 Оценка 1315
[+1/-1]
Оценка 1315
[+1/-1]

 Оценить
Оценить 






| Оценка 1315
[+1/-1]
Оценить
|
Не так давно мы познакомили вас, уважаемые читатели, с новым, и, на наш взгляд, очень перспективным языком Nemerle. Однако понять и оценить перспективность этого языка не так-то просто. Ведь если вы не знакомы с подходами, которые предлагает Nemerle, то для вас он будет выглядеть еще одной разновидностью языка программирования, мало чем отличающейся от тех языков, к которым вы привыкли. Эта статья ставит своей целью показать, чем, и главное, как Nemerle может помочь вам в вашей повседневной работе.
Хотя статья опирается на Nemerle, она может оказаться интересной и для тех, кто не интересуется этим языком, но заинтересован в освоении функционального программирования и аспектах, с ним связанным.
Прежде чем начать рассказывать о том, что Nemerle дает программисту, мне очень хочется привести цитату из статьи Пола Грейхема «Lisp: побеждая посредственность». Конечно, Пол Грейхем является проповедником Lisp-а, а о Nemerle он вообще на тот момент и слышать не мог. Но, тем не менее, его слова как нельзя более точно описывают, почему многим программистам трудно понять и оценить более мощный язык (полную версию статьи вы можете найти по адресу http://www.nestor.minsk.by/sr/2003/07/30710.html).
Что же в Lisp-е такого прекрасного? Если он такой замечательный, почему его не используют все? Казалось бы, риторические вопросы, но на самом деле на них есть прямые ответы. Lisp настолько хорош не тем, что в нем есть некое волшебное качество, видимое только его приверженцам, а тем, что он — самый мощный язык программирования из существующих.
И причина того, что все вокруг пишут не на Lisp'е, заключается в том, что выбор языка программирования — вопрос не только технологии, но также и привычки, а ничто не меняется так медленно, как привычки. Конечно, оба эти тезиса требуют разъяснений.
Я начну с шокирующего утверждения: языки программирования отличаются друг от друга своей мощностью.
По крайней мере, мало кто будет спорить, что высокоуровневые языки мощнее машинного языка (машинный код и ассемблеры – VladD2). Большинство программистов согласятся, что, как правило, программировать стоит не на машинном языке, а на каком-нибудь языке высокого уровня, переводя программу в машинный код с помощью компилятора. Сейчас эта идея получила даже аппаратное воплощение — с восьмидесятых годов команды процессоров разрабатываются скорее для компиляторов, чем для программистов.
Каждый знает, что писать всю программу вручную на машинном языке — ошибочно. Но гораздо реже понимают, что существует и более общий принцип: при наличии выбора из нескольких языков ошибочно программировать на чем-то, кроме самого мощного, если на выбор не влияют другие причины (VladD2: выделено мной, мне кажется эта мысль очень важна, ведь если, например, более мощный язык не обеспечивает приемлемой производительности, то его выбор также будет неоправданным).
Все языки одинаково мощны, если рассматривать их с точки зрения эквивалентности машине Тьюринга, но это не та мощь, которая важна программисту. (Никто ведь не хотел бы программировать машину Тьюринга). Мощь языка, в которой заинтересован программист, возможно, трудно определить формальными методами, однако одно из объяснений этого понятия заключается в свойствах, которые в менее мощном языке можно получить, только написав на нем интерпретатор для более мощного языка. Если в языке A есть оператор для удаления пробелов из строк, а в языке B его нет, это не делает A более мощным, чем B, так как в B можно написать процедуру, которая делала бы это.
Но, скажем, если язык A поддерживает рекурсию, а B — нет, это нечто, что нельзя исправить написанием библиотечных функций (VladD2: впрочем, бывает так, что средствами языка B в принципе можно решить проблему, но решение ее столь сложно, что решение это можно назвать чисто теоретическим).
Есть много исключений из этого правила. Если вы пишете программу, которая должна тесно взаимодействовать с программой, написанной на определенном языке, возможно, окажется разумным писать новую программу на том же языке.
Если вы пишете программу, которая должна делать что-то очень простое, вроде численной обработки больших массивов данных или манипуляций с битами, можно использовать язык не самого высокого уровня абстракции, тем более что программа будет слегка быстрее (VladD2: и то не факт).
Если вы пишете короткую программу, которую используете один раз и выбросите прочь, возможно, следует использовать тот язык, который имеет лучшие библиотечные функции для данной задачи.
Но в целом для программного обеспечения нужно использовать самый мощный (и приемлемо эффективный) язык из всех доступных. Отличный от этого выбор — это ошибка такого же рода, как программирование в машинных кодах, хотя и с меньшими негативными последствиями.
Понятно, что уровень машинного языка очень низок. А высокоуровневые языки часто рассматриваются как одинаковые, по крайней мере, так принято считать. Но это не так. Технический термин "язык программирования высокого уровня" не обозначает ничего определенного. Не существует четкой границы между множеством "машинных" языков с одной стороны, и множеством "высокоуровневых" – с другой. Языки распределены в континууме (возможно, не просто континууме, а некой структуре, уменьшающейся кверху; важна здесь не форма, а сама идея о том, что существует, по крайней мере, частичный порядок) абстрактности, начиная от самых мощных "языков высокого уровня" вниз к "машинным языкам", которые, в свою очередь, тоже отличаются друг от друга по мощности.
Возьмем Cobol. Cobol — язык высокого уровня, так как компилируется в машинный язык. Но станет ли кто-нибудь утверждать, что по мощности Cobol эквивалентен, скажем, Python-у? (VladD2: учитывая свой опыт общения на форумах RSDN скажу, что, несомненно, станет:) ) Возможно, он ближе к машинному языку, чем Python.
А как насчет Perl четвертой версии? В Perl 5 в язык были добавлены лексические замыкания (lexical closures). Большинство Perl-хакеров согласятся, что Perl 5 мощнее, чем Perl 4. Но раз вы это признали, вы признали, что один высокоуровневый язык может быть мощнее другого. Из этого неизбежно следует, что использовать нужно самый мощный язык.
Впрочем, из этого утверждения редко делается вывод. Программисты старше определенного возраста редко меняют язык по своей воле. Они будут считать достаточно хорошим тот язык, к которому привыкли.
Программисты очень привязываются к своим любимым языкам, а я не хочу оскорбить ничьи чувства, поэтому я объясню свою позицию, используя гипотетический язык с названием Блаб.
Блаб попадает в середину континуума абстрактности. Это не самый мощный язык, но он мощнее, чем Cobol или машинный язык.
И на самом деле, наш гипотетический программист на Блабе не будет использовать ни Cobol, ни машинный код. Для машинных кодов есть компиляторы. Что же касается Cobol-а, наш программист не знает, как на этом языке вообще что-то можно сделать. В Cobol-е ведь даже нет возможности X, присутствующей в Блабе!
Когда наш гипотетический Блаб-программист смотрит вниз на континуум мощности языков, он знает, что смотрит вниз. Менее мощные, чем Блаб, языки явно менее мощны, так как в них нет некой особенности, к которой привык программист. Но когда он смотрит в другом направлении, вверх, он не осознает, что смотрит вверх. То, что он видит, — это просто "странные" языки. Возможно, он считает их одинаковыми с Блабом по мощности, но со всяческими сложными штучками. Блаба для нашего программиста вполне достаточно, так как он думает на Блабе (VladD2: выделено мной).
Когда мы поменяем точку обзора программиста, используя любой язык программирования выше по континууму мощности, мы обнаружим, что теперь программист смотрит на Блаб сверху вниз. «Как же можно что-то сделать, используя Блаб? В нем отсутствует даже конструкция Y!»
Используя метод индукции, приходишь к выводу, что только те программисты, которые понимают самый мощный язык, в состоянии осознать полную картину разницы в мощности между различными языками (видимо, именно это имел в виду Эрик Реймонд, когда говорил о том, что Lisp сделает вас лучше как программиста). Следуя парадоксу Блаба, нельзя доверять мнению других: другие программисты довольны тем языком, который используют, потому что этот язык определяет способ их программистского мышления.
Я понял это на собственном опыте, когда учился в старших классах школы и писал программы на Бейсике. Этот язык не поддерживал даже рекурсию. Трудно представить написание программ без рекурсии, но в то время мне это было не нужно. Я думал на Бейсике. Я был спец. Мастер всего, что изучил.
Пять языков, которые советует хакерам Эрик Реймонд, находятся в разных точках континуума мощности, и то, где они находятся относительно друг друга, — тонкий вопрос. Я скажу, что Lisp находится на вершине континуума. И чтобы поддержать это утверждение, я скажу о том, чего мне не хватает, когда я смотрю на остальные пять языков. Как же можно что-то сделать с ними, думаю я, без свойства Z? И самое большое Z — это макросы. (VladD2: Рассматривать макросы как отдельное свойство — это немного неправильно. На практике их польза увеличивается такими свойствами Lisp'а, как лексические замыкания и частичная параметризация (rest parameters) – аналогичная возможность в Nemerle назевается «частичное применение (partial application)).
Во многих языках есть что-то, называющееся макросом. Но макросы в Lisp'е уникальны (VladD2: на сегодня это так, только если глядеть на другие языки с высоты Lisp-а, но об этом позже). То, что делают макросы, имеет отношение, верите вы или нет, к скобкам. Создатели Lisp'а добавили все эти скобки в язык не для того, чтобы отличаться от других. Скобки в Lisp'е имеют особый смысл, они — внешнее свидетельство фундаментальной разницы между Lisp'ом и другими языками.
Программа на Lisp'е состоит из данных. И не в том тривиальном значении, что исходные файлы содержат символы, а строки — один из типов данных, поддерживаемых языком. После прочтения программы парсером Lisp-код состоит из готового к использованию дерева структур данных.
Дело не в том, что в Lisp'е странный синтаксис, скорее, его нет вообще. Программы пишутся в синтаксических деревьях, которые в других языках генерируются парсером во время разбора исходного текста. Эти синтаксические деревья в Lisp'е полностью доступны вашим программам, и вы можете писать программы, которые изменяют эти деревья. В Lisp'е подобные программы называются макросами. Это программы, которые пишут программы.
Программы, которые пишут программы? И когда же такое может понадобиться?
Не очень часто, если вы думаете на Cobol'е. И постоянно, если вы думаете на Lisp'е. Было бы удобно, если бы я дал пример мощного макроса и сказал бы: "Вот! Смотрите!". Но если бы я и привел пример, для того, кто не знает Lisp, он выглядел бы как белиберда. Рамки данной статьи не позволяют изложить все необходимое для понимания подобного примера. В книге Ansi Common Lisp я старался излагать материал как можно быстрее, но даже так я не добрался до макросов раньше страницы 160.
Однако мне кажется, что я могу дать убедительный аргумент. Исходный текст редактора Viaweb на 20-25 процентов состоял из макросов. Макросы сложнее писать, чем обычные функции Lisp'а, и считается дурным тоном использовать их там, где можно без них обойтись. Поэтому каждый макрос в той программе был необходим. Это значит, что примерно 20-25 процентов кода в программе делают то, что нельзя просто сделать на других языках.
Как бы скептически ни относился Блаб-программист к моим заявлениям о таинственной мощи Lisp'а, это должно его заинтересовать. Мы не писали этот код для своего собственного развлечения. Мы были маленькой компанией, и программировали так, как только могли, чтобы возвести технологический барьер между нами и нашими конкурентами.
Пытливый читатель может задаться вопросом, а нет ли здесь взаимосвязи? Некоторая большая часть кода делала нечто, что очень сложно сделать на других языках. Получившееся в результате программное обеспечение делало то, что программное обеспечение наших соперников делать не могло. Возможно, между этими фактами есть связь. Я советую вам подумать в этом направлении. Возможно, это все не просто старческие бредни.
К чему я привел этот фрагмент? Дело в том, что если вы думаете на C# или, скажем, на Delphi, или даже на C++, то без желания понять и некоторых усилий с вашей стороны вы окажетесь в роли того самого Блаб-программиста, смотрящего на более мощный язык и видящего в нем не более чем кучу непонятных заморочек.
Грэхем немного лукавит. Реальная жизнь сложнее описанной им модели. Языки программирования невозможно четко расположить на шкале, где нулем является машинный язык, а максимальным значением – «самый-самый» язык программирования. Фактически, есть много языков, которые превосходят другие в том или ином аспекте, и уступают в прочих. Тот же Lisp не безгрешен. Причем достоинства языка зачастую являются причиной его недостатков. Так, расплатой за мощные макросы является совершенно ужасный синтаксис без приоритетов операторов (да и без операторов как таковых), без внятно выделяющиеся синтаксических конструкций и т.п. Причем макросы Lisp-а, ко всему прочему, еще и ограничены в своих возможностях, так как не позволяют при своей работе использовать информацию о типах и иным образом взаимодействовать с компилятором (его в большинстве случаев просто нет).
Однако для нас сейчас все это не важно. Для нас важно только то, что для осознания мощности языка нам требуется сломать наши стереотипы мышления и попытаться по-новому взглянуть на, казалось бы, привычные вещи.
Вспомните те времена, когда вы изучали что-то действительно новое для вас. Помните напряжение мозга, возникающее в тщетных попытках понять что-то концептуально новое? А помните то чувство удивленного восторга после того, как вы смогли понять это новое? Помните слова: «Боже, как это просто! И чего я не мог тут понять?!»?
То же самое происходит, когда мы сталкиваемся с новыми приемами программирования и тем более с новыми парадигмами. И чтобы упростить восприятие нового, лучше всего рассматривать его на примерах. Именно этим мы с вами и займемся в этой статье. Но перед этим давайте рассмотрим список возможностей, присутствующих в Nemerle и (скорее всего) отсутствующих в привычных вам языках.
Для начала приведу перевод термина «первоклассный объект» (First-class object) из Википедии:
http://en.wikipedia.org/wiki/First_class_object
В компьютерной области, первоклассный объект (или значение, сущность, гражданин) в контексте конкретного языка программирования – это сущность, которую можно использовать в коде без ограничений (по сравнению с другими объектами в том же языке). В зависимости от языка это может значить, что первоклассный объект:
От себя могу сказать что, пожалуй, главным в понятии «первоклассный объект» является то, что им можно полноценно манипулировать (и манипулировать удобно).
Большинство современных языков рассматривают функцию как почти первоклассный объект. Казалось бы, мы можем передавать функции (ссылки на них) в другие функции, возвращать из них и даже помещать в структуры данных (это называется поддержкой функций высшего порядка – ФВП), но к сожалению мы все еще кое в чем ограничены. Пожалуй, ближе всего (из господствующих (mainstream) языков) к использованию функций как первоклассных объектов подошел C# 2.0. Однако и в нем манипулировать функциями не очень удобно. К тому же, по сравнению с другими подходами, подход, основанный на манипуляции функциями, порождает более медленный код. Nemerle предоставляет более широкий набор возможностей манипуляции функциями. Причем манипуляция функциями в этом языке выглядит более просто и естественно. Так, в C# мы, в сущности, манипулируем не функциями, а делегатами, которые являются отдельными объектами, инкапсулирующими ссылку на функцию и ее контекст. При этом делегаты обладают некоторой избыточностью (они позволяют ссылаться более чем на одну функцию, и каждое объявление делегата вводит новый тип), которая затрудняет манипуляцию функциями.
Давайте же посмотрим, что можно делать с функциями в Nemerle, а потом разберем, что это дает на практике.
Nemerle позволяет:
Вы что-то не поняли из этого списка? А возможно, вы все поняли, но не понимаете, что все это может дать на практике? Сейчас мы последовательно разберем каждую из перечисленных возможностей и рассмотрим, как их можно использовать на практике и что все это дает.
Начнем с локальных функций и замыканий. Многие из вас уже сталкивались с локальными функциями в Паскале и его потомках. Главное отличие локальных функций Nemerle от их аналогов в Паскале-подобных языках – это то, что локальные функции могут располагаться в любом месте метода и использовать объявленные выше переменные и функции. Это позволяет производить декомпозицию сложных методов, причем делать это проще и с меньшими затратами сил, нежели при использовании для этого методов и объектов.
Замыкания родились очень давно. Это произошло еще во времена раннего Lisp-а. Однако до недавнего времени они упорно обходили стороной господствующие языки программирования.
Фактически первым из господствующих ЯП, в котором появились замыкания, стал C# 2.0. Правда, доступны они только в рамках анонимных методов, которые ввиду неудобного синтаксиса, необходимости манипулировать анонимными методами исключительно через делегаты и относительной медленности делегатов, применяются на практике довольно редко. Кроме того, бледное подобие замыканий можно наблюдать в lambda из библиотеки Boost (C++). Но из-за сильной ограниченности ее вряд ли можно рассматривать всерьез.
Nemerle поддерживает замыкания для лямбд (аналогов анонимных методов C#, но с человеческим лицом, в C# 3.0 тоже появится более удобный синтаксис, который так и будет называться – лямбдой) и локальных функций.
Наличие замыканий вкупе с локальными функциями и лямбдами позволяет как бы передавать куски локального кода в другие функции, изменяя тем самым их поведение.
Это позволяет выполнять декомпозицию кода не на уровне методов и классов, а на куда более детальном уровне, вплоть до отдельных выражений и операторов. Используя замыкания и локальные/анонимные функции мы можем передавать в другие функции части алгоритмов, тем самым создавая локальные специализации этих методов.
| ПРИМЕЧАНИЕ Вообще говоря, многие подходы функционального программирования можно использовать в не функциональных языках, но делать это настолько неудобно, что результат обычно бывает плачевным. |
Я долго думал, какие примеры использовать для демонстрации преимущества функционального подхода и пришел к выводу, что лучше всего воспользоваться идей Кернигана. В своей книге «The C Programming language» он в качестве примеров приводил реализацию функций из стандартной библиотеки языка C.
Пожалуй, первым случаем применения ФВП в моей жизни была функция qsort (функция быстрой сортировки). Вот ее объявление на C++:
void qsort(
void *base,
size_t num,
size_t width,
int (__cdecl *compare)(constvoid *, constvoid *)
);
|
В последнем своем параметре эта функция получает ссылку на другую функцию – compare. Функция compare применяется в ходе выполнения алгоритма быстрой сортировки для сравнения элементов сортируемого массива.
Аналогичная функция имеется в .NET Framework 1.x:
public
static
void Sort(Array array, IComparer comparer)
|
Здесь вместо функции сравнения используется интерфейс IComparer. Использование объекта-компаратора вместо простой ссылки на функцию является не очень удобным решением.
| ПРИМЕЧАНИЕ В Java это подвинуло к созданию множества интерфейсов содержащий по одному методу, для облегчении создания частных реализаций таких методов в язык была ведена возможность создать локальные и даже анонимные классы. |
Поэтому в .NET 2.0 была добавлена следующая версия функции сортировки:
// Объявление делегата.
public
delegate int Comparison<T>(T x, T y);
publicstaticvoid Sort<T>(
T[] array,
Comparison<T> comparison
)
|
Эта функция использует для сравнения элементов делегат. Это позволяет использовать расширенные возможности C# 2.0 для объявления функций сравнения по месту:
Person[] persons = new Person[] { new Person("Иванов", "Иван"), new Person("Петров", "Петр"), new Person("Иванов", "Петр") }; // Сортируем по фамилии... Array.Sort(persons, delegate(Person p1, Person p2) { return p1.LastName.CompareTo(p2. LastName) }); ... // Сортируем по имени... Array.Sort(persons, delegate(Person p1, Person p2) { return p1.FirstName.CompareTo(p2.FirstName) }); ... |
Какие проблемы есть у этого кода? Во-первых, код несколько длинноват. Во-вторых, он будет работать медленнее аналогичного варианта, использующего объект-компаратор.
В Nemerle вместо делегатов можно использовать функциональный тип. В отличие от делегатов, его не нужно объявлять отдельно, и не требуется создавать его экземпляров. Любая функция (в том числе и лямбда) с подходящей сигнатурой может быть передана в параметр функционального типа. Вот как будет выглядеть аналогичная функция сортировки на Nemerle:
public
static
void Sort[T](ary : array[T], comparison : T * T -> int);
|
T * T -> int – это описание функционального типа. Функция, соответствующая этому типу, должна принимать два параметра типа T и возвращать целочисленное значение.
А вот так выглядит применение данной функции (пример полностью аналогичен коду на C#):
[Record] class Person { public LastName : string; public FirstName : string; public override ToString() : string { $"($LastName? $FirstName)" } } def persons = array[ Person("Иванов", "Иван"), Person("Петров", "Петр"), Person("Иванов", "Петр") ]; // Сортируем по фамилии... Sort(persons, (p1, p2) => p1.LastName.CompareTo(p2.LastName)); ... // Сортируем по имени... Sort(persons, (p1, p2) => p1.FirstName.CompareTo(p2.FirstName)); ... |
Не знаю как вам, а на мой взгляд, и определение функции, и ее использование выглядят приятнее. Причем скорость вызова функциональных объектов выше, чем у делегатов, и даже выше, чем у интерфейсов. Так что можно смело использовать их всюду. Накладные расходы будут минимальны.
Многие могут задаться вопросом «почему же скорость вызова функционального объекта выше, чем у интерфейса?». Это происходит из-за того, что функциональные объекты преобразуются компилятором Nemerle в классы с виртуальным методом apply(...), список параметров которого аналогичен списку параметров лямбды. Так, если в коде вы воспользовались лямбдой или частичным применением оператора, как в следующем примере:
... ary.Sort(_ > _); |
компилятор сгенерирует класс вида:
private
sealed
class _N__N_l3506_3623 : Function<int, int, bool>
{
publicsealedoverride apply(_N_3621 : int, _N_3622 : int) : bool
{
_N_3621 > _N_3622;
}
}
|
и следующим образом модифицирует код программы:
def function1 : Function[int, int, bool] = _N__N_l3506_3623();
ary.Sort(function1);
|
Таким образом, скорость вызова функционального объекта соответствует скорости вызова виртуального метода (в перспективе JIT-компилятор .NET или компилятор Nemerle могут оптимизировать этот вызов, заменяя его не виртуальным или вообще устраняя).
Виртуальный же метод в .NET быстрее вызова метода интерфейса и тем более быстрее вызова делегата. Разница эта не так велика. Она варьируется, в зависимости от версии .NET Framework и марки процессора, в пределах от нескольких процентов (для .NET Framework 2.0.50727.308 с маркетинговым названием .NET 3.0) и Core 2 Duo, до 2-3 раз в более ранних версиях .NET Framework и на более слабых процессорах. Подробности того, почему скорость вызова виртуальных методов в .NET выше, чем скорость вызова методов интерфейсов и делегатов, выходит за рамки этой статьи. Вы можете найти их на форумах и в статьях на RSDN.ru.
Я провел смелый научный эксперимент, суть которого заключалась в измерении скорости быстрой сортировки с использованием разных типов компараторов. Вот результаты этого теста:
Framework version: 2.0.50727.308 -------------------------------------------------- Test Sort Fun took: 00:00:02.0639765 Test OK. Test Sort Delegate took: 00:00:02.5174177 Test OK. Test Sort Interface took: 00:00:02.2520124 Test OK. Test Sort Int took: 00:00:01.3553026 Test OK. Test Array.Sort took: 00:00:01.2027735 Test OK. Test Array.Sort + Delegate took: 00:00:03.2673144 Test OK. |
Здесь «Sort Fun» это тест, использующий для сравнения элементов функциональный объект, «Sort Delegate» – делегат, «Sort Interface» – объект-компаратор, используемый через интерфейс, «Sort Int» – мономорфная реализация сортировки для массива целых, «Array.Sort» – результат использования встроенной в .NET Framework функции (без компаратора, написанной на C++), а «Array.Sort + Delegate» – использование встроенной функции с делегатом в качестве компаратора (в данном случае это C#-реализация). Исходные коды теста можно найти по ссылке: http://rsdn.ru/Forum/Message.aspx?mid=2323364&only=1.
Еще больше улучшить читаемость кода можно, явно объявив функции-компараторы:
def cmpByLastName(p1, p2) { p1.LastName.CompareTo(p2.LastName) }
def cmpByFirstName(p1, p2) { p1.FirstName.CompareTo(p2.FirstName) }
...
Sort(persons, cmpByLastName);
...
Sort(persons, cmpByFirstName);
...
|
При этом код становится самодокументируемым, и необходимость в комментариях отпадает.
Точно так же можно определить специализированные функции сортировки (ведь мы можем обращаться с функциями так же, как с любыми другими объектами!).
В общем, мы можем устранять дублирование кода и производить его декомпозицию на любом, даже самом микроскопическом уровне.
Кроме того, функциональные типы автоматически приводятся к делегатам (и наоборот). Это позволяет использовать уже имеющиеся в .NET Framework методы.
Однако приведенное использование функциональных объектов является самым простым случаем их использования. Вот более сложный пример, демонстрирующий использование замыканий. Предположим, что у нас есть эталонный экземпляр класса Person, и нам нужно узнать, есть ли в неком списке другой экземпляр с таким же именем и фамилией. Если язык не поддерживает замыканий, то информацию об этом объекте придется поместить в специализированный объект компаратор. Для этого придется создать специальный класс, его экземпляр и поместить туда эталонный экземпляр Person. Используя замыкания, то же самое можно сделать по месту:
def persons = array[
Person("Иванов", "Иван"),
Person("Петров", "Петр"),
Person("Иванов", "Петр")
];
def x = Person("Иванов", "Петр");
WriteLine(persons.Exists(y => y.LastName == x.LastName
&& y.FirstName == x.FirstName));
|
Этот код выведет на консоль true, так как в массиве есть искомый элемент. Основная суть этого кода заключается в следующем фрагменте:
y => y.LastName == x.LastName && y.FirstName == x.FirstName |
Переменная «y» – это параметр лямбда-функции (анонимной функции, объявленной по месту). Он будет поочередно сопоставляться с каждым элементом массива. А переменная «x» захватывается из внешнего контекста. В конечном итоге вместо приведенного фрагмента получается функция, замкнутая на контексте, в котором она определена. Это позволяет ей использовать все видимые в этом месте переменные. Такую функцию называют лексически замкнутой, или просто замыканием.
Конечно, лексическое замыкание – это виртуальное понятие для человека. Фактически компилятор тем или иным способом переписывает код. Компиляторы Nemerle и C# 2.0-3.0 при подобном переписывании создают скрытые методы (если замыкание использует только члены текущего класса) или отдельный класс (если замыкания ссылаются на локальные переменные). Во втором случае локальный код переписывается так, чтобы он вместо локальных переменных использовал переменные экземпляра класса. Этот экземпляр также добавляется компилятором. Ссылка на него помещается в локальную переменную.
В принципе, компиляторы могут поступать и более интеллектуально. Если удастся определить, что функция используется только для передачи другой функции, и можно произвести инлайнинг этой другой функции (или создать специализированный вариант этой другой функции), то компилятор может полностью избавить код от накладных расходов, связанных с вызовом функций. Уверен, что рано или поздно эта оптимизация обязательно появится. Однако и без этой оптимизации накладные расходы на замыкания не так велики. На практике заметить их невооруженным взглядом совершенно невозможно.
В библиотеках Nemerle существует множество функций, принимающих уточняющие функции в качестве параметров. Особенно они удобны при работе со списками и массивами. Вот наиболее употребляемые функции высшего порядка (принимающие уточняющие функции) из класса list[T]:
// «Итерация». Вызвает функцию для каждого элемента коллекции.
public Iter(f : T -> void) : void// То же, что и предыдущая функция, но в функцию передается индекс элемента.public IterI(mutable acc : int, f : int * T -> void) : void// Позволяет отобразить один список в другой. Для преобразования// элемента в элемент другого типа вызывается уточняющая функция.public Map[T2](f : T -> T2) : list[T2]
// «Свертка». Уточняющая функция вызывается последовательно для// каждого элемента и позволяет «накапливать» информацию.// Например, с помощью этой функции можно подсчитать сумму элементов:// WriteLine([1, 2, 3, 4, 5].FoldLeft(0, _ + _));public FoldLeft[T2](acc : T2, f : T * T2 -> T2) : T2
// То же, что и предыдущая функция, но свертка производится в обратную сторонуpublic FoldRight[T2](acc : T2, f : T * T2 -> T2) : T2
// Группирует элементы списка в подсписки в соотвествии с критерием,// определяемым уточняющей функцией.public Group(cmp : T * T -> int) : list[list[T]]
// Возвращает true, если для всех элементов предикат возвратил true.// Например:[2, 4, 6, 8].ForAll(x => x % 2 == 0)// вернет true, так как все элементы списка - четные.public ForAll(predicate : T -> bool) : bool// Эта функция возвращает true, если хотя бы для одного элемента// предикат вернет true.public Exists(predicate : T -> bool) : bool// Находит первый элемент, для которого предикат вернет true.public Find(predicate : T -> bool) : option[T]
// То же, что и в предыдущем случае, но при неудаче возвращает// значение по умолчанию.public FindWithDefault(default : T, pred : T -> bool) : T
// Возвращает список, состоящий из элементов исходного списка, для// которых предикат вернул true.public FindAll(predicate : T -> bool) : list[T]
// Подсчитывает количество элементов, для которых предикат вернет true.public FilteredLength(predicate : T -> bool) : int// Синоним для функции FindAll.public Filter(predicate : T -> bool) : list[T]
// Разбивает список на два в соответствии с критерием, заданным функцией.public Partition(predicate : T -> bool) : list[T] * list[T]
// Сортирует список, используя для сравнения элементов уточняющую функцию.public Sort(cmp : T * T -> int) : list[T]
// Возвращает true, если список отсортирован в соответствии с критерием,// задающимся уточняющей функцией.publicstatic IsOrdered[T](this lst : list[T], great : T * T -> bool) : bool// Преобразовывает список в массив. Для преобразования элементов вызывается// уточняющая функция.public MapToArray[T2](f : T -> T2) : array[T2]
|
Это неполный список, к тому же вы можете расширять его самостоятельно. С использованием методов расширения это делается элементарно.
using System;
using System.Console;
using Nemerle.Utility;
// Помещение ссылки на метод в переменную. Метод WriteLine перегружен, так что
// необходимо указать, на какой именно перегруженный вариант требуется
// получить ссылку.
def f = WriteLine : string -> void;
f("Вызов функции через ссылку");
// Частичное применение функции. def f = WriteLine(_);
f("Частичное применение функции");
// Другой вариант частичного применения. В этот раз первому параметру // назначен строковый литерал.def f = WriteLine("Еще один вариант - '{0}'", _);
f("частичного применения функции");
// Частичное применение, захватывающее переменную из локального контекста.// В этом примере первому параметру назначается переменная // formatFromOuterContext. Изменение значения этой переменной даже // после создания функционального объекта все равно будет приводить к// изменению значения, передаваемого методу WriteLine.
// Причем вы можете передать f в любой метод или присвоить полю некоторого
// класса, и все равно эта переменная будет доступна. Это происходит
// вследствие того, что компилятор заменяет переменную на поле
// фунционального объекта.mutableformatFromOuterContext = "{0} с замыканием на внешний контекст!";
def f = WriteLine(formatFromOuterContext, _);
f("Частичное применение функции");
formatFromOuterContext = "Замыкание - забавная вещь :) – '{0}'";
f("повторный вызов");
def lst = [1, 2, 4, 6, 9];
mutablesum0 = 0;
// Лямбда с одним параметром (и замыканием на внешнюю переменную).
lst.Iter(x => sum0 += x);
WriteLine($"sum0 = $sum0");
def lst = [1, 2, 4, 6, 9];
def sum1 = lst.Fold(0, (x, y) => x + y); // Лямбда с двумя параметрами.
WriteLine($"sum1 = $sum1");
def lst = [1, 2, 4, 6, 9];
def sum2 = lst.Fold(0, _ + _); // Частичное применение оператора «+»
WriteLine($"sum2 = $sum2");
def lst = [1, 2, 4, 6, 9];
def lst = lst.Map(_.ToString());// Частичное применение метода.def sum3 = lst.Fold("", _ + _); // Частичное применение оператора «+».
WriteLine($"sum3 = '$sum3'");
|
Этот код выводит на консоль:
Вызов функции через ссылку Частичное применение функции Еще один вариант - 'частичного применения функции' Частичное применение функции с замыканием на внешний контекст! Замыкание - забавная вещь :) - 'повторный вызов' sum0 = 22 sum1 = 22 sum2 = 22 sum3 = '96421' |
| СОВЕТ Компилятор Nemerle считает, что исходный файл имеет кодировку UTF-8. Так что если вы будете пробовать запустить этот пример под Microsoft VS, не забудьте пересохранить файл с кодом «File -> Save ИмяФайла.n as ...» и в выпадающем списке на кнопке Save выбрать пункт «Save with Encoding...», а в выпадающем списке выбрать «Encoding» пункт «Unicode (UTF-8 with signature) – Codepage 65001». |
Функции высшего порядка могут применяться не только в библиотеках, но и в прикладном коде. Вкупе с замыканиями они могут избавить вас от дублирования кода и сделать код более читабельным. Единственное, что вам придется сделать – это задуматься над тем, как и где их лучше использовать.
Ниже приведен пример функции, из проекта интеграции Nemerle в VS .NET, проверяющей парность скобок:
def isBraceMatch()
{
def lex = engine.GetLexer(_source);
def stack = Stack();
stack.Push(Token.EndOfFile());
def scan(toc : Token)
{
| EndOfFile => stack.Count == 1
| BeginBrace // {
| BeginRound // (
| BeginSquare // [
| BeginQuote => // <[
stack.Push(toc);
scan(lex.GetToken())
| EndBrace => check(_ isToken.BeginBrace)// }
| EndRound => check(_ isToken.BeginRound)// )
| EndSquare => check(_ isToken.BeginSquare) // ]
| EndQuote => check(_ isToken.BeginQuote) // ]>
| _ => scan(lex.GetToken());
}
and check(predicate)
{
if (stack.Count > 0 && predicate(stack.Peek()))
{
stack.RemoveLast();
scan(lex.GetToken())
}
elsefalse
}
scan(lex.GetToken());
}
|
| ПРИМЕЧАНИЕ Конструкция and применена в данном примере вместо конструкции def. Это позволяет объявленной таким образом локальной функции быть видимой в предыдущей локальной функции. |
Обратите внимание на код, выделенный красным. Это вызов определенной чуть ниже локальной функции check(), которой передаются различные условия проверки. Если бы я писал код на C#, то, скорее всего, был бы вынужден сдублировать код, размещенный в данном случае в функции check(), так как в C# нет таких удобных и кратких способов декомпозиции кода. В качестве альтернативы я мог бы создать отдельный метод, принимающий делегат, абстрагирующий метод от лишних деталей, и ссылки на все необходимые объекты (или даже целый класс), но тогда каждую отдельную проверку мне пришлось бы оформить тоже отдельным методом. И хотя небольшим утешением может стать тот факт, что вместо множества методов можно было бы создать один обобщенный, или воспользоваться анонимными методами, но все же это решение далеко от элегантности. В итоге я не только избежал дублирования или распухания кода, но и получил весьма хорошо читаемый код. Ведь:
check(_ is Token.BeginQuote)
|
намного понятнее при чтении, чем:
if (stack.Count > 0 && stack.Peek() is Token.BeginQuote)
{
stack.RemoveLast();
scan(lex.GetToken())
}
elsefalse |
Используя же Nemerle, я, не задумываясь, вынес общий участок кода в отдельную локальную функцию, а отличающийся фрагмент кода передал в эту функцию в качестве параметра (функционального типа). Поскольку код отличался всего на один оператор, я воспользовался частичным применением операторов для превращения оператора в функцию. В частичном применении можно задать часть параметров/операндов конкретными значениями, а не заданные параметры/операнды обозначить символом-заместителем «_». Кстати, «_» (подчеркивание) играет в Nemerle большую роль. Оно участвует в сопоставлении с образцом, выступает в качестве указания того, что параметр намеренно не используется, и в тех местах, где нужно проигнорировать возвращаемое значение функции (в отличие от C#, Nemerle ругается, если вы игнорируете возвращаемое значение функции, это предотвращает ошибки «по забывчивости»).
Я заметил, что использование ФВП иногда помогает сделать алгоритмы более линейными. Например, без ФВП иногда приходится разделять алгоритм на отдельные части. Предположим, что вам нужно написать алгоритм, который подготавливает некоторые данные, далее, используя их, обращается к некоторому хранилищу, а затем обрабатывает полученный результат. Так как для обращения к хранилищу нужно кое-что вычислить, вы не можете передать это знание функции в виде данных. Вам придется создать одну функцию, которая вычисляет эти данные. Вызвать ее. По полученным результатам обратиться к хранилищу и затем вызвать другую функцию, передав ей полученную из хранилища информацию.
Таким образом, вам не удастся инкапсулировать весь алгоритм внутри одной функции.
Проблема элементарно решается с использованием ФВП. Достаточно описать процедуру извлечения данных в виде функционального объекта и передать ее единой универсальной функции. Тогда функция произведет необходимые вычисления, обратится к хранилищу посредством переданного функционального объекта и затем обработает полученные результаты.
Такое поведение можно рассматривать как разворот управления. Из пассивной функция становится активной. Причем для вас она все равно выглядит как функция, а не как активная сущность. Ведь вы смотрите на передаваемый функциональный объект как на уточняющую функцию.
Конечно, вместо функционального объекта можно передавать ссылку на класс или интерфейс. И иногда это даже удобнее (позволяет делать более одной операции). Но функциональные объекты и замыкания зачастую позволяют значительно упростить код. А значит, делают применение подобных решений более оправданным.
У C#-программистов считается дурным тоном давать публичный доступ к полям классов и структур. Объясняется это очень просто – это нарушает инкапсуляцию и потенциально может привести к скрытому и неконтролируемому изменению состояния объекта, имеющего публичные поля.
Откровенно говоря, меня всегда коробил тот факт, что между (C#):
class A
{
publicint Attribute;
}
|
и:
class A
{
privateint _attribute;
publicint Attribute
{
get { return _attribute; }
set { _attribute = value; }
}
}
|
семантическая разница очень умозрительная, а разница в объеме кода очень даже осязаемая и отнюдь не радующая.
Однако семантическая разница все же есть. Свойство нельзя передать по ссылке, а стало быть, невозможно получить и неявное изменение его значения.
Но того же эффекта можно добиться, если сделать поле доступным только для чтения. Конструкции:
public
readonly
int Attribute;
|
и:
private
int _attribute;
publicint Attribute
{
get { return _attribute; }
}
|
для внешнего кода практически семантически эквивалентны.
Кроме того, поля, доступные только для чтения более безопасны. Они оберегают программиста от лишних ошибок (ведь такое поле можно изменить только в конструкторе).
Учитывая все это, в Nemerle все переменные было решено по умолчанию сделать неизменяемыми. Напротив, чтобы сделать поле изменяемым, его нужно специально пометить ключевым словом mutable.
Зачастую возможность изменять состояние объекта дает возможность оптимизировать код, избегая непроизводительных расходов. Однако бывает так, что неизменяемость дает еще большую экономию.
Одной из интересных черт неизменяемых (immutable) объектов является то, что ссылки на них можно хранить без каких-либо опасений. Это позволяет использовать один и тот же объект в разных иерархиях объектов. Классическим случаем такого неизменяемого объекта является однонаправленный связанный список, или просто «список». В Nemerle список описывается типом list[T] и является вариантом (здесь и далее под «вариантом» понимается тип данных variant) с неизменяемыми полями (напоминаю, что в Nemerle все поля, не помеченные ключевым словом mutable, являются доступными только для чтения). Вот его упрощенное описание:
public
variant list[T]
{
| Cons { hd : T; tl : list[T]; }
| Nil // [] является синтаксическим сахаром к Nil
}
|
Если, например, создать следующие списки:
def lst1 = 1 :: []; // == list.Cons(1, list.Nil())def lst2 = 2 :: lst1; // == list.Cons(2, lst1)def lst3 = 3 :: lst1; // == list.Cons(3, lst1)def lst4 = 4 :: lst3; // == list.Cons(4, lst3) |
то в памяти они будут представлены следующим образом:
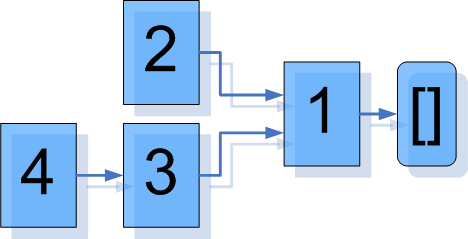
Как видите, присоединение нового элемента к списку не приводит к копированию исходного списка. Вместо этого создается новый элемент списка, ссылающийся на начало исходного списка. Если при этом какая-то переменная содержала указатель на предыдущий список, то она так и будет указывать на него. Другими словами, отряд не заметит потери бойца... (с).
Таким образом, образование списков путем прибавления нового элемента в начало другого списка не приводит к излишнему расходу памяти и не изменяет логической целостности других списков.
Несмотря на то, что фактически списки превращаются в дерево, для пользователя они выглядят как набор отдельных списков.
Тот же эффект проявляется и в более сложных структурах данных, например, в деревьях. Неизменяемость элементов позволяет добиться эффекта версионности. Добавляя новые элементы в дерево, мы вынуждены заменять все ветки от заменяемой до корневой ветки включительно. Казалось бы лишние расходы?! Но глубина сбалансированного двоичного дерева обычно не бывает очень большой. Зато неизменность предыдущих веток позволяет иметь одновременно в памяти множество разных версий дерева. Причем затраты на их создание значительно ниже, чем если копировать все дерево целиком.
По аналогии со списками можно говорить, что модификация дерева (изменение одного из его элементов) порождает новое дерево. Неизменяемость же позволяет добиться этого малой кровью, стоимость порождения новой копии будет мало отличаться от стоимости добавления элемента в аналогичное дерево, состояние которого изменяется при добавлении новых элементов.
Реализацию такого дерева можно найти по адресу:
http://nemerle.org/svn/nemerle/trunk/lib/tree.n
Чтобы было понятно, как работает этот тип (реализующий так называемое красно-черное дерево – дерево, проводящее автоматическую балансировку), я продемонстрирую здесь сам вариант, благо он очень компактен, и функцию добавления элементов.
/// Описывает ветку дерева «красно-черного» дерева.
public variant Node[T] : IEnumerable[T] where T : IComparable[T]
{
| Red { key : T; lchild : Node[T]; rchild : Node[T]; }
| Black { key : T; lchild : Node[T]; rchild : Node[T]; }
| Leaf
/// Подсчет количества элементов.public Count : int
{
get
{
match (this)
{
| Red(_, left, right) | Black(_, left, right) =>
1 + left.Count + right.Count
| _ => 0
}
}
}
public GetEnumerator() : SCG.IEnumerator[T] { NodeEnumerator(this) }
}
/// Функция возвращает копию дерева со вставленным в него новым элементом
/// Если элемент уже находится в дереве, то в зависимости от значения
/// параметра «replace» генерируется исключение или элемент заменяется.
public Insert[T](tree : Node[T], elem : T, replace : bool) : Node[T]
where T : System.IComparable[T]
{
def insert(tree)
{
| Node.Red(key, ltree, rtree) =>
if (elem.CompareTo(key) > 0)
Node.Red(key, ltree, insert(rtree))
elseif (elem.CompareTo(key) < 0)
Node.Red(key, insert(ltree), rtree)
elseif (replace)
Node.Red(elem, ltree, rtree)
elsethrow System.ArgumentException("node already in the tree")
| Node.Black(key, ltree, rtree) =>
if (elem.CompareTo(key) > 0)
BalanceRight(key, ltree, insert(rtree))
elseif (elem.CompareTo(key) < 0)
BalanceLeft(key, insert(ltree), rtree)
elseif (replace)
Node.Black(elem, ltree, rtree)
elsethrow System.ArgumentException("node already in the tree")
| Node.Leaf => Node.Red(elem, Node.Leaf(), Node.Leaf())
}
match (insert(tree))
{
| (Node.Black) as tree => tree
| Node.Red(key, ltree, rtree) => Node.Black(key, ltree, rtree)
| Node.Leaf => assert(false)
}
}
/// Балансировка дерева.
private BalRight[T](elem : T, lchild : Node[T], rchild : Node[T])
: Node[T] where T : System.IComparable[T]
{
match ((elem, lchild, rchild))
{
| (key, ltree, Node.Red(key1, ltree1, rtree1)) =>
Node.Red(key, ltree, Node.Black(key1, ltree1, rtree1))
| (key, Node.Black(key1, ltree1, rtree1), rtree) =>
BalanceLeft(key, Node.Red(key1, ltree1, rtree1), rtree)
| (key, Node.Red(key1, Node.Black(key3, ltree3, rtree3),
Node.Black(key2, ltree2, rtree2)), rtree) =>
Node.Red(key2,
BalanceLeft(key1, Node.Red(key3, ltree3, rtree3), ltree2),
Node.Black(key, rtree2, rtree))
| _ => assert(false, "balance violation")
}
}
/// Балансировка дерева.
private BalLeft[T](elem : T, lchild : Node[T], rchild : Node[T])
: Node[T] where T : System.IComparable[T]
{
match ((elem, lchild, rchild))
{
| (key, Node.Red(key1, ltree1, rtree1), rtree) =>
Node.Red(key, Node.Black(key1, ltree1, rtree1), rtree)
| (key, ltree, Node.Black(key1, ltree1, rtree1)) =>
BalanceRight(key, ltree, Node.Red(key1, ltree1, rtree1))
| (key, ltree, Node.Red(key1, Node.Black(key3, ltree3, rtree3),
Node.Black(key2, ltree2, rtree2))) =>
Node.Red(key3,
Node.Black(key, ltree, ltree3),
BalanceRight(key1, rtree3, Node.Red(key2, ltree2, rtree2)))
| _ => assert(false, "balance violation")
}
}
|
Обратите внимание на фрагменты кода, выделенные красным внутри функции Insert. Это рекурсивный вызов вставки. Функция вставки находит подветку, в которую должна быть вставлена новая ветка, и заменяет ее новой веткой, одна из подверток которой содержит старую ссылку, а вторая – ссылку на ветку, возвращаемую рекурсивным вызовом этой же функции вставки. Таким образом, функция пересоздает все ветки, ведущие к вставляемой. Если опустить подробности балансировки, то можно сказать, что в результате работы этой функции возвращается дерево, которое отличается от исходного вставленными элементами и всеми элементами, ведущими от корня (включительно) к вставленному элементу. Так как дерево автоматически сбалансируется при вставке, то, вследствие особенностей двоичной арифметики, его глубина даже при большом количестве хранимых элементов не будет очень большой.
Такой поход не только позволяет реализовать дешевое копирование деревьев, но и приводит к существенной экономии памяти, ведь большинство элементов деревьев являются общими.
Фактически, используя неизменяемые структуры данных, можно создать нечто вроде транзакционной памяти. Тот факт, что хранение старых версий стоит дешево, позволяет хранить старые версии объектов и возвращаться к ним, если требуется откат.
Эта реализация доступна в стандартной библиотеке Nemerle. Ее полное имя – Nemerle.Collections.Tree.Node, где Tree – это имя модуля, а Node – варианта, описывающего дерево. Однако использовать ее напрямую неудобно. Намного удобнее воспользоваться объектно-ориентированными обертками, классами Map[TKey, TValue] и Set[T] из того же пространства имен.
Функциональные структуры данных активно используются в компиляторе Nemerle. Так, для хранения контекста «открытых» (с помощью директивы using) пространств имен используется экземпляр типа GlobalEnv, который содержит неизменяемые списки открытых пространств имен и alias-ов, Set[string] для хранения ключевых слов, Map[string, GrammarElement] для хранения операторов, запускающих механизм синтаксических расширений, и Map[string, MainParser.OperatorInfo] для хранения описаний операторов. Благодаря тому, что все эти структуры данных являются функциональными, удается создавать множество экземпляров GlobalEnv, не расходуя понапрасну время и память.
Одна из мощных возможностей, позаимствованных Nemerle у ML-подобных языков – сопоставление с образцом. В Nemerle она выражается в виде оператора match, а также неявного сопоставления с образцом внутри методов и оператора foreach.
В двух словах, сопоставление с образцом можно описать как switch (из C) на стероидах. Но это будет слишком примитивным взглядом на столь замечательную возможность.
Основная идея сопоставления с образцом заключается в том, чтобы заменить конструкции if и switch, а также многие паттерны проектирования вроде использования хэш-таблицы для поиска ассоциаций, одной мощной конструкцией match, которая вместо проверок содержала бы образцы. Это похоже на switch, но, в отличие от него, в качестве образцов в match можно использовать не только константы, но и более сложные конструкции.
Как следует из названия, операция сопоставления с образцом производит сопоставление некоторого значения с неким образцом и дает ответ на вопрос, соответствует ли объект этому образцу. Ответ выражается в выполнении действия, которое следует непосредственно за стрелкой – «=>».
Главное преимущество сопоставления с образцом – его декларативность. Фактически, if-ы содержат не указание, что мы хотим найти, а условия и выражения, говорящие о том, как осуществить этот поиск. К тому же, более-менее сложный поиск нужной информации редко умещается в пределах одного if или switch. Образец же является именно выражением того, что нам требуется.
В статье Nemerle, опубликованной в #1 за 2006 год, подробно рассказано о том, какие виды сопоставления с образцом поддерживаются в Nemerle. В этой же статье речь пойдет о сопоставлении с образцом вариантов.
Варианты специально разрабатывались таким образом, чтобы их было удобно использовать в операции сопоставление с образцом.
Чтобы продемонстрировать мощь сочетания сопоставления с образцом и вариантов, я написал простенький пример интерпретатора арифметических выражений, принимающего на вход выражение в виде AST (абстрактного синтаксического дерева) и позволяющего вычислить выражение или преобразовать его в строку. При этом я реализовал два варианта этого интерпретатора. Один – на Nemerle с использованием вариантов и сопоставления с образцом, а второй – на C# в полном соответствии с принципами ООП и применением паттерна проектирования Посетитель для вынесения операций обработки AST из AST-классов.
using System;
using System.Collections.Generic;
using System.Text;
publicinterface IExprVisiter
{
void Visit(Literal expr);
void Visit(Call expr);
void Visit(Plus expr);
void Visit(Minus expr);
void Visit(Mul expr);
void Visit(Div expr);
}
publicabstractclass Expr
{
publicabstractvoid AceptVisiter(IExprVisiter visiter);
publicoverridestring ToString()
{
ToStringExprVisiter visiter = new ToStringExprVisiter();
AceptVisiter(visiter);
return visiter.ToString();
}
}
publicclass Literal : Expr
{
public Literal(double value)
{
_value = value;
}
double _value;
publicdouble Value
{
get { return _value; }
}
publicoverridevoid AceptVisiter(IExprVisiter visiter)
{
visiter.Visit(this);
}
}
publicclass Call : Expr
{
public Call(string name, params Expr[] parm)
{
_name = name;
_parms = parm;
}
string _name;
publicstring Name
{
get { return _name; }
}
Expr[] _parms;
public Expr[] Parms
{
get { return _parms; }
}
publicoverridevoid AceptVisiter(IExprVisiter visiter)
{
visiter.Visit(this);
}
}
publicabstractclass Operator : Expr
{
public Operator(Expr expr1, Expr expr2)
{
_expr1 = expr1;
_expr2 = expr2;
}
Expr _expr1;
public Expr Expr1
{
get { return _expr1; }
}
Expr _expr2;
public Expr Expr2
{
get { return _expr2; }
}
}
publicclass Plus : Operator
{
public Plus(Expr expr1, Expr expr2) : base(expr1, expr2) { }
publicoverridevoid AceptVisiter(IExprVisiter visiter)
{
visiter.Visit(this);
}
}
publicclass Minus : Operator
{
public Minus(Expr expr1, Expr expr2) : base(expr1, expr2) { }
publicoverridevoid AceptVisiter(IExprVisiter visiter)
{
visiter.Visit(this);
}
}
publicclass Mul : Operator
{
public Mul(Expr expr1, Expr expr2) : base(expr1, expr2) { }
publicoverridevoid AceptVisiter(IExprVisiter visiter)
{
visiter.Visit(this);
}
}
publicclass Div : Operator
{
public Div(Expr expr1, Expr expr2) : base(expr1, expr2) { }
publicoverridevoid AceptVisiter(IExprVisiter visiter)
{
visiter.Visit(this);
}
}
class ToStringExprVisiter : IExprVisiter
{
StringBuilder _bilder = new StringBuilder();
publicoverridestring ToString()
{
return _bilder.ToString();
}
void PrintList(IList<Expr> lst)
{
foreach (Expr var in lst)
{
var.AceptVisiter(this);
_bilder.Append(", ");
}
if (lst.Count > 0)
_bilder.Length -= ", ".Length;
}
publicvoid Visit(Literal expr)
{
_bilder.Append(expr.Value);
}
publicvoid Visit(Call expr)
{
_bilder.Append(expr.Name);
_bilder.Append("(");
PrintList(expr.Parms);
_bilder.Append(")");
}
void VisitOperator(Operator expr, string kind)
{
expr.Expr1.AceptVisiter(this);
_bilder.Append(kind);
expr.Expr2.AceptVisiter(this);
}
publicvoid Visit(Plus expr)
{
VisitOperator(expr, " + ");
}
publicvoid Visit(Minus expr)
{
VisitOperator(expr, " - ");
}
publicvoid Visit(Mul expr)
{
VisitOperator(expr, " * ");
}
publicvoid Visit(Div expr)
{
VisitOperator(expr, " / ");
}
}
class EvalExprVisiter : IExprVisiter
{
publicdouble Result;
publicdouble Eval(Expr expression)
{
expression.AceptVisiter(this);
return Result;
}
publicvoid Visit(Literal expr)
{
Result = expr.Value;
}
publicvoid Visit(Call expr)
{
switch (expr.Name)
{
case"min":
if (expr.Parms.Length != 2)
thrownew InvalidOperationException(expr.ToString());
Result = Math.Min(Eval(expr.Parms[0]), Eval(expr.Parms[1]));
return;
case"max":
if (expr.Parms.Length != 2)
thrownew InvalidOperationException(expr.ToString());
Result = Math.Max(Eval(expr.Parms[0]), Eval(expr.Parms[1]));
return;
default: thrownew InvalidOperationException(expr.ToString());
}
}
publicvoid Visit(Plus expr)
{
Result = Eval(expr.Expr1) + Eval(expr.Expr2);
}
publicvoid Visit(Minus expr)
{
Result = Eval(expr.Expr1) - Eval(expr.Expr2);
}
publicvoid Visit(Mul expr)
{
Result = Eval(expr.Expr1) * Eval(expr.Expr2);
}
publicvoid Visit(Div expr)
{
Result = Eval(expr.Expr1) / Eval(expr.Expr2);
}
}
class Program
{
staticvoid Main(string[] args)
{
Expr expr = new Plus(new Literal(1.23),
new Call("max", new Literal(1), new Literal(2)));
Console.WriteLine("Expression '{0}' = {1}",
expr, new EvalExprVisiter().Eval(expr));
}
}
|
using System;
using System.Console;
using Nemerle.Utility;
using Expr;
public variant Expr
{
| Literal { value : double; }
| Call { name : string; parms : list[Expr]; }
| Plus { expr1 : Expr; expr2 : Expr; }
| Minus { expr1 : Expr; expr2 : Expr; }
| Mul { expr1 : Expr; expr2 : Expr; }
| Div { expr1 : Expr; expr2 : Expr; }
publicoverride ToString() : string
{
match (this)
{
| Literal(value) => value.ToString()
| Call(name, parms) => $"$name(..$parms)"
| Plus(e1, e2) with op = "+" | Minus(e1, e2) with op = "-"
| Mul (e1, e2) with op = "*" | Div (e1, e2) with op = "/"
=> $"$e1 $op $e2"
}
}
public Eval() : double
{
match (this)
{
| Literal(value) => value
| Plus (e1, e2) => e1.Eval() + e2.Eval()
| Minus(e1, e2) => e1.Eval() - e2.Eval()
| Mul (e1, e2) => e1.Eval() * e2.Eval()
| Div (e1, e2) => e1.Eval() / e2.Eval()
| Call("max", [arg1, arg2]) => Math.Max(arg1.Eval(), arg2.Eval())
| Call("min", [arg1, arg2]) => Math.Min(arg1.Eval(), arg2.Eval())
| Call(_, _) => throw InvalidOperationException(this.ToString());
}
}
}
module Program
{
Main() : void
{
def expr = Plus(Literal(1.23), Call("max", [Literal(1), Literal(2)]));
WriteLine($"Expression '$expr' = $(expr.Eval())");
//_ = ReadLine();
}
}
|
Думаю, вряд ли кого-то придется уговаривать, что Nemerle-вариант значительно более краток и, тем не менее, ясен. Причем возьму на себя смелость утверждать, что ясным он будет даже для тех, кто плохо знаком с Nemerle. Так в чем же секрет?
Мне кажется, основной секрет – в декларативности, обеспечиваемой сопоставлением с образом и сплайс-строками (строками, допускающими вычисляемые выражения, помеченные знаком «$»). По сути, образцы очень близки к BNF-нотации (нотации для описания формальных грамматик языков программирования Бэкуса/Наура).
На уменьшение объемов исходного кода влияет также лаконичность описания вариантов и возможность использования особой формы статической «утиной типизации». Но обо всем по порядку.
В зависимости от точки зрения варианты можно трактовать как ограниченный набор sealed-классов, имеющий общего предка, как эдакий типобезопасный аналог конструкции union из языка C, или как умную «штуковину», именуемую алгебраическими типами данных.
Главной особенностью вариантов является то, что они идеально подходят для описания разнообразных структур данных. Описание получается кратким и выразительным. Это свойство позволяет не только уменьшить объем деклараций типов, но и использовать синтаксис, похожий на их декларации для описания образцов (паттернов).
Краткость синтаксиса обеспечивается разумными умолчаниями и ограничениями. Так, все поля Variant Option (то есть, отдельного значения варианта, или подтипа, далее я буду называть Variant Option элементом варианта) обязаны быть публичными, и по умолчанию являются неизменяемыми. Это позволяет, не нарушая принципов инкапсуляции, обойтись без создания свойств-аксессоров и явного указания атрибута доступа, ведь неизменяемые поля и так хорошо защищены и семантически эквивалентны свойствам. Кроме того, для элемента варианта автоматически создается конструктор по умолчанию, включающий все его поля. Учитывая, что именно объявления свойств и конструктора приводят к разбуханию C#-кода, становится понятно, почему варианты так выразительны.
Однако поначалу у людей, привыкших к ООП, могут возникать проблемы с вариантами. Дело в том, что, несмотря на то, что варианты похожи на классы в ООП, проектирование с их использованием существенно отличается. Основное отличие заключается в том, как добиваться полиморфизма, то есть, как работать с экземплярами разных типов одинаковым образом. ОО-подход предлагает для этого создавать иерархии классов, объявляя в базовых классах виртуальные методы (создавать общий интерфейс) или использовать интерфейсы (если они поддерживаются языком) и реализовывать их в разных классах. Элементы варианта нельзя расположить в иерархии как классы (их нельзя наследовать, и от них нельзя производить наследование). Варианты всего лишь позволяют описывать группы логически связанных сущностей. В них также нельзя реализовывать интерфейсы. Казалось бы, на лицо ограниченность. Но не спешите выносить столь категоричное суждение. На самом деле это просто другой подход к полиморфизму!
Его философия заключается в том, что если что-то крякает как утка, плавает как утка, и летает как утка, то это и есть утка. Точно так же, если у двух элементов одного варианта есть поля, имеющие одинаковый тип (точнее сказать, совместимый) и одинаковое (или схожее) смысловое значение, то мы можем в пределах одного вхождения оператора match обращаться к таким полям, даже если физически они относятся к разным элементам варианта.
| ПРИМЕЧАНИЕ Терминология: Вхождение match – это набор паттернов, заканчивающийся знаком «=>». Паттерн – это конструкция, начинающаяся со знака «|», за которым идет выражение паттерна и необязательная защита (when <выражение защиты>). |
match (x)
{
| X(Y()) | X => someCode() // Это вхождение match-а (match_case).
| _ => ()
}
|
| ПРИМЕЧАНИЕ В этом примере «| X(Y())» и «X» – это образцы, а вся строка целиком – это вхождение оператора match. |
Лучше всего объяснить все это на примере. Взгляните на код метода ToString() приведенный выше. Там есть следующее вхождение:
| Plus(e1, e2) with op = "+" | Minus(e1, e2) with op = "-"
| Mul (e1, e2) with op = "*" | Div (e1, e2) with op = "/"
=> $"$e1 $op $e2" |
Код $"$e1 $op $e2" будет выполняться, если на вход выражения match будет подан Expr.Plus, Expr.Minus, Expr.Mul или Expr.Div.
Тут следует кое-что пояснить. Все эти элементы варианта Expr имеют одинаковые (одинакового типа и смысла) поля – «expr1» и «expr2» (типа Expr). Так как компилятор Nemerle видит, что переменные, введенные в паттернах одного match-вхождения, совпадают по именам, он порождает код, связывающий с этими переменными значения полей того элемента варианта, с которым произошло совпадение образца. Это позволяет писать полиморфный код (работающий вне зависимости от того, с элементом какого конкретного типа произошло сопоставление). Если у одного из вариантов (или даже у всех) нет подходящего поля, то его можно заменить искусственно введенной переменной. Это делается с помощью конструкции with. В данном примере с помощью конструкции with вводится переменная «op», с которой связывается строковый литерал, соответствующий конкретному оператору.
Понимаю, что звучит это все сложно, но на самом деле за всеми этими словами скрываются довольно простые и интуитивно понятные вещи.
Давайте мысленно протрассируем приведенный выше участок кода. Если на вход приходит значение Expr.Plus(Literal(1), Literal(2)), будет произведено сопоставление с образцом:
| Plus(e1, e2) with op = "+" |
При этом с переменная «e1» будет связана с литералом «1», а «e2» с литералом «2». Их преобразование в строку даст «1» и «2», соответственно. С переменной «op» будет связано значение «+».
Корреляция между именами переменных, объявляемых в паттерне, и именами полей отсутствует. Так что можно в одном образце одного и того же match-вхождения присвоить имени «e1» значение из поля «expr1», а в другом – из поля «expr2»:
| Plus(e1, e2) | Minus(e2, e1) |
Более того, можно даже в одном из образцов связать переменную с независимым значением. Для этого используется конструкция with:
| Plus(e1, e2) | Minus(_, e2) with e1 = null |
В данном примере «_» используется, чтобы оповестить компилятор о том, что значение первого поля Expr.Minus следует проигнорировать.
Самым интересным в сопоставлении с образцом является, пожалуй, возможность создавать сложные образцы. Примеры таких образцов можно найти все в том же примере калькулятора:
| Call("max", [arg1, arg2]) => Math.Max(arg1.Eval(), arg2.Eval())
|
Заметьте, что здесь производится не только сопоставление реального типа варианта с типом, указанным в образце, но и производится проверка значений полей элемента варианта. Сначала проверяется, что поле «name» у Expr.Call равно строковому литералу ("max" в данном случае), а потом проверяется, что второе поле, parms, содержит список, состоящий из двух элементов (для сопоставления со списками используется синтаксис конструирования списков, который отличается от синтаксиса конструирования обычных вариантов). Причем, поскольку образец списка содержит переменные, они связываются с элементами списка. Таким образом, в приведенном примере переменная arg1 связывается с первым элементом списка, а arg2 – со вторым. В итоге мы получаем декларативную проверку, гарантирующую, что мы имеем дело с вызовом функции по имени "max", имеющей два параметра. И все эти проверки укладываются в 26 символов, включая объявление переменных! Это в несколько раз меньше, чем описание на естественном языке, данное мной :).
В реальных программах образцы могут быть еще сложнее. Умелое использование вариантов и сопоставления с образцом дает программисту воистину непревзойденную мощь!
Есть еще много тонкостей связывания. Например, можно связывать переменные образца и поля вариантов явно – по имени, но все это частные тонкости, которые легко почерпнуть из документации на сайте языка, или из вводной статьи на нашем сайте – www.rsdn.ru. Главное, что я пытаюсь донести – это то, как нужно мыслить, чтобы использовать варианты эффективно. Посему, стоит перечислить, чего следует избегать при их использовании. Вот список того, что не следует делать:
В отличие от классических алгебраических типов, варианты допускают наличие методов. Причем методы могут быть даже виртуальными. Это позволяет наряду с утиным полиморфизмом match-а использовать и полиморфизм в стиле ООП. Единственно, надо понимать, что этот полиморфизм ограничивается двумя уровнями (вариантом и его элементами) и позволяет выстраивать иерархии как в случае с классами.
Если при использовании вариантов у вас все время возникает желание увидеть иерархию наследования, то стоит задуматься, не стоит ли заменить варианты классами.
Вообще варианты хороши, скажем так, для внутренней реализации. Классы же хороши для описания общей архитектуры программы. Варианты также не лучший способ для описания публичного интерфейса сборок, которые требуется использовать из C#. В C# элементы вариантов будут видны как sealed-классы, работать с которыми придется средствами ООП и процедурного программирования (то есть без средств автоматизации в виде match-а).
В Nemerle основной конструкцией сопоставления с образцом, несомненно, является оператор match. Однако его функциональность доступна и в других контекстах. Ниже я перечислю их и приведу примеры использования.
Если вам не требуется извлекать данные из паттерна или использовать множество match-вхождений с множеством образцов, а требуется всего лишь узнать, соответствует ли некоторое значение некоторому образцу, то можно воспользоваться оператором «is». Его синтаксис прост:
expression ‘is’ pattern
|
Результатом этого выражения является булево значение. Если выражение соответствует паттерну – true и наоборот. Оператор «is» удобно использовать в операторах if/when и других контекстах, где требуется булево значение.
Если тело функции состоит из выражения match, в которое передаются все параметры этой функции (или метода), например:
def toString(expr : Expr) : string
{
match (expr)
{
| Literal(value) => value.ToString()
| Call(name, parms) => $"$name(..$parms)"
| Plus(e1, e2) with op = "+" | Minus(e1, e2) with op = "-"
| Mul (e1, e2) with op = "*" | Div (e1, e2) with op = "/"
=> $"$e1 $op $e2"
}
}
|
то выражение match можно опустить, расположив match-вхождения непосредственно в теле функции:
def toString(expr : Expr) : string
{
| Literal(value) => value.ToString()
| Call(name, parms) =>
$"$name($(parms.Map(_.ToString()).ToString(\", \")))"
| Plus(e1, e2) with op = "+" | Minus(e1, e2) with op = "-"
| Mul (e1, e2) with op = "*" | Div (e1, e2) with op = "/"
=> $"$e1 $op $e2"
}
|
При этом можно опустить и само имя параметра, заменив его подстановочным знаком «_».
Ввиду того, что сопоставление с образцом часто используется для декомпозиции данных, запакованных в варианты или кортежи, в Nemerle был добавлен синтаксис, позволяющий производить такую декомпозицию прямо в параметрах локальных функций. Например, вы можете написать:
def f((a, b), c)
{
(a + b) / c
}
|
Можно применять и литеральные паттерны (например, заменить переменную b значением «1»), но при этом надо понимать, что из-за отсутствия альтернативного match-вхождения в случае неудачного сопоставления с образцом будет сгенерировано исключение. Что, на мой взгляд, очень плохо.
Очень удобно использовать сопоставление с образцом в операторе foreach. При этом доступны сразу несколько возможностей.
1. Вы можете отфильтровать нужные элементы по типу. Например, предположим, что вам требуется из общего списка членов (typeMembers) некоторого типа отфильтровать только те элементы, которые реализуют интерфейс IMethod (то есть являются методами). Это можно сделать следующим образом:
foreach (method is IMethod in typeMembers)
processMethod(method);
|
2. Вы можете использовать защиту, чтобы обработать только нужные элементы. Например, вот так можно исключить из обработки элементы, значения которых равны null:
foreach (elem when elem != null in someList)
process (elem);
|
Другой пример – вы можете захотеть обработать только публичные методы:
foreach (method is IMethod when method.IsPublic in typeMembers)
processMethod(method);
|
В принципе, этот прием аналогичен использованию отдельного оператора when, но зачастую бывает более лаконичен.
3. Вы можете указывать один образец варианта. При этом будут отфильтрованы только те элементы, которые соответствуют этому образцу:
def expressions = [Literal(1.23), Mul(Literal(2), Literal(3))];
foreach (Mul(_, _) as mul in expressions)
WriteLine(mul);
|
3. Вы можете производить декомпозицию вариантов и кортежей непосредственно при объявлении элемента в foreach:
def expressions = [Literal(1.23), Mul(Literal(2), Literal(3))];
foreach (Mul(e1, e2) asmulin expressions)
WriteLine($"$(mul.Eval()) = $e1 * $e2");
|
4. Самый сложный случай практически аналогичен анонимному применению match в функциях:
def
expressions = [Literal(1.23), Mul(Literal(2), Literal(3))];
foreach (expr in expressions)
{
| Mul(e1, e2) => WriteLine($"$(expr.Eval()) = $e1 * $e2");
| Div(e1, e2) => WriteLine($"$(expr.Eval()) = $e1 * $e2");
...
}
|
Данная статья имела своей целью продемонстрировать полезные возможности, которые Nemerle предоставляет тем, кто предпочел этот язык. Надеюсь, что она окажется полезной для вас, и возможно, послужит причиной, чтобы поближе познакомиться с этим, на мой взгляд, замечательным языком.
Впрочем, одна из мощнейших возможностей Nemerle так и не была затронута в этой статье. Это – макросы. Если буду жив и здоров, то в следующих номерах обязательно постараюсь охватить эту тему поглубже.
| Оценка 1315
[+1/-1]
Оценить
|
