()
{
Provider = new DefaultJobProvider();
}
public static IJobProvider Provider { get; set; }
} |
Этот паттерн интенсивно используется в .NET Framework (SynchronizationContext.Current, Thread.CurrentThread, Thread.CurrentPrincipal, HttpContext.Current и т.д.) и применяется для установки нужного окружения для выполнения так называемых «сквозных задач» (cross-cutting concerns), связанных с транзакциями, безопасностью и т.п. Но он может применяться и для других инфраструктурных зависимостей (например, для логгера или безопасности), а также для некоторых типов бизнес-задач.
Этот паттерн не обладает основными недостатками синглтонов, поскольку он оперирует абстракциями, а также поддерживает гибкость, необходимую для юнит-тестирования, и позволяет изменить поведение в зависимости от нужд приложения. Обычно такие зависимости устанавливается в Composition Root приложения и, в случае необходимости, могут содержать реализацию по умолчанию.
Несмотря на эти особенности, Ambient Context обладает и главным недостатком, присущим синглтону и Service Locator-у: неявностью. Чтобы понять, что некоторый класс использует зависимость через Ambient Context нужно проанализировать весь код класса (как мы увидим позднее, есть ряд приемов, чтобы, по крайней мере, уменьшить эту проблему).
Даже при наличии ряда недостатков, Ambient Context с разумным использованием может помочь развязать разные модули друг от друга, не протаскивая слишком большое количество зависимостей через высокоуровневые классы.
Если бы мы жили в идеальном мире, то все зависимости передавались бы через конструкторы, а решение о том, каким абстракциям соответствуют какие реализации, принималось бы только в одном месте – в Composition Root. Но в реальном мире приложения обладают высокой связанностью, используются кучи синглтонов, да и абстракции далеки от идеала. Для решения или смягчения этих проблем я использую ряд приемов, которые могут помочь и вам.
Прежде всего, я стараюсь не выделять слишком много абстракций. Точнее, я стараюсь выделить минимальное количество интерфейсов, способных обеспечить разумную гибкость приложения. На самом деле, в приложении не так много зависимостей (стратегий), ответственность за получение которых нужно перекладывать на вызывающий код, и уж тем более таких зависимостей, которые нужно протаскивать через десяток уровней.
Старайтесь избегать интерфейсов с одной реализацией, ведь это усложняет понимание и навигацию, не давая ничего взамен. Из-за популярности техники инверсии зависимостей ее стали применять бездумно, по принципу «ну ведь так все делают» или «это ведь полезно!». Протаскивание интерфейсов через несколько уровней нарушает инкапсуляцию, поскольку вместо стратегий наружу выставляются подробности реализаций низкоуровневых деталей.
Подумайте, является ли выделенный интерфейс абстракцией, которую вы не можете и не должны контролировать. Если это не так, то просто выделите отдельный класс и используйте его напрямую. В любом случае вы получите достаточную гибкость и модульность и легко сможете выделить интерфейс, если в этом появится необходимость.
Обычно я стараюсь использовать следующий подход: низкоуровневые классы принимают зависимости через конструктор, которые затем разрешаются как можно раньше. При этом в более высокоуровневом классе я в любом случае стараюсь инициализировать зависимость в конструкторе: путем создания конкретного класса или путем получения ее от третьей стороны:
class MainViewModel
{
private readonly IJobProvider _jobProvider = JobProvider.Provider;
private readonly IJobConsumer _jobConsumer = new TaskBasedJobConsumer();
public void Start()
{
var editViewModel = new EditViewModel(_jobProvider);
var window = new Window { DataContext = editViewModel };
window.ShowDialog();
}
} |
При таком подходе мы получаем достаточно четкое представление о зависимостях класса и можем довольно легко перейти от одного типа управления зависимостями к другому (например, переключиться от Ambient Context к Constructor Injection). Поскольку основная бизнес-логика сосредоточена на нижних уровнях, которые принимают зависимости через конструктор, то мы получаем разумный компромисс между тестируемостью и количеством абстракций, которые нужно за собой таскать.
Получение зависимостей в конструкторе позволяет четко увидеть все зависимости класса, всего лишь просмотрев список его полей и тело конструктора, что существенно смягчает описанную ранее проблему паттерна Ambient Context.
Помните, что ваша система является иерархичной, уровень абстракции которой возрастает от низкоуровневых классов к более высокоуровневым. То же самое должно происходить и с абстракциями-зависимостями. Не нужно протаскивать в том же виде интерфейсы через 3-4 уровня классов. Поднимаясь по уровням абстракции, группируйте зависимости в более высокоуровневые зависимости: пользуйтесь абстрактными фабриками, возвращающими несколько зависимостей, или группируйте зависимости вместе.
Не останавливайтесь на существующем наборе абстракций. Тот факт, что вашему классу требуется 3-4 интерфейса, говорит о том, что в вашем дизайне не хватает еще одной зависимости или конкретного класса. Возможно, стоит скрыть все четыре зависимости за одним фасадом и протаскивать уже именно его. А может быть, стоит вообще воспользоваться наблюдателем, и пусть высокоуровневый класс решает, как его реализовать.
Основная суть управления зависимостей, как и любого другого принципа проектирования, сводится к борьбе со сложностью и упрощению сопровождения, и не является самоцелью. Инверсия зависимостей заключается к перекладыванию ответственности на более высокий уровень, но нужно четко понимать, что это не решение проблемы, а изменение ее формы. Иногда это все, что нам нужно, но чрезмерное увлечение интерфейсами может привести к усложнению кода и преобразованию иерархии классов (это хорошо) в плоский граф (а это плохо).
Зависимости сами по себе не являются чем-то плохим, пока они используются в ограниченном количестве мест, позволяют легко сопровождать код и писать для него юнит-тесты, и основной способ борьбы с ними сводится не столько к выделению интерфейсов, сколько к ограничению их области применения. При этом помните, что параноидальное выделение интерфейсов и протаскивание их десятками с помощью контейнеров не делает дизайн слабосвязанным и понятным. Код остается формально тестируемым, но стоимость его сопровождения (и стоимость сопровождения тестов) будет не меньше, чем исходный якобы «монолитный» дизайн с мелкими конкретными классами.