Как я обещал в прошлом номере, в этой статье я начинаю расширенное описание процесса создания и отладки макросов. К сожалению, ресурсы человеческие и журнальные страницы ограничены, и в этом номере публикуется только первая часть статьи. К сожалению, в ней речь так и не доходит до реальных примеров макросов. Зато здесь я попытался описать внутреннюю кухню компилятора, что, на мой взгляд, необходимо для полного понимания работы макросов и, как следствие, для их более эффективной разработки.
Во второй части статьи я постараюсь описать аспекты создания конкретных типов макросов и привести примеры, демонстрирующие процесс их создания.
Ну, а пока... теория :).
Что такое макрос и зачем он нужен?
Макрос Nemerle – это подключаемый модуль компилятора, который позволяет тем или иным образом генерировать код. Это слишком расплывчатое определение, но чуть ниже я постараюсь уточнить его.
Предупреждение
Прежде чем начать развернутый рассказ о макросах, хочется сделать одно небольшое предупреждение, дабы уберечь вас от необдуманных поступков и травм, которыми могут наградить вас ваши коллеги за вашу излишне бурную деятельность.
Макросы – это мощнейшее средство, которое может как значительно упростить решение сложнейших задач, так и сделать вашу жизнь (и что еще более опасно, жизнь ваших коллег) невыносимой.
Как метко подметил Игорь Ткачев (IT) – макросы сродни атому. Атом может использоваться как для создания оружия тотального уничтожения мира, так и для производства дешевой электроэнергии. Так и макросы могут стать как супер-инструментом упрощающим вашу жизнь, так и средством прострелить себе через пятку остатки головного мозга :).
Макрос должен использоваться тогда и только тогда, когда другие средства не предоставляют удовлетворительного решения. Причем если вы колеблетесь, решить ли проблему в виде библиотеки или функции, или создать новый макрос, то лучше выберите первый путь (по крайней мере до тех, пор пока у вас не появится железных аргументов за использование макроса).
Аргументами в пользу применения макросов могут служить:
Необходимость генерировать код по некоторому образцу. Например, таким примером может служить наличие паттерна проектирования (или реализации), который требует относительно большой ручной работы для реализации, не может быть оформлен в виде функции или класса, и который может быть выражен декларативно (а весь код может быть сгенерирован на основании декларативного описания и/или информации о типах проекта или внешних сборок).
Возможность решить проблему, создав простой в использовании DSL (Domain Specific Language, язык, специфичный для предметной области). Например, вы можете описать ваши данные на неком языке, а потом по этому описанию сгенерировать множество сложных типов, реализующих все необходимые детали. Использование DSL может стать могучим подспорьем в борьбе со сложностью, приближая реализацию системы к ее спецификации.
Вы чувствуете, что можете автоматизировать свой труд, если получите доступ к внутренним структурам компилятора и его API.
Вам очень не хватает некоторой конструкции, способной существенно сократить ваш код или сделать его более безопасным. Например, если вы занимаетесь созданием многопоточных или псевдопараллельных приложений, то может быть разумно разработать стратегию неблокирующей работы (на основе очереди, см. статью "Работа с потоками в C#" в этом номере журнале) и ввести в язык специальные конструкции, позволяющие прозрачно интегрировать эту стратегию в язык.
В общем, стоит сто раз отмерить, чтобы потом не отрезать себе важные части тела :).
Виды макросов
Макросы в Nemerle можно разделить на следующие типы:
Макросы в выражениях (expression macro). Они, в свою очередь, делятся на макросы, выглядящие в коде как обычные функции, и на макросы, вводящие новый синтаксис.
Макросы-операторы.
Мета-атрибуты.
Лексические макросы.
Макросы в выражениях или обычные макросы –это макросы, которые выглядят как обычные функции, или макросы, которые можно использовать внутри выражений и которые вводят специализированный синтаксис. Простые макросы-функции очень удобны, если некоторую задачу нельзя оформить в виде функции или класса, но можно решить макросом, и при этом вас удовлетворяет то, что вызов макроса выглядить как обычный вызов функции. В отличие от обычной функции, в макросе вы можете пользоваться API компилятора, анализировать и преобразовывать код, передаваемый в макрос в качестве параметров, и анализировать код типов, объявленных в исходном тексте проекта. Примерами обычных макросов могут служить макросы форматированного ввода-вывода (print, printf, strint, и т.п.), макрос lazy, добавляющий возможность декларативно помечать участки кода и структуры данных как «ленивые», т.е. поддерживающие отложенное вычисление. Примером макросов, вводящих синтаксис, может служить большинство операторов самого языка Nemerle (например, оператор &&). Макросами являются такие конструкции, как return, break, continue, if/else, while, do/while, for, foreach, using, lock, и многие, многие другие операторы, которые на первый взгляд выглядят как встроенные. При этом некоторые макросы значительно мощнее своих встроенных аналогов из других языков программирования. Например, макрос foreach в Nemerle не только выполняет те же оптимизации, что и его аналог в C#, но и поддерживает сопоставление с образцом, позволяя намного более гибко обрабатывать последовательности.
Макросы-операторы позволяют ввести в язык новые операторы. Nemerle поддерживает расширение типов операторами так же, как это делает C#. Причем такие операторы будут доступны и в C# (если тип, в которых они определены, доступен публично). Однако макросы-операторы предоставляют большую гибкость в некоторых случаях.
Во-первых, макросы-операторы оперируют с любыми типами данных (даже описанными во внешних сборках, или даже вообще неизвестными на этапе компиляции макросов, т.е. еще не существующими). Это является как преимуществом, так и недостатком. Преимущество состоит в том, что таким образом созданный оператор накрывает сразу большой класс типов и может без труда применяться, даже если операнды имеют разный тип. А недостаток заключается в том, что намного тяжелее обрабатывать особенности отдельных типов – ведь перегрузка при этом не работает, и вам придется анализировать типы операндов вручную. Еще одним недостатком является то, что вы не можете одновременно использовать два одинаковых оператора (объявленных в разных пространствах имен).
Во-вторых, вы можете вводить действительно новые типы операторов. Единственное ограничение – операторы должны состоять из нелитеральных символов (не букв, цифр или знака подчеркивания). Такого нет даже в C++, хвастающемся своей гибкостью и расширяемостью. Однако, как у многих преимуществ, у этого есть своя оборотная сторона. Оператор в Nemerle определяется как последовательность нелитеральных символов, так что если вы по забывчивости соедините два оператора, то лексический анализатор Nemerle будет интерпретировать их как единый оператор (скорее всего, не определенный в программе). Например, вы не можете написать двойного отрицания «!!someValue», так как оно будет проинтерпретировано как оператор «!!». Впрочем, подобные выкрутасы не имеют смысла в Nemerle (как, например, в C++, где это является довольно распространенным паттерном преобразования целочисленного значения в bool). Префиксные операторы довольно редки в Nemerle, а бинарные операторы не вызывают никаких проблем ввиду свой специфики, так что я еще не видел на практике проблем от неверной интерпретации операторов. К тому же помогают принятые на RSDN правила форматирования кода, которые обязывают программиста выделять операторы пробелами. В любом случае, возможность определять собственные операторы воистину неоценима для тех, кто хочет создавать собственные DSL!
Мета-атрибуты внешне не отличаются от пользовательских атрибутов C#, но, в отличие от них, приводят к вызову макроса с соответствующим именем и не вызывают генерации пользовательских атрибутов в метаданных сборки. Мета-атрибуты отлично подходят для реализации паттернов проектирования (многие из них уже реализованы в стандартной библиотеке), различных фреймворков, разнообразных мелких автоматизаций (например, можно сделать атрибуты, автоматически добавляющие эффективный код сериализации к классу). Как и в обычных макросах, в мета-атрибутах вы можете анализировать и изменять код типов, объявленных в текущем (компилируемом) проекте.
Лексические макросы вводят определенное ключевое слово, за которым должна идти группа токенов, заключенных в один из следующих видов скобок: {}, (), [ ], <[ ]>. Внутри скобок может быть любой набор токенов Nemerle. Единственное ограничение – все скобки должны быть парными (лексический анализатор Nemerle производит предварительный разбор токенов на группы, так что непарные скобки приведут к ошибке). Лексические атрибуты отлично подходят для создания сложных встроенных DSL и для расширения языка (например, с их помощью в Nemerle добавлена поддержка программирования по контракту – Design By Contract).
Разработка и отладка
Поскольку макросы – это, по сути, плагины к компилятору, то и отлаживать их нужно не так, как обычные приложения.
Создавать и отлаживать макросы можно двумя путями.
Первый путь был описан в моей статье "Макросы в Nemerle". Он заключается в использовании редактора Scintilla и небольшого batch-файла, автоматизирующего процесс компиляции сборки, содержащей макрос, и сборки, в которой он применяется. При таком подходе стандартными средствами отладки макроса становятся печать генерируемого макросом кода в консоль редактора Scintilla и расстановка вызовов System.Diagnostics.Trace.Assert(false) или System.Diagnostics.Debugger.Break() в теле макроса с целью динамического подключения отладчика (сама Scintilla не поддерживает отладку .NET-приложений).
Второй способ – использование созданной нами «Интеграции Nemerle в VS». Этот способ является более перспективным, но на момент написания этих строк проект интеграции еще находится в состоянии альфа-версии и содержит ошибки. Впрочем, ошибки будут в скором времени устранены. Использование же интеграции значительно повышает удобство разработки.
Чтобы создать и отладить макрос в VS 2005, нужно:
Создать проект «Nemerle\Macro Library» (Ctrl+Shift+N в пустом решении (Solution), выбрать папку Nemerle и затем – тип проекта «Macro Library»).
Создать проект типа «Console Application» (добавив его в то же решение).
Добавить во второй проект (консольного приложения) ссылку на первый проект (меню «Project\Add Reference...», на закладке «Project» выбрать единственное доступное значение).
После этого перекомпиляция макро-проекта будет приводить к тому, что консольный проект будет использовать новую версию макросов.
Это позволяет изучать генерируемый макросом код, просто наводя курсор мыши на его использование в коде и изучая содержимое всплывающей при этом подсказки.
Чтобы обеспечить отладку, нужно сделать следующее:
Сделать активным отлаживаемым проектом макро-проект.
В свойствах проекта, на закладке «Debug» в поле «Start Program», прописать путь к ncc.exe. Обычно он находится в каталоге «%ProgramFiles%\Nemerle», так что в этом поле можно прописать: «$(ProgramFiles)\Nemerle\NCC.exe».
В поле «Working Directory» следует прописать путь к консольному проекту. Например: «$(MSBuildProjectDirectory)\..\MacroTestConsoleApplication».
В поле «Command Arguments» следует прописать имена файлов (точнее, относительные пути к ним), затем указать ключ «-m:» (или –r:, если сборка также содержит типы), после которого указать путь к отлаживаемой макро-сборке. В итоге у вас должно получиться нечто вроде: «Main.n -m:$(MSBuildProjectDirectory)\bin\Debug\MacroLibrary2.dll».
ПРИМЕЧАНИЕ
Файлы проектов VS 2005 на самом деле являются файлами MSBuild. Поэтому в них можно использовать конструкции $(…) для доступа к свойствам проекта и переменным среды окружения. Свойство «MSBuildProjectDirectory» раскрывается в путь к текущему проекту, а «ProgramFiles» – в путь к каталогу «Program Files». Более подробно об этих возможностях можно узнать из статьи «MSBuild» (опубликованной в RSDN Magazine #6 2004).
ПРЕДУПРЕЖДЕНИЕ
Пока что диалог редактирования «Интеграции Nemerle с VS» раскрывает конструкции $(…) при открытии свойств проекта. Так что при повторном редактировании свойств проекта все пути, записанные с использованием конструкций $(…), превращаются в полные пути. Мы постараемся устранить этот недостаток в ближайшем будущем, а пока можно непосредственно редактировать файл макро-проекта в текстовом редакторе. Вот как могут выглядеть отвечающие за отладку теги в проекте:
Если вы настроили все верно, то можно поставить точку прерывания в теле макроса, нажать F5 и отлаживать код макроса по шагам.
Главное – понимать, что код макроса – это обычный библиотечный код, и к нему применимы все приемы отладки DLL.
Отдельной проблемой при создании макроса является то, что макрос может породить синтаксически корректный, но неверный с точки зрения семантики языка, код. В результате проект, в котором используется макрос, не будет компилироваться. Разработчики компилятора работают над тем, чтобы смягчить последствия этого, но полностью проблему устранить невозможно. В качестве средств отладки в данном случае можно порекомендовать просмотр генерируемого кода в IDE. Для этого нужно подвести мышь к месту, где используется макрос, и посмотреть всплывающую подсказку (Tooltip). Кроме того, можно использовать макрос, преобразующий код в текст, или просто вызов метода ToString() у выражений, возвращаемых из тела макроса или добавляющих новые типы.
Естественно, очень полезными при этом будут unit-тесты. С их помощью можно эмулировать сложные и граничные условия применения. Кроме того, Unit-тесты являются отличным способом отладки кода макросов (ведь макросы откуда-то надо вызвать).
Кроме того может случаться так, что код, порожденный макросом, будет корректен как синтаксически, так и семантически, но при этом будет содержать логические ошибки. При этом программа, использующая этот макрос, успешно скомпилируется, но будет выполняться с ошибками. Тут, опять же, можно применять преобразование генерируемого кода в текст (с последующим анализом), но можно воспользоваться и другими средствами. Например, вы можете использовать Reflector для декомпиляции сгенерированного кода, или добавить в порождаемый макросом код отладочную печать.
Кроме того, можно заставить компилятор порождать для сгенерированного кода текст и отладочную информацию. Пока что текст можно породить только для кода типов и их членов, добавляемого через метод DefineWithSource класса TypeBuilder. Думаю, что в дальнейшем эта идея будет развита, и возможность генерировать отладочный исходный текст появится и для макросов уровня выражений.
На сегодня эта функция новая, и толком я ее не успел попробовать. Так что сказать что-то о качестве ее работы я не могу. Если что, пишите отчеты об ошибках ;).
Ну и естественно, при создании макросов не лишним будет создать вручную прототип кода, который будет в дальнейшем генерироваться макросом. Это позволит отработать логику этого кода, а потом просто перенести его в макрос, сделав его универсальным.
Надеюсь, что со временем отладка макросов станет ненамного сложнее отладки обычного кода. Пока что это не так, но возможности, предоставляемые макросами, стоят того, чтобы потратить некоторое время на их отладку. Главное, что отлаженный макрос может легко применяться даже новичками.
Стадии компиляции
Компиляция – это многостадийный процесс. Макросы могут выполняться на разных стадиях. В зависимости от того, на какой стадии выполняется макрос, изменяются доступные ему данные и его возможности по модификации компилируемой программы.
Чтобы написать макрос, не обязательно знать всю «кухню» компилятора. Но знания о процессе компиляции не окажутся бесполезными. Они позволят вам делать более осознанный выбор.
Процесс компиляции
В листинге 1 приведен исходный код функции ManagerClass.Run(), из которой вызываются другие функции, отвечающие за разные стадии компиляции:
Листинг 1. Метод ManagerClass.Run() – основной метод компилятора.
/**
* Run passes of the compiler.
*/public Run() : void
{
Instance = this;
try
{
InitCompiler();
ProgressBar(1);
LoadExternalLibraries();
ProgressBar(2);
Hierarchy = TypesManager(this);
def trees = List.RevMap(Options.Sources, fun(x) { ParsingPipeline(LexingPipeline(x)) });
Message.MaybeBailout(); // we have detected multiple files already
ProgressBar(5);
// create N.C.TypeBuilders for all parsed types and add
// them to namespace hierarchyforeach (group in trees)
List.Iter(group, ScanningPipeline);
when (Options.DoNotLoadStdlib)
InternalType.InitNemerleTypes();
ProgressBar(8);
Hierarchy.Run();
Message.MaybeBailout();
Hierarchy.CreateAssembly();
ProgressBar(10);
Hierarchy.EmitAuxDecls();
Message.MaybeBailout();
NameTree.CheckReferencedNamespaces();
Hierarchy.EmitDecls();
Message.MaybeBailout();
NameTree.FinishMacroContextClass();
Hierarchy.CheckForUnusedGlobalSymbols();
Hierarchy.CheckFinalization();
when (Options.XmlDocOutputFileName != null)
{
def docs = XmlDoc(DocComments, Options.XmlDocOutputFileName);
Hierarchy.SourceTopIter(docs.DumpType);
docs.Save();
}
unless (Options.CompileToMemory)
Hierarchy.SaveAssembly();
Message.MaybeBailout();
KillProgressBar();
Stats.Run(this);
}
finally
{
CleanUp();
when (Options.PersistentLibraries)
Hierarchy.RemoveProgramTypes();
}
}
Сначала происходит инициализация внутренних структур данных (InitCompiler). На этом шаге, в частности, создается так называемое дерево пространств имен. Оно предоставляет быстрый доступ к описанию пространств имен, типов и макросов. В это дерево помещаются типы из текущего проекта, а также типы и макросы из сборок, ссылки на которые подключены к проекту. Дерево типов описывается классом Node, вложенным в класс NamespaceTree, который, в свою очередь, располагается в пространстве имен Nemerle.Compiler. Реализацию этих классов можно найти в файле http://nemerle.org/svn/nemerle/trunk/ncc/hierarchy/NamespaceTree.n
Создавая сложные макросы, нуждающиеся в информации о типах всего проекта, вам обязательно потребуется обращаться к этому классу, так что на нем нужно остановиться поподробнее. Чтобы не усложнять изложение отступлениями от основной темы, я дам описание этого класса чуть позже (см. раздел «Дерево пространств имен (NamespaceTree)»).
На следующем шаге производится загрузка типов из внешних сборок (LoadExternalLibraries). Типы из внешних сборок загружаются в «ленивой» манере. Подробнее об этом также будет рассказано в разделе «Дерево пространств имен (NamespaceTree)». Сейчас важно отметить только то, что на этом шаге происходит загрузка макросов из внешних сборок. По сути, макросы – это обычные типы .NET, помеченные специальным атрибутом и выполняющие ряд соглашений (так как для написания макросов введен специальный синтаксис, углубляться в устройство этих типов нет смысла). Описание макроса помещается в дерево пространств имен и может быть доступно, если программист «откроет» это пространство имен или укажет квалифицированный путь к макросу.
Далее создается и инициализируется TypesManager – класс, хранящий список TypeBuilder-ов и управляющий ими. TypeBuilder описывает тип, такой как класс, структура, вариант или перечисление. TypeBuilder создается только для типов, получаемых при парсинге исходного текста или создаваемых макросами/компилятором. Другими словами, это типы, которые будут помещены в результирующую сборку.
После этого шага компилятор готов к основной работе. Фактически, описанные выше шаги делает любой компилятор. Так что они по большому счету малоинтересны. А вот дальше начинаются существенные различия по сравнению со «среднестатистическим» компилятором «среднестатистического» объектно-ориентированного языка программирования.
Чтобы организовать поддержку макросов и расширения синтаксиса (а также в целях поддержки основанного на отступах Python-оподобного синтаксиса без скобок), компилятор Nemerle вводит необычную стадию компиляции, PreParse, и довольно необычное промежуточное представление кода.
Итак, по порядку. Сначала производится лексический разбор. Ссылка на лексический анализатор передается парсеру, который и занимается непосредственным его использованием. В файле http://nemerle.org/svn/nemerle/trunk/ncc/parsing/Lexer.n можно лицезреть код лексического анализатора, класс LexerBase из пространства имен Nemerle.Compiler и его наследников: LexerFile – разбирающий файлы, LexerString – позволяющий разобрать код находящийся в строке, LexerCompletion – являющийся расширением LexerString и использующийся при подсветке синтаксиса в IDE.
Лексический анализатор написан вручную (без использования построителей лексеров/парсеров). Это вызвано тем, что Nemerle (на котором и написан его компилятор) является языком, весьма упрощающим написание парсеров, что делает задачу не столь уж сложной. Хотя, честно говоря, лично я бы предпочел видеть чистую лексическую грамматику.
Итак, задача лексического анализатора – «прочесть» файл (или переданную строку) и вернуть поток (список) токенов, описывающих лексемы из обрабатываемого файла. В Nemerle есть небольшой список предопределенных ключевых слов и операторов. Вот он:
Кроме того, предопределенными являются скобки. Nemerle поддерживает следующие виды скобок: (...), {...}, [...] и <[...]>.
Последний вид скобок, <[ и ]>, предназначен для выделения квази-цитирования. Применение остальных практически аналогично применению скобок в C#, за исключением того, что параметры generic-типов обрамляются не угловыми скобками – < и > – а квадратными скобками – [ и ].
Я не случайно заговорил о скобках. Скобки в Nemerle обрабатываются особым образом. Это тоже связано с возможностью расширения синтаксиса. Чуть позже вы поймете, как.
Лексемы (токены) в Nemerle представляются вариантом Token. Вот его описание:
namespace Nemerle.Compiler
{
publicvariant Token : System.Collections.IEnumerable
{
| Identifier { name : string; } // Идентификатор (например, «main»).// Идентификатор, перед которым идет @.
| QuotedIdentifier { name : string; }
| IdentifierToComplete { prefix : string; } // Используется IntelliSense.
| Keyword { name : string; } // Ключевое слово.
| Operator { name : string; } // Оператор.// Разнообразные литералы.
| StringLiteral { value : string; }
| CharLiteral { value : char; }
| IntegerLiteral { lit : Literal.Integer; cast_to : Parsetree.PExpr }
| FloatLiteral { value : float; }
| DoubleLiteral { value : Double; }
| DecimalLiteral { value : Decimal; }
| Comment { value : string; } // Комментарий.
| Semicolon { generated : bool; } // ;
| Comma // ,
| BeginBrace { generated : bool; } // {
| EndBrace { generated : bool; } // }
| BeginRound // (
| EndRound // )
| BeginSquare // [
| EndSquare // ]
| BeginQuote // <[
| EndQuote // ]>// Следующие три токена применяются только в лексерах, используемых в IDE
| Indent { value : string; }
| WhiteSpace { value : string; }
| NewLine { value : string; }
// Следующая группа токенов появляется только после PreParse-шага.
| RoundGroup { Child : Token; } // ( ... )
| BracesGroup { Child : Token; } // { ... }
| SquareGroup { mutable Child : Token; } // [ ... ]
| QuoteGroup { Child : Token; } // <[ ... ]>
| LooseGroup { mutable Child : Token; } // ; ... ;// Эти токены тоже появляются только после PreParse-шага.// Причем в их поля Env помещается специальный объект, описывающий// список открытых пространств имен, подключенных из них, и ключевых слов// и операторов. Это делает возможным связывание типов для используемых// далее (внутри пространств имен) имен.
| Namespace { Env : GlobalEnv; Body : Token; }
| Using { Env : GlobalEnv; }
| EndOfFile
| EndOfGroup
// Определяет положение токена в файле.publicmutable Location : Nemerle.Compiler.Location;
// Ссылка на следующий токен.publicmutable Next : Token;
publicthis () { }
publicthis (loc : Location) { this.Location = loc; }
publicoverride ToString () : string { ... }
}
...
То, что токены описываются вариантом (типом данных variant), позволяет в дальнейшем упростить их анализ с помощью сопоставления с образцом.
Шаг – PreParse
Так вот, отличия от «нормального» компилятора начинаются сразу же за шагом лексического анализа.
Вы наверняка обратили внимание, что по сравнению с C# или, скажем, с C++, компилятор Nemerle распознает слишком мало ключевых слов и операторов.
Естественно, это не значит, что Nemerle – ограниченный язык. Просто приведенного списка ключевых слов достаточно для базового языка. Остальные ключевые слова и операторы описываются в виде макросов. Собственно, PreParse-шаг и позволяет распознать дополнительные ключевые слова.
Поскольку ключевые слова в Nemerle вводятся путем «открытия» пространств имен, PreParse вынужден анализировать директивы «using» и «namespace».
Однако пространства имен могут идти друг за другом и содержать код типов, при разборе которого потребуется знание обо всех типах и пространствах имен проекта. Чтобы позволить включать внутрь кода собственные DSL, авторами Nemerle была принята оригинальная идея. Они откладывают реальный парсинг типов проекта до следующих стадий, а на данной стадии производят так называемую «свертку по скобкам».
«Свертка по скобкам» подразумевает, что все скобки внутри исходного файла Nemerle являются парными и рекурсивно вложенными. Если в процессе PreParse-шага обнаруживается непарность или некорректная вложенность скобок, компилятор выдает сообщение об ошибке. Например, такой код:
{ ( } )
считается ошибочным.
Лексический анализатор распознает скобки как отдельные лексемы:
Все «обычные» (т.е. не относящиеся к скобкам и токенам Namespace и Using) помещаются внутрь токенов «скобочных групп». Таким образом, после PreParse-шага поток токенов из плоского превращается в иерархический. Причем уже на этом шаге выявляются все несоответствия скобок. Токены, идущие друг за другом и не объединенные в скобочный токен, помещаются в токен LooseGroup.
Lexer, PreParse и ключевые слова
Очень тонким моментом является то, как распознаются ключевые слова. Дело в том, что фактически лексический анализ (выделение токенов) и PreParse-шаг выполняются одновременно! PreParse-ер попросту запрашивает у Lexer-а токены по одному. При этом Lexer производит распознавание следующей лексемы в потоке символов, и если это идентификатор, то производит его сравнение с текущим списком ключевых слов, находящимся в переменной Keywords Lexer-а.
PreParse же, в свою очередь, распознавая пространства имен и директивы using, формирует набор ключевых слов и замещает им набор ключевых слов Lexer-а:
...
def parse_using_directive(tok)
{
finish_current(current_begin);
def (id, idLocs) = get_qualified_identifier();
match (get_token())
{
| Token.Semicolon as st =>
def loc = tok.Location + st.Location;
Env = Env.AddOpenNamespace(id, loc);
lexer.Keywords = Env.Keywords;
...
Таким образом, если в пространствах имен, «открытых» к этому моменту, обнаруживается ключевое слово, то оно автоматически распознается и помещается в токен Token.Keyword.
При обработке директив «using» также происходит регистрация синтаксических расширений (если в «открываемом» пространстве имен имеется макрос, расширяющий синтаксис). Это позволяет в дальнейшем (на стадии парсинга) распознать последовательности токенов, за распознавание которых отвечают макросы, и поместить их в специальную ветку AST – «MacroCall» (об AST речь пойдет чуть позже). На стадии типизации MacroCall «раскрывается», преобразуясь в окончательное выражение, которое типизируется, и для которого в дальнейшем (на стадии генерации кода) генерируется MSIL.
После PreParse-шага все токены разбираемого файла превращаются в дерево, состоящее из групповых токенов (RoundGroup, BracesGroup, SquareGroup, QuoteGroup, LooseGroup) и простых токенов, находящихся внутри них. Групповые токены отличаются от обычных тем, что кроме поля Next, указывающего на следующий токен, находящийся на том же уровне иерархии, они содержат также поле Child, ссылающееся на вложенные токены.
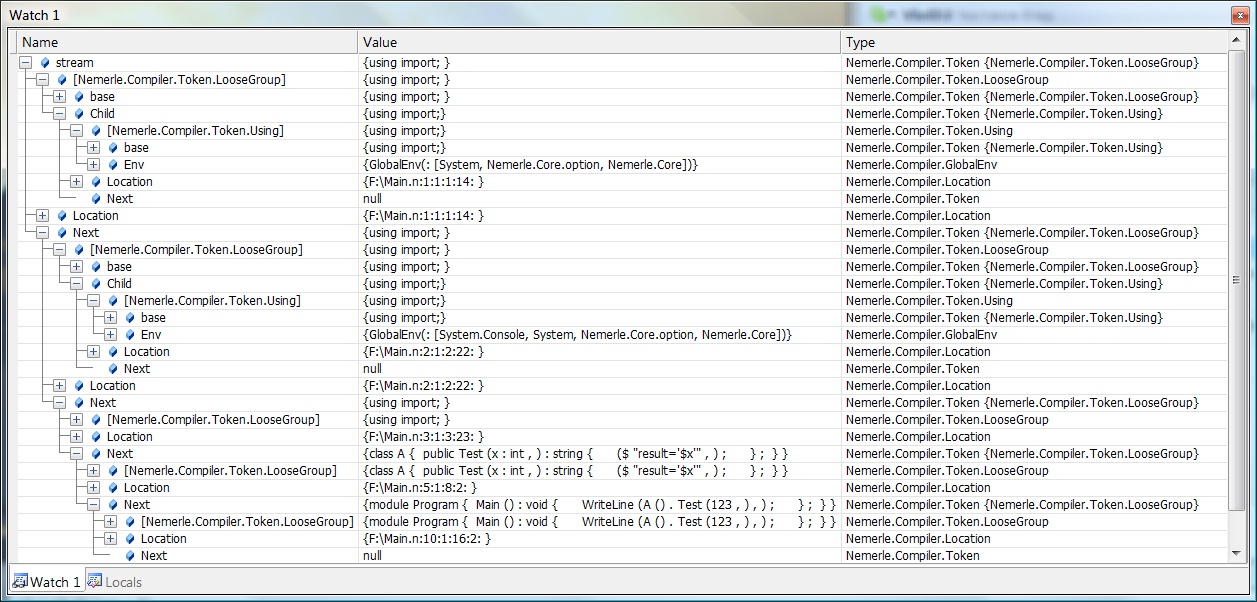
На рисунке 1 показано дерево, формируемое для следующего исходного файла:
using System;
using System.Console;
using Nemerle.Utility;
class A
{
public Test(x : int) : string { $"result='$x'" }
}
module Program
{
Main() : void
{
WriteLine(A().Test(123));
}
}
Рисунок 1. Дерево токенов файла после шага PreParse.
Как видите, каждая директива using превратилась в токен Using, хранящий ссылку на GlobalEnv (описывающий список «открытых» пространств имен), а токены класса A и модуля Program разложены по соответствующим токенам LooseGroup.
Точно так же раскладываются по группам и токены методов и других членов типов.
На рисунке 2 приведен фрагмент этого дерева, описывающий метод Test:
Рисунок 2. Фрагмент дерева токенов, описывающий метод Test.
Если смотреть на дерево токенов с высоты «птичьего полета», то оно представляет собой связанный список токенов, некоторые из которых являются групповыми и хранят подсписки. Фактически любая конструкция языка уже после стадии построения дерева токенов помещается в отдельный подсписок, так что задача парсера очень сильно упрощается. К тому же, в случае ошибок в разбираемом коде, парсер может пропустить непонятную группу и попытаться распознать остальные. Это положительно сказывается на качестве сообщений об ошибках.
Парсинг конструкций верхнего уровня (типов)
После формирования дерева токенов наступает пара парсинга. На этом этапе распознаются синтаксические конструкции, причем как встроенные в язык, так и определенные с помощью макросов.
Принцип распознавания синтаксических конструкций, вводимых макросами, очень прост. Если среди токенов встречаются ключевые слова, производится проверка, не является ли данное ключевое слово в данном месте началом одного из «открытых» к этому моменту синтаксических расширений. Если является, то управление передается функции, производящей распознавание синтаксического правила макроса. Итогом работы такой процедуры является ветка AST MacroCall.
Результатом работы парсера является ветки AST. Так что стоит остановиться на этом вопросе отдельно.
AST
По поводу AST у меня есть две новости. Она радостная, а другая грустная. Грустная заключается в том, что фактически одного единого AST не существует. AST состоит из ряда типов, преимущественно вариантов.
Радостная новость заключается в том, что в большинстве случаев, создавая макросы, вам не придется работать с AST на уровне типов. Как для генерации AST, так и для декомпозиции имеющегося AST можно примерять квази-цитирование. Это невероятно упрощает задачу. Многое можно сделать декларативно!
Но все же, чтобы понимать суть происходящего, неплохо было бы познакомиться с типами, составляющими AST.
Можно выделить AST, описывающее типы (описывается вариантом TopDeclaration), AST, описывающее члены типов (описывается вариантом ClassMember), и AST, описывающее выражения (описывается вариантом PExpr).
Варианты TopDeclaration и ClassMember унаследованы от класса DeclarationBase:
[Record]
publicclass DeclarationBase : Located
{
publicmutable name : Splicable;
public mutable modifiers : Modifiers;
public ParsedName : Name { get { name.GetName () } }
public Name : string { get { name.GetName ().Id } }
public GetCustomAttributes () : list[PExpr] { modifiers.custom_attrs }
public Attributes : NemerleAttributes
{
get { modifiers.mods }
set { modifiers.mods = value }
}
public AddCustomAttribute (e : PExpr) : void
{
modifiers.custom_attrs = e :: modifiers.custom_attrs
}
}
Очевидно, что данный класс позволяет веткам AST верхнего уровня (описывающим типы и их члены) содержать имя, модификаторы (например, public или static) и пользовательские атрибуты.
Все классы AST опосредованно или напрямую унаследованы от класса Located, который добавляет поддержку хранения местоположения конструкции в исходном файле. Местоположение описывается структурой Location, которая описывает имя и идентификатор исходного файла (свойства FileIndex : int и File : string), верхнюю и нижнюю координаты (свойства Line, Column, EndLine и EndColumn типа int), а также признак того, был ли данный элемент получен из кода, или сгенерирован компилятором/макросом (свойство IsGenerated : bool).
[Record (Exclude = [_definedIn])]
public variant TopDeclaration : DeclarationBase
{
| Class // Описывает класс
{
mutable t_extends : list[PExpr];
decls : list[ClassMember];
}
| Alias { ty : PExpr; } // Описывает конструкцию type
| Interface // Описывает интерфейс
{
mutable t_extends : list[PExpr];
methods : list[ClassMember]; // only iface_member
}
| Variant // Описывает вариант
{
mutable t_extends : list[PExpr];
mutable decls : list[ClassMember];
}
| VariantOption { decls : list[ClassMember]; } // вхождение варианта
| Macro // Описывает макрос
{
header : Fun_header;
synt : list[PExpr];
expr : PExpr;
}
| Delegate { header : Fun_header; } // Описывает макрос
| Enum // Описывает перечисление
{
t_extends : list[PExpr];
decls : list[ClassMember];
}
publicmutable typarms : Typarms; // Параметры generic-типа/// Если данная декларация вложена в другую декларацию, это свойство
/// содержит ссылку на нее.
/// Это свойство содержит null, если это декларация верхнего уровня.public DefinedIn : TopDeclaration { get { ... } };
publicthis (tp : Typarms) { ... }
publicthis () { ... }
publicoverride ToString() : string { ... }
}
[Record (Exclude = [_env, _tokens, _bodyLocation, _definedIn])]
public variant ClassMember : DeclarationBase
{
| TypeDeclaration { td : TopDeclaration; }
| Field { mutable ty : PExpr; }
| Function
{
header : Fun_header;
mutable implemented : list[PExpr];
mutable body : FunBody;
}
| Property
{
ty : PExpr;
prop_ty : PExpr;
dims : list[Fun_parm]; // parameters of indexer propertyget : option[ClassMember];
set : option[ClassMember];
}
| Event
{
ty : PExpr;
field : ClassMember.Field;
add : ClassMember.Function;
remove : ClassMember.Function;
}
| EnumOption { value : option [PExpr]; }
public SetEnv(env : GlobalEnv) : void { _env = env; }
[Accessor] internal mutable _env : GlobalEnv;
[Accessor] internal mutable _tokens : Token.BracesGroup;
[Accessor] internal mutable _bodyLocation : Location;
/// Это свойство содержит ссылку на тип (TopDeclaration),
/// где определен данный член.
[Accessor] internal mutable _definedIn : TopDeclaration;
/// Доступен только если это экземпляр ClassMember.Function,
/// в котором тело не типизировано.public Body : PExpr
{
get { ... }
set { ... }
}
public IsMutable() : bool { modifiers.mods %&& NemerleAttributes.Mutable }
internal PrintBody (writer : LocatableTextWriter) : void { ... }
publicoverride ToString() : string { ... }
}
Получить экземпляр ClassMember или TopDeclaration можно как создав их явно, так и воспользовавшись квази-цитированием.
Однако тут есть одна особенность. По умолчанию, при разборе квази-цитирования полагается, что цитата будет содержать выражения (PExpr). Поэтому нужно подсказать компилятору, что вы хотите получить AST для конструкции другого рода. Префикс «decl:» позволяет указать компилятору, что ему нужно разглядеть в цитате не выражение, а тип или член типа. Например, следующий макрос демонстрирует добавление в проект типа, описанного средствами квази-цитирования:
macro BuildClass ()
{
def ctx = Nemerle.Macros.ImplicitCTX();
// Описываем класс квази-цитатой. Чтобы компилятор понял, что нужно
// распознавать именно класс, мы добавляем префикс «decl:». def astOfClass = <[decl:internalclass FooBar
{
publicstatic SomeMethod () : void
{
System.Console.WriteLine ("Hello world");
}
}
]>;def builder = ctx.Env.Define(astOfClass);
builder.Compile();
<[ FooBar.SomeMethod () ]> // А это выражения, и префикса не требуется.}
Такой префикс называется «типом цитирования». Вот полный список типов цитирования:
decl – декларация верхнего уровня. Тип или член типа.
fundecl – декларация локальной функции.
case – вхождение оператора match.
parameter – описание параметра функции.
ttype – «типизированная» ссылка на тип. При его использовании цитата должна содержать ссылку на тип. Допустима частичная квалификация (с учетом открытых в месте объявления пространств имен).
Все, кроме последнего, типы цитирования могут быть использованы не только для формирования AST, но и для его декомпозиции (в качестве паттернов в операторе match). ttype не может выступать в качестве паттерна.
Стоит вернуться обратно к процессу парсинга. По окончанию этого процесса для каждого разбираемого файла создается список распознанных AST-типов. Если тип объявлен в коде как partial, для него создается несколько AST (по одному для каждой части). Причем части типа могут находиться в разных файлах (обычно именно так и случается).
Естественно, что работать с отдельными частями типа неудобно. К тому же код надо типизировать. Поэтому на следующем шаге компилятор создает для каждого типа, объявленного в проекте, отдельный класс TypeBuilder, в который и собираются все AST отдельных частей типа.
Вы будете смеяться, но все описанное выше относилось к одной строке функции Run, описанной выше. Вот эта строка:
def trees = List.RevMap(Options.Sources,
fun(x) { ParsingPipeline(LexingPipeline(x)) });
Создание TypeBuilder-ов
На следующем шаге компилятор перебирает все TopDeclaration (т.е. AST типов), полученные на предыдущем шаге, создает TypeBuilder-ы для каждого отдельного типа и добавляет их в дерево пространств имен. За это отвечает следующая строчка метода Run:
foreach (group in trees)
group.Iter(ScanningPipeline);
Все части одного partial-типа помещаются в единый экземпляр TypeBuilder-а. Их члены объединяются в единый список, что позволяет работать с типом как с единым целым, а не возиться с отдельными его частями. Впрочем, список TopDeclaration для partial-типа по-прежнему доступен. Так же доступен список положений (Location) частей partial-типа.
На этом же шаге производится генерация классов для макросов, объявленных в компилируемом проекте, и для делегатов (для них генерируется специальный класс-заглушка, которую позже, во время исполнения, JIT дорабатывает напильником до готовности).
Типизация TypeBuilder-ов
На этом шаге TypeBuilder-ы, созданные на предыдущем шаге, подвергаются «типизации».
На этом шаге выполняется множество важнейших операций, из которых, пожалуй, две самые важные для нас – это «раскрытие» макросов и разрешение типов. За этот шаг отвечает вызов:
Hierarchy.Run();
Он делает следующее:
Создает окружения типов.
Производится связывание типов.
Определяются зависимости наследования между типами.
Проверяется соответствие типов.
Добавляются описания членов (сначала нетипизированные, потом типизированные).
Добавляются специальные методы поддержки сопоставления с образцом в вариантные типы.
Процесс типизации разбит на несколько стадий. Раскрытие макросов производится на разных фазах этого процесса. Эти фазы описываются перечислением MacroPhase:
BeforeInheritance – выполняется перед началом процесса типизации. В этот момент имеется только список TypeBuilder, но в них доступна только информация, полученная в процессе парсинга. К этому моменту иерархия типов еще не построена, и все ссылки на типы еще не разрешены. Все это приводит к тому, что с одной стороны на этой стадии можно производить почти любые модификации в коде, а с другой – недоступна практически никакая информация о типах (доступна только информация, которую можно выудить из нетипизированного AST). Данная фаза замечательно подходит для таких задач, как добавление интерфейсов в список реализуемых интерфейсов, добавление базового класса и для добавления новых типов (к общему списку типов проекта).
BeforeTypedMembers – выполняется перед тем, как члены типов (методы, свойства и поля) будут «связаны» с реальными типами. До стадии WithTypedMembers в описаниях типов фактически лежат нетипизированные выражения (на самом деле там лежат более сложные структуры данных, включающие, в том числе, ссылку на контекст (GlobalEnv), хранящий список «открытых» пространств имен, да и хранятся не строки). Учитывая то, что иерархия типов к этому моменту уже полностью построена, на этой стадии уже можно получить значительно больше информации. И хотя типы параметров и возвращаемых значений еще не «связаны» с реальными типами, но эти связи можно вычислить, используя метод MonoBindType из класса TypeBuilder (хотя это и является по сути хаком, но сами разработчики компилятора используют его на практике). Эта функция использует контекст (GlobalEnv) и AST ссылки на тип, чтобы вычислить ссылку на описание этого типа (напомню, что к этому моменту все описания типов уже находятся в дереве пространств имен). Фаза BeforeTypedMembers очень привлекательна для макроатрибутов и вообще макросов уровня типов, так как позволяет безболезненно добавлять к типам новые члены.
WithTypedMembers – выполняется на самых последних стадиях типизации. Фактически, после этой стадии обрабатывается только тот код, который генерируется компилятором для внутренних нужд и не представляет интереса для прикладного программиста. На этой фазе доступна вся информация о типах. Казалось бы, это самая удобная стадия для работы макроса. Возникает даже вопрос, а зачем козе баян, тьфу ты, зачем нужны другие фазы? Ответ на него прост и одновременно печален. Дело в том, что на сегодняшний момент на этой стадии практически нельзя менять описание типов компилируемого проекта. Попытка добавить новые методы, классы или наследование, а также попытка что-либо изменить натолкнутся на активное сопротивление со стороны компилятора. Таким образом, всю мощь информации о типах, доступную в этой фазе, получится применить только для изменения или генерации кода методов (и других членов типов). Именно поэтому так ценна возможность использования метода MonoBindType, описанная в предыдущем пункте данного перечисления. Таким образом, фаза WithTypedMembers лучше всего подходит для макросов уровня членов типов.
Дальнейшие стадии компиляции
Стадии компиляции, которые идут далее, малоинтересны с точки зрения разработки макросов. Так что я не буду их разбирать. Если вам любопытно, что же происходит далее, вы можете вернуться к листингу 1.
Компиляция и типизация тел методов
В процессе обычной компиляции (т.е. при вызове компилятора, а не под управлением IDE) тела методов разбираются в процессе парсинга тел типов. Это поведение отличается от поведения компилятора при работе под управлением IDE, когда компилятор работает в режиме IntelliSense.
В режиме IntelliSense парсинг кода методов откладывается до тех пор, пока пользователь не запросит информацию о содержимом метода (например, попробует посмотреть подсказку (Tooltip) или попробовать дополнить вводимый идентификатор) или до тех пор, пока не начнется фоновая проверки кода. Фоновая проверка запускается (с небольшой задержкой) после того как файл с кодом открывается в редакторе IDE (или по прошествии некоторого времени после того, как файл был отредактирован).
Если вы хотите, чтобы ваш макрос корректно себя вел в IDE, то надо обязательно учитывать эту особенность. Так, не стоит добавлять классы, которые должны быть доступны посредством IntelliSense, из макросов уровня выражений.
Возможно также специальным образом поддерживать работу в режиме IntelliSense (хотя, конечно, проще делать универсальный код). Чтобы знать, в каком режиме работает компилятор, вы можете обратиться к свойству IsIntelliSenseMode класса ManagerClass, ссылку на который в макросах можно получить следующим образом:
Nemerle.Macros.ImplicitCTX().Manager
Режим восстановления после обнаружения ошибки
По умолчанию, во время процесса типизации, компилятор работает, скажем так, в быстром режиме. В этом режиме он не проводит анализ ошибок, справедливо полагая, что их не будет. Если все же встречается ошибка, то компилятор генерирует исключение RestartInErrorMode, которое отлавливается на верхнем уровне процесса типизации. В этом случае компилятор переключается в режим усиленного выявления ошибок и повторяет процесс типизации.
Код, не учитывающий это поведение, может привести к появлению наложенных ошибок, которые могут сбить с толку прикладного программиста.
Проблема заключается в том, что код макроса может добавить новые типы или изменить описание имеющихся типов. В случае ошибки такой макрос будет выполнен дважды и приведет к созданию дублирующихся описаний.
Чтобы избежать этой, неприятной, ситуации можно или вообще отказаться от добавления/изменения типов из макросов уровня выражения (это оптимальное решение), или, по крайней мере, проверять, что компилятор работает в нормальном режиме, а не в режиме выявления ошибок.
Узнать о том, что компилятор работает в режиме выявления ошибок, можно обратившись к свойству InErrorMode все у того же объекта-менеджера, что использовался для доступа к свойству IsIntelliSenseMode.
ПРЕДУПРЕЖДЕНИЕ
Также стоит обратить внимание на то, что в случае работы в IntelliSense-режиме (IsIntelliSenseMode == true) значение свойства InErrorMode всегда равно true, и повторный проход не делается. Это связано с тем, что в задачи IntelliSense входит выявление ошибок, и с тем, что значительную часть времени код в IDE находится в незавершенном состоянии. Двойной проход при этом только замедлил бы и усложнил бы работу IDE.
Дерево пространств имен (NamespaceTree)
Данная тема не имеет прямого отношения к макросам, но действительно мощные макросы вряд ли могут обойтись без анализа типов, доступных в проекте.
Информация обо всех типах, доступных в проекте (как объявленных непосредственно в нем, так и импортированных из внешних сборок), помещается в дерево пространств имен, или, как его еще называют, дерево типов.
Ниже приведено упрощенное описание этого дерева.
Ветки этого дерева описываются классом Node, вложенным в класс NamespaceTree:
[ManagerAccess]
publicclass NamespaceTree
{
/// Используется для «ленивой» загрузки типов из внешних сборок и/// стирания различий между типами, объявленными в компилируемой /// сборке, и внешними типами.publicvariant TypeInfoCache
{
| No
| Cached { tycon : TypeInfo; }
| CachedAmbiguous { elems : list[TypeInfo] }
| NotLoaded { e : ExternalType; }
| NotLoadedList { elems : list[ExternalType] }
| MacroCall { m : IMacro; }
| NamespaceReference
}
/// Описывает одну ветку дерева пространств имен (дерева типов).publicclass Node
{
public Parent : Node; // Ветка, в которую вложена данная ветка./// Имя данной ветки. Если, скажем, это ветка System.IO.File,/// то данное свойство будет иметь значение «File».
[Accessor(PartName)] name : string;
/// Значение ветки. См. описание типа TypeInfoCache (выше) и описание/// метода EnsureCached(). publicmutable Value : TypeInfoCache;
/// Список дочерних веток.public Children : Hashtable[string, Node] { get; }
/// Гарантирует, что информация о типах для данной ветки полностью /// загружена, разобрана и доступна для анализа универсальными /// средствами./// Дело в том, что информациыя о типах, загружаемых из внешних /// сборок, грузится в «ленивой» манере. При загрузке сборки в начале/// компиляции загружается только список типов, а детальная информация/// о них получается только тогда, когда она запрашивается в первый раз./// При этом типы .NET помещаются в TypeInfoCache.NotLoaded или/// TypeInfoCache.NotLoadedList. Впоследствие, когда требуется получить/// описание этих типов, производится процедура загрузки, в процессе /// которой тип значения ветки изменяется на TypeInfoCache.Cached или/// TypeInfoCache.CachedAmbiguous. Метод EnsureCached как раз и /// производит такую загрузку.public EnsureCached() : void;
/// Возвращает список типов, объявленных в данном проекте, т.е. типов,
/// созданных в процессе парсинга исходных кодов проекта, типов,
/// создаваемых в процессе работы макросов, и типов, генерируемых
/// компилятором (например, для делегатов).public GetTypeBuilders(onlyTopDeclarations : bool) : array[TypeBuilder];
/// Текстовое представление полного имени ветки (так, как оно выводится /// в сообщениях компилятора).public GetDisplayName() : string;
/// Полное имя ветки в виде списка.public FullName : list[string] { get; }
// Говорит, что данная ветка «фальшивая», и является альтернативным
// именем для другого типа.public IsFromAlias : bool { get { name == null } }
/// Очистить список подветок данной ветки. Лучше не вызывать :). public Clear();
/// Получить ссылку на ветку по пути, представленному в виде строки,
/// разделенной точками. Внимание! Если путь не существует, то он будет
/// автоматически создан. Откровенно говоря, по уму такой метод надо было
/// бы назвать как-то вроде «GetNodeByPathOrCreateIt()».public Path (n : string) : Node;
/// То же, что и предыдущий метод, но путь задается списком.public Path (n : list [string]) : Node;
/// Данный метод аналогичен предыдущему, но не создает путь в случае
/// отсутствия искомой ветки, и возвращает не ветку, а ее значение.
/// Надо признаться, что последнее свойство этого метода делает его
/// малоинтересным для практического использования.public TryPath (n : list [string]) : TypeInfoCache;
/// Метод, аналогичный Path(), но не создающий ветку, если она отсуствует.public PassTo (name : list [string]) : Node { ... }
/// Позволяет получить ветку по относительному пути.
/// При этом можно задать сразу несколько корневых веток, начиная от
/// которых будет производиться поиск.
publicstatic PassTo (nss : list [Node], name : list [string]) : Node;
/// Методы LookupType позволяют найти тип по полному пути./// Как и метод Path, они создают пустую ветку, если не могут /// найти требуетмый путь.public LookupType (split : list [string], args_count : int)
: option[TypeInfo];
public LookupTypes (split : list [string], for_completion = false)
: list[TypeInfo];
public LookupValue() : option[TypeInfo];
public LookupMacro(split : list[string]) : option[IMacro];
// Ряд не важных методов и свойств опущен...
}
/// Корневая ветка дерева простанств имен (свойство имеет имя NamespaceTree).
[Accessor] internal namespace_tree : Node;
// Этот метод позволяет сделать то, что официально делать не // разрешается... а именно динамически добавить макрос.public AddMacro (split : list[string], m : IMacro) : void;
publicstatic AddMacro (ns : Node, m : IMacro) : void;
// Ряд не важных методов и свойств опущен...
}
Из комментариев к коду должно быть понятно предназначение тех или иных членов. Смысл же данных классов прост... Классы Node образуют дерево. Свойство Children содержит ассоциативный список относительных имен подветок, соотносимых с самими подветками. Ветка может быть описанием типа, содержать описание нескольких типов (если возникла неоднозначность), быть описанием макроса или быть веткой пространства имен. Кроме того, ветка может хранить ссылку на незагруженное описание типов из внешних сборок. Перед работой со значением ветки необходимо вызвать метод EnsureCached. Это приведет к загрузке информации о типах, если она до этого еще не была загружена.
Обратите внимание, что вложенные типы не попадают в это дерево! Чтобы получить их список, нужно обратиться к методу GetNestedTypes класса TypeBuilder.
Заключение первой части
Задача этой части – дать вам базовую информацию, которая облегчит глубокое понимание работы макросистемы (да и всего компилятора) Nemerle. В ней затрагиваются многие тонкие аспекты работы компилятора. Не беда, если вы не запомнили их все сразу. Если что, вы всегда можете вернуться к этой части и прочесть требуемый раздел снова.
В следующей части я расскажу о создании конкретных типов макросов, о том, какие задачи проще решать теми или иными видами, и приведу примеры каждого из видов макросов.
Эта статья опубликована в журнале
RSDN Magazine
#1-2007. Информацию о журнале можно найти здесь