 Оценка 0
Оценка 0 
 Оценить
Оценить 






| Оценка 0 Оценить
|
Изучению семантики данных препятствует некоторая недовыясненность сути предмета, отсутствие единых признанных подходов и терминологическая путаница. Определенные затруднения вызывает увеличение количества предметных областей, с которыми необходимо работать, и неизбежное усиление роли лингвистического и когнитивного аспектов.
Мы собираемся заниматься исключительно семантикой баз данных, однако будем использовать отдельные аналогии из лингвистики и языков программирования. Полезно знать, что в некоторых подходах к переводу с одного естественного языка (ЕЯ) на другой ЕЯ создается специальный язык функций для представления семантики, в который транслируются фразы исходного языка [1]. А уже с этого промежуточного языка осуществляется трансляция на второй ЕЯ. В языках программирования обратим внимание на необходимость выделения нескольких видов семантики: операционной (описывается в терминах перехода состояний некоторой абстрактной машины), денотационной (в языке для представления семантики используются математические структуры, позволяющие установить возможность вычисления конструкций языка посредством специализированных функций), дедуктивной (позволяет доказывать свойства программ, в первую очередь их правильность), трансляционной (использует правила перевода на язык, семантика которого известна), основанной на таблицах решений и т.д.
Вернемся к терминологии в базах данных. Еще в 1988 году Э. Кодд [2] отметил, что «ярлык «семантическое» не должен интерпретироваться в каком-либо абсолютном смысле». Тем не менее, существует безосновательная, но устойчивая традиция выделять некоторые модели и базы данных как семантические. Модель «сущность-связь» считается семантической моделью, по-видимому, по сравнению с табличными моделями данных. Oracle11g представляется как первая семантическая база данных из-за того, что она хорошо работает с XMLи RDF и действительно расширяет семантический слой базы. Однако элементы семантики есть в любых моделях данных. В тех же табличных базах семантику определяют метаданные, например, ключи и ограничения целостности. В базах данных с декларативными языками всегда реализуется операционная семантика представляется планами исполнения. Так что можно говорить только о большей или меньшей насыщенности моделей и баз данных семантикой.
Будем называть смыслами данных [3] (сокращенно – смыслами) любые фрагменты семантики, которые могут быть выделены, запомнены и использованы при интерпретации данных. Смыслы данных – это частный вид элементов семантики, но не любой элемент семантики есть смысл данных. Иначе говоря, мы можем достаточно четко определить смыслы данных и показать, как их реализовывать, но не утверждаем, что других элементов семантики в информационных системах не существует.
Смысл характеризуется интерпретатором, местом нахождения, событиями, вызывающими активность, местом или способом прикрепления, особенностями активизации и сценарием реализации. Роль интерпретатора, который распознает существование смысла и реализует его, может играть человек (пример такого смысла – комментарий в тексте программы при обычном его использовании), программа (пример – неявные преобразования типов), человек и программа (например, тройки RDF, ограничения целостности в базах данных или документирующий комментарий в Java).
Элементы семантики, интерпретируемые программой, должны быть активны во время исполнения программы. Смыслы в базах данных это вид данных, прикрепленных к другим данным и отличающийся от обычных пассивных данных своей активностью, то есть способностью инициировать работу некоторого программного или человеко-программного интерпретатора смысла.
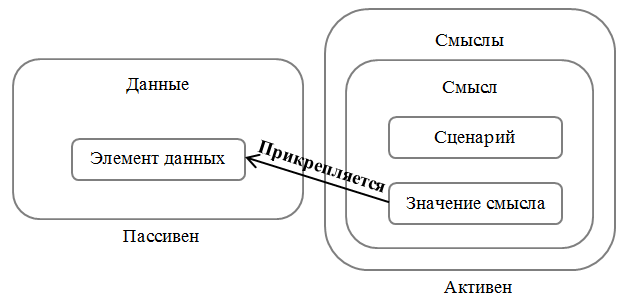
Рисунок 1. Данные и смыслы
Одно замечание о месте и/или способе прикрепления элементов семантики к фразам исходного языка или элементам данных. Так, в ЕЯ семантические структуры прикрепляются к слову, словосочетанию, фразе, тексту или корпусу текстов. Процесс смыслообразования управляется ходом анализа фразы в некотором контексте. В языках программирования смыслы могут прикрепляться к токенам, конструкциям языка или программам.
Есть основания считать, что в современных базах данных смыслы более локализованы, чем в ЕЯ, способы прикрепления семантики к данным другие, а процесс смыслообразования упрощен. Еще раз обратим внимание на то, что семантика может выражаться и часто выражается на языке, отличном от языка представления данных.
В базах данных семантика давно используется в геоинформационных системах. Правда, там понимают ее своеобразно – как слой неких ярлыков, размещенных поверх основного слоя базы. По-настоящему необходимость расширения семантики данных была понята в работах по консолидации гетерогенных баз данных и, особенно, с появлением семантического Web’а.
Обычно декларативные языки, используемые в информационных системах, весьма бедны семантикой, а программа-интерпретатор не имеет за душой ничего, кроме операционной семантики, позволяющей реализовать правильное исполнение инструкций и выбрать оптимальный вариант. Можно расширить семантику базы, добавляя элементы семантики, полученные отображением каких-то моделей предметной области. Такой процесс мы будем называть насыщением базы данных смыслами. Нетрудно догадаться, что использование и частных элементов семантики, и общих, присущих достаточно большим предметным областям, может быть весьма полезным. К сожалению, язык описания предметной области обычно не формализован, типология предметных областей не определена или неизвестна.
Мы покажем, что в базах данных можно существенно увеличить объем хранимой семантики, как интерпретируемой программой, так и совместно программой и человеком, рассмотрим классификации хранимых смыслов и способы реализации баз данных, насыщенных смыслами.
Современные информационные системы (ИС), как правило, хранят лишь незначительную часть семантики моделируемой предметной области и решаемых задач. Большая часть информации, собранной в процессе анализа предметной области, в лучшем случае остается в документации, предназначенной для человека, в худшем – просто теряется. Приятное исключение – системы типа Oracle Designer и Unify.
Использование онтологий для построения информационных систем и расширения возможностей запросов в базах данных [4] существенно меняет ситуацию. Появляется возможность включения большого пласта семантики предметных областей. Но онтологии содержат лишь часть возможной семантики данных. Кроме того, использование онтологий из внешних источников может существенно снизить быстродействие.
Мы уже упоминали, что первое основание для классификации любых смыслов – это интерпретатор смыслов, то есть человек, программа или совместно человек и программа.
Второе основание для классификации – место нахождения. Это память человека, база данных, интерфейс пользователя и т.д. Здесь мы будем рассматривать только смыслы, размещенные в базе данных.
Среди смыслов, которые могут храниться в базе, и предназначены для интерпретации программой, выделим следующие три вида:
Поясним последний вид смыслов. Обычно неявно предполагается, что пользователь умный (а с другой стороны, усложнение программы нам ни к чему), то есть он, как сейчас говорят, «в теме» и правильно понимает семантику предметной области. Например, он не будет писать запрос, в котором складываются рост и вес сотрудников. А может быть, даже помнит, что измерение успеваемости выполняется в шкале порядка, а потому средний балл – это неадекватная статистика.
Третье основание классификации смыслов – это набор событий, вызывающих активность. Выделим четыре вида событий: задание и изменение структур данных, изменение данных, чтение данных, события связанные с работой системы управления базами данных и ее администрированием. Современные базы данных почти никогда не используют событие чтения данных и не всегда работают с событиями первого и последнего классов.
Четвертое основание классификации смыслов – место прикрепления.
Учтем, что современные базы данных могут иметь многослойные модели. Например, данные столбца реляционной таблицы могут разбираться с помощью регулярных выражений, в столбце может храниться содержимое файла XML и т.д.Поэтому смыслы в табличных базах могут прикрепляться к следующим объектам:
Обратим внимание на то, что столбец, таблица, схема как элементы метаданных могли бы быть связаны со смыслами в словаре, если бы СУБД позволяла это.
Вспомним, что связи в СУБД реляционного типа не представляются отдельными хранимыми объектами базы, а выражаются через ключи – первичный и внешний – которые являются атрибутами таблиц-сущностей. Поэтому традиционно реализуются только бинарные ассоциации кратностей «один-ко-многим» и «один-к-одному» и некоторый примитивный вариант обобщения. Используя смыслы можно представлять связи таблицами, у которых ключ составляют столбцы привязки к таблицам-сущностям. Смыслы в таблицах-связях задаются эмерджентными атрибутами или прикрепленными к ним другими атрибутами. Появляется возможность реализовать связи с произвольной арностью, агрегаты, композиции и ряд полноценных вариантов обобщения. Возможно более детальное задание кратности, например, {0,1}.
Отметим, что строки и значения в выбранной строке и столбце, то есть ячейки таблицы, в метаданных не представляются. Пары понятий «строка – таблица» и «ячейка – столбец» интересны тем, что они представляют каждая экстенсионал и интенсионал одного и того же понятия. У любого элемента такой пары могут быть свои смыслы. Например, столбец «Дата рождения» в некоторой таблице представляет интенсионал понятия «Время начала существования». Если имеется смысл «Надежность сведений о дате рождения», то его значения относятся к конкретным значениям дат, представляющим экстенсионал понятия, а не ко всему столбцу «Дата рождения». Поскольку прикрепление возможно только к элементам схемы, описываемым метаданными, то столбец смысла «Надежность сведений о дате рождения» будет прикрепляться к столбцу «Дата рождения», но интерпретироваться будет в соответствии с его назначением на ячейку.
Последнее пятое основание классификации смыслов, хранящихся в базе данных – особенности активизации и сценарий реализации – мы рассмотрим ниже в разделе “Реализация смыслов в базах данных реляционного типа».
Смыслы можно классифицировать еще по следующим основаниям:
Значениями признака «предметная область» являются модель предметной области, концептуальная модель базы, база (логическая или физическая модель), эмулированная структура данных, хранящаяся в базе, другие компоненты информационной системы – такие, как интерфейс пользователя, приложения middle tier и т.п.
Если для реализации смысла не требуется использования других смыслов, то такой«независимый» смысл будем называть поверхностным. Остальные смыслы будут характеризоваться как глубинные.
И несколько слов о типах данных, представляющих значения смысла. Ниже будет видно, что очень часто используются перечислимые типы, причем не исключено, что в консолидируемых данных могут встретиться разные наборы значений, которые необходимо как-то согласовывать. Типичный пример – оценка успеваемости в 5-, 10- и стобальной системах.
Ожидаемые шкалы измерения [5] значений смыслов – номинальная, порядковая или решеточная. Возможно использование более сложных шкал типичных для психологии, социологии и эконометрики.
Рассмотрим четыре примера смыслов в табличных базах данных.
В таблице, хранящей сведения о товарах, имеются два столбца – «Вес»и «Единица измерения веса». Для определения весов партий товаров необходимо перемножить количество по каждой позиции на вес одной позиции и сложить результаты, учитывая, что вес может измеряться в разных единицах – граммах, килограммах, тоннах и т.д.
В информационной системе, «понимающей» что такое единица измерения, можно написать запрос, представленный в листинге 1, а программа претранслятора входного запроса должна обнаружить смысл «Единица измерения» и автоматически перефразировать запрос с учетом использованных единиц измерения. Смысл активизируется событием «чтение данных» и всегда прикрепляется к столбцу.
SELECT sum(количество*вес) FROM... |
Смысл «Шкала измерения» характеризует все данные в столбце. Активизируется событием «чтение данных» и прикрепляется, естественно, к столбцу с характеризуемыми данными.
«Надежность экспериментальных данных» оценивается значениями перечислимого типа, например, в виде набора «надежные», «не надежные», «неизвестно». При запросе некоторой статистики программа должна обнаружить этот смысл и попросить пользователя уточнить задание («Вывести только надежные данные или все?» или «Сравнить надежные и остальные данные?» и т.п.). Смысл активизируется событием «чтение данных». Может прикреляться и к строке, и к столбцам.
Табличный смысл «Структура в таблице» позволяет указать, какая именно структура хранится в таблице (например, дерево или сеть некоторого вида) и следит за ее целостностью при модификации данных. Пусть таблица содержит иерархию подчиненности сотрудников в организации. При модификации данных необходимо следить за тем, чтобы структура сохранялась, то есть не должны появляться поддеревья, образующие лес, не должны образоваться циклы. Рассматриваемый смысл может быть связан со строковым смыслом «Роль в дереве». С помощью последнего можно указать, какие узлы являются – листьями, какой – корнем, а какие имеют и предков и потомков. Смысл активизируется событиями «удаление данных», «ввод данных», «обновление данных», а прикрепляется он к таблице.
Отметим, что смысл «Структура в таблице» глубинный, а предыдущие три смысла – поверхностные.
Перечислим еще несколько смыслов, указав их место крепления:
Было бы удобно добавлять информацию о смыслах к таблицам метаданных словаря, но СУБД не предоставляют такой возможности. Существует два основных способа прикрепления значений смысла к данным.
Рассмотрим первый вариант. Значения смыслов, прикрепляемых к части значения в столбце, к ячейке, к строке и группе строк, можно хранить непосредственно в таблицах с данными. На рис. 2 к столбцу «Столбец n» прикреплен столбец со значением ячеечного смысла «Столбец со значением смысла». Вторая таблица представляет словарь смыслов, позволяющий определить связь столбцов данных и смыслов в таблицах, хранящих значения смысла, и указать имена этих смыслов. Предполагается, что со столбцом связан единственный смысл.

Рисунок 2. Подсхема БД при хранении смыслов в таблице с данными
Строчные смыслы, значения которых прикрепляются каждое к одной строке или группе строк, реализуются почти такой же схемой, но в схеме таблицы со смыслами значения столбца смысла относятся к строке целиком, а не к столбцу или ячейке. Поэтому столбец «Имя столбца, к которому прикреплен смысл» необходимо убрать из таблицы словаря. Вместо него указывается набор имен столбцов, по которым выделяется группа строк или одна строка. Для группы строк указывается условие выделения группы.
Во втором варианте предлагается хранить смыслы изолированно от пассивных данных. Это облегчает организацию повторного использования смыслов и создание режима отказа от использования смыслов. Подсхема, содержащая словарь смыслов, хранит всю информацию, необходимую для работы со смыслами. Она представляет собой нечто вроде хранимой в БД онтологии смыслов, используемых в базе.
Онтологии, которые позволяют хранить свое содержимое в БД, зачастую настолько универсальны, что запросы для извлечения информации получаются очень сложными и медленными. Наша схема хранит только необходимый набор смыслов. Кроме того, обычные онтологии не предоставляют возможности описать активность смыслов и каким-либо образом ее вызывать.
Чтобы разрешить использование двух режимов – с использованием смыслов и без них – и не перегружать данными базу, не интерпретирующую семантику, следует весь семантический слой вынести в отдельную подсхему. Например, система, содержащая только смыслы, прикрепляемые к ячейке, будет выглядеть так, как показано на рис. 3.

Рисунок 3. Подсхема БД при хранении смыслов изолировано от данных
Для реализации смыслов в табличных БД (базах реляционного типа) необходимо, чтобы СУБД предоставляла следующие возможности:
Возможности табличных СУБД в этом плане ограничены. Например, в Oracle, начиная с версии 10g,существует ряд пакетов, позволяющих эмулировать триггер на selectи переписывать запрос частично или полностью. Для эмуляции триггера на событие select можно использовать пакет DBMS_RLSили DBMS_FGA.Методы пакетаDBMS_RLS позволяют организовать поведение близкое к триггерам. Эмуляция триггера происходит путем создания так называемых процедур политики и задания времени их выполнения (например, на событие select указанной таблицы).
Для перезаписи запросов «на лету» в Oracle предлагается использовать пакет DBMS_ADVANCED_REWRITE.Однако у него много ограничений, и его использование в процедурах политики пакета DBMS_RLS приводит к внутренней ошибке Oracle.
Известными нам средствами СУБД отменить текущий запрос в процедуре политики невозможно. Разве что переписать текущий запрос так, чтобы он не возвращал строк, например, добавив тождественно ложное условие (например, «1=2») или вызвать ошибку приложения с помощью процедуры RAISE_APPLICATION_ERROR.
В Oracleсуществует еще одна возможность переформулировки запроса, но она реализуется только оптимизатором. В настоящий момент пользователи не имеют возможности использовать ее непосредственно.
Если нет возможности изменить СУБД, остается создать клиент или специальное серверное приложение со встроенным транслятором для предварительной обработки команд языка (рис. 4). В такой системе можно и переписывать исходный запрос, составляя новый запрос с учетом найденных смыслов, и отменять исходный запрос.
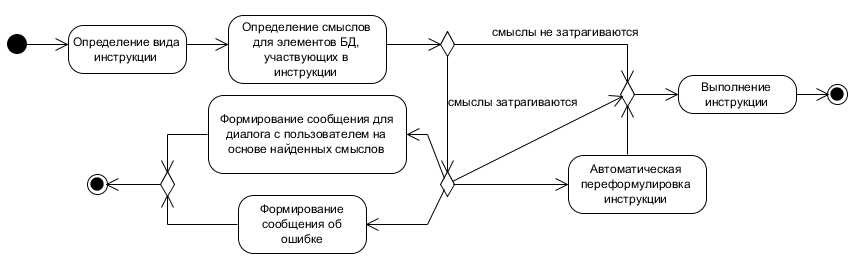
Рисунок 4. Работа клиента с претранслятором.
Кроме процессов определения вида инструкции и обнаружения смыслов, участвующих в выполнении этой инструкции, в сценариях, связанных со смыслами, используются:
Рассмотрим организацию схемы, хранящей смыслы изолированно от пассивных данных (рис. 4). Таблицы в ней разделены на четыре группы. На рис. 5 каждая таблица отмечена номером группы, в которую она входит. Таблица «Связь таблиц данных и смыслов», хранящая значения смыслов и их привязку к данным составляет первую группу. Она соответствует таблице «Словарь смыслов» второго способа хранения смыслов (рис. 4), используется при переформулировании запроса и позволяет добавить условия на значения смыслов.
Вторая группа таблиц содержит в себе описание смыслов и состоит из четырех таблиц: «Смысл», «Место крепления смысла», «Группа смысла», «Уровень информирования пользователя». Таблица «Место крепления смысла» содержит возможные места крепления (например, таблица, столбец, строка и т.д.), которые являются одной из характеристик смысла. «Группа смысла» позволяет выделить набор смыслов, для обработки которых может использоваться один и тот же сценарий. Например, в группу «качества данных» входят смыслы «надежность данных», «состояние документа» и т.п. Таблица «Уровень информирования пользователя» содержит вид возвращаемого сценарием результата. Сценарий может вернуть информацию, необходимую для интерактивного общения с пользователем, информацию для сообщения о внесенных изменениях в запрос, или ничего не вернуть. В последнем случае, пользователь оказывается в неведении о внесенных изменениях в запрос или в БД. При этом вид возвращаемого результата зависит от рассмотренных ниже режимов работы со смыслами.
Третья группа таблиц содержит информацию о возможных наборах значений смыслов, а также соответствия значений из разных возможных наборов значений. В эту группу входят таблицы «Набор значений», «Шкала значений», «Значение», «Соответствие значений из разных наборов», «Связь смысла и наборов его возможных значений». Таблица «Набор значений» содержит возможные значения смысла. Таблица «Шкала значений» помогает определить что-то типа шкалы, в которой измеряется набор значений. Таблица «Значение» содержит все возможные значения смыслов для разных наборов. Можно указать соответствия значений из разных наборов, предназначенных для одного смысла, с помощью таблицы «Соответствие значений из разных наборов».
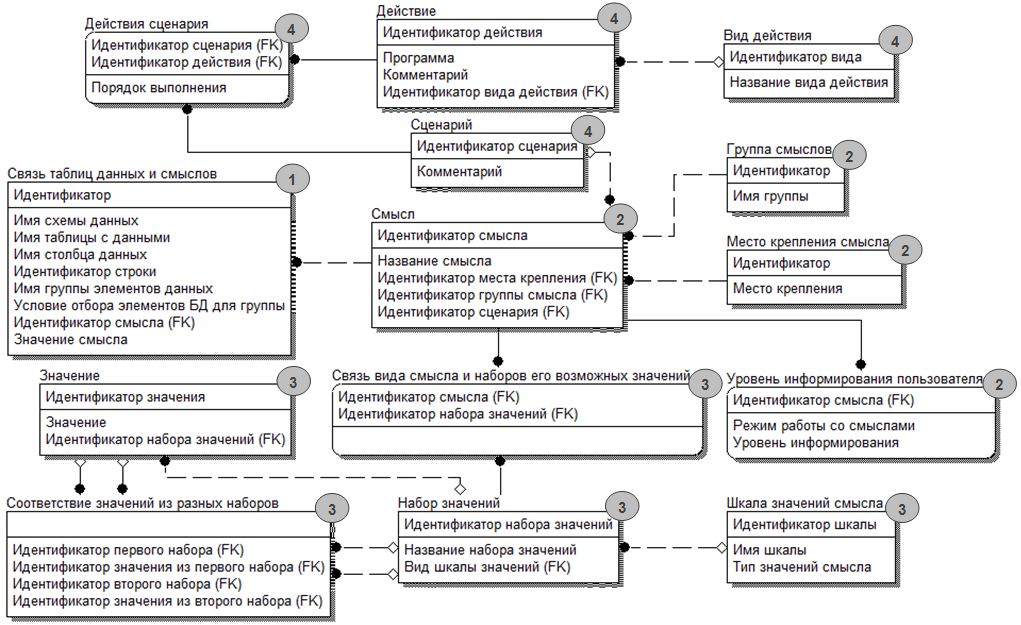
Рисунок 5. Схема хранения данных смыслов
Четвертая группа таблиц содержит информацию о сценариях, выполняемых при активизации смысла. Она содержит таблицы «Сценарий», «Действие», «Вид результата действия» «Действия в сценарии». Действие – это строка, которая представляет собой код на одном из процедурных языков программирования (например,PL/SQL). При выполнении сценария каждое действие выполняется, например, с помощью динамического SQL.При описании сценария каждому действию ставится в соответствие идентификатор, задающий его место в сценарии (содержится в таблице «Действия в сценарии»). Некоторые действия могут использовать результаты, полученные предыдущим действием. Кроме того, результат действия, как и сценария в целом, может быть различный (таблица «Вид результата действия»). Виды результата действий совпадают с видами результата сценариев, описанных выше и хранящихся в таблице «Уровень информирования пользователя». Единственное отличие в том, что режим работы со смыслами не влияет на вид результата действия. Предлагается обрабатывать смысл, ориентируясь на эти виды результата действий, так как это позволяет более эффективно организовать код.
Можно использовать три режима работы со смыслами:
Помимо описанных характеристик в схеме отражены также наборы возможных значений смыслов и соответствия между ними.
Рассмотренная схема позволяет хранить смыслы только одного приложения.
В работе [6]представлена система, реализующая инвариантные структуры данных, называемые еще универсальной моделью данных (УМД). Она предоставляет пользователю возможность работы с виртуальными базами данных, которые обладают следующими свойствами:
Простейшая схема УМД представлена на рис. 6.

Рисунок 6. Схема УМД
Запросы при работе с УМД очень большие, медленные и трудные для понимания. В [6] предлагается решить эту проблему путем использования языка Query-by-Example (QBE), для реализации которого был написан претранслятор для перевода запросов с языка QBEна SQL.Запросы всегда пишутся в виртуальной базе, и имеется возможность проконтролировать исполняемый запрос. Такой способ реализации позволяет реагировать на любое событие, инициированное пользователем, в т.ч. и запрос с фразой SELECT.
На основе варианта системы, описанного в [6], разработано клиентское приложение, использованное как претранслятор при работе со смыслами в табличной модели данных. Единственный транслятор интерпретирует и запросы, и команды DDL и DML. Поэтому выполнение любой команды, в том числе и запроса, может быть триггерным событием, запускающим процедуру, играющую роль триггера. В частности, событием может быть запрос данных.
При работе со смыслами запрос может переформулироваться так, чтобы он содержал не только данные, но и значения смыслов. Для построения такого запроса необходимо извлекать данные из таблицы «Связь таблиц данных и смыслов», которая содержит элементы БД и прикрепляемые к ним значения смыслов.
Запросы для извлечения значений строковых смыслов очень похожи на запросы, формируемые для работы с УМД. Действительно, сравним таблицы «Связь таблиц данных и смыслов» (рис. 5) и таблицу «Данные» варианта УМД, изображенного на рис. 6. При построении запроса, содержащего условия на значения строковых смыслов (например, «надежность данных»), используются столбцы «Имя схемы данных», «Имя таблицы с данными», «Имя столбца данных», «Идентификатор строки», «Идентификатор смысла», «Значение смысла». Таким образом, таблица «Связь таблиц данных и смыслов» представляет собой, в сущности, таблицу данных в УМД, разработанной для хранения смыслов, а все остальные таблицы, изображенные на рис. 5, представляют собой описание смыслов и сценариев при их активизации. Соответствия столбцов таблицы «Связь таблиц данных и смыслов» и таблицы «Данные» показаны на рис. 7. Таким образом, для построения запросов при работе со смыслами был всего лишь немного модифицирован пакет, транслирующий запросы при работе с УМД.
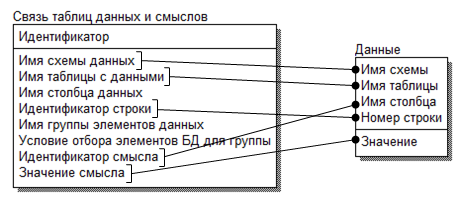
Рисунок 7. Соответствия столбцов таблиц «Связь таблиц данных и смыслов» и «Данные»
На рис. 8 представлен интерфейс системы для работы со смыслами. Запросы к табличной базе данных осуществляются с помощью конструкций языка QBE. На рис. 8 показаны запрос на QBE, соответствующий ему сформированный запрос на SQL, его результат, а также набор смыслов, которые можно добавить на форму для уточнения запроса. Подобный результат пользователь увидит при работе с системой в «лояльном» режиме. При добавлении смыслов на форму пользователь автоматически переводится в «строгий» режим работы.
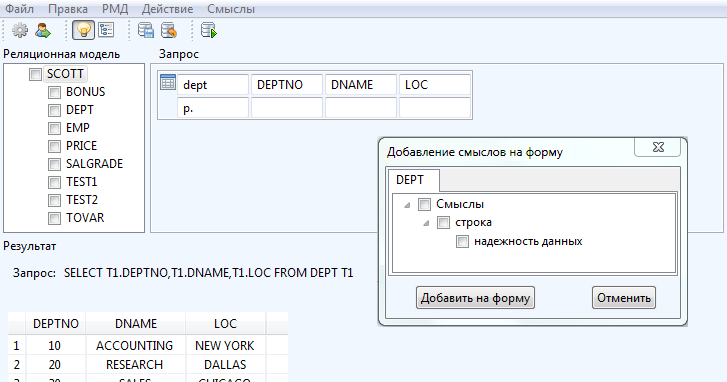
Рисунок 8. Выполнение запроса в «лояльном» режиме работы со смыслами
В «строгом» режиме работы пользователю предоставляется дерево смыслов, которые он может добавить на форму. При выполнении запроса, учитывая выбранные смыслы, транслятор может переформулировать или отменить исходный запрос. В итоге запрос, извлекающий смыслы данных, объединяется с запросом, извлекающим сами данные, и выполняется, а результат и весь текст запроса предоставляются пользователю (рис.9).
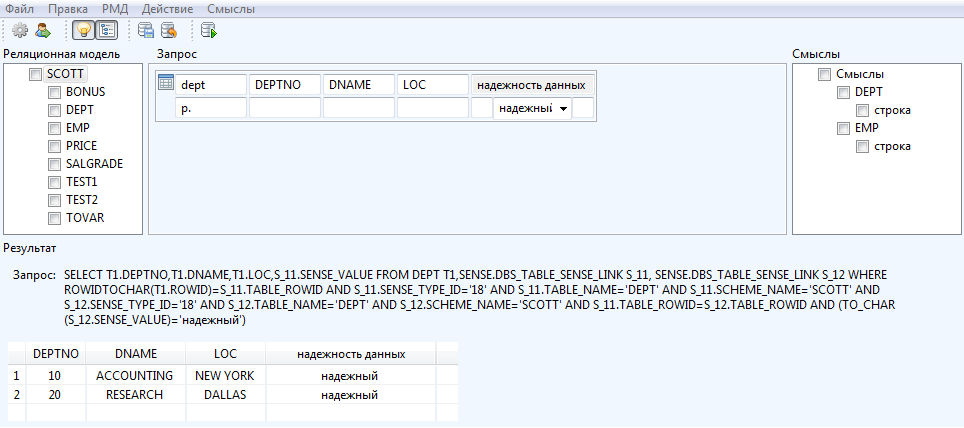
Рисунок 9. Выполнение запроса в «строгом» режиме работы со смыслами
Пользователь может сразу перейти в «строгий» режим работы, если он знает, какие типы смыслов ему нужны для составления запроса. Разделение на режимы работы учитывается системой при выборе сценария работы. Таким образом, для каждого смысла можно предусмотреть два сценария – для «строгого» и «лояльного» режимов.
Заметим, что некоторые сценарии с учетом смыслов могут выполняться автоматически, без обращения к пользователю.
Как уже упоминалось, предусмотрен вариант отказа пользователя от работы со смыслами.
Поскольку смыслы, помещаемые в базу, определяются в основном предметной областью и в меньшей мере – базой данных, желательно смыслы выделить и обеспечить их повторное использование. Схема, предоставляющая такую возможность, приведена на рис.10.
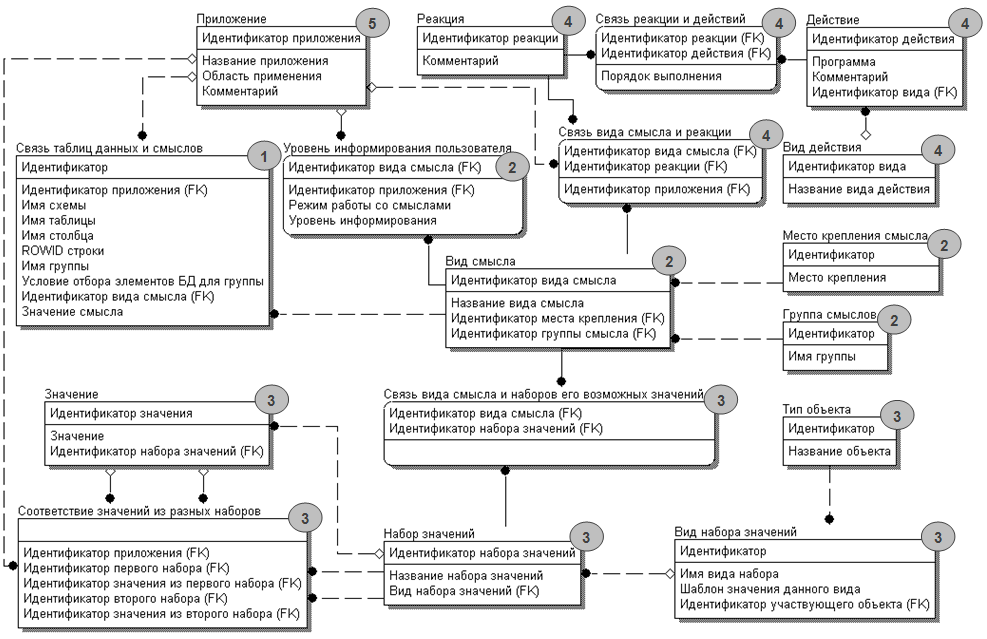
Рисунок 10. Упрощенное добавление соответствия смыслов из разных приложений и их значений
К схеме хранения смыслов, представленной на рис. 5, добавлена таблица «Приложение», отмеченная на рис. 10 цифрой 5, которая позволит выделить информацию о смыслах разных приложений (рис. 10). Информация о приложении, использующем смыслы, будет влиять только на таблицы «Связь таблиц данных и смыслов», «Сценарий», «Связь смысла и наборов его возможных значений», «Соответствие значений из разных наборов». Остальные таблицы содержат данные, описывающие смыслы и не зависящие от приложения.
Не вдаваясь в подробности, отметим, что такая система представляет некоторую разновидность базы знаний предметной области, ориентированной на реализацию в базах данных. Понятно, что для эффективного ее использования необходимо решить целый ряд теоретических проблем, связанных с заданием сходства и связанности смыслов, их контекстности.
Для переноса предлагаемого нами подхода на объектные модели данных следует учесть отличия в структурах моделей, выяснить, как организовать активность при обнаружении смыслов, и как могут храниться данные и смыслы. Основное отличие объектной и объектно-реляционной моделей от реляционной в расширении допустимых типов и наличии методов. В объектной модели ODMG используются классы определяющие типы, а в объектно-реляционной модели в дополнение к скалярным типам, используются векторные типы данных.
В объектной модели можно задавать видимость полей класса и, в частности, задавать и получать значения полей только с помощью методов get и set. Активность смыслов можно реализовать в этих методах. При этом хранить информацию о смыслах можно как совместно с данными, так и в других классах.
Объектно-реляционная модель ближе к реляционной. Столбцы объектных таблиц общедоступны. Поэтому хранение смыслов и активность могут быть организованы как в реляционной модели.
Предлагаемый подход существенно расширяет семантику, реализуемую в базах данных.В базе появляются связи, которые ранее не могли быть созданы. Можно считать, что введены семантические расширения реляционных и объектных моделей, реализуемые программно.
Базы данных, насыщенные семантикой, можно эмулировать за счет использования претрансляторов, которые в исходной инструкции обнаруживают прикрепленные смыслы и реализуют их, преобразуя исходную инструкцию автоматически или после диалога с пользователем, а затем передавая полученный результат на исполнение.
Для создания семантических расширений СУБД реляционного типа и объектно-реляционных необходимо:
Мы полагаем, что производителям СУБД было бы нетрудно внести необходимые изменения. Возможность работы с использованием и без использования смыслов не ухудшит быстродействия в обычном режиме.
Основные проблемы баз данных насыщенных семантикой связаны с необходимостью создания таксономии смыслов, разработкой типовых шаблонов реализации смыслов и организацией повторного использования смыслов, по возможности независимого от СУБД. Поскольку объем информации в предметных областях, отображаемых в базах данных, громаден, подобная работа может быть выполнена только коллективно.
В ближайшее время мы надеемся разобраться с теоретическими проблемами смыслов и начать работу с глубинными смыслами.
| Оценка 0 Оценить
|