Данная статья не претендует на математическую красоту и строгость. Она, скорее, является инженерным решением, комбинирующим несколько способов оценки ошибки при аппроксимации кривой Безье кусочно-линейным способом. Представленный материал не содержит какой-либо сложной математики, он прост и доступен. Таким образом, статья представляет интерес в основном для начинающих, а от матерых профессионалов и математиков я ожидаю в основном критику, что само по себе хорошо. Предварительные исследования я публиковал в дискуссии на сайте RSDN, в разделе “Исходники”, тема называется “Адаптивное разбиение кривой Безье”. С момента начальной публикации (и начальной идеи) было выявлено множество недостатков этого кода. Он является работоспособным, но как говорится, “есть способ лучше”. Хочу выразить благодарность новому участнику форума, Владимиру Ладыневу, c псевдонимом runtime2, который предложил идею оценки “плоскостности” кривой по сумме двух расстояний.
Итак. Кривые и поверхности Безье широко используются в современной 2D- и 3D-графике. Для большинства приложений достаточно кривых второго и третьего порядка, то есть квадратических и кубических. Существует огромное количество материалов по кривым Безье, которые можно легко найти в Интернете, и я думаю, что если вы читаете эту статью, то имеете представление о предмете. Основной вопрос данной статьи заключается в том, как на практике рисовать эти самые кривые. Я не рассматриваю рисование в виде вызовов функций API, типа PolyBezier, это мне не интересно. Мне интересно изобрести собственное супер-круглое колесо.
Обычная практика заключается в аппроксимации кривых кусочно-линейным способом, то есть, при помощи некоторого количества прямых отрезков. Преимущество этого способа в том, что он является наиболее универсальным и при этом одним из наиболее эффективных. Результат аппроксимации в виде ломаной (полилинии) можно использовать множеством различных способов.
Способ прямых вычислений
Прежде всего, посмотрим, как можно вычислить координаты промежуточных точек непосредственно. Это описано на сайте известного австралийского астронома Paul Bourke: http://astronomy.swin.edu.au/~pbourke/curves/bezier
Ниже приведен фрагмент кода для вычисления одной точки в произвольном месте кривой. Это точная копия с сайта Пола, поэтому постарайтесь при чтении кода не мычать вслух и не провоцировать неадекватные реакции окружающих.
/*
Интерполяция кубической кривой Безье (четыре контрольные точки).
Параметр mu менятся в диапазоне от 0 до 1, от начала к концу кривой.
*/
XYZ Bezier4(XYZ p1, XYZ p2, XYZ p3, XYZ p4, double mu)
{
double mum1, mum13, mu3;
XYZ p;
mum1 = 1 - mu;
mum13 = mum1 * mum1 * mum1;
mu3 = mu * mu * mu;
p.x = mum13*p1.x + 3*mu*mum1*mum1*p2.x + 3*mu*mu*mum1*p3.x + mu3*p4.x;
p.y = mum13*p1.y + 3*mu*mum1*mum1*p2.y + 3*mu*mu*mum1*p3.y + mu3*p4.y;
p.z = mum13*p1.z + 3*mu*mum1*mum1*p2.z + 3*mu*mu*mum1*p3.z + mu3*p4.z;
return(p);
}
У нас есть четыре контрольные точки и некий параметр mu в диапазоне от 0 до 1, определяющий положение точки на кривой. Технически этого достаточно, мы просто вычисляем точки, увеличивая “mu”, и рисуем отрезки между соседними точками.
Недостатки способа
Прежде всего, способ прямых вычислений очень дорог, в 2D он требует 24 умножений с плавающей точкой для каждой точки кривой. Но это можно легко преодолеть, используя инкрементальный рекуррентный метод. Его реализация приведена в конце другой моей статьи здесь: http://antigrain.com/research/bezier_interpolation/index.html. Я не буду подробно останавливаться на нем, замечу лишь, что в основном цикле метод требует всего 6 сложений с плавающей точкой. На современных процессорах это действительно очень быстро.
Но основная проблема заключается в том, как определить количество точек, необходимое для гладкой аппроксимации, и как определить закон, по которому будет увеличиваться “mu” в случае прямых вычислений. В простейшем случае можно взять некий интервал, например, 0.01. Таким образом любая кривая будет разбита на 99 отрезков. Недостатки очевидны, длинные кривые будут иметь слишком мало точек для гладкой аппроксимации, короткие – слишком много.
Таким образом, надо вычислять количество точек (и интервал) в зависимости от длины кривой. Но чтобы посчитать длину кривой, надо вычислить саму кривую. Получается замкнутый круг. Достаточно хорошее приближение – это сумма длин отрезков: (p1, p2)+(p2, p3)+(p3, p4). Экспериментальным путем я нашел, что следующая оценка работает достаточно хорошо на типичном экранном разрешении:
Заметим, что я рассуждаю в терминах графики с субпиксельной точностью и техникой сглаживания (anti-aliasing), что сильно отличается от обычного пиксельного разрешения (MoveTo/LineTo) и одно-пиксельных линий, нарисованных с помощью алгоритма Брезенхема. Более подробно с этим можно ознакомиться в моем сообщении на форуме: http://www.rsdn.ru/Forum/Message.aspx?mid=545188&only=1
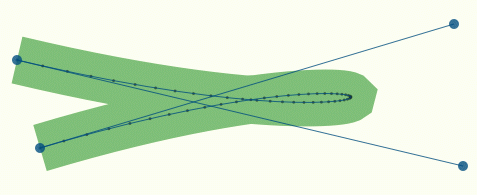
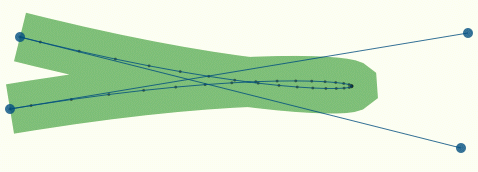
Но даже если адекватно вычислить шаг, проблемы все равно остаются. Кубическая кривая может иметь крутые повороты, узкие петли и даже точки перегиба (рисунок 1).
Рисунок 1.
Здесь имется кривая, аппроксимированная 52-мя отрезками. Сама кривая выглядит достаточно гладко, но вычисленная эквидистанта (stroke) имеет явные дефекты. В идеальном случае эквидистанта должна гладко повторять форму петли. Этого можно достичь, увеличив количество точек (и уменьшив шаг, рисунок 2)
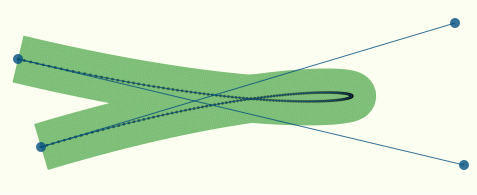
Рисунок 2.
Здесь кривая аппроксимирована уже с помощью 210 отрезков, при этом ясно видно, что большинство точек – лишние, иначе говоря, на плоских участках слишком много точек. Но даже если сделать шаг очень маленьким, проблема все равно остается (рисунок 3).
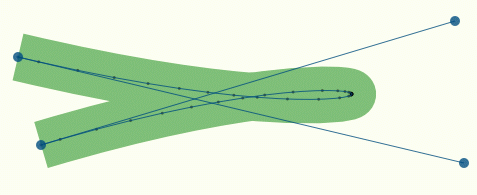
Рисунок 3.
Здесь 1091 отрезок, но при этом проблема на крутых поворотах (почти перегиб) все равно явно видна. В идеальном случае хотелось бы иметь минимальное количество точек при хорошем качестве аппроксимации (рисунок 4).
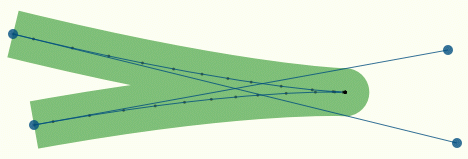
Рисунок 4.
Кривая разбита на 40 отрезков и при этом выглядит достаточно гладко, даже учитывая весьма жирную полосу (эквидистанту) вокруг кривой. Это тот самый результат, который хотелось достичь, и он действительно достигнут. Более того, даже на очень крутых поворотах (если это не настоящий перегиб), эквидистанта остается гладкой, при вполне разумном количестве отрезков, в данном случае, 44. Очевидно, что достаточно много точек сконцентрировано в месте поворота (рисунок 5, в данном случае это не перегиб, это именно поворот; о перегибах будет сказано позже).
Рисунок 5.
Paul de Casteljau разделяет и властвует (рулит, в общем)
Paul de Casteljau, замечательный инженер из Citroen, обнаружил интересное свойство кривых Безье любого порядка. Строго говоря, Paul de Casteljau вывел эти кривые в 1959 году, то есть раньше, чем Pierre Bezier (1962 год), и по справедливости эти кривые должны называться именем Casteljau. Но такова уж судьба, они были конкурентами, Pierre Bezier работал в Renault, Paul de Casteljau – в Citroen. Так автомобильный бизнес создает научно-технический прогресс.
Это интересное свойство заключается в том, что любую кривую Безье любого порядка можно очень простым способом разбить на две кривые того же порядка, и они будут в точности совпадать с исходной кривой.
Рисунок 6
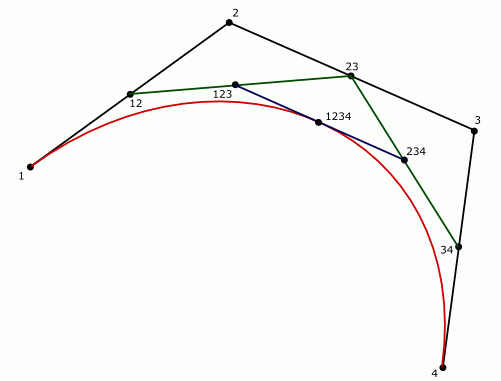
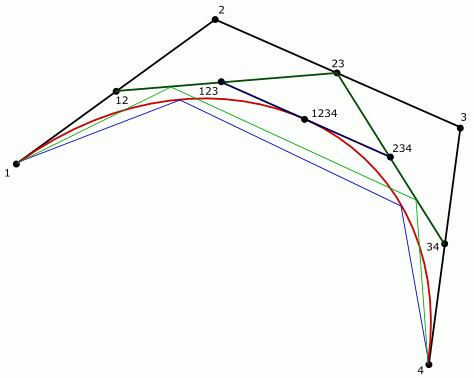
Есть точки 1, 2, 3, 4, определяющие кривую. Точки 1, 4 – это концы, 2, 3 – контрольные точки кривой (“усы” в графических редакторах). Для разбиения пополам вычисляются средние точки, 12, 23, 34. После чего – средние точки 123 и 234 и наконец, точка 1234, лежащая на кривой. Вместо половины (0.5) можно взять любой другой коэффициент от 0 до 1, но в данной статье нас интересует именно разбиение пополам. Две новые кривые будут образованы точками 1, 12, 123, 1234 - левая часть и 1234, 234, 34, 4 – правая часть.
Нетрудно заметить, что точки, определяющие две новые кривые, образуют гораздо более плоскую фигуру, чем исходные. А если поделить две новые кривые еще раз, то они будут еще более плоскими. Таким образом, после некоторого количества рекурсивных делений можно заменить полученные кривые простыми отрезками.
Следующая рекурсивная функция тоже является классической:
Это, собственно, все, что нужно для рисования кривой. Но проблема заключается в операторе “if(curve_is_flat)”.
Оценка ошибки отклонения
Метод de Casteljau, кроме своей простоты, имеет еще одно замечательное преимущество. А именно то, что у нас есть информация для оценки “прямизны” кривой – это исходные точки плюс все дополнительно вычисленные. В случае инкрементального алгоритма все, что у нас есть – это точка. Можно, конечно, запоминать как минимум еще две предыдущие точки, и анализировать их, но это сильно усложняет сам алгоритм.
Можно определить множество критериев того, когда деление пополам должно закончиться. В простейшем случае, можно взять расстояние между точками 1 и 4. Это плохой критерий, поскольку точки 1 и 4 могут изначально совпадать (кривая в виде петли). Казалось бы, достаточно один раз принудительно поделить кривую пополам, но и это не спасает. Оказывается, есть случаи, когда даже после деления пополам, одна из частей будет иметь петлю и даже совпадающие концы. Но главный недостаток в том, что этот критерий, как и любой, основанный на длинах отрезков, определяемых контрольными точками, никак не учитывает мгновенную кривизну. Он гарантирует лишь то, что отрезки не будут длиннее некоторой величины. Фактически это означает, что распределение точек будет не лучше (а даже хуже), чем в простом инкрементальном методе.
Гораздо лучшую оценку дает расстояние между точкой и прямой, поскольку это расстояние будет пропорционально фактической ошибке аппроксимации (отклонению полученной ломаной от идеальной кривой). Вопрос в том, какие расстояния выбрать.
Изначально я экспериментировал с расстоянием между точкой 1234 и прямой, определяемой отрезком 1-4. Здесь есть две проблемы. Во-первых, точки 1 и 4 могут совпадать, во-вторых, расстояние может быть равным нулю, то есть, точка 1234 может лежать на отрезке 1-4. Это, например, “Z”-случай, с координатами (100, 100, 200, 100, 100, 200, 200, 200).
Рисунок 7. Z-случай.
Обе ситуации разрешаются с помощью принудительного деления первый раз. Но не совсем. Ситуация с совпадающими начальной и конечной точкой может возникнуть даже после одного деления. И теоретически, она может возникнуть на любом этапе деления.
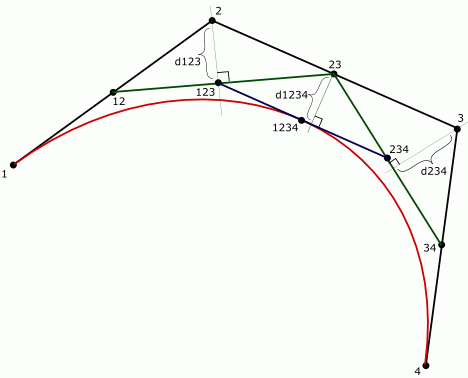
После ряда экспериментов оказалось, что оценка по трем расстояниям работает гораздо более точно.
Рисунок 8
Здесь просто суммируются три расстояния: d123+d1234+d234. Данный критерий не требует принудительного деления пополам. В результате дальнейших экспериментов, с подсказки Владимира Ладынева (runtime2) выяснилось, что оценка по двум расстояниям работает еще лучше, также не требует принудительного первого деления и, к тому же, существенно дешевле. Это сумма расстояний d2+d3 (рисунок 9).
Рисунок 9.
Здесь также имеется неприятность с совпадающими точками 1 и 4, но она будет разрешена дальше. Вычисление расстояний между точкой и прямой может показаться дорогой операцией, однако, это не так. Не обязательно даже вычислять квадратные корни. Вычислять длины как таковые, не требуется, нужно лишь сравнивать их с некой величиной. А сравнивать можно не сами длины, а квадраты этих длин. Таким образом, получается следующий код:
Здесь m_distance_tolerance – это квадрат допустимого максимального отклонения от идеальной кривой. На самом деле и это не совсем так, но в данном случае нет необходимости углубляться в более детальный анализ. Замечу лишь, что для типичных экранных разрешений значение 0.5*0.5 = 0.25 дает вполне хороший результат.
Таким образом, задача минимизации количества точек без превышения максимальной ошибки вдоль всей кривой решена. Замечу, что инкрементальный метод дает гораздо больше точек, но ошибка аппроксимации на плоских участках кривой – слишком мала (можно увеличить ее без ущерба для визуального качества), в то время как на крутых поворотах она слишком велика. Способ, показанный выше, минимизирует количество точек вдоль всей кривой, сохраняя ошибку аппроксимации приблизительно одинаковой.
Что же касается “неприятности” при совпадении точек 1 и 4, то здесь переменные dx, dy, d2, d3 обращаются в строгий ноль и значение выражения в операторе “if” будет false. Это один из редких случаев, где строгость операции сравнения чисел с плавающей точкой (меньше или меньше-равно) имеет большое значение. Но в действительности все гораздо сложней, чем на самом деле (конец цитаты). Данный код вызовет переполнение стэка в случае, когда три или все четыре точки совпадают. Если же в условии будет “меньше или равно”, это будет безопасно, но в случае совпадения точек 1 и 4, результат тоже будет некорректным. Все эти сложности преодолеваются дальше, методом убивания двух зайцев одним выстрелом, но сначала – о более интересных вещах.
Оценка угловой ошибки
Приведенный выше код, с некоторыми оговорками, решает задачу оптимизации количества точек с учетом максимального отклонения от идеальной прямой по расстоянию в Евклидовой метрике. Но он имеет тот же недостаток, что и инкрементальный способ на крутых поворотах или узких петлях.
Рисунок 10.
Данная аппроксимация содержит 36 отрезков и максимальное отклонение от идеальной кривой в 0.08 пиксела. Тем не менее, широкая полоса (stroke) выглядит так же неаккуратно, как и при инкрементальном методе. Очевидно, что одной оценки по максимальному отклонению недостаточно, и нужно учитывать еще и углы поворота для смежных отрезков. Итак, при делении кривой пополам две новые кривые являются более плоскими. Это также означает, что углы наклона отрезков 1-2 и 3-4 должны становиться все более и более одинаковыми. Если же углы существенно отличаются, то в этом месте имеется крутой поворот или узкая петля, и нужно продолжить деление.
Для вычисления углов используется функция atan2(). Это сравнительно дорогая функция, которая существенно замедляет алгоритм в целом. Замечу, что критерий угловой ошибки важен не всегда. Он важен только в случае, когда надо вычислить эквидистантную кривую, то есть полосу (stroke) значительной ширины. Если этого не требуется, достаточно критерия максимального отклонения по расстоянию.
Таким образом, вводится другой критерий, m_angle_tolerance.
// После того, как определено, что “кривизна” не превышает значение
// distance_tolerance, имеется тенденция завершить деление.
// Но требуются проверки по дополнительным критериям.//----------------------if(m_angle_tolerance < curve_angle_tolerance_epsilon)
{
// Данное условие означает, что m_angle_tolerance
// не учитывается вообще.
m_points.add(point_type(x1234, y1234));
return;
}
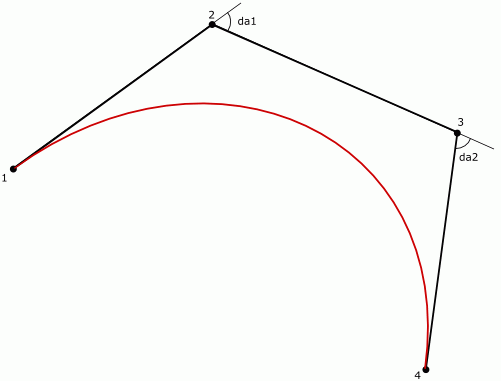
// Критерий по углу и точке перегиба//----------------------double a23 = atan2(y3 - y2, x3 - x2);
double da1 = fabs(a23 - atan2(y2 - y1, x2 - x1));
double da2 = fabs(atan2(y4 - y3, x4 - x3) - a23);
if(da1 >= pi)
da1 = 2*pi - da1;
if(da2 >= pi)
da2 = 2*pi - da2;
if(da1 + da2 < m_angle_tolerance)
{
// Наконец, можно остановить рекурсию//----------------------
m_points.add(point_type(x1234, y1234));
return;
}
Здесь m_angle_tolerance является также и флагом. Если его значение не превышает некого epsilon, угловая ошибка не вычисляется вообще. Рисунок 11 иллюстрирует вычисления:
Рисунок 11.
Конечно же, можно просто вычислить угол между отрезками 1-2 и 3-4, но два угла будут полезны позже, при обработке точек перегиба.
Вообще говоря, я начал экспериментировать с критерием только угловой ошибки, но сразу обнаружил, что он дает плохой результат на сравнительно плоских участках.
Приведенный выше код гарантирует, что два любых последовательных отрезка будут образовывать фигуру, достаточно плоскую для того, чтобы эквидистанта выглядела гладко. Тем не менее, и здесь есть проблемы, и прежде всего – это обработка точек перегиба.
Обработка точек перегиба
Невырожденная кубическая кривая Безье может иметь одну точку перегиба. Точка перегиба – это точка на кривой, в которой функция угла наклона имеет разрыв. Это резкий излом, остающийся резким, как бы ни масштабировали кривую.
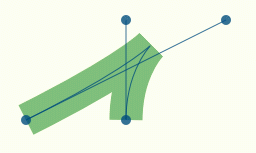
Для получения реального перегиба контрольные точки должны быть расположены в точности в форме буквы X, например с координатами (100, 100, 300, 200, 200, 200, 200, 100), рисунок 11.
Рисунок 12. Х-случай.
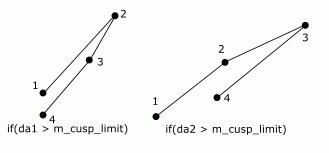
В этом случае, условие da1 + da2 < m_angle_tolerance теоретически никогда не выполнится. На практике оно выполнится, как только все четыре точки кривой совпадут, и все аргументы всех вызовов atan2() обратятся в ноль. Но в тот момент, когда это произойдет, может случиться переполнение стека. Это плохие новости. Хорошие новости – в том, что это препятствие можно легко обойти следующим образом.
Здесь m_cusp_limit – это не просто максимальный угол. Это – число Пи минус максимальный угол (ну или 180 минус угол). Замечу так же, что обычно добавляется точка на кривой, то есть, точка 1234. Это делается потому, что позволяет распределить точки симметрично относительно концов кривой. Другими словами, вычисленные точки кривой должны с высокой точностью совпадать с точками той же кривой, вычисленной в обратном направлении. Но в данном случае добавляется точка, при которой имеется резкий перегиб. Я пришел к этому решению экспериментальным путем и это решение гарантирует, что “срез” полосы в точке перегиба будет с высокой точностью перпендикулярен линиям в этой точке (рисунок 13).
Рисунок 13.
Дьявол кроется в деталях
Но всех этих усилий недостаточно для обеспечения числовой стабильности. Есть множество вырожденных случаев, при которых алгоритм работает неправильно. Мои эксперименты заняли значительное время, поскольку мне хотелось найти “серебряную пулю”, а прямой анализ всех вырожденных случаев превратился бы в длинный спагетти-код, который я очень не люблю. Например, точки могут совпадать; в этом случае возникает неопределенность и функция atan2() возвращает 0, то есть, как если бы прямая была горизонтальной. В этом случае вычисление угла между вырожденным и реальным отрезками дает неверный результат. Опустив все “муки творчества”, приведу лишь конечный вывод.
Все вырожденные случаи могут быть интерпретированы как случаи коллинеарности.
Для оценки расстояния вычисляются следующие выражения:
Теперь, если поделить d2 на длину отрезка 1-4, получается Евклидово расстояние между точкой 2 и прямой, определяемой отрезком 1-4. Но как было упомянуто, знать само расстояние не нужно, и не требуется ничего делить – достаточно сравнить значение с другим вычисленным значением. Далее, из тривиального анализа данных выражений следует, что можно легко определить как случаи совпадающих точек, так и случаи коллинеарности. Для этого вводится некая константа, curve_collinearity_epsilon. Экспериментальным путем я определил это значение как 1e-30.
Во всех случаях коллинеарности можно поступать иначе, нежели в обычном случае. Один из случаев – полная коллинеарность, когда все четыре точки лежат на одной прямой. Этот случай также возникает при совпадении точек 1 и 4. Хоть он и не является коллинеарным, но метод оценки для этого случая работает так же хорошо, как и в коллинеарном случае.
Наиболее удивительным оказалось то, что данный критерий защищает и от глубокой рекурсии в точке перегиба на кривой. Можно даже убрать проверку на максимальную глубину рекурсии, но я бы ее все-таки оставил, ибо “мало ли чего”. Это “мало ли чего” обусловлено лишь тем, что моих знаний не хватает, чтобы привести строгое математическое доказательство, что эта проверка не нужна. Поскольку я не математик, а инженер, то и решение задачи выполнено именно в инженерном стиле (см. предисловие).
Коллинеарный случай
Я хотел бы выразить благодарность Timothee Groleau из Сингапура (http://www.timotheegroleau.com), предложившему простую идею оценки кривизны по расстоянию между точкой 1234 и средней точкой отрезка 1-4. Результат работы этой оценки отличается от оценки по расстояниям между точкой и прямой. Он тоже дает приемлемый результат, но, в общем и целом, значительно хуже. Но этот способ имеет одно значительное преимущество, а именно то, что он корректно справляется с коллинеарным случаем, когда контрольные точки имеют следующий порядок 2-1-4-3 (рисунок 14).
Рисунок 14.
Любой метод, основанный на расстоянии между точкой и прямой, в данном случае не сработает, и результатом будет просто отрезок 1-4, что, очевидно, является неправильным. Критерий Timothee работает хорошо в этом случае, и при этом уже есть механизм определения коллинеарности. Таким образом, код обработки коллинеарного случая получается очень простым:
Единственное, что нужно учесть – то, что в вырожденном случае точка 1234 может попасть на середину отрезка 1-4. Эта проблема решается принудительным делением кривой первый раз.
Параметр level позволяет также ограничить глубину рекурсии. Как уже было сказано, все признаки указывают на отсутствие необходимости в этом, но на всякий случай я все-таки ввел ограничение в 32 уровня вложенности. На практике я не встречал более 17 в очень сложных случаях (очень длинная кривая, тысячи точек, очень малые значение distance_tolerance и angle_tolerance, плюс очень узкая петля).
Критерий Timothee генерирует некоторое количество точек в других коллинеарных случаях, например:
1-2-3-----------4
Было бы неплохо распознавать подобные случаи и генерировать результат в виде одного отрезка 1-4, но в этом нет большой необходимости, поскольку на практике коллинеарные случаи крайне редки, хотя почти коллинеарные встречаются весьма часто. Но “почти” в данном случае не считается, стоит отступить от прямой хотя бы на 0.001 пиксела, как случай перестает быть коллинеарным.
Эти случаи обрабатываются просто. Достаточно считать точки 1 и 3 в первом случае (2 и 4 во втором) совпадающими. Здесь есть одна небольшая деталь, о которой будет сказано позже.
Здесь в точке перегиба добавляются две точки вместо одной (1234). Я пришел к этому тоже экспериментальным путем. Добавление одной точки (любой из имеющихся) генерирует отсечку неверной формы (с неправильным углом). Математическая сущность этого способа для меня не вполне очевидна, но... это просто работает.
Класс имеет следующие параметры:
approximation_scale — Определяет точность аппроксимации. На практике нужно преобразовывать координаты из мировых в экранные, в результате чего всегда будет присутствовать некий коэффициент масштабирования. Обычно кривые обрабатываются в мировых координатах, в то время, как точность аппроксимации должна быть, в конце концов, в пикселах. Обычно это выглядит следующим образом: m_curved.approximation_scale(m_transform.scale()); где m_transform – матрица аффинных преобразований, учитывающая все преобразования, включая viewport и zoom.
angle_tolerance — Задается в радианах. Чем меньше это значение, тем более точно будет аппроксимирована кривая на крутых поворотах. Однако 0 означает, что угловые условия вообще не учитываются.
cusp_limit — Угол в радианах. Если 0, то только реальные точки перегиба будут выглядеть как “bevel join”. Значения больше нуля ограничивают “остроту” на поворотах. Чем больше это значение, тем менее крутые повороты будут “обрезаны”. Обычно это значение не должно превышать 10-15 градусов (в “радиановом” эквиваленте, разумеется).
Как было упомянуто выше, оценка угловой ошибки является дорогой операцией и не всегда нужна. Она необходима только в случаях, если требуется нарисовать полосу значительной ширины (или другую эквидистанту, например, контур). Для оптимизации этого можно поступить примерно следующим образом:
double scl = m_transform.scale();
m_curved.approximation_scale(scl);
// Выключить обработку условий по углу и точек перегиба//-----------------
m_curved.angle_tolerance(0);
if(attr.fill_flag)
{
// Заливка
. . .
}
if(attr.stroke_flag)
{
// Обработка широких линий (stroke)//---------------------// Если визуальная ширина линии (stroke) значима, следует
// включить обработку резких поворотов и перегибов.//---------------------if(attr.stroke_width * scl > 1.0)
{
m_curved.angle_tolerance(0.2);
}
. . .
}
Квадратические кривые
Справиться с квадратическими кривыми гораздо проще. Нет даже необходимости использовать критерий cusp_limit, поскольку точка перегиба на кубической кривой может возникнуть только в коллинеарном случае, который уже обрабатывается отдельно.
Рекурсивная функция генерации квадратической кривой
Можно так же скомпилировать его самостоятельно, причем для платформ Win32, Unix/Linux с X11, а так же, MacOS, BeOS и AmigaOS, или для любой другой платформы, где работает библиотека SDL (http://www.libsdl.org). Для этого надо загрузить AGG: http://antigrain.com/agg23.zip или http://antigrain.com/agg23.tar.gz и скомпилировать пример bezier_div.cpp.
На рисунке 15 приведен снимок экрана.
Рисунок 15
Пример работает довольно медленно по сравнению с другими примерами из AGG, но в этом нет ничего страшного. Я вычисляю максимальное отклонение от идеальной кривой и угловую ошибку для пяти масштабов: 0.01, 0.1, 1, 10 и 100. Эти вычисления занимают довольно существенное время. Ошибка отклонения вычисляется так. Устанавливается значение approximation_scale, соответствующее масштабу и вычисляется отклонение. Это значение умножается на величину масштаба. Реультатом этих вычислений является ошибка, нормализованная для экранного разрешения (в пикселах) – то есть так, как если бы кривая рисовалась на экране с субпиксельной точностью и в соответствующих масштабах (0.01, 0.1, 1, 10, 100).
Образцовая кривая вычисляется прямым способом, описанным в статье Paul Bourke, с очень маленьким шагом (4096 точек). Разница в максимальном отклонении между инкрементальным и рекурсивным способами очевидна. В рекурсивном случае нормализованная максимальная ошибка остается приблизительно одинаковой, вне зависимости от масштаба (или уменьшается на масштабах 0.01 и 0.1). В инкрементальном методе ошибка резко уменьшается на масштабах 10 и 100. Очевидно, что такое поведение неправильно, поскольку достигать ошибки в 0.001 пиксела не нужно – это обходится слишком дорого, и в результате получается необоснованно большое количество точек. В данном случае цель – не минимизировать ошибку вообще, а оптимизировать количество точек, не превышая заданную ошибку.
Для инкрекрементального метода можно задавать значение approximation_scale как некую функцию, например sqrt(scale). Квадратный корень формально уравнивает отклонение при разных масштабах, но на реальных изображениях при масштабировании явно видны “угловатости”. Этот факт доказывает, что инкрементальный метод дает неоптимальное распределение точек, даже в случае непревышения заданного отклонения.
Можно сравнить результаты:
“Инкрементальный тигр”
“Рекурсивный тигр”
Разница может показаться очень незначительной, но если загрузить обе картинки и переключаться между ними при помощи какой-либо программы slideshow (я пользуюсь бесплатной Irfanview, http://www.irfanview.com), то разница в точности становится явно видна. В этих примерах я постарался установить параметры так, чтобы генерировалось приблизительно одинаковое число точек. Я даже дал инкрементальному методу некоторую “фору”. Тем не менее, если внимательно сравнить изображения, то можно увидеть, что рекурсивный метод дает гораздо более точную аппроксимацию.
Но все же, простой и быстрый инкрементальный метод так же может быть использован в ряде задач, особенно там, где производительность критична. Типичный случай – рисование мелких шрифтов. Обычно шрифты не содержат кривых сложной формы, все кривые близки к дугам окружностей. Шрифты TrueType в большинстве случаев содержат только квадратические кривые.
Дополнение 1
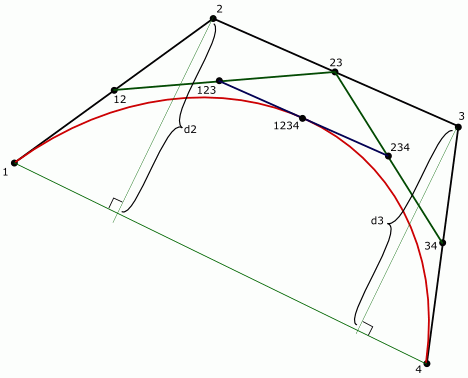
Во время написания статьи я сообразил, что добавление точки, лежащей на кривой (точка 1234) не является оптимальным. В этом случае, кривая получается описанной вокруг полученной ломаной, а ломаная – соответственно вписанной в кривую. Если же добавить точку 23, получится несколько лучший результат (как бы более центрированный относительно кривой).
Рисунок 16
Здесь синяя ломаная – это то, что получится при добавлении точек 1234 в случае ровно двух делений пополам, зеленая – при добавлении точек 23. Очевидно, что отклонение зеленой линии меньше. На практике зеленая линия дает отклонение примерно в 1.4 раза меньше, то есть, sqrt(2). Замечу так же, что для квадратической кривой это улучшение не срабатывает, поскольку точка на кривой (123) – это все, что имеется.
Дополнение 2
В конференции comp.graphics.algorithms, куда я поместил анонс, я получил справедливую критику за недостаточное знакомство с профессиональными научными статьями на подобные темы. Вся дискуссия находится по адресу:
Одна из статей, приведенных в ссылках, называется “Adaptive forward differencing for rendering curves and surfaces” и ее можно легко найти в Интернете. Описанный в статье метод является математически изящным, но он не решает проблему вычисления гладких эквидистант по результирующим точкам. Но наиболее интересным оказалось сообщение со следующим текстом от человека с ником “Just d' FAQs” (ниже мой перевод):
A well-known flatness test is both cheaper and more reliable than the ones you have tried. The essential observation is that when the curve is a uniform speed straight line from end to end, the control points are evenly spaced from beginning to end. Therefore, our measure of how far we deviate from that ideal uses distance of the middle controls, not from the line itself, but from their ideal *arrangement*. Point 2 should be halfway between points 1 and 3; point 3 should be halfway between points 2 and 4.This, too, can be improved. Yes, we can eliminate the square roots in the distance tests, retaining the Euclidean metric; but the taxicab metric is faster, and also safe. The length of displacement (x, y) in this metric is |x|+|y|.
Хорошо известный тест “прямизны” является и более дешевым и более надежным, чем использованный вами. Основной результат наблюдения заключается в том, что если кривая является прямой линией, по которой равномерно движется точка, то контрольные точки кривой также расположены равномерно. Поэтому, критерий того, насколько далеко мы удаляется от идеальной кривой, заключается не в расстоянии от линии как таковой, а величине отклонения от идеального расположения контрольных точек для случая прямой линии (уф! пока переводил, аж сам понял, о чем речь (). Точка 2 должна быть посередине между точками 1 и 3, точка 3 должна быть посередине между 2 и 4. Здесь также возможны улучшения. Да, мы можем избавиться от вычисления квадратных корней, продолжая использовать расстояния в Евклидовой метрике, но расстояния в метрике Манхэттена (taxicab) работают быстрее и тоже дают хороший результат. Длина вектора (x, y) в этой метрике равна |x|+|y|.
И этот код не требует принудительного первого деления, то есть он является вполне надежным и обладающим числовой стабильностью в любом случае. Автор сообщения настаивал, что данного критерия достаточно, но как показали дополнительные эксперименты, результат очень похож на результат простого инкрементального метода. То есть, данная оценка не обеспечивает хорошего баланса между количеством точек и максимальным отклонением от идеальной кривой. Это означает, что все мои исследования имеют право на жизнь и прошли достаточно жесткую проверку практикой (как минимум, с моей точки зрения). Тем не менее, имеет смыcл использовать это выражение в полностью коллинеарном случае, что я в результате и сделал. А самое главное – можно исключить принудительное деление кривой пополам. Но поскольку теперь используются разные метрики - Euclidian и Manhattan (она же - taxicab), придется нормировать значения “tolerance” примерно следующим образом:
Во всех случаях коллинеарности данный метод работает лучше, чем метод, предложенный Timothee Groleau. На этом я и остановился, хотя подобные исследования можно продолжать до бесконечности – кто бы еще платил за это деньги...
Заключение
Данное исследование является по большей части моим личным капризом. Оно может показаться потерянным временем, особенно для людей, пользующихся готовыми решениями в виде вызовов функций API. Но данная работа как минимум помогла решить некоторые проблемы в моих проектах, и, я надеюсь, поможет и другим людям. А во-вторых, я получил удовольствие, работая над этой задачей, и даже имею надежду получить определенную материальную компенсацию в конечном итоге (не непосредственно, а просто в виде укрепления моей личной репутации). И это единственное, что имеет значение в данном случае. Ну и конечно же, хотелось бы выразить благодарность редакции RSDN, в частности, Михаилу Купаеву за конструктивные замечания и исправления, а главное – за превосходное знание грамматики русского языка.
Эта статья опубликована в журнале
RSDN Magazine
#3-2005. Информацию о журнале можно найти здесь