Предисловие
Кровосмешение языков
Шаблоны
Пример
Все то же самое на C#
Прагмы managed и unmanaged
Так что же делать?
Заключение
Благодарности

|
Аннотация
Предисловие Кровосмешение языков Шаблоны Пример Все то же самое на C# Прагмы managed и unmanaged Так что же делать? Заключение Благодарности |
|
Жизнь Windows-программиста под Unix тяжела, но к счастью, коротка.
(народная мудрость)
Статья посвящена некоторым тонкостям использования шаблонов классов (class templates) языка C++ при совместном использовании “управляемого” (managed) и стандартного C++. Статья предполагает знание основ управляемого C++ в среде .Net. Перед прочтением настоящей статьи настоятельно рекомендуется ознакомиться со статьей Игоря Ткачёва “Управляемый C++”, опубликованной в RSDN Magazine #0.
| ПРЕДУПРЕЖДЕНИЕ "Мнения автора могут не совпадать с его точкой зрения (В. Пелевин, Generation “П”). Это означает, что некоторые утверждения в данной статье могут показаться спорными, но они лишь отражают консервативную точку зрения автора в момент написания статьи. Времена меняются, средства развиваются, и не исключено, что через некоторое время ситуация станет другой. Но в любом случае, приведенный здесь материал позволит лучше понять некоторые внутренние особенности платформы .Net, а примеры кода могут быть использованы для тестирования новых версий. |
Претенциозный эпиграф к данной статье выбран не случайно. Прошу ни в коем случае не воспринимать это как неуважение, но мое наблюдение показывает, что зачастую люди, долгое время пишущие для одной платформы, просто не задумываются о том, что существуют и другие. Я ничего не имею против такого подхода, наоборот, я и сам бы не прочь досконально освоить одну конкретную платформу и "маньячить" на ней всю свою оставшуюся жизнь. Так ведь не дают! Все меняется со скоростью света, и новые технологии возникают, как из волшебного горшочка с кашей. Куда уж тут проглотить! Так что же, каждый раз все переписывать заново? Нет, конечно! Постепенно приходишь к пониманию важности написания платформно-независимого кода, по крайней мере, той алгоритмической части, которую можно отделить от платформы. И вот она, библиотека алгоритмов, на чистом и индустриально стандартном C++, годами отработанная, bug-free, оптимизированная вручную, компилируется и работает везде и всюду. Какие, казалось бы, могут быть проблемы при использовании ее в .Net? А вот, оказывается, есть они, и связано это не с чем иным, как с Managed C++ Extensions (MC++) и, соответственно, с промежуточным языком MSIL. То есть, "все, что нажито непосильным трудом..." ну, вы поняли :-).
Как человек консервативный, я поначалу скептически воспринял всю эту возню с .Net, но сейчас эта платформа становится мне все более и более симпатичной. Жить становится проще, уходит COM Hell, можно спокойно "поженить" дружественный До-диез с до предела оптимизированным Си-плюс-плюс-кодом безо всяких там кошмарных COM-интерфейсов. И главное, работает! Надежно работает – были, конечно, всякие проблемы, типа Голубого Экрана Смерти при компиляции больших проектов, но сейчас они ушли.
Так что же, про смешение языков? А очень просто - нету никаких разных языков, все языки суть MSIL (платформо-независимый, хотя бы потенциально), в который все и транслируется, и который, кстати, до-транслируется в родной машинный код прямо при запуске. Значит, это не есть какой-то там убогий интерпретатор, это самый настоящий двухфазный компилятор! При этом MSIL является объектно-ориентированным, по крайней мере, я сделал такой вывод, разглядывая листинги, выдаваемые ildasm.exe. Однако, чудес в этом мире не бывает, за все приходится платить, и как результат, все, что проходит через MSIL, работает в 1.5-3 раза медленнее старого доброго C++. Для mainstream-ориентированного C# это прекрасный результат! Это лучше лучших из лучших виртуальных Java-машин.
Тем не менее, есть много задач, где даже в 1.5 раза медленнее – это слишком. Представьте себе лица заказчиков, которым скажут: "Вот новая перспективная платформа, Dot-Net, но теперь, дескать, наш супер-алгоритм структурной гипероптимизации параметрического синтеза будет работать 38 часов вместо 20". Такого рода задачи, для которых "pretty fast is never fast enough", были, есть, и всегда будут. И что бы там ни обещали, маловероятно, чтобы MSIL догнал C++, так же, как и C++ вряд ли догонит старый ФОРТРАН на комплексной арифметике.
Однако, выход есть – используй родной код C++ в виде библиотеки (скомпилированной без Managed Extensions) вместе с C#, и радуйся. Тем более, что и сделать-то для этого надо самую малость – простую обертку на MC++ для вызовов native-кода – это действительно не сложно. Когда я попытался проделать это с реальной библиотекой, оказалось, что все начинает работать именно в те самые полтора-три раза медленнее, чем родной код на C++. Начав разбираться, я в первую очередь выяснил, что на простых примерах ситуация не воспроизводится – все работает быстро! Дальнейшие исследования все-таки дали результат. Как правило, к библиотекам прилагаются .h файлы, под личиной которых может скрываться "черт знает что". В том числе и (о, ужас!) шаблоны!
Шаблоны классов и функций являются мощным механизмом оптимизации в C++ (да-да, именно оптимизации). В большинстве случаев не нужен истинный динамический полиморфизм с его медленными вызовами виртуальных функций, достаточно статического полиморфизма шаблонов. Кроме того, что в большинстве реализаций C++ прямой вызов работает раз в 10 быстрее виртуального, можно еще и использовать inline-функции, для которых накладные расходы – просто нулевые. Без ложной скромности скажу, что переписав один алгоритм с чистого С на C++, мне удалось ускорить его на 30-35 процентов только за счет средств языка (class templates & inline functions). В языке С единственным способом эмуляции параметризованных классов являются макросы препроцессора, при написании которых каждый раз возникает кошмарный рак головы. Однако же, и в макросах есть преимущество, заключающееся в том, что программист сам контролирует, где и когда они будут развернуты (instantiated). При использовании шаблонов это есть тайна, покрытая мраком, что в очередной раз и доказало использование MC++ вместе с наистандартнейшим C++. Итак, проблема в "инстанциировании". Ну, хватит воду мутить, перейду к примеру.
Он тривиален. Создайте новый проект Managed C++ Application и назовите его для определенности performance_test. Добавьте туда два новых файла:
unmanaged_module.h#ifndef UNMANAGED_MODULE_INCLUDED #define UNMANAGED_MODULE_INCLUDED template<class T> void my_sort(T* array, unsigned len) { unsigned i, j; T temp; for (i = 1; i < len; i++) { j = i; temp = array[j]; while(j > 0 && array[j - 1] > temp) { array[j] = array[j - 1]; j--; } array[j] = temp; } } int unmanaged_function(int n); #endif |
#include "unmanaged_module.h" //template void my_sort<int>(int*, unsigned); int unmanaged_function(int n) { int random_seed = 1234; int i; int* array = new int[n]; for(i = 0; i < n; i++) { int r = ((random_seed = random_seed * 214013 + 2531011) >> 16); array[i] = r % n - n/2; } my_sort(array, n); int sum = 0; for(i = 0; i < n; i++) sum += array[i]; delete [] array; return sum; } |
Все закомментированные строки оставьте как есть, они еще пригодятся (может быть). Выключите "Precompiled Headers" для unmanaged_module.cpp – оно там не надо, поскольку этот файл самодостаточен и не зависит ни от каких системных вещей (иначе он не скомпилируется). То, что находится в unmanaged_module.h, есть не что иное, как простая сортировка вставками (insertion sort), оформленная в виде шаблона функции. В unmanaged_module.cpp «живет» одна-единственная функция тестирования этой сортировки. Здесь простейшим способом генерируются псевдослучайные числа и вызывается собственно сортировка. Суммирование элементов в конце функции – всего лишь способ наверняка обмануть оптимизатор.
В файл performance_test.cpp включите следующий текст взамен сгенерированного:
#include "stdafx.h" #using <mscorlib.dll> #include <tchar.h> #include <stdio.h> #include <time.h> #include "unmanaged_module.h" using namespace System; #define NUM 5000 //template void my_sort<int>(int*, unsigned); int _tmain(void) { clock_t t1; clock_t t2; int sum = 0; int i; //int a[1] = {1}; //my_sort(a, 1); t1 = clock(); for(i = 0; i < NUM; i++) { sum += unmanaged_function(1000); } t2 = clock(); printf("%2.0f calls per second\n", NUM / (double(t2 - t1) / double(CLOCKS_PER_SEC))); return sum; } |
Теперь, не забыв включить Release-конфигурацию, скомпилируйте и запустите. У меня на P-III 1.3Ghz эта штука дает 330 вызовов в секунду (сортировка вставками все-таки).
Но при чем же здесь название unmanaged_module? А при том, что это был лишь первоначальный, пробный запуск – в нем все managed, соответственно, весь код транслируется в промежуточный MSIL.
Зайдите в свойства файла unmanaged_module.cpp и сделайте его действительно unmanaged – то есть в пункте “Compile as Managed” включите "Not using managed extensions". Скомпилируйте, запустите. У меня это начинает работать ровно в 3 раза быстрее! В три! То есть, 1030 вызовов в секунду. Все-таки старый добрый C++ все еще рулит. Поскольку компилятор обрабатывает отдельные файлы независимо, получаются 2 obj-файла, один скомпилированный в MSIL (performance_test.cpp), другой – в родной бинарный код Intel (unmanaged_module.cpp). И они прекрасно друг с другом живут. Можно даже и не стараться проверять это в полностью unmanaged-проекте – будет тот же результат. Вот как примерно происходят вызовы:
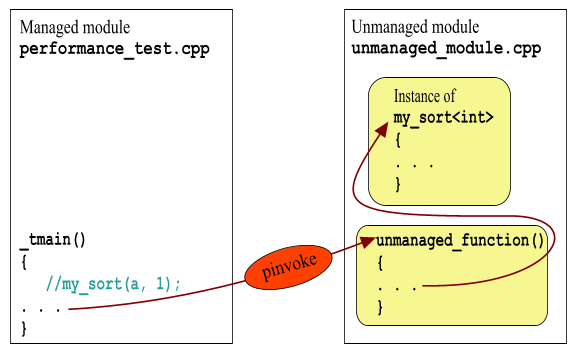
Так что же, настало счастье? Можно "обернуть" вызов unmanaged_function() в простейший MC++ класс – и вызывай его из любого языка? Почти, есть одна ложка дегтя, большая ложка. Раскомментируйте в performance_test вот это:
int a[1] = {1};
my_sort(a, 1);
|
Скомпилируйте, запустите. Увы! Изначальные тормоза вернулись на место :-(. Но что же произошло? Ведь этот один-единственный вызов ничего не делает и ничего меняет, тем более, что он находится за пределами кода, в котором измеряется время. Так вот, все это из-за развертывания шаблонов. Дело в том, что теперь, как в unmanaged_module.obj, так и в performance_test.obj живет по экземпляру кода my_sort<int>. А поскольку нехорошо иметь два экземпляра одного и того же кода в исполняемом модуле, компоновщик должен уметь оставить только один из них – все равно они идентичны. И теперь, когда включено упоминание об использовании my_sort<int> в managed-секции (perfornace_test.cpp), появилось два идентичных экземпляра кода... Идентичных по функциональности, но не по эффективности! А компоновщик предпочитает медленный managed-вариант быстрому и хорошему unmanaged, в результате чего все старания идут насмарку. Вот как это происходит:
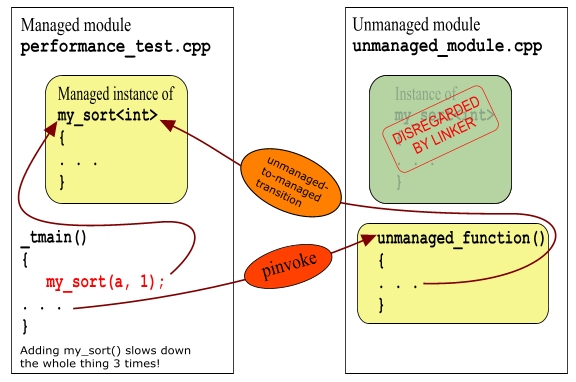
Дополнительно убедиться в справедливости вышесказанного можно, посмотрев код performance_test.exe при помощи ildasm.exe. В первом случае там нет my_sort<int>(), во втором – есть, причем на IL-asm. Можно даже и не стараться с явным развертыванием шаблонов – не помогает, проверено. Точнее, помогает включить развертывание в медленную managed-секцию, если в preformance_test.cpp раскомментировать вот это:
template void my_sort<int>(int*, unsigned); |
Впрочем, есть вариант с явным развертыванием, но об этом – позже.
Вы скажете: "Ну и что, не используй шаблонов в managed-секции". А как же мне их не использовать, если для написания managed-обертки я-таки обязан включить .h файл, в котором, как правило, есть что-то типа:
my_class
{
. . .
private:
std::map<int, int> m_my_map;
};
|
А это означает, что как минимум конструктор и деструктор std::map<int, int> будут "жить" в managed-коде. И не дай бог, где-то в других местах .h файла (в inline-функциях) встретится что-то типа m_my_map.find(i); Тогда все, что связано с std::map::find() тоже будет развернуто здесь же. Я, кстати, проводил эксперимент с STL-контейнерами: библиотека использует, скажем, тот же std::map. Так, по мере появления вызовов разных функций std::map в managed-секции, наблюдается неуклонное падение производительности. Такие дела. Образно говоря, managed-объектники как бы "выкачивают" часть эффективно сгенерированного кода в свое MSIL-царство. Представляете, какая каша там в результате творится?
Для полноты эксперимента стоит провести испытание на C#, поскольку есть мнение, что оптимизатор C# работает лучше, чем MC++. Создайте новый проект C# Console Application, назвав его cs_test, и замените сгенерированный код на следующий:
Исходный текст тестового приложения на C#using System; namespace cs_test { class MySort { //unsafe public static void Sort(int[] array, int len) { int i, j; int temp; for (i = 1; i < len; i++) { j = i; temp = array[j]; while(j > 0 && array[j - 1] > temp) { array[j] = array[j - 1]; j--; } array[j] = temp; } } public static int TestSort(int n) { int random_seed = 1234; int i; int[] array = new int[n]; for(i = 0; i < n; i++) { int r = ((random_seed = random_seed * 214013 + 2531011) >> 16); array[i] = r % n - n/2; } Sort(array, n); int sum = 0; for(i = 0; i < n; i++) sum += array[i]; return sum; } }; class Class1 { [STAThread] static void Main(string[] args) { int sum = 0; int i; long t1 = Environment.TickCount; for(i = 0; i < 5000; i++) { sum += MySort.TestSort(1000); } long t2 = Environment.TickCount; System.Console.WriteLine("Performance=" + 5000.0 / ((t2 - t1) / 1000.0) + " calls per second"); } } } |
Ну что же, результат неплохой. На моей конфигурации (P-III 1.3GHz) данный тест показывает 428 вызовов в секунду, что на 30% лучше MC++. Однако, как и следовало ожидать, C++ догнать тяжело. Заметим, что пометка метода Sort как unsafe ничего не меняет. Возможно, компилятор “распознал”, что здесь не может возникнуть выхода за пределы массива, и отключил проверку границ. Но это всего лишь предположение. Вывод заключается в том, что C# генерирует действительно более оптимальный код, но, тем не менее, сильно отстающий от C++. Напомним, что целью статьи является не столько сравнение C++, MC++ и C#, сколько попытка проанализировать, что же надо предпринять, чтобы весь legacy-код на стандартном C++ мог быть использован без потерь производительности.
Итак, вернусь к C++. Есть такие директивы:
// . . . managed code #pragma unmanaged . . . // unmanaged function #pragma managed // . . . managed code continue |
Казалось бы, достаточно написать включение файла unmanaged_module.h внутри этих директив
#pragma unmanaged #include “umnanaged_module.h” #pragma managed |
и все станет хорошо. Но, как говорится, “в действительности все совсем не так, как на самом деле”. Эти “прагмы” действуют только на определения функций, но не на их объявления. Точнее говоря, для простых функций это работает, то есть, если у нас есть следующие объявление и определение:
#pragma unmanaged int increment(int a); #pragma managed int increment(a) { return a + 1; } // Работает! Этот код и впрямь unmanaged! |
и все это попадает в файл, скомпилированный с ключом /clr (managed code), то тело функции increment будет действительно unmanaged.
Но это не работает для классов и, тем более, для inline-функций и шаблонов:
#pragma unmanaged class my_class { public: int increment(int a); } #pragma managed int my_class::increment(a) { return a + 1; } // Не работает. Если определение находится в // managed-секции, будет сгенерирован MSIL-код. |
И тут возникает вопрос. Что есть тело функции? Когда вы пишете в .h-файле что-то типа
inline int increment(a) { return a + 1; } |
вы думаете, что это оно и есть. Нет! Это только лишь определение и ничего больше! Ключевым словом здесь является inline. Тело функции возникает “само по себе”, в тот момент, когда вы ее используете (раскрываете). То же самое относится и к шаблонам. Функции-члены шаблонов классов, так же, как и простых функций, имеют одну особенность, а именно, они могут иметь более одного тела, то есть могут быть развернуты в нескольких независимых obj-файлах. При этом компоновщик должен уметь справиться с такой ситуацией. Судите сами, если вы напишете две простые функции с одним именем и идентичной сигнатурой в двух разных .cpp-файлах, компоновщик “пожалуется” на двойное определение. В случае же с my_sort<int>() он прекрасно справляется, хотя там тоже возникают два идентичных внешних символа. Как раз эта особенность и губит производительность в .Net.
| ПРИМЕЧАНИЕ Если функция помечена как inline (явно, или неявно – внутри описания класса), то это отнюдь не гарантирует того, что функция будет действительно “развернута”. То есть, это оставляется на усмотрение оптимизатора. В конце концов, в Debug-конфигурации inline-функции не разворачиваются вообще. Таким образом, у нас тоже появляется по экземпляру функции в каждом obj-файле, где она используется. В этом случае поведение inline-функций при компоновке ничем не отличается от поведения шаблонов классов. |
Как уже было сказано, чудес не бывает. Очевидный способ ускорить работу – это полная и абсолютная изоляция. Я имею в виду, что можно создать proxy-классы, которые обернут managed-код и скроют .h файлы основной библиотеки. Это неудобно – на каждый класс у нас появляются еще два, proxy и managed-обертка. В конце концов, при хорошем дизайне не имеет смысла выставлять наружу все мельчайшие детали – надо укрупнять функциональность (так же, как и при использовании старого COM).
Но даже и это не спасает! STL сейчас используется довольно широко. Да что там STL – есть много других полезных библиотек, например, ACE, а уж про BOOST и говорить не стоит. Представьте, что у вас есть полностью закрытая библиотека, вместе с которой идет один-единственный .h файл, даже без классов, а с простыми функциями. Но эта библиотека, где-то там внутри, использует тот же std::map<int, int>, который снаружи не видно и не слышно. Так вот, не используйте в этом случае std::map<int, int> в managed-секции – будут ровно те же грабли. А как же узнать, что можно, а что нельзя? А никак! Ничего нельзя, на всякий случай – только .Net классы. Что говорите, DLL? Спасибо, DLL Hell проходили.
Компилятор оставляет MSIL-код, выбрасывая более быстрый, по одной единственной причине – потому, что файл performance_test.obj следует первым. Вот и решение проблемы! Надо просто поменять порядок файлов, чтобы unmanaged_module.cpp был первым. Но не все так просто. В VS.NET отсутствует явный способ указания порядка файлов. Если проект состоит только из исходников, как в нашем примере, можно все их удалить из проекта, после чего добавить в нужном порядке – сначала unmanaged_module.cpp, затем – performance_test.cpp. Не забудьте снова установить нужные опции для unmanaged_module.cpp. Все должно работать быстро. Но, во-первых, это крайне неудобно. Если нужно добавить новый unmanaged-файл, то сначала придется удалять все managed-файлы, добавлять новые unmanaged, после чего – старые managed. Во-вторых, я бы не стал твердо рассчитывать на эту особенность, поскольку она не ,документирована и, в общем-то, выглядит не вполне надежно. И в-третьих, что делать, если надо подключить unmanaged-библиотеки? Библиотечные файлы, указанные в Linker -> Input -> Additional Dependencies, всегда становятся в конец командной строки компоновщика. Но даже если бы и была возможность указать библиотеки первыми, неизвестно, как бы компоновщик это воспринял. В общем, сложность системы слишком велика, чтобы делать определенные выводы о ее поведении в таких “тонких” случаях.
Прежде всего скажу, что это не всегда возможно, а зачастую – практически нереально, но в определенных частных случаях может помочь. Поскольку компилятор и компоновщик могут раскрывать код в managed-секции, надо дать им такую возможность, указав, что он должен быть unmanaged. Понятно ли я выразился? :-) Короче говоря, в файле performance_test.cpp сделайте так:
#pragma unmanaged template void my_sort<int>(int*, unsigned); #pragma managed |
При этом все работает быстро – проверьте! Заметим, что указание явного раскрытия в unmanaged_module.cpp не помогает, поскольку my_sort<int>() там и так уже раскрыта неявно.
Однако же, это нелегко – раскрывать таким образом все классы и функции. Без тщательного анализа кода здесь не обойтись. А если это STL? При добавлении в библиотеку нового контейнера с новыми параметрами, надо четко следить за тем, описана ли у нас соответствующее раскрытие. Такие дела.
Проблема решалась бы проще, если бы компилятор (или компоновщик?) умел генерировать полностью развернутые имена для всех раскрытых шаблонов. Тогда можно было бы методом copy/paste объявить их явно.
В слово "хак" обычно вкладывается негативный смысл, хотя раньше (МТИ, 60-е годы) это слово означало "изящное техническое решение". Да и вообще, вот замечательная книга на эту тему: http://www.cooler.it/hackers/- всем отдыхать полчаса (Кин-дза-дза!) и читать!
Я бы не назвал свое решение изящным, но что-то в этом есть. Помните старый анекдот?
Пришел мужик в баню, помылся, попарился. И тут обнаружил, что забыл полотенце. Думает, что же делать? Вдруг видит большую надпись "ЗАНАВЕСКАМИ НЕ ВЫТИРАТЬСЯ!". - О! А что? Хорошая мысль!
Так вот, в любом руководстве по .Net английским по белому написано: "...don't use inline assembly instructions in managed C++ functions". Что в общем-то и понятно, поскольку родной бинарный код не может быть однозначно транслирован обратно в MSIL. Этот побочный эффект мы и используем – просто включите в my_sort() любую ассемблерную команду, и наша функция уже никогда не сможет быть раскрыта в MSIL коде:
__asm nop |
В этом случае диаграмма вызовов будет такой:
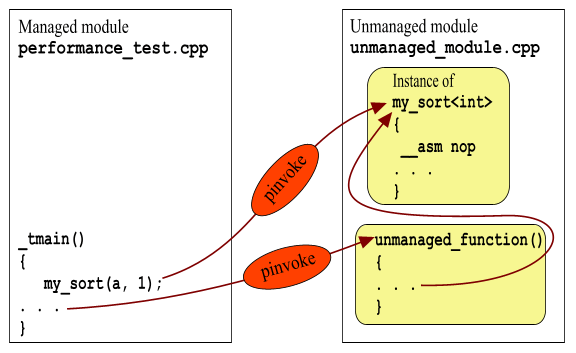
Разумеется, в реальности надо сделать #define, заключенный в #ifdef/#elif/#endif. Ну не мне вас этому учить.
Практика показала, что при включении ассемблерных инструкций в любую C++ managed-функцию, компилятор пытается сгенерировать родной машинный код. Если же это невозможно, например в managed-классе, объявленном как __gc, то он ругается не на “использование __asm в managed code”, а на невозможность использования managed-типов внутри unmanaged-кода. Что-то я совсем вас запутал. Попробуйте в performance_test.cpp добавить следующее:
__gc class test { public: test() { __asm nop } }; |
И обратите внимание на текст сообщения об ошибке: “. . .error C3821: 'test::test(void)': managed type cannot be used in an unmanaged function”. А где же здесь использование managed type? Неявно присутствующий this – это он и есть.
Но смысл даже не в этом, смысл в том, что (еще раз) компилятор, встречая ассемблерную инструкцию, молча пытается сгенерировать unmanaged-код, и только в том случае, если это невозможно, выдает ошибку. Для нашего _tmain() это возможно, и в этом можно убедиться, добавив __asm nop в _tmain(), и посмотрев код при помощи ildasm.exe. При этом, если оставить my_sort() без явного раскрытия и без ассемблерных инструкций, он будет скомпилирован в MSIL. И, следовательно, будет вызываться из unmanaged _tmain() как unmanaged-to-managed transition. Такие дела.
В качестве побочного эффекта, на моем P-III один лишний nop в начале функции my_sort() дал дополнительное увеличение производительности на 20%. Думаю, что это связано cо спецификой выравнивания на P-III для данной конкретной функции при данных опциях оптимизации. На P-IV никакой разницы в скорости нет. В общем, есть такой прием, как добавление nop'ов в критические участки кода для лучшего выравнивания инструкций, но это уже относится к вопросу о глубокой оптимизации для конкретного процессора. Так что этот эффект в my_sort() – просто случайность.
Идеальных решений не существует. Microsoft заявляет, что код MSIL является платформно-независимым. Очень хотелось бы в это верить – это был бы действительно прорыв в технологиях. Но использование платформно-независимого MSIL автоматически означает невозможность трансляции чего бы то ни было в родной машинный код. Все приведенные выше примеры рассчитаны на то, чтобы максимально использовать процессор, не заботясь о переносимости в виде бинарного MSIL-кода. Насколько я понимаю, идея переносимости MSIL находится только лишь в зачаточном состоянии, но "тем не менее, если смотреть в перспективу", ну и так далее. Так вот, все о чем было написано – это о свободе выбора – максимальная производительность или максимальная совместимость. В текущей реализации .Net такого выбора пока не существует. Судите сами. Решили, к примеру, заботиться о совместимости – любая ассемблерная инструкция эту совместимость ломает. Решили задействовать максимальную производительность в ущерб совместимости – снова возникают "подводные грабли".
Но все-таки хорошее решение могло бы существовать. Самая малость – ключ компоновщика, который бы указывал, что делать и проверять: в режиме "full compatibility" – все транслировать в MSIL и ругаться на любую попытку использовать native code, то есть, все должно быть managed. В режиме "maximum performance" всегда отдавать предпочтение unmanaged instantiations в ущерб managed. Это же очень просто!
А может, такое действительно есть?
Огромное спасибо Игорю Ткачёву и Павлу Кузнецову за конструктивные замечания и предложения.