 Оценка 520
Оценка 520 
 Оценить
Оценить 






| Оценка 520 Оценить
|
| Введение Проблема Дизайн Решение Заключение Список литературы |  |
Рано или поздно для любого Web-приложения встаёт проблема реализации полнотекстового поиска. Существует множество решений – от самостоятельной реализации алгоритмов поиска до внедрения сторонних подсистем от таких поставщиков как Microsoft, Google и других.
В этой статье мы рассмотрим один из способов добавления полнотекстового поиска в существующее Rich Internet Application (RIA) на платформе Silverlight c поддержкой WCF RIA Services. В качестве Object-Relational Mapper (ORM) используется Linq2Sql. Предполагается, что читатель имеет базовые знания по данным технологиям. Дополнительных знаний о полнотекстовом поиске не требуется.
Предположим, что у нас есть приложение для издателей книг, написанное на Silverlight c поддержкой WCF RIA Services. Нам необходимо реализовать возможность поиска по таким полям, как "Название" и "Аннотация".
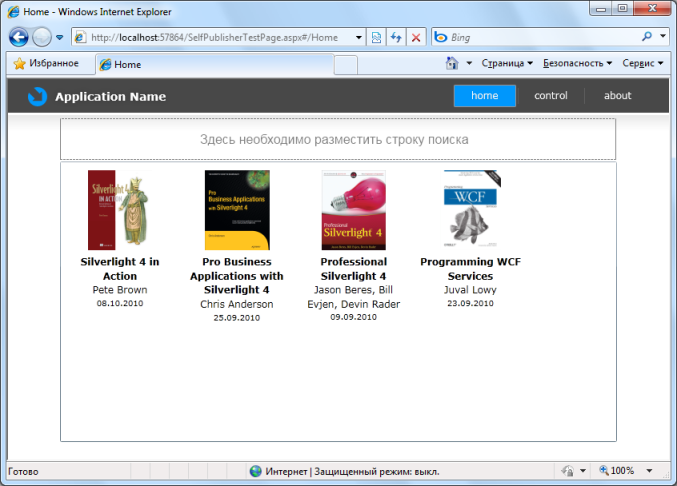
Рис. 1. Вид главной страницы приложения
| ПРИМЕЧАНИЕ Поле "Аннотация" не представлено на рисунке и отображается только в подробной информации о книге. |
Прежде чем спроектировать решение, определимся с терминологией.
Полнотекстовый поиск – это поиск документов или записей в базе данных на основании их содержимого. Выполняя полнотекстовый поиск, поисковая система анализирует все слова в каждом сохранённом документе или записи, и ищет соответствие для слов, введенных пользователем.
Поисковый индекс – словарь, в котором перечислены все слова, и указано, в каких документах или записях базы данных они встречаются. Поисковый индекс (далее просто индекс) позволяет существенно ускорить скорость поиска по сравнению с анализом содержимого документов или записей базы данных.
Самый популярный вопрос, который можно услышать от начинающих разработчиков – почему для реализации полнотекстового поиска нельзя использовать метод Contains, который в большинстве ORMs транслируется в конструкцию LIKE? Ответ прост – данный способ является достаточно ограниченным, т.к. не учитывает морфологические особенности языка и не позволяет использовать язык запросов (о нём мы поговорим позже). Учитывая перечисленные недостатки, целесообразно выбрать поисковый движок. Для платформы .Net наиболее популярными способами считаются использование встроенной функциональности Microsoft SQL Server (начиная с версии SQL Server 2000) и использование Lucene.Net. Мы рассмотрим последний, ввиду недостатка русскоязычных материалов по этому движку.
Lucene.Net – это перенесенный с платформы Java поисковый движок Lucene. Он поддерживает тот же API и те же классы, что и оригинальная версия. Это накладывает определённый отпечаток, а так же делает индекс обратно совместимым для обеих платформ.
Текущий стабильный релиз 2.9.2 может быть загружен из официального репозитория.
Итак, что такое Lucene? Lucene – это высокопроизводительная, масштабируемая библиотека для информационного поиска (ИП). ИП относится к процессу поиска документов, информации в документах или метаданных о документах. Lucene позволяет добавлять возможности поиска в различные приложения. Этот открытый проект реализован Apache Software Foundation и может быть использован на условиях лицензии Apache Software. Таким образом, Lucene в настоящее время и на протяжении уже несколько лет является самой популярной свободной библиотекой для ИП.
Помимо основных модулей Lucene, существует большое количество дополнений, предлагающих полезные расширения функциональности. Некоторые из них являются жизненно необходимыми почти для всех приложений, например, модуль проверки орфографии и подсветки результатов. Эти модули входят в состав отдельного проекта под названием Lucene Contrib.
Lucene используется в таких проектах, как StackOverflow, Twitter, Loggly.com, Archive.org, Search.USA.gov, WhiteHouse.gov, Digg, MySpace, LinkedIn, Fedex, Apple, SalesForce.com, Encyclopedia Britannica CD-ROM/DVD, Eclipse IDE, Atlassian (JIRA) и др.
Следующая диаграмма наглядно показывает процесс поиска в приложении на основе Lucene.Net.
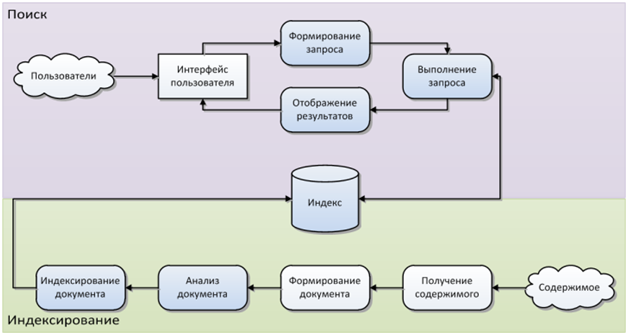
Рис. 2. Основные компоненты поисковой подсистемы
Компоненты Lucene.Net выделены другим цветом на диаграмме
Рассмотрим более подробно операции индексирования и поиска.
Как мы отмечали раньше, для ускорения работы поиска он должен выполняться по индексу, а не по реальным данным. Поэтому перед обработкой поисковых запросов необходимо построить индекс. Основные этапы формирования индекса таковы:
После того как построен индекс, поисковый движок может принимать запросы от пользователя. Рассмотрим основные этапы прохождения пользовательского запроса:
Lucene.Net использует комбинацию естественно-логического и пространственно-векторного подходов, а также оставляет возможность выбора за пользователем;
Имея библиотеку для полнотекстового поиска, мы можем приступить к разработке решения.
Итак, нам нужно проанализировать поля сущности Book:
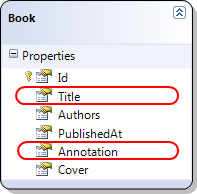
Рис. 3. Описание сущности Book
Оба поля представляют собой простой текст и отличаются только длиной.
Перейдём к реализации сервиса для процессов индексации и поиска.
| ПРИМЕЧАНИЕ Для упрощения задачи мы возложим эти обязанности на уже существующий сервис для работы со списком книг. |
| СОВЕТ В промышленных масштабах рекомендуется использовать для поиска отдельный сервер, т.к. поиск – одна из самых часто используемых и затратных операций. |
Описание сервиса:
[EnableClientAccess()] publicclass BookService : LinqToSqlDomainService<SelfPublisherDataContext> { CRUD Operations ... #region Search Operations // Путь к каталогу, хранящему поисковый индекс.privateconststring Path = @"C:\Test"; // Названия полей, необходимых для индексирования.privateconststring IdName = "Id"; privateconststring TitleName = "Title"; privateconststring AnnotationName = "Annotation"; // Максимальное количество найденных записей.privateconstint Size = 10; // Версия поискового движка.privatereadonly Version _version = Version.LUCENE_29; // Анализатор поискового индекса.privatereadonly Analyzer _analyzer = new StandardAnalyzer(Version.LUCENE_29); /// <summary>/// Индексирование./// </summary>publicvoid Index() ... /// <summary>/// Поиск./// </summary>/// <param name="query">Строка поиска.</param>/// <returns>Результаты поиска.</returns> [Query] public IEnumerable<Book> Find(string query) [...] #endregion } |
Рассмотрим операцию индексирования:
public
void Index()
{
var indexDirectory = new DirectoryInfo(Path);
// 1.if (indexDirectory.Exists)
indexDirectory.Delete(true);
FSDirectory entityDirectory = null;
IndexWriter writer = null;
try
{
// 2.
entityDirectory = FSDirectory.Open(indexDirectory);
writer = new IndexWriter(
entityDirectory,
_analyzer,
true,
IndexWriter.MaxFieldLength.UNLIMITED);
// 3.using (var context = new SelfPublisherDataContext())
{
foreach (var book in context.Books)
{
var document = new Document();
document.Add(
new Field(
IdName,
book.Id.ToString(),
Field.Store.YES,
Field.Index.NOT_ANALYZED,
Field.TermVector.NO));
document.Add(
new Field(
TitleName,
book.Title,
Field.Store.YES,
Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
document.Add(
new Field(
AnnotationName,
book.Annotation,
Field.Store.YES,
Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.AddDocument(document);
}
}
// 4.
writer.Optimize(true);
}
finally
{
if (writer != null)
writer.Close();
if (entityDirectory != null)
entityDirectory.Close();
}
} |
Первоначально необходимо обработать ситуацию, когда индекс уже существует (1). В данном примере мы его удаляем и создаём заново, однако для больших объёмов данных это затратная операция, поэтому в библиотеке существует операция Merge, которая занимается внесением изменений в уже существующий индекс. Далее мы приступаем к формированию индекса с помощью объекта IndexWriter (2). От того, как будет записан индекс на диск, напрямую зависит скорость поиска. Возможностей управлять этим процессом немного, но инженеры Apache в настоящее время активно исправляют этот недостаток. Индекс строится на основе документов, которые, в свою очередь, описываются с помощью полей (3). Здесь важно отметить, что значение Id должно сохраняться, но не анализироваться, это нужно для последующей идентификации записей в базе данных. Значения свойств Title и Annotation должны анализироваться и сохраняться, так же, как и информация об их положении в исходном тексте (флаг WITH_POSITIONS_OFFSETS). И последнее, что нужно для построения индекса – это провести оптимизацию (4). Данная операция нужна потому, что в процессе построения индекса, происходит его фрагментация.
Перейдём к операции поиска:
public IEnumerable<Book> Find(string query)
{
// 1.if (string.IsNullOrWhiteSpace(query))
return Enumerable.Empty<Book>();
var indexDirectory = new DirectoryInfo(Path);
FSDirectory entityDirectory = null;
IndexSearcher searcher = null;
try
{
// 2.
entityDirectory = FSDirectory.Open(indexDirectory);
searcher = new IndexSearcher(entityDirectory, true);
// 3.var documentBooks = FindDocumentBooks(query, searcher);
// 4.
Highlight(query, documentBooks, b => b.Title, (b, t) => b.Title = t);
Highlight(
query, documentBooks, b => b.Annotation, (b, t) => b.Annotation = t);
return documentBooks.Select(db => db.Value).ToList();
}
finally
{
if (searcher != null)
searcher.Close();
if (entityDirectory != null)
entityDirectory.Close();
}
} |
Проверяем на корректность строку поиска (1). Здесь по умолчанию мы возвращаем пустую коллекцию. Строка корректна – создаём объект IndexSearcher для поиска по индексу (2), вызываем метод FindDocumentBooks (3) и далее метод Highlight для подсветки результатов (4). Реализация FindDocumentBooks:
private IEnumerable<KeyValuePair<int, Book>> FindDocumentBooks(string query, Searcher searcher)
{
// 1.var parser = new MultiFieldQueryParser(
_version,
new[] { TitleName, AnnotationName },
_analyzer);
// 2.var scoreDocs = searcher.Search(parser.Parse(query), Size).scoreDocs;
// 3.var documentBookIds = scoreDocs.Select(x => new KeyValuePair<int, int>
(
x.doc,
int.Parse(searcher.Doc(x.doc).Get(IdName))
)).ToList();
// 4. var bookIds = documentBookIds.Select(db => db.Value);using (var context = new SelfPublisherDataContext())
{
return context.Books
.Where(b => bookIds.Contains(b.Id))
.ToList()
.Select(b =>
new KeyValuePair<int, Book>(
documentBookIds.Single(db => db.Value == b.Id).Key, b));
}
} |
Здесь мы определяем парсер для запроса (1). В данном случае используется парсер для поиска по нескольким полям сразу. Далее происходит соответственно разбор строки запроса (2) и поиск документов, которые соответствуют записям (3). После того, как документы найдены, необходимо получить записи из базы данных на основании сохранённого ранее идентификатора (4).
К этому моменту у нас уже есть полнотекстовый поиск, и его можно использовать в качестве улучшенного Contains. Однако мы продолжим и рассмотрим реализацию метода Hightlight для подсветки результатов поиска:
private
void Highlight(string query, IEnumerable<KeyValuePair<int, Book>> documentBooks, Func<Book, string> getter, Action<Book, string> setter)
{
// 1.var parser = new QueryParser(_version, query, _analyzer);
var scorer = new QueryScorer(parser.Parse(query));
var formatter = new SimpleHTMLFormatter();
var highlighter = new Highlighter(formatter, scorer);
highlighter.SetTextFragmenter(new SimpleFragmenter());
// 2.foreach (var documentBook in documentBooks)
{
var book = documentBook.Value;
var fragments = highlighter.GetBestFragments(_analyzer, getter(book), 10);
if (fragments.Length <= 0)
continue;
var fragment = fragments[0];
setter(book, fragment);
}
} |
Код достаточно прямолинеен. Мы создаём парсер для запроса, оценщик токенов в запросе, форматер и, наконец, класс Highlighter, отвечающий за подсветку результатов (1). Далее мы проходим по сущностям и обрамляем найденные слова в теги html-разметки (2). Хотя мы здесь и ограничились первым найденным фрагментом, в Lucene.Net имеется возможность выбрать стиль оформления результатов на основании процентного соответствия условиям поиска.
Здесь может возникнуть вопрос, почему сервисный метод осведомлён о том, как отображать информацию для клиента, не ведёт ли это к проблемам, когда клиенты созданы на разных платформах и языках?
В данном случае это сделано, намерено с целью продемонстрировать функциональность библиотеки. С тем же успехом мы могли послать Silverlight-клиенту позиций найденных токенов и список сущностей. Однако это верно не для всех клиентов. Например, если запрос к сервису инициируется кодом на JavaScript, подсветка результатов в браузере может замедлить выдачу результатов поискового запроса. К другому очевидному преимуществу формированию html-разметки на стороне сервиса можно отнести возможность кеширования.
Проблему отображения html-разметки в Silverlight-приложении можно решить по-разному.Мы выберем путь конвертации. Создадим специальный пользовательский элемент управления, который способен преобразовать html в xaml. Вот его код:
public
partial
class HtmlTextBlock
{
publicstaticreadonly DependencyProperty HtmlProperty =
DependencyProperty.Register(
"Html",
typeof(string),
typeof(HtmlTextBlock),
new PropertyMetadata(new PropertyChangedCallback(OnHtmlChanged))
);
public HtmlTextBlock()
{
InitializeComponent();
}
publicstring Html
{
get { return (string)(GetValue(HtmlProperty)); }
set { SetValue(HtmlProperty, value); }
}
privatestaticvoid OnHtmlChanged(DependencyObject o, DependencyPropertyChangedEventArgs e)
{
var textBlock = (HtmlTextBlock)o;
textBlock.View.Inlines.Clear();
var html = (string)e.NewValue;
var matches = Regex.Matches(html, "<B>(?'text'.*?)</B>");
if (matches.Count > 0)
{
var offset = 0;
string text;
foreach (Match match in matches)
{
// текст до совпадения
text = html.Substring(offset, match.Index - offset);
if (text.Length > 0)
textBlock.View.Inlines.Add(new Run { Text = text });
// текст, соответствующий результатам запроса
text = match.Groups["text"].Value;
if (text.Length > 0)
{
textBlock.View.Inlines.Add(
new Run
{
Text = text,
FontWeight = FontWeights.Bold
});
}
offset = match.Index + match.Length;
}
// текст после совпадения
text = html.Substring(offset);
textBlock.View.Inlines.Add(new Run { Text = text });
}
else
{
var text = html;
textBlock.View.Inlines.Add(new Run { Text = text });
}
}
} |
Ключевая идея заключается в том, чтобы найти выделенный фрагмент в html-разметке и на его основании сформировать блоки Run, которые отвечают за форматирование текста в xaml.
| ПРИМЕЧАНИЕ Более удачным решением может показаться написание форматера для xaml, с целью получения xaml-разметки на выходе. В этом случае вы должны понимать, что потеряете кросс-платформенность, т.к. клиенты будут вынуждены разбирать xaml, и то, что вам придётся найти способ осуществить привязку xaml-разметки в вашем приложении, т.к. простого способа сделать это в Silverlight не существует. |
В результате мы получим следующее окно:
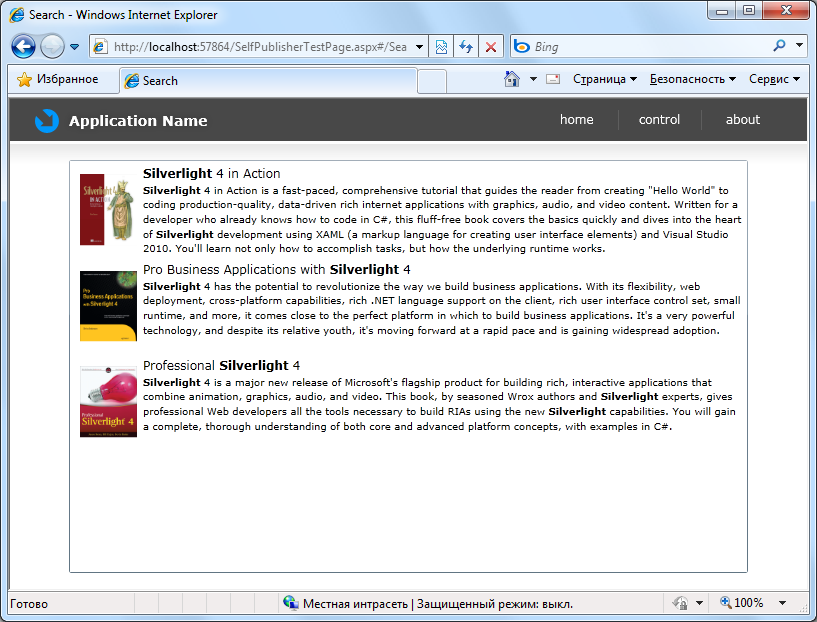
Рис. 4. Вид окна с результатами поиска.
Последнее, о чём мы поговорим – это язык запросов. Чтобы его использовать, не нужно модифицировать код, наша реализация уже его поддерживает. Пользователь может использовать логические операции объединения (AND) и/или исключения (OR), подстановочные символы "?" (когда пропущено 0 или 1 символ) и "*" (когда пропущено 0 или более символов), двойные кавычки для поиска устойчивых выражений и т.д. Например, если пользователь введёт запрос вида wcf OR “silverlight 4”, то в результате будут найдены все книги, заголовок или аннотация которых содержат ключевое слово "wcf" или ключевую фразу "silverlight 4".
Мы достигли желаемого результата, т.е. наше приложение теперь поддерживает полнотекстовый поиск. Несмотря на то, что за бортом осталось множество нюансов, которые можно встретить на практике, автор искренне надеется, что данная статья поможет вам быстро и безболезненно добавить полнотекстовой поиск в ваши приложения.
| Оценка 520 Оценить
|