 Оценка 1020
[+1/-0]
Оценка 1020
[+1/-0]

 Оценить
Оценить 






| Оценка 1020
[+1/-0]
Оценить
|
В этом разделе мы рассмотрим новые API для многопоточного программирования, появившиеся в .Net Framework 4.0 и повышающие эффективность использования многоядерных процессоров:
Эти библиотеки широко известны (неформально) как PFX (Parallel Framework). Класс Parallel вместе с конструкциями для параллелизма задач (task parallelism constructs) называются Task Parallel Library или TPL.
В Framework 4.0 также добавлен ряд низкоуровневых конструкций, которые будут также полезны и при обычной работе с многопоточностью. Мы рассмотрели их ранее:
Для понимания этого раздела необходимо разобраться в фундаментальных принципах, рассмотренных в частях 1-4, в особенности в понятиях блокировки и безопасности потоков.
Все исходные коды этого раздела доступны в виде интерактивных примеров на LINQPad. Чтобы получить доступ к этим примерам, щелкните по Download More Samples на вкладке LINQPad Samples, слева вверху, и выберите C# 4.0 in a Nutshell: More Chapters.
В последнее время скорость центральных процессоров перестала стремительно расти, и производители сосредоточились на увеличении количества ядер. И это является проблемой для нас, как программистов, поскольку при этом наш код, предназначенный для работы в однопоточной среде, не начинает работать быстрее автоматически.
Воспользоваться преимуществами наличия нескольких ядер легко серверным приложениям, в которых каждый поток может независимо обрабатывать отдельные запросы от клиентов, но клиентским приложениям этого добиться сложнее, поскольку в этом случае обычно требуется преобразовать код, интенсивно использующий вычисления, следующим образом:
И, хотя вы можете сделать все это с помощью классических конструкций для работы с многопоточностью, такое решение будет неуклюжим, особенно шаги секционирования и объединения результатов. Дополнительной проблемой является то, что для обеспечения потокобезопасности эти конструкции используют типичную стратегию блокировок, которая при одновременной работе нескольких потоков с одними и теми же данными приводит к высокой конкуренции.
Библиотека PFX специально разработана, чтобы помочь разработчику в таких случаях.
Параллельное программирование (parallel programming) – это техника программирования, которая использует преимущества многоядерных или многопроцессорных компьютеров и является подмножеством более широкого понятия многопоточности (multithreading).
Существует две стратегии разделения работы между потоками: параллелизм данных (data parallelism) и параллелизм задач (task parallelism).
Если над большим объемом данных должен быть выполнен некий набор задач, можно распараллелить его таким образом, чтобы каждый поток выполнял (одинаковый) набор задач на подмножестве значений. Этот подход называется параллелизмом данных, поскольку мы разбиваем данные между потоками. В противоположность этому, при параллелизме задач мы разбиваем задачи, и в таком случае каждый поток выполняет разную задачу.
В общем случае, параллелизм данных проще и лучше масштабируется на высокопроизводительном оборудовании, поскольку уменьшает или полностью устраняет совместное использование данных (таким образом уменьшая конкурентный доступ и другие проблемы безопасности потоков). Кроме того, параллелизм данных основывается на том факте, что данных обычно значительно больше, чем отдельных задач, что увеличивает возможности параллельной обработки.
Параллелизм данных также способствует структурному параллелизму (structured parallelism), что означает, что модули параллельной работы начинают и заканчивают работу в одном и том же месте вашей программы. В противоположность этому, параллелизм задач ведет к неструктурированному параллелизму, что означает, что места, в которых модули начинают и заканчивают свою работу, могут быть разбросаны по всему вашему приложению. Структурный параллелизм проще и менее подвержен ошибкам, и позволяет вам возложить всю сложную работу по секционированию данных и координации потоков (и даже объединению результатов) на библиотеки.
PFX включает в себя два уровня функциональности. Верхний уровень состоит из двух API структурного параллелизма данных: PLINQ и класса Parallel. Нижний уровень содержит классы для параллелизма задач – плюс дополнительный набор конструкций, упрощающих решение задач параллелельного программирования.
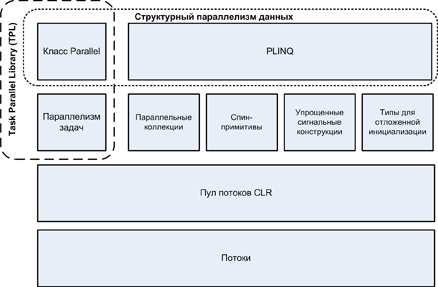
Рисунок 1.
Библиотека PLINQ предоставляет самую богатую функциональность: она автоматизирует все этапы распараллеливания вычислений, включая разделение работы на задачи, выполнение этих задач различными потоками и объединение результатов в одну выходную последовательность. Ее использование называется декларативным (declarative), поскольку вы просто объявляете (declare) то, что вы хотите выполнить параллельно (подобно запросам LINQ), и позволяете ей заботиться о деталях реализации. В противоположность этому, другие подходы являются императивными: в этом случае вам нужно явно написать код по разделению задачи и объединению результатов. В случае класса Parallel вы должны объединить результаты самостоятельно; в случае конструкций параллелизма задач вы должны еще и самостоятельно разделить задачу:
|
Разделение задачи |
Объединение результатов |
|
|---|---|---|
|
PLINQ |
Да |
Да |
|
Класс Parallel |
Да |
Нет |
|
Параллелизм задач из PFX |
Нет |
Нет |
Параллельные коллекции (concurrent collections) и спин-примитивы (spinning primitives) помогают в решении низкоуровневых задач параллельного программирования, что очень важно, поскольку PFX проектировалась для работы не только на современном оборудовании, но и с будущими поколениями процессоров со значительно большим количеством ядер. Если вы хотите перетащить кучу срубленных деревьев, и в вашем распоряжении есть 32 человека, самым сложным является координация людей таким образом, чтобы они не путались друг у друга под ногами. То же самое касается распределения алгоритма между 32 ядрами: при использовании обычных блокировок для защиты общих ресурсов, результирующая блокировка ресурса может привести к тому, что только часть ядер будет на самом деле занята одновременно. Параллельные коллекции оптимизированы специально для высококонкурентного доступа и сосредоточены на минимизации или устранении блокировок. PLINQ и класс Parallel в частности, основываются на параллельных коллекциях и спин-примитивах для эффективной реализации своей работы.
|
PFX и классическая многопоточность Классические сценарии работы с многопоточностью полезны даже на одноядерных компьютерах, даже при отсутствии реального распараллеливания. Эти сценарии мы уже рассматривали: они включают в себя задачи по созданию отзывчивого пользовательского интерфейса и загрузке двух Web-страниц одновременно. Некоторые конструкции, рассмотренные в разделах, посвященных параллельному программированию, также иногда применяются в классических задачах многопоточности. В частности: PLINQ и класс Parallel полезны, когда вы хотите выполнить операции параллельно и дождаться окончания их выполнения (структурный параллелизм, structured parallelism). Это включает задачи, не требующие нагрузки центрального процессора, такие как вызов Web-сервиса. Конструкции параллелизма задач полезны, когда вы хотите выполнить некоторую операцию в потоке из пула потоков, а также управляете последовательностью выполняемых действий с помощью продолжений (continuations) и родительских/дочерних задач. Параллельные коллекции иногда полезны, когда вам нужна потокобезопасная очередь, стек или словарь. С помощью BlockingCollection легко реализовать структуры типа поставщик/потребитель. |
Основной сценарий использования PFX – параллельное программирование: повышение эффективности использования многоядерных процессоров для ускорения выполнения кода с большим количеством вычислений.
Самая большая сложность в эффективном использовании многоядерных процессоров заключается в законе Амдала, который заключается в том, что максимальное повышение эффективности за счет распараллеливания ограничено кодом, который должен вычисляться последовательно. Например, если только две трети времени выполнения алгоритма могут быть распараллелены, вы никогда не получите троекратного прироста производительности, даже при бесконечном количестве ядер.
Так что, прежде чем продолжать, стоит проверить, является ли распараллеливаемый код узким местом. Кроме того, стоит подумать о том, должен ли код выполнять такое количество вычислений; оптимизация обычно является самым простым и эффективным подходом. Впрочем, здесь может потребоваться компромисс, поскольку использование некоторых техник оптимизации может усложнить распараллеливание кода.
Наиболее просто получить выгоду при решении так называемых задач чрезвычайного параллелизма (embarrassingly parallel problems) – когда вся задача может быть легко разбита на подзадачи, которые могут выполняться сами по себе (структурный параллелизм хорошо подходит под этот круг задач). Примерами могут служить задачи обработки изображений, трассировка лучей, подходы на основе «грубой силы» в математике или криптографии. Примером задач, не относящихся к этой категории, является реализация оптимизированной версии алгоритма быстрой сортировки, для получения хороших результатов нужно хорошо постараться и в этом случае понадобится неструктурный параллелизм.
PLINQ автоматически распараллеливает локальные LINQ-запросы. PLINQ легко использовать, поскольку он берет на себя разбиение задачи и объединения результатов.
Для использования PLINQ просто вызовите метод AsParallel() для входящей последовательности и затем продолжайте использовать LINQ-запросы обычным образом. Следующий запрос вычисляет простые числа от 3 до 100 000, используя все ядра процессора:
// Находим простые числа с помощью простого (неоптимизированного) алгоритма. IEnumerable<int> numbers = Enumerable.Range (3, 100000-3); var parallelQuery = from n in numbers.AsParallel() where Enumerable.Range (2, (int) Math.Sqrt (n)).All (i => n % i > 0) select n; int[] primes = parallelQuery.ToArray(); |
AsParallel – это метод-расширение, объявленный в классе System.Linq.ParallelEnumerable. Он оборачивает входные данные в последовательность, построенную на основе ParallelQuery<TSource>, что приводит к тому, что операторы запросов LINQ будут вызывать альтернативный набор методов расширения, определенные в классе PrallelEnumerable. В этом классе определены параллельные реализации всех стандартных операторов запроса, которые, по сути, разбивают входную последовательность на части (), каждая из которых обрабатывается разными потоками, объединяя затем результаты в одну выходную последовательность:
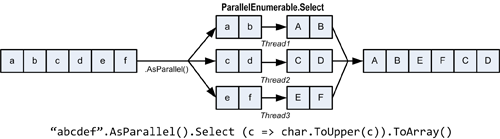
Рисунок 2.
Вызов метода AsSequential() производит операцию, обратную AsParallel(), то есть преобразует ParallelQuery<TSource> в IEnumerable<T>, чтобы последующие операторы вызывали стандартные операторы запросов и выполнялись последовательно. Это необходимо перед вызовом методов со сторонними эффектами или потоконебезопасных методов.
В операторах запросов, принимающих две входящие последовательности (Join, GroupJoin, Concat, Union, Intersect, Except и Zip), нужно применять AsParallel() к обеим входящим последовательностям (иначе будет сгенерировано исключение). Не нужно, однако, применять AsParallel внутри запроса, поскольку операторы PLINQ выдают другую ParallelQuery-последовательность. Повторный вызов AsParallel будет неэффективен, так как приведет к слиянию результатов и повторному распараллеливанию запроса.
mySequence.AsParallel() // Оборачиваем последовательность в ParallelQuery<int> .Where (n => n > 100) // Создаем еще одну последовательность ParallelQuery<int> .AsParallel() // Не нужно и неэффективно! .Select (n => n * n) |
Не все операторы запросов могут эффективно распараллеливаться. Те операторы, для которых это невозможно, реализуются в PLINQ последовательно. PLINQ может также выполнить оператор последовательно, если он подозревает, что накладные расходы на параллелизм на самом деле замедлят выполнение запроса.
PLINQ применим только к локальным коллекциям: он не работает с LINQ to SQL или с Entity Framework, поскольку в этих случаях LINQ-запросы преобразуются в SQL, которые затем выполняются на сервере баз данных. Однако вы можете использовать PLINQ для выполнения дополнительных локальных запросов к результатам, полученным с помощью запросов к БД.
| ПРЕДУПРЕЖДЕНИЕ Если в процессе выполнения PLINQ-запроса генерируется исключение, то PLINQ генерирует AggregateException, в свойстве InnerExceptions которого будет содержаться настоящее исключение (или исключения). Подробнее см. раздел Работа с AggregateException. |
|
Почему AsParallel не используется по умолчанию? Поскольку AsParallel прозрачно распараллеливает запросы LINQ, возникает вопрос: «Почему Майкрософт просто не распараллеливает стандартные операторы запросов и не использует PLINQ по умолчанию?» Существует несколько причин, почему этот подход не используется по умолчанию. Во-первых, использование PLINQ приносит пользу только при наличии значительного количества вычислительных задач, распределенных по рабочим потокам. Многие запросы LINQ to Objects выполняются очень быстро, и распараллеливание не только не нужно – накладные расходы на разделение данных, объединения результатов и координацию дополнительных потоков могут, на самом деле, только ухудшить производительность. Кроме того: - результат работы PLINQ запроса (по умолчанию) может отличаться от результатов выполнения LINQ-запроса порядком выходных элементов. - PLINQ заворачивает исключения в AggregateException (для обработки нескольких возможных сгенерированных исключений). - PLINQ дает ненадежные результаты, если запросы вызывают потоконебезопасные методы. И, в конце концов, PLINQ предоставляет слишком мало возможностей для оптимизации и тонкой настройки. Если обременить стандартные API LINQ to Objects такими нюансами, это приведет к беде. |
Как и обычные LINQ-запросы, PLINQ-запросы выполняются отложенно. Это означает, что выполнение начнется только тогда, когда вы начнете использовать результаты запроса – обычно в цикле foreach (это может произойти также в операторе преобразования, таком как ToArray, или операторе, возвращающем единственный элемент или значение).
Однако когда вы перебираете результаты запроса, вычисление несколько отличается от того, что происходит при выполнении обычного запроса. Последовательный запрос полностью управляется вызывающим кодом “pull”-образом: каждый элемент входной последовательности извлекается только по требованию вызывающего кода. Параллельный запрос обычно использует независимые потоки для извлечения элементов из входной последовательности, несколько опережая потребности вызывающего кода (как телесуфлер для комментатора или «анти-шок» системы в CD-проигрывателях). Затем он обрабатывает элементы параллельно с помощью цепочки запросов (query chain), сохраняя в маленьком буфере результаты, которые доступны оттуда вызывающему коду по требованию. Если вызывающий код приостанавливает или прерывает перебор, обработчик запроса также приостанавливает или прекращает свое выполнение, чтобы не расходовать понапрасну память и процессорное время.
Вы можете изменить поведение буферизации PLINQ путем вызова метода WithMergeOption после вызова метода AsParallel. Значение по умолчанию – AutoBuffered – в целом дает наилучший результат. NoBuffered отключает буферизацию, и полезно, когда вы хотите получить результат как можно скорее; FullyBuffered полностью кэширует результаты, прежде чем вернуть их вызывающему коду (OrderВy и Reverse всегда используют последний вариант, впрочем, как и функции получения элемента, агрегации или преобразования).
Побочным эффектом параллельного выполнения операторов запросов является то, что при объединении результатов порядок элементов не обязательно совпадает с исходным, что и показано на предыдущем рисунке. Другими словами, соблюдение порядка следования элементов последовательности, которое гарантируется операторами LINQ, не гарантируется операторами PLINQ.
Если требуется сохранить порядок элементов, нужно сделать это явно путем вызова метода AsOrdered() после вызова AsParallel():
myCollection.AsParallel().AsOrdered()... |
Вызов метода AsOrdered для последовательностей большого размера снижает производительность, поскольку в этом случае необходимо отслеживать исходную позицию элементов.
Вы можете нивелировать снижение эффективности вызова AsOrdered, вызвав позже в запросе AsUnordered: это создает определенную точку, после которой запрос может выполняться эффективнее. Так что, если вы хотите сохранить порядок следования элементов входной последовательности только для первых двух операторов, вы можете поступить таким образом:
inputSequence.AsParallel().AsOrdered() .QueryOperator1() .QueryOperator2() .AsUnordered() // С этого момента порядок не имеет значения .QueryOperator3() ... |
Оператор AsOrdered не применяется по умолчанию, поскольку для большинства запросов не важен исходный порядок входной последовательности. Другими словами, если бы AsOrdered применялся по умолчанию, то для повышения эффективности пришлось бы вызывать AsUnordered для большинства параллельных запросов, что было бы слишком обременительно.
На данный момент существует ряд практических ограничений того, что PLINQ может распараллеливать. Эти ограничения могут быть ослаблены после выпусков сервис-паков или будущих версий .Net Framework.
Следующие операторы запросов предотвращают распараллеливание запросов, если исходные элементы не находятся в своих исходных позициях:
Большинство операторов изменяют индексную позицию элементов (включая операторы, удаляющие элементы, например, Where). Это значит, что если вы хотите использовать перечисленные выше операторы, то они должны идти в начале запроса.
Следующие операторы являются распараллеливаемыми, но они используют дорогую стратегию секционирования (partitioning stategy), что иногда может привести к менее эффективному результату, нежели последовательная обработка.
Версия оператора Aggregate, принимающая начальное значение, в своем стандартном виде не может быть распараллелена, для этого PLINQ предоставляет специальную перегрузку (о ней будет сказано ниже).
Все остальные операторы являются распараллеливаемыми, хотя их применение и не гарантирует, что запрос будет распараллелен. PLINQ может выполнить запрос последовательно, если определит, что накладные расходы на распараллеливание приведут к замедлению выполнения этого запроса. Можно изменить это поведение и принудительно заставить запрос выполняться параллельно путем вызова следующего метода после AsParallel():
.WithExecutionMode (ParallelExecutionMode.ForceParallelism) |
Предположим, что мы хотим реализовать проверку правописания, которая будет быстро обрабатывать очень большие документы и будет использовать все доступные ядра процессора. Выражая алгоритм в виде LINQ-запроса, можно очень легко распараллелить эту задачу.
Для начала нужно загрузить словарь английских слов в HashSet для эффективного поиска:
if (!File.Exists ("WordLookup.txt")) // Содержит порядка 150,000 слов new WebClient().DownloadFile ( "http://www.albahari.com/ispell/allwords.txt", "WordLookup.txt"); var wordLookup = new HashSet<string> ( File.ReadAllLines ("WordLookup.txt"), StringComparer.InvariantCultureIgnoreCase); |
Затем мы воспользуемся этим контейнером для создания тестового «документа», состоящего из миллиона случайных слов. После создания этого документа мы добавим в него несколько ошибок:
var random = new Random(); string[] wordList = wordLookup.ToArray(); string[] wordsToTest = Enumerable.Range (0, 1000000) .Select (i => wordList [random.Next (0, wordList.Length)]) .ToArray(); wordsToTest [12345] = "woozsh"; // Делаем несколько wordsToTest [23456] = "wubsie"; // ошибок. |
Теперь можно выполнить параллельную проверку правописания путем проверки wordsToTest с помощью wordLookup. PLINQ делает это очень простым:
var query = wordsToTest .AsParallel() .Select ((word, index) => new IndexedWord { Word=word, Index=index }) .Where (iword => !wordLookup.Contains (iword.Word)) .OrderBy (iword => iword.Index); query.Dump(); // Отображаем результаты с помощью LINQPad |
Вот вывод, полученный с помощью LINQPad:
|
OrderedParallelQuery<IndexedWord> (2 элемента) |
|
|
Word |
Index |
|
woozsh |
12345 |
|
wubsie |
23456 |
IndexedWord – это структура, определенная следующим образом:
struct IndexedWord { public string Word; public int Index; } |
Метод wordLookup.Contains, используемый в предикате, делает разумным распараллеливание этого запроса.
Можно немного упростить этот запрос путем использования анонимного типа вместо структуры IndexedWord. Однако это негативно скажется на производительности, поскольку анонимные типы (будучи классами и, таким образом, ссылочными типами) влекут за собой выделение памяти в управляемой куче и последующую сборку мусора.
Эта разница может быть незаметна при последовательном выполнении запросов, но при параллельном выполнении запросов использование стековых переменных может быть более эффективным. Это связано с тем, что использование стековых переменных легко распараллеливается (поскольку у каждого потока есть свой стек), в то время как все потоки должны состязаться за использование одной кучи, управляемой одним менеджером памяти и сборщиком мусора.
Давайте расширим наш пример и распараллелим создание нашего тестового списка. Этот список создается с помощью LINQ-запроса, значит, это должно быть просто. Вот последовательная версия:
string[] wordsToTest = Enumerable.Range (0, 1000000) .Select (i => wordList [random.Next (0, wordList.Length)]) .ToArray(); |
К сожалению, вызов метода random.Next не является потокобезопасным, так что решение не сводится к простой вставке AsParallel в существующий запрос. Возможным решением является создание функции, которая будет использовать блокировку вокруг вызова random.Next; однако это ограничит параллелизм. Более подходящим решением является использование ThreadLocal<Random> для создания отдельного объекта Random для каждого потока. Тогда мы сможем распараллелить запрос следующим образом:
var localRandom = new ThreadLocal<Random> ( () => new Random (Guid.NewGuid().GetHashCode()) ); string[] wordsToTest = Enumerable.Range (0, 1000000).AsParallel() .Select (i => wordList [localRandom.Value.Next (0, wordList.Length)]) .ToArray(); |
Фабричная функция по созданию объекта Random передает хэш-код GUID-а, гарантируя, что два объекта Random, созданные за короткий промежуток времени, будут генерировать разные случайные последовательности.
|
Когда использовать PLINQ? Весьма соблазнительно поискать LINQ-запросы в своих существующих приложениях и поэкспериментировать с их распараллеливанием. В большинстве случаев от этого не будет никакого толку, поскольку большинство задач, для которых LINQ оказывается наилучшим решением, выполняются очень быстро и, таким образом, не получат никакой выгоды от распараллеливания. Лучше найти узкое место в блоке с большим количеством вычислений и ответить на такой вопрос: «Можно ли это представить в виде LINQ-запроса?» (положительным побочным эффектом такого преобразования является то, что обычно LINQ-запросы занимают меньше места и более читаемы). PLINQ хорошо подходит для задач чрезвычайного параллелизма (embarrassingly parallel problems). Он также хорошо походит для структурированных блокирующих задач, таких, как вызов нескольких сервисов одновременно (см. раздел "Вызов блокирующих функций или функций с интенсивным вводом/выводом"). PLINQ является плохим выбором для работы с изображениями, поскольку узким местом будет объединение миллионов точек в одну выходную последовательность. Вместо этого лучше сохранить точки напрямую в массив или блок неуправляемой памяти и использовать класс Parallel или параллелизм задач для работы с многопоточностью. (Хотя возможно решить проблему объединения результатов путем вызова метода ForAll. Это может иметь смысл, если алгоритм обработки изображения сам привел к использованию LINQ). |
Поскольку PLINQ выполняет запрос в параллельных потоках, вы должны заботиться о том, чтобы не выполнять никаких потоконебезопасных операций. В частности, изменение переменных является побочным эффектом, а потому не является потокобезопасным:
// Слежующий запрос перемножает каждый элемент на его позицию. // Принимая на вход Enumerable.Range(0,999), в результате мы получим квадраты. int i = 0; var query = from n in Enumerable.Range(0,999).AsParallel() select n * i++; |
Мы можем увеличить i на единицу потокобезопасной операцией путем использования блокировок или Interlocked операций, но проблема все еще будет в том, что i не обязательно будет соответствовать позиции элемента во входной последовательности. И вызов AsOrdered не исправит проблему, поскольку AsOrdered гарантирует только то, что элементы выходной последовательности будут располагаться аналогично, если бы входная последовательность обрабатывалась последовательно, но это не означает, что входная последовательность будет на самом деле обработана последовательно.
Вместо этого, этот запрос нужно переписать с использованием функции Select, принимающей индекс в качестве параметра:
var query = Enumerable.Range(0,999).
AsParallel().Select ((n, i) => n * i); |
Ради повышения производительности любые методы, вызываемые из операторов запроса, должны быть потокобезопасными в том смысле, что не должны изменять поля или свойства (отсутствие сторонних эффектов, или функциональная чистота). Если эти методы потокобезопасны в том смысле, что они используют блокировки, потенциал параллелизма этого запроса будет ограничен - продолжительностью захвата блокировки, деленной на суммарное время, проведенное внутри этой функции.
Иногда запросы выполняются длительное время не из-за интенсивных операций центрального процессора, а потому что процессор ждет чего-то, например, загрузки web-страниц или ответа от оборудования. PLINQ может эффективно распараллеливать такие запросы, если вы скажете ему об этом путем вызова метода WithDegreeOfParallelism после вызова метода AsParallel. Предположим, что мы хотим проверить существование шести Web-сайтов одновременно. Вместо того чтобы использовать асинхронные делегаты или вручную запускать шесть потоков, это элементарно можно сделать с помощью PLINQ-запроса:
from site in new[] { "www.albahari.com", "www.linqpad.net", "www.oreilly.com", "www.google.com", "www.takeonit.com", "stackoverflow.com" } .AsParallel().WithDegreeOfParallelism(6) let p = new Ping().Send (site) select new { site, Result = p.Status, Time = p.RoundtripTime } |
Вызов метода WithDegreeOfParallelism заставляет PLINQ запускать указанное количество задач одновременно. Это необходимо, когда вы вызываете блокирующие функции, такие как Ping.Send, поскольку в противном случае PLINQ предполагает, что запрос выполняет задачи с высокой нагрузкой на центральный процессор, и создает задачи соответствующим образом. Например, на двуядерном компьютере PLINQ по умолчанию может запускать только две задачи одновременно, что в данном случае является явно нежелательным.
| ПРИМЕЧАНИЕ PLINQ обычно обрабатывает задачу в потоке, полученном из пула потоков. Вы можете увеличить минимальное количество потоков путем вызова функции ThreadPool.SetMinThreads. |
В качестве другого примера давайте предположим, что мы пишем систему видеонаблюдения и хотим постоянно объединять изображение с четырех камер наблюдения в одно составное изображения для отображения его на мониторе. Мы можем представить камеру в виде следующего класса:
class Camera { public readonly int CameraID; public Camera (int cameraID) { CameraID = cameraID; } // Получить изображение с камеры: // возвращаем простую строку, а не изображение public string GetNextFrame() { Thread.Sleep (123); // Симулируем время, необходимое для получения снимка return "Frame from camera " + CameraID; } } |
Для получения составного изображения мы должны вызвать метод GetNextFrame у каждого из четырех объектов-камер. Предполагая, что это потребует больше количество операций ввода/вывода, можно вчетверо увеличить частоту кадров с помощью параллелизма – даже на одноядерной машине. PLINQ позволяет добиться этого с минимальными усилиями со стороны разработчика:
Camera[] cameras = Enumerable.Range(0, 4) //Создаем 4 объекта камеры. .Select(i => new Camera(i)) .ToArray(); while (true) { string[] data = cameras .AsParallel().AsOrdered().WithDegreeOfParallelism (4) .Select(c => c.GetNextFrame()).ToArray(); Console.WriteLine(string.Join(", ", data)); // Отображаем данные... } |
Метод GetNextFrame блокирует ход выполнения программы, поэтому мы вызываем WithDegreeOfParallelism для получения необходимого уровня параллелизма. В нашем примере блокирование происходит при вызове метода Sleep; в реальной жизни блокирование будет происходить из-за того, что получение изображения с камеры требует скорее интенсивного ввода/вывода, чем интенсивной загрузки процессора.
Вызов метода AsOrdered гарантирует, что изображения будут отображены в нужной последовательности. Поскольку в последовательности всего четыре элемента, это не окажет никакого влияния на производительность.
Метод WithDegreeOfParallelism можете вызвать в PLINQ-запросе только один раз. Если вам нужно вызвать этот метод снова, вы должны принудительно объединить результаты, а затем снова распараллелить запрос путем вызова метода AsParallel:
"The Quick Brown Fox" .AsParallel().WithDegreeOfParallelism (2) .Where (c => !char.IsWhiteSpace (c)) .AsParallel().WithDegreeOfParallelism (3) // Принудительный Merge + Partition .Select (c => char.ToUpper (c)) |
Отменить выполнение PLINQ-запроса, результаты которого обрабатываются внутри цикла foreach, очень просто: прервите выполнение цикла foreach, и запрос будет отменен автоматически во время неявного вызова метода Dispose перечислителя.
Запрос, который использует операторы преобразования, получения элементов или агрегации, может быть отменен из другого потока с помощью маркера отмены (cancellation token). Для передачи маркера отмены вызовите метод WithCancellation после вызова AsParallal и передайте в свойстве Token объект типа CancellationTokenSource. Затем другой поток может вызвать метод Cancel этого маркера, который сгенерирует OperationCanceledException в коде, использующем результаты запроса:
IEnumerable<int> million = Enumerable.Range (3, 1000000); var cancelSource = new CancellationTokenSource(); var primeNumberQuery = from n in million.AsParallel().WithCancellation (cancelSource.Token) where Enumerable.Range (2, (int) Math.Sqrt (n)).All (i => n % i > 0) select n; new Thread (() => { Thread.Sleep (100); // Отменяем запрос спустя cancelSource.Cancel(); // 100 миллисекунд. } ).Start(); try { // Запускаем выполнение запроса: int[] primes = primeNumberQuery.ToArray(); // Мы никогда сюда не попадем, потому что другой поток отменит наше выполнение. } catch (OperationCanceledException) { Console.WriteLine ("Query canceled"); } |
PLINQ не прерывает работу потоков, поскольку это опасно. Вместо этого, после отмены, прежде чем завершить выполнение запроса, он ждет окончания выполнения каждого рабочего потока, обрабатывающего текущий элемент. Это значит, что выполнение любых внешних методов, вызванных при выполнении запроса, будет завершено.
Одно из преимуществ использования PLINQ заключается в простоте объединения результатов параллельной обработки выходной последовательности. Однако иногда все, что требуется, это выполнить некоторую функцию для каждого элемента:
foreach (int n in parallelQuery) DoSomething (n); |
В этом случае, если вас не заботит порядок обработки элементов, можно повысить эффективность выполнения запроса путем использования метода ForAll.
Метод ForAll выполняет делегат для каждого выходного элемента ParallelQuery. Он изменяет внутреннее поведение обработки PLINQ запросов, обходя этапы объединения и перечисления результатов. Вот простой пример:
"abcdef".AsParallel().Select (c => char.ToUpper(c)).ForAll (Console.Write); |
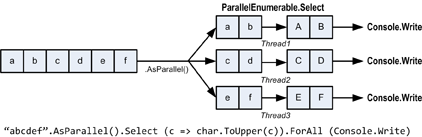
Рисунок 3.
Объединение и перечисление результатов не является очень уж дорогой операцией, поэтому использование ForAll дает значительные преимущества только при большом количестве элементов, обработка которых выполняется очень быстро.
PLINQ может использовать одну из трех стратегий секционирования (partitioning strategy) для назначения элементов входной последовательности рабочим потокам:
|
Стратегия |
Выделение элементов |
Относительная производительность |
|
Секционирование блоками (Chunk partitioning) |
Динамическое |
Средняя |
|
Секционирование по диапазону (Range partitioning) |
Статическое |
От плохой до отличной |
|
Хеш-секционирование (Hash partitioning) |
Статическое |
Плохая |
Для операторов запросов, которые требуют сравнения элементов (GroupBy, Join, GroupJoin, Intersect, Except, Union и Distinct), у вас нет выбора: PLINQ всегда использует хеш-секционирование (hash partitioning). Хеш-секционирование относительно неэффективно, поскольку требует предварительного расчета хеш-значения каждого элемента последовательности (таким образом, элементы с одинаковым хеш-значением могут быть обработаны одним и тем же потоком). Если этот вариант вам покажется слишком медленным, у вас будет единственная возможность – вызвать метод AsSequential для отключения распараллеливания.
Для всех остальных операторов запроса у вас есть выбор, использовать секционирование по диапазону или блоками. По умолчанию:
Если кратко, то секционирование по диапазону быстрее на больших последовательностях, для которых обработка каждого элемента требует одинакового количества процессорного времени. В противном случае секционирование блоками более эффективно.
Для принудительного использования секционирования по диапазону:
| СОВЕТ ParallelEnumerable.Range – это не просто краткая запись для Enumerable.Range(...).AsParallel(). Вызов этого метода влияет на производительность, поскольку в этом случае будет использоваться секционирование по диапазону. |
Для принудительного использования секционирования блоками оберните входную последовательность в вызов метода Partitioner.Create (расположенного в пространстве имен System.Collection.Concurrent) следующим образом:
int[] numbers = { 3, 4, 5, 6, 7, 8, 9 }; var parallelQuery = Partitioner.Create (numbers, true).AsParallel() .Where (...) |
Второй аргумент метода Partitioner.Create указывает на то, что вы хотите выровнять загрузку (load-balance) запроса, другими словами, вы хотите использовать секционирование блоками.
Секционирование блоками работает следующим образом: рабочий поток периодически берет небольшой «блок» элементов из входной последовательности для обработки. PLINQ начинает с выделения блоков очень маленького размера (состоящих из одного-двух элементов), а затем увеличивает размер блока по мере обработки запроса: это гарантирует, что короткие последовательности распараллеливаются эффективным образом, а длинные последовательности не страдают от чрезмерных накладных расходов. Если рабочему потоку попались «простые» в обработке элементы (которые он быстро обработал), это приведет к получению дополнительных блоков. Это позволяет системе поддерживать равномерность нагрузки потоков (и балансировать нагрузку ядер процессора); единственным недостатком этого метода является использование синхронизации при получении элементов из разделяемой входной последовательности (обычно с помощью эксклюзивной блокировки), что может привести к некоторым накладным расходам и конкуренции за общий ресурс.

Рисунок 4.
Секционирование по диапазону обходит обычный процесс перебора входной последовательности и заранее выделяет одинаковое количество элементов для каждого рабочего потока, избегая конкуренции за входную последовательность. Но если одному из потоков достанутся более «простые» элементы и он закончит свое выполнение раньше, он будет бездействовать, пока остальные потоки продолжают свою работу. Алгоритм расчета простых чисел, рассмотренный ранее, может показать плохую производительность при использовании секционирования на основе диапазона. Примером, когда этот тип секционирования может работать эффективно, является вычисление суммы квадратных корней первых десяти миллионов целых чисел:
ParallelEnumerable.Range (1, 10000000).Sum (i => Math.Sqrt (i)) |
ParallelEnumerable.Range возвращает ParallelQuery<T>, поэтому последующий вызов AsParallel не нужен.
| ПРИМЕЧАНИЕ Секционирование на основе диапазона не обязательно выделяет диапазоны непрерывными блоками, вместо этого оно может использовать стратегию на основе фрагментов (“striping” strategy). Например, при наличии двух рабочих потоков один из них может обрабатывать четные элементы, в то время как другой поток будет обрабатывать нечетные. Оператор TakeWhile практически всегда приводит к использованию этой стратегии, поскольку он будет стараться избежать обработки ненужных элементов в конце последовательности. |
PLINQ эффективно распараллеливает операторы Sum, Average, Min и Max без дополнительного вмешательства. Оператор Aggregate предоставляет проблемы для PLINQ.
Если вы не знакомы с этим оператором, вы можете рассматривать его как обобщенную версию операторов Sum, Average, Min и Max, другими словами, это оператор, который позволяет добавить специализированный алгоритм аккумулирования значений для реализации нетиповых агрегаций.
int[] numbers = { 1, 2, 3 }; int sum = numbers.Aggregate ( 0, (total, n) => total + n); // 6 |
Первый аргумент метода Aggregate – это
| ПРИМЕЧАНИЕ Большинство задач, для которых предназначен метод Aggregate, могут быть легко решены с помощью более знакомого синтаксиса – цикла foreach. Преимущество использования Aggregate заключается в том, что большая и сложная агрегация может быть распараллелена декларативным образом. |
При вызове метода Aggregate можно опустить начальное значение (seed value). В таком случае первый элемент входной последовательности
int[] numbers = { 1, 2, 3 }; int sum = numbers.Aggregate ((total, n) => total + n); // 6 |
Результат тот же, что и раньше, но, на самом деле,
int[] numbers = { 1, 2, 3 }; int x = numbers.Aggregate (0, (prod, n) => prod * n); // 0*1*2*3 = 0 int y = numbers.Aggregate ( (prod, n) => prod * n); // 1*2*3 = 6 |
Как мы вскоре увидим, агрегации без начального значения могут быть распараллелены без использования дополнительных перегруженных версий этого метода. Однако здесь существует одна ловушка: агрегирующие методы без начального значения должны использоваться в методах, которые являются
(total, n) => total + n * n |
Это выражение не является ни коммутативным, ни ассоциативным. (Например, 1 + 2*2 != 2 + 1*1). Давайте посмотрим на результат его использования для получения суммы квадратов чисел 2, 3, 4:
int[] numbers = { 2, 3, 4 }; int sum = numbers.Aggregate ((total, n) => total + n * n); // 27 |
Вместо вычисления:
2*2 + 3*3 + 4*4 // 29 |
Он вычисляет
2 + 3*3 + 4*4 // 27 |
Это можно исправить несколькими способами. Во-первых, можно добавить 0 в качестве первого элемента
int[] numbers = { 0, 2, 3, 4 }; |
Это не только неэлегантно, но и приведет к некорректному результату при параллельном выполнении, поскольку PLINQ предполагает наличие ассоциативности и выбирает
f(total, n) => total + n * n |
LINQ to Objects вычисляет это таким образом:
f(f(f(0, 2),3),4) |
а PLINQ может вычислять так:
f(f(0,2),f(3,4)) |
со следующими результатами:
Существует два хороших решения этой проблемы. Первое решение заключается в применении агрегации с начальным значением, в качестве которого используется 0. Единственная сложность заключается в том, что при использовании PLINQ, если мы хотим, чтобы запрос не выполнялся последовательно, нужно использовать специальную перегруженную версию (как мы вскоре увидим).
Второе решение заключается в преобразовании запроса таким образом, чтобы агрегирующая функция стала коммутативной и ассоциативной:
int sum = numbers.Select (n => n * n).Aggregate ((total, n) => total + n); |
| ПРИМЕЧАНИЕ
Конечно, в таком простом сценарии можно (и нужно) использовать оператор Sum вместо Aggregate: |
int sum = numbers.Sum (n => n * n); |
На самом деле, вы можете много чего сделать с помощью операторов Sum и Aggregate. Например, вы можете использовать Average для вычисления среднеквадратического отклонения.
Math.Sqrt (numbers.Average (n => n * n)) |
Или даже для вычисления обычного отклонения:
double mean = numbers.Average(); double sdev = Math.Sqrt (numbers.Average (n => { double dif = n - mean; return dif * dif; })); |
Оба вычисления безопасны, эффективны и полностью распараллеливаемы.
Мы только что видели, что в случае агрегаций без
Применение агрегаций с явно указанными начальными значениями может показаться безопасным, но, к сожалению, они обычно вычисляются последовательно из-за зависимости от единственного начального значения. Для решения этой проблемы в PLINQ есть дополнительная перегруженная версия оператора Aggregate, которая позволяет указать несколько начальных значений в виде
Нужно также задать функцию, которая покажет, каким именно образом будут объединяться локальный и главный аккумуляторы. И последнее, эта перегрузка оператора Aggregate ожидает делегат (зачастую ненужный), который выполняет окончательное преобразования результата (вы можете добиться того же самого путем вызова некоторой функции для результата, полученного после выполнения этого оператора). Итак, вот четыре делегата, в том порядке, в котором вы должны их передать:
| ПРИМЕЧАНИЕ В простых случаях вы можете указать |
В качестве очень простого примера давайте рассмотрим суммирование значений массива numbers:
numbers.AsParallel().Aggregate ( () => 0, // seedFactory (localTotal, n) => localTotal + n, // updateAccumulatorFunc (mainTot, localTot) => mainTot + localTot, // combineAccumulatorFunc finalResult => finalResult) // resultSelector |
Этот пример показывает, что так же эффективно можно получить тот же самый ответ с помощью более простых подходов (например, с помощью агрегата без указания начального значения или, еще лучше, с помощью оператора Sum). В качестве более реального примера давайте предположим, что мы хотим вычислить частоту использования всех букв английского алфавита в определенной строке. Простое решение, выполняемое последовательно, может быть таким:
string text = "Let’s suppose this is a really long string"; var letterFrequencies = new int[26]; foreach (char c in text) { int index = char.ToUpper (c) - 'A'; if (index >= 0 && index <= 26) letterFrequencies [index]++; }; |
| ПРИМЕЧАНИЕ Примером текста очень большого размера может быть последовательность генов. В таком случае «алфавит» будет содержать буквы a, c, g и t. |
Для распараллеливания можно заменить оператор foreach вызовом метода Parallel.ForEach (как будет показано в следующем разделе), но в этом случае придется решать проблему параллельного доступа к общему массиву. А блокировка доступа к этому массиву просто убьет весь потенциал распараллеливания.
Оператор Aggregate предоставляет лучшее решение. Аккумулятором в данном случае будет массив, аналогичный массиву letterFrequencies из нашего предыдущего примера. Вот последовательная версия с использованием Aggregate:
int[] result = text.Aggregate ( new int[26], // Создаем "аккумулятор" (letterFrequencies, c) => // Агрегируем буквы в аккумуляторе { int index = char.ToUpper (c) - 'A'; if (index >= 0 && index <= 26) letterFrequencies [index]++; return letterFrequencies; }); |
И вот теперь параллельная версия, которая использует специальную перегрузку метода Aggregate:
int[] result = text.AsParallel().Aggregate ( () => new int[26], // Создаем новый локальный аккумулятор (localFrequencies, c) => // Добавляем элементы в локальный аккумулятор { int index = char.ToUpper (c) - 'A'; if (index >= 0 && index <= 26) localFrequencies [index]++; return localFrequencies; }, // Объединяем локальный и главный аккумуляторы (mainFreq, localFreq) => mainFreq.Zip (localFreq, (f1, f2) => f1 + f2).ToArray(), finalResult => finalResult // Выполняем окончательное преобразование ); // на конечном результате. |
Обратите внимание, что локальные аккумулирующие функции
PFX предоставляет базовую форму структурного параллелизма с помощью трех методов класса Parallel:
Все три метода блокируют управление до окончания выполнения всех действий. Как и при использовании PLINQ, при возникновении необработанного исключения оставшиеся рабочие потоки прекращают выполнение после завершения обработки текущего элемента, и исключение (или исключения), завернутое в AggregationException, передается вызывающему коду.
Метод Parallel.Invoke выполняет массив делегатов типа Action параллельно, и затем ожидает их завершения. Самая простая версия этого метода определена следующим образом:
public static void Invoke (params Action[] actions); |
Вот как можно воспользоваться методом Parallel.Invoke для одновременной загрузки двух Web-страниц:
Parallel.Invoke ( () => new WebClient().DownloadFile ("http://www.linqpad.net", "lp.html"), () => new WebClient().DownloadFile ("http://www.jaoo.dk", "jaoo.html")); |
С первого взгляда может показаться, что это просто сокращенная форма создания двух объектов класса Task (или асинхронных делегатов) с последующим ожиданием их завершения. Но есть одно существенное различие: метод Parallel.Invoke будет выполняться эффективно, даже если вы передадите ему миллион делегатов. Это связано с тем, что он
При использовании всех методов класса Parallel ответственность за объединение результатов лежит на вас. Это значит, что вы сами должны думать о безопасности потоков. Так, например, следующий код не является потокобезопасным:
var data = new List<string>(); Parallel.Invoke ( () => data.Add (new WebClient().DownloadString ("http://www.foo.com")), () => data.Add (new WebClient().DownloadString ("http://www.far.com"))); |
Использование блокировок вокруг добавления в список решит проблему, хотя и создаст узкое место при большом количестве быстроисполнимых делегатов. В данном случае идеальным решением будет использование потокобезопасных коллекций, таких как ConcurrentBag.
Существует перегруженная версия метода Parallel.Invoke, которая принимает объект класса ParallelOptions.
public static void Invoke (ParallelOptions options, params Action[] actions); |
С помощью ParallelOptions можно добавить маркер отмены, ограничить максимальное количество рабочих потоков или указать свой планировщик задач (custom task scheduler). Использование маркеров отмены полезно, когда число одновременно выполняемых задач превосходит (примерное) количество ядер процессора: при отмене все делегаты, выполнение которых еще не было начато, будут отменены. Однако все делегаты, выполнение которых уже начато, продолжат до завершения. См. раздел Отмена для примеров использования маркеров отмены.
Методы Parallel.For и Parallel.ForEach аналогичны C#-операторам цикла for и foreach, за исключением того, что итерирование элементов последовательности происходит параллельно, а не последовательно. Вот их (упрощенные) сигнатуры:
public static ParallelLoopResult For ( int fromInclusive, int toExclusive, Action<int> body) public static ParallelLoopResult ForEach<TSource> ( IEnumerable<TSource> source, Action<TSource> body) |
Следующий последовательный оператор for:
for (int i = 0; i < 100; i++) Foo (i); |
Может быть распараллелен так:
Parallel.For (0, 100, i => Foo (i)); |
или еще проще:
Parallel.For (0, 100, Foo); |
А следующий последовательный оператор foreach:
foreach (char c in "Hello, world") Foo (c); |
может быть распараллелен так:
Parallel.ForEach ("Hello, world", Foo); |
Например, если воспользоваться пространством имен System.Security.Cryptography, можно сгенерировать шесть пар открытых/закрытых ключей параллельно следующим образом:
var keyPairs = new string[6]; Parallel.For (0, keyPairs.Length, i => keyPairs[i] = RSA.Create().ToXmlString (true)); |
С помощью Parallel.Invoke можно передать в методы Parallel.For и Parallel.ForEach большое количество рабочих элементов, которые будут эффективно разбиты на секции для обработки несколькими задачами.
| ПРИМЕЧАНИЕ Последний запрос может быть также реализован с помощью PLINQ: |
string[] keyPairs = ParallelEnumerable.Range (0, 6) .Select (i => RSA.Create().ToXmlString (true)) .ToArray(); |
Методы Parallel.For и Parallel.ForEach обычно лучше работают во внешних, а не во внутренних циклах. Это связано с тем, что в первом случае для распараллеливания вы предоставляете блоки (chunks) большего размера, снижая влияние накладных расходов. Распараллеливать одновременно внешние и внутренние циклы обычно не нужно. В следующем примере понадобится более 100 ядер процессора для получения преимуществ от распараллеливания внутреннего цикла:
Parallel.For (0, 100, i =>
{
// Для внутреннего цикла лучше использовать последовательное выполнение.
Parallel.For (0, 50, j => Foo (i, j));
}); |
Иногда полезно знать индекс текущего элемента внутри цикла. Используя последовательную версию foreach, это сделать просто:
int i = 0; foreach (char c in "Hello, world") Console.WriteLine (c.ToString() + i++); |
Однако изменение разделяемой переменной не является потокобезопасной операцией в параллельном контексте. Вместо этого нужно использовать следующую версию метода ForEach:
public static ParallelLoopResult ForEach<TSource> ( IEnumerable<TSource> source, Action<TSource,ParallelLoopState,long> body) |
ParallelLoopState нам пока не интересен (который будет рассмотрен в следующем разделе). На данный момент нас интересует только третий параметр делегата Action с типом long, который как раз и содержит индекс цикла:
Parallel.ForEach ("Hello, world", (c, state, i) =>
{
Console.WriteLine (c.ToString() + i);
}); |
Чтобы рассмотреть этот метод в реальном контексте, давайте изменим класс проверки правописания, реализованный с помощью PLINQ. Следующий код загружает словарь вместе с массивом из миллиона тестовых слов:
if (!File.Exists ("WordLookup.txt")) // Содержит порядка 150,000 слов new WebClient().DownloadFile ( "http://www.albahari.com/ispell/allwords.txt", "WordLookup.txt"); var wordLookup = new HashSet<string> ( File.ReadAllLines ("WordLookup.txt"), StringComparer.InvariantCultureIgnoreCase); var random = new Random(); string[] wordList = wordLookup.ToArray(); string[] wordsToTest = Enumerable.Range (0, 1000000) .Select (i => wordList [random.Next (0, wordList.Length)]) .ToArray(); wordsToTest [12345] = "woozsh"; // Добавляем несколько wordsToTest [23456] = "wubsie"; // ошибок правописания. |
Проверку правописания в массиве wordsToTest можно выполнить с помощью индексированной версии метода Parallel.ForEach:
var misspellings = new ConcurrentBag<Tuple<int,string>>(); Parallel.ForEach (wordsToTest, (word, state, i) => { if (!wordLookup.Contains (word)) misspellings.Add (Tuple.Create ((int) i, word)); }); |
Обратите внимание, что придется самостоятельно объединять результаты в потокобезопасную коллекцию: такая необходимость является недостатком по сравнению с использованием PLINQ. Преимуществом использования класса Parallel по сравнению с использованием PLINQ является то, что не нужно использовать дорогостоящую индексированную версию оператора запроса Select, менее эффективную, чем индексированная версия метода ForEach.
Поскольку телом циклов параллельной версии For или ForEach является делегат, нельзя закончить выполнение цикла преждевременно с помощью оператора break. Вместо этого нужно вызвать метод Break или Stop объекта ParallelLoopState.
public class ParallelLoopState { public void Break(); public void Stop(); public bool IsExceptional { get; } public bool IsStopped { get; } public long? LowestBreakIteration { get; } public bool ShouldExitCurrentIteration { get; } } |
Получить объект ParallelLoopState очень просто: все версии методов For и ForEach содержат перегруженную версию, которая принимает делегат вида Action<TSource, ParallelLoopState> в качестве тела цикла. Таким образом, распараллелить этот код:
foreach (char c in "Hello, world") if (c == ',') break; else Console.Write (c); |
Можно так:
Parallel.ForEach ("Hello, world", (c, loopState) => { if (c == ',') loopState.Break(); else Console.Write (c); }); Hlloe |
По результатам выполнения видно, что тело цикла может завершиться в случайном порядке. Но кроме этого различия, вызов метода Break приводит к выполнению
| ПРИМЕЧАНИЕ Методы Parallel.For и Parallel.ForEach возвращают объект ParallelLoopResult, который содержит свойства IsCompleted и LowestBreakIteration. Эти свойства могут дать вам понять, полностью ли закончилось выполнение цикла, и если нет, то на какой итерации цикла выполнение было прервано. Если LowersBreakIteration возвращает null, это означает, что был вызван метод Stop (а не Break). |
Если тело цикла выполняется очень долго, можно захотеть прервать его выполнение из другого потока в середине выполнения путем вызова методов Break или Stop. Этого можно добиться путем опроса свойства ShouldExitCurrentIteration в различных участках кода; это свойство начинает возвращать true сразу после вызова метода Stop и вскоре после вызова метода Break.
| ПРИМЕЧАНИЕ ShouldExitCurrentIteration также начинает возвращать true после отмены выполнения (cancelation request) или после генерации исключения в теле цикла. |
Свойство IsExceptional позволяет узнать, произошло ли исключение в другом потоке. Любые необработанные исключения приведут к остановке выполнения цикла после окончания выполнения текущей итерации другими потоками: чтобы избежать этого, следует явно обрабатывать исключения в коде.
Методы Parallel.For и Parallel.ForEach имеют перегруженные версии, которые принимают обобщенный аргумент TLocal. Эти версии предназначены для упрощения объединения данных при использовании циклов с большим количеством итераций. Вот простой пример:
public static ParallelLoopResult For <TLocal> ( int fromInclusive, int toExclusive, Func <TLocal> localInit, Func <int, ParallelLoopState, TLocal, TLocal> body, Action <TLocal> localFinally); |
Необходимость в использовании этих методов на практике возникает редко, поскольку PLINQ покрывает их функциональность (и это хорошо, поскольку эти перегрузки выглядят пугающе!).
По сути, проблема заключается в следующем: предположим, мы хотим найти сумму квадратных корней чисел в диапазоне от 1 до 10,000,000. Задача вычисления 10 миллионов квадратных корней очень легко распараллеливается, но их суммирование является проблемой, поскольку придется использовать блокировку при обновлении суммы:
object locker = new object(); double total = 0; Parallel.For (1, 10000000, i => { lock (locker) total += Math.Sqrt (i); }); |
Однако выгода от параллелизма превосходит накладные расходы на получение 10 миллионов блокировок плюс длительность каждой блокировки.
Однако, на самом деле, нам
Методы For и ForEach, которые принимают TLocal, работают именно так. Добровольцами в этом случае являются рабочие потоки, а
Вдобавок к этому, делегат тела цикла вместо возврата void должен возвращать новый аккумулятор локальных значений. Вот переработанный пример:
object locker = new object(); double grandTotal = 0; Parallel.For (1, 10000000, () => 0.0, // Инициализация локального значения. // Делегат тела цикла. Обратите внимание что он возвращает // новую локальную сумму. (i, state, localTotal) => localTotal + Math.Sqrt (i), // Добавление локального значения к основному. localTotal => { lock (locker) grandTotal += localTotal; } ); |
Здесь все еще используется блокировка, но на этот раз только вокруг добавления локального значения к основной сумме. Это делает процесс вычисления значительно более эффективным.
| ПРИМЕЧАНИЕ Как уже говорилось ранее, в подобных случаях отлично подходит PLINQ. Этот пример может быть распараллелен очень просто с помощью PLINQ следующим образом: |
ParallelEnumerable.Range(1, 10000000) .Sum (i => Math.Sqrt (i)) |
| ПРИМЕЧАНИЕ (Обратите внимание, что мы используем ParallelEnumerable для принудительного использования В более сложных случаях можно использовать LINQ-оператор Aggregate вместо Sum. Если указать фабричный метод инициализации начального значения, ситуация будет более или менее похожа на использование функции Parallel.For с использованием локальных значений. |
|
Класс |
Назначение |
|---|---|
|
Для управления единицей работы |
|
|
Для управления единицей работы, которая возвращает значение |
|
|
Для создания задач |
|
|
Для создания задач и продолжений с тем же типом возвращаемого значения |
|
|
Для управления планировщиком задач |
|
для ручного управления жизненным циклом задачи.
По сути, задание представляет собой легковесный объект для управления распараллеливаемой единицей работы (unit of work). Задание избегает накладных расходов по запуску выделенного потока путем использования пула потоков CLR: тот же самый пул потоков используется при вызове функции ThreadPool.QueueUserWorkItem, настроенный в CLR 4.0 специальным образом для более эффективной работы вместе с заданиями (и более эффективной работы в целом).
Задания могут применяться всегда, когда вам нужно выполнить что-либо параллельно. Однако они
Задания делают значительно больше, нежели предоставляют эффективный способ использования пула потоков. Они также предоставляют возможности для управления единицами работы (units of work), включая следующие возможности:
Задачи также реализуют
| ПРЕДУПРЕЖДЕНИЕ Библиотека параллелизма задач (Task Parallel Library) позволяет создавать сотни (даже тысячи) задач с минимальными накладными расходами. Но если вам нужно создавать миллионы задач, то для поддержания эффективности нужно разбить их на более крупные единицы работы. Класс Parallel и PLINQ делают это автоматически. |
| ПРИМЕЧАНИЕ Visual Studio 2010 предоставляет новое окно для мониторинга задач (Debug | Window | Parallel Tasks). Это окно эквивалентно окну Threads, но предназначено для задач. В окне Parallel Stacks также предусмотрен специальный режим для задач. |
Как говорилось в Части 1 при обсуждении пула потоков, можно создать и запустить Task, вызвав метод Task.Factory.StartNew и передав в него делегат Action:
Task.Factory.StartNew (() => Console.WriteLine ("Hello from a task!")); |
Обобщенная версия, Task<TResult> (наследник класса Task), позволяет получить данные после завершения выполнения задачи:
Task<string> task = Task.Factory.StartNew<string> (() => // Начало задачи { using (var wc = new System.Net.WebClient()) return wc.DownloadString ("http://www.linqpad.net"); }); RunSomeOtherMethod(); // Мы можем выполнять другую работу параллельно... string result = task.Result; // Ожидаем выполнения задачи для получения результатов. |
Метод Task.Factory.StartNew создает и запускает задачу за один шаг. Вы можете разъединить эти операции, вначале создав объект Task, а затем вызвав метод Start:
var task = new Task (() => Console.Write ("Hello")); ... task.Start(); |
Задача, созданная таким образом, может быть выполнена синхронно (в том же потоке) путем вызова метода RunSynchronously вместо вызова метода Start.
| ПРИМЕЧАНИЕ Вы можете отслеживать статус выполнения задачи с помощью свойства Status. |
При создании экземпляра задачи или вызова метода Task.Factory.StartNew вы можете указать
static void Main() { var task = Task.Factory.StartNew (Greet, "Hello"); task.Wait(); // Ожидаем завершения задачи. } static void Greet (object state) { Console.Write (state); } // Hello |
При наличии в C# лямбда-выражений можно найти
static void Main() { var task = Task.Factory.StartNew (state => Greet ("Hello"), "Greeting"); Console.WriteLine (task.AsyncState); // Greeting task.Wait(); } static void Greet (string message) { Console.Write (message); } |
| ПРИМЕЧАНИЕ Visual Studio отображает свойство AsyncState каждой задачи в окне Parallel Tasks, так что наличие разумного имени может значительно облегчить процесс отладки. |
Процесс выполнения задачи можно настроить путем использования перечисления TaskCreationOptions во время вызова метода StartNew (или создания экземпляра класса Task). TaskCreationOptions – это флаговое перечисление со следующими (объединяемыми) значениями:
Значение LongRunning говорит планировщику выделить для задачи отдельный поток. Это целесообразно для задач с длительным временем выполнения (long-running tasks), поскольку в противном случае они могут «подвесить» очередь и заставить короткие задачи ожидать неразумное количество времени, прежде чем они смогут быть выполнены. Значение LongRunning также хорошо подходит для блокирующих задач.
| ПРИМЕЧАНИЕ Проблема с очередью задач обычно возникает из-за того, что планировщик задач обычно старается поддерживать в определенный момент времени количество задач, необходимое для полной загрузки всех ядер процессора. |
Значение PreferFairness говорит планировщику попытаться распределить задачи в том же порядке, в котором они были запущены. Обычно это не так, поскольку планировщик оптимизирует работу задач путем использования локальных очередей. Эта оптимизация приносит плоды на очень мелких задачах.
AttachedToParent предназначено для создания дочерних задач.
Когда одна задача запускает другую, можно, путем указания TaskCreationOptions.AttachedToparent, установить отношения типа родительская задача/дочерняя задача:
Task parent = Task.Factory.StartNew (() =>
{
Console.WriteLine ("I am a parent");
Task.Factory.StartNew (() => // Независимая задача
{
Console.WriteLine ("I am detached");
});
Task.Factory.StartNew (() => // Дочерняя задача
{
Console.WriteLine ("I am a child");
}, TaskCreationOptions.AttachedToParent);
}); |
Дочерняя задача отличается тем, что при ожидании завершения родительской задачи вы будете также ожидать завершения и всех дочерних задач. Как вскоре будет показано, это может быть особенно полезно, когда дочерняя задача является продолжением.
Вы можете явно ожидать завершения задачи двумя способами:
Можно также одновременно ожидать завершения нескольких задач с помощью статических методов Task.WaitAll (ожидать завершения всех указанных задач) и Task.WaitAny (ожидать завершения какой-либо задачи).
Метод WaitAll аналогичен последовательному ожиданию всех задач, однако он более эффективен, поскольку приводит (в большинстве случаев) всего лишь к одному переключению контекста. Также, если одна или более задача генерирует необработанное исключение, метод WaitAll продолжает ожидание всех остальных задач, и только потом генерирует одно исключение AggregateException, которое содержит все исключения неудачно завершившихся задач. Вызов этого метода эквивалентен следующему:
// Предполагаем, что t1, t2 и t3 – это задачи: var exceptions = new List<Exception>(); try { t1.Wait(); } catch (AggregateException ex) { exceptions.Add (ex); } try { t2.Wait(); } catch (AggregateException ex) { exceptions.Add (ex); } try { t3.Wait(); } catch (AggregateException ex) { exceptions.Add (ex); } if (exceptions.Count > 0) throw new AggregateException (exceptions); |
Вызов метода WaitAny эквивалентен ожиданию ManualResetEventSlim, который переводится в сигнальное состояние при завершении каждой задачи.
Помимо тайм-аута, в Wait-методы вы также можете передать маркер отмены: это позволит отменить ожидание, но
При ожидании завершения задачи (либо путем вызова метода Wait, либо путем доступа к свойству Result) любое необработанное исключение будет передано вызывающему коду, обернутое в объект AggregationException. Обычно это устраняет необходимость в написании кода обработки непредвиденных исключений внутри задачи; вместо этого можно сделать так:
int x = 0; Task<int> calc = Task.Factory.StartNew (() => 7 / x); try { Console.WriteLine (calc.Result); } catch (AggregateException aex) { Console.Write (aex.InnerException.Message); // Пытались разделить на 0 } |
Вам все еще нужно обрабатывать исключения автономных задач (задач, которые не являются родительскими для других задач, и завершения выполнения которых никто не ожидает), чтобы предотвратить крах приложения из-за необработанных исключений, после того, как эта задача будет обработана сборщиком мусора (это тема следующего примечания). Это также касается задач, завершающихся по тайм-ауту, поскольку все исключения, которые будут сгенерированы
| ПРИМЕЧАНИЕ Статическое событие TaskScheduler.UnobservedTaskException предоставляет последнюю возможность сделать что-либо с необработанными исключениями задачи. Путем обработки этого события вы можете перехватить исключения задачи, предоставить собственную логику их обработки и предотвратить завершение работы приложения. |
Ожидание завершения родительских задач приводит к ожиданию всех дочерних задач и к обработке исключений, возникших в этих задачах.
var atp = TaskCreationOptions.AttachedToParent; var parent = Task.Factory.StartNew (() => { Task.Factory.StartNew (() => // Дочерняя задача { // Дочерняя задача дочерней задачи Task.Factory.StartNew (() => { throw null; }, atp); }, atp); }); // Следующий вызов приведет к генерации NullReferenceException // (обернутого в AggregateExceptions): parent.Wait(); |
| ПРИМЕЧАНИЕ Интересно, что проверка свойства задачи Exception после возникновения исключения предотвратит последующую гибель вашего приложения. Причина заключается в том, что разработчики PFX не хотели, чтобы вы |
| ПРЕДУПРЕЖДЕНИЕ Необработанное исключение, возникшее в задаче не приводит к |
Как вскоре будет показано, альтернативной стратегией обработки исключений является применение продолжений.
При запуске задачи можно передать маркер отмены. Это позволит отменить выполнение задачи с помощью кооперативного паттерна отмены, рассмотренного ранее:
var cancelSource = new CancellationTokenSource(); CancellationToken token = cancelSource.Token; Task task = Task.Factory.StartNew (() => { // Выполняем некоторые операции... token.ThrowIfCancellationRequested(); // Проверяем запрос отмены // Выполняем некоторые операции... }, token); ... cancelSource.Cancel(); |
Для определения отмененной задачи необходимо перехватить AggregateException и проверить вложенное исключение следующим образом:
try { task.Wait(); } catch (AggregateException ex) { if (ex.InnerException is OperationCanceledException) Console.Write ("Task canceled!"); } |
| ПРИМЕЧАНИЕ Если вы хотите явно сгенерировать OperationCanceledException (вместо вызова token.ThrowIfCancellationRequested), вы должны передать маркер отмены в конструкторе OperationCanceledException. Если вы этого не сделаете, задача не завершится со статусом TaskStatus.Canceled и не сгенерирует событие OnlyOnCanceled для продолжений. |
При отмене выполнения задачи, выполнение которой еще не началось, ее выполнение не будет начато, вместо этого будет немедленно сгенерировано исключение OperationCanceledException.
Поскольку другие API понимают маркеры отмены, вы можете передать их другим конструкциям, в таком случае все операции будут отменены без вашего вмешательства.
var cancelSource = new CancellationTokenSource(); CancellationToken token = cancelSource.Token; Task task = Task.Factory.StartNew (() => { // Передаем наш маркер отмены в запрос: var query = someSequence.AsParallel(). WithCancellation (token)... ...обработка результата запроса... }); |
Вызов метода Cancel объекта cancelSource в этом примере приведет к отмене PLINQ-запроса, что приведет к генерации исключения OperationCanceledException в теле задачи, что, в свою очередь, приведет к отмене выполнения этой задачи.
| ПРИМЕЧАНИЕ Маркеры отмены, которые можно передать в такие методы, как Wait и CancelAndWait, позволяют отменять ожидание выполнения операции, а не саму задачу. |
Иногда бывает полезно запустить на выполнение задачу сразу же после завершения выполнения другой задачи (или после неудачного завершения этой задачи). Метод ContinueWith класса Task предоставляет именно такую возможность.
Task task1 = Task.Factory.StartNew (() => Console.Write ("antecedant..")); Task task2 = task1.ContinueWith (ant => Console.Write ("..continuation")); |
Как только задача task1 (
В нашем примере показан самый простой тип продолжений, который функционально эквивалентен следующему:
Task task = Task.Factory.StartNew (() =>
{
Console.Write ("antecedent..");
Console.Write ("..continuation");
}); |
Однако подход на основе продолжений более гибок, поскольку вначале вы можете ожидать завершение задачи task1, а затем ожидать завершение задачи task2. Это может быть особенно важным, если задача task1 возвращает данные.
| ПРИМЕЧАНИЕ Еще одним (небольшим) отличием является то, что, по умолчанию, родительская задача и ее продолжение могут выполняться в разных потоках. Вы можете заставить их принудительно выполняться в одном потоке, указав TaskContinuationOptions.ExecuteSynchronously при вызове метода ContinueWith: это может улучшить производительность очень мелких продолжений путем уменьшения накладных расходов. |
Как и обычные задачи, продолжения могут иметь тип Task<TResult> и возвращать некоторые данные. В следующем примере вычисляется Math.Sqrt(8*2) путем выполнения нескольких связанных задач и только потом выводится результат вычисления:
Task.Factory.StartNew<int> (() => 8) .ContinueWith (ant => ant.Result * 2) .ContinueWith (ant => Math.Sqrt (ant.Result)) .ContinueWith (ant => Console.WriteLine (ant.Result)); // 4 |
Этот пример неестественно прост; в реальных приложениях, лямбда-выражения будут вызывать функции с интенсивными вычислениями.
Продолжение может выяснить, было ли сгенерировано исключение родительской задачей, с помощью свойства Exception родительской задачи. Следующий код выводит подробную информацию об исключении NullReferenceException на консоль:
Task task1 = Task.Factory.StartNew (() => { throw null; });
Task task2 = task1.ContinueWith (ant => Console.Write (ant.Exception)); |
| ПРЕДУПРЕЖДЕНИЕ Если родительская задача генерирует исключение, а продолжение не проверит свойство Exception родительской задачи (и никто не ожидает завершения родительской задачи), исключение считается необработанным и приложение умирает (если это исключение не будет обработано с помощью TaskScheduler.UnobservedTaskException). |
Безопасным паттерном является перегенерация родительского исключения. Если кто-либо ожидает завершения продолжения (путем вызова Wait), исключение будет передано коду, ожидающему завершения продолжения.
Task continuation = Task.Factory.StartNew (() => { throw null; })
.ContinueWith (ant =>
{
if (ant.Exception != null) throw ant.Exception; // Продолжаем обработку...
});
// Теперь исключение передано коду, ожидающему завершения продолжения.
continuation.Wait(); |
Другим способом работы с исключениями является применение различных продолжений для нормального и ненормального завершений родительской задачи. Это делается с помощью TaskContinuationOptions:
Task task1 = Task.Factory.StartNew (() => { throw null; });
Task error = task1.ContinueWith
(ant => Console.Write (ant.Exception),
TaskContinuationOptions.OnlyOnFaulted);
Task ok = task1.ContinueWith
(ant => Console.Write ("Success!"),
TaskContinuationOptions.NotOnFaulted); |
Этот паттерн особенно полезен вместе с дочерними задачами, которые будут рассмотрены очень скоро.
Следующий метод-расширение "проглатывает" необработанные исключения задачи (этот код можно улучшить путем добавления логирования исключений):
public static void IgnoreExceptions (this Task task) { task.ContinueWith (t => { var ignore = t.Exception; }, TaskContinuationOptions.OnlyOnFaulted); } |
Вот как можно его использовать:
Task.Factory.StartNew (() => { throw null; }).IgnoreExceptions(); |
Полезной возможностью продолжений является то, что они начинаются только после завершения дочерних задач. При этом любые исключения, генерируемые дочерними задачами, передаются в задачи-продолжения.
В следующем примере запускаются три дочерние задачи, каждая из которых генерирует NullReferenceException. Затем все они обрабатываются в одном месте с помощью продолжения родительской задачи:
TaskCreationOptions atp = TaskCreationOptions.AttachedToParent;
Task.Factory.StartNew (() =>
{
Task.Factory.StartNew (() => { throw null; }, atp);
Task.Factory.StartNew (() => { throw null; }, atp);
Task.Factory.StartNew (() => { throw null; }, atp);
})
.ContinueWith (p => Console.WriteLine (p.Exception),
TaskContinuationOptions.OnlyOnFaulted); |

Рисунок 5.
По умолчанию запуск продолжений осуществляется
NotOnRanToCompletion = 0x10000, NotOnFaulted = 0x20000, NotOnCanceled = 0x40000, |
Эти флаги обладают следующим свойством: чем больше флагов вы применяете, тем меньше вероятность того, что продолжение будет выполнено. Для удобства существуют также несколько объединенных значений:
OnlyOnRanToCompletion = NotOnFaulted | NotOnCanceled, OnlyOnFaulted = NotOnRanToCompletion | NotOnCanceled, OnlyOnCanceled = NotOnRanToCompletion | NotOnFaulted |
Объединение всех Not* флагов (NotOnRanToCompletion, NotOnFaulted, NotOnCanceled) не имеет смысла.
RanToCompletion означает, что родительская задача завершилась успешно (она не была отменена и не завершилась с необработанным исключением).
Faulted означает, что родительской задачей было сгенерировано необработанное исключение.
Canceled означает одно из двух:
Очень важно понимать, что если продолжение не выполнено из-за этих флагов, то оно не забыто и не покинуто, его выполнение
Task t1 = Task.Factory.StartNew (...); Task fault = t1.ContinueWith (ant => Console.WriteLine ("fault"), TaskContinuationOptions.OnlyOnFaulted); Task t3 = fault.ContinueWith (ant => Console.WriteLine ("t3")); |
После запуска этого кода задача t3 обязательно будет запущена, даже если t1 не сгенерирует исключение. Это связано с тем, что если задача t1 завершится успешно, задача falt будет отменена, и поскольку для задачи t3 ограничения не заданы, она будет выполнена безусловно.

Рисунок 6.
Если мы хотим, чтобы задача t3 запускалась только после выполнения задачи fault, мы должны написать так:
Task t3 = fault.ContinueWith (ant => Console.WriteLine ("t3"), TaskContinuationOptions.NotOnCanceled); |
(С другой стороны, мы можем указать OnlyOnRanToCompletion; в этом случае t3 не будет выполнена, если по ходу выполнения fault произойдет исключение.)
Другой полезной возможностью продолжений является то, что вы можете планировать их выполнение после выполнения нескольких предыдущих задач. Значение ContinueWhenAll приведет к запуску задачи только после завершения всех предыдущих задач. Оба эти методы определены в классе TaskFactory:
var task1 = Task.Factory.StartNew (() => Console.Write ("X")); var task2 = Task.Factory.StartNew (() => Console.Write ("Y")); var continuation = Task.Factory.ContinueWhenAll ( new[] { task1, task2 }, tasks => Console.WriteLine ("Done")); |
Этот код выведет “Done” только после того, как выведет “XY” или “YX”. Аргумент tasks в лямбда-выражении дает доступ к массиву завершенных задач, что бывает полезным, когда предшественники возвращают какие-то данные. В следующем примере складываются два значения, которые возвращаются из двух предшествующих задач:
// В реальных задачах task1 и task2 будут вызывать сложные функции Task<int> task1 = Task.Factory.StartNew (() => 123); Task<int> task2 = Task.Factory.StartNew (() => 456); Task<int> task3 = Task<int>.Factory.ContinueWhenAll ( new[] { task1, task2 }, tasks => tasks.Sum (t => t.Result)); Console.WriteLine (task3.Result); // 579 |
| ПРИМЕЧАНИЕ В этом примере мы добавили аргумент типа <int> в вызов Task.Factory, чтобы пояснить, что мы получаем обобщенную фабрику задач. Аргумент типа является необязательным, поскольку он может быть выведен компилятором. |
Вызов метод ContinueWith более одного раза для одной и той же задачи создает несколько продолжений одной задачи. Когда предыдущая задача завершается, все продолжения запускаются одновременно (если вы не укажете TaskContinuationOptions.ExecuteSynchronously, в этом случае продолжения будут выполняться последовательно).
При выполнении следующего примера происходит задержка в одну секунду, а затем на экран выводится “XY” или “YX”:
var t = Task.Factory.StartNew (() => Thread.Sleep (1000)); t.ContinueWith (ant => Console.Write ("X")); t.ContinueWith (ant => Console.Write ("Y")); |
Если указать для задачи-продолжения
public partial class MyWindow : Window { TaskScheduler _uiScheduler; // Объявляем TaskScheduler в виде поля, чтобы мы // могли его исчпользовать во всем. public MyWindow() { InitializeComponent(); // Получаем планировщик UI для потока, создающего: _uiScheduler = TaskScheduler. FromCurrentSynchronizationContext(); Task.Factory.StartNew<string> (SomeComplexWebService) .ContinueWith (ant => lblResult.Content = ant.Result, _uiScheduler); } string SomeComplexWebService() { ... } } |
Существует также возможность написать свой собственный планировщик задач (путем создания наследника класса TaskScheduler), хотя это может быть полезно лишь в очень специфических сценариях. Для ручной настройки планирования заданий обычно используется класс TaskCompletionSource, который будет рассмотрен ниже.
При вызове Task.Factory происходит обращение к статическому свойству класса Task, которое возвращает объект класса TaskFactory, используемый по умолчанию. Фабрики задач предназначены для создания задач, в частности, для создания трех типов задач:
| ПРИМЕЧАНИЕ Интересно, что TaskFactory является |
TaskFactory – это не
var factory = new TaskFactory ( TaskCreationOptions.LongRunning | TaskCreationOptions.AttachedToParent, TaskContinuationOptions.None); |
Создание задач в этом случае сводится к вызову метода StartNew фабрики:
Task task1 = factory.StartNew (Method1); Task task2 = factory.StartNew (Method2); ... |
Настройки поведения продолжений будут применены при вызове методов ContinueWhenAll и ContinueWhenAny.
Класс Task предназначен для двух независимых целей:
Интересно, что, по сути, эти возможности не связаны: вы можете использовать возможности задач для управления рабочими элементами без использования пула потоков. Класс, который предоставляет такие возможности, называется TaskCompletionSource.
Для использования TaskCompletionSource нужно просто создать экземпляр этого класса. Он предоставляет свойство Task, которое возвращает задачу, завершение выполнения которой вы можете ожидать или присоединять к ней продолжения, аналогично тому, как это делается с любыми другими задачами. Однако задача полностью контролируется с помощью объекта TaskCompletionSource посредством следующих методов:
public class TaskCompletionSource<TResult> { public void SetResult (TResult result); public void SetException (Exception exception); public void SetCanceled(); public bool TrySetResult (TResult result); public bool TrySetException (Exception exception); public bool TrySetCanceled(); ... } |
Если методы SetResult, SetException или SetCanceled вызвать более одного раза, то будет сгенерировано исключение; вызов же методов Try* вернет false.
| ПРИМЕЧАНИЕ TResult соответствует типу возвращаемого значения задачи, так что TaskCompletionSource<int> вернет Task<int>. Если нужна задача, которая ничего не возвращает, создайте TaskCompletionSource<object> и передайте null при вызове SetResult. Затем вы можете привести объект Task<object> к Task. |
Следующий пример выводит «1 2 3» через пять секунд ожидания:
var source = new TaskCompletionSource<int>(); new Thread (() => { Thread.Sleep (5000); source.SetResult (123); }) .Start(); Task<int> task = source.Task; // Наша «дочерняя» задача. Console.WriteLine (task.Result); // 123 |
Далее будет показано, как класс BlockingCollection может быть использован для написания очереди типа поставщик/потребитель. Затем будет продемонстрировано, как класс TaskCompletionSource может улучшить решение, предоставив возможность ожидать завершения и отменять выполнение элементов очереди.
Как вы уже видели ранее, PLINQ, класс Parallel и задачи автоматически выполняют передачу исключения клиенту. Чтобы понять, почему это так важно, давайте рассмотрим следующий LINQ-запрос, который генерирует исключение DivideByZeroException на первой итерации:
try { var query = from i in Enumerable.Range (0, 1000000) select 100 / i; ... } catch (DivideByZeroException) { ... } |
Если попросить PLINQ распараллелить этот запрос, и если будет проигнорирована обработка исключений, то DivideByZeroException будет выброшено в
Вот почему исключения автоматически перехватываются и передаются вызывающему коду. Но, к сожалению, обычно все сложнее, чем простой перехват DivideByZeroException. Поскольку эти библиотеки упрощают работу с несколькими потоками, на самом деле возможна ситуация, когда два или более исключения возникнут одновременно. Для гарантии того, что информация ни о каких исключениях не будет потеряна, исключения заворачиваются в AggregateException, свойство InnerExceptions которого содержит все перехваченные исключения:
try { var query = from i in ParallelEnumerable.Range (0, 1000000) select 100 / i; // Перебираем результаты ... } catch (AggregateException aex) { foreach (Exception ex in aex.InnerExceptions) Console.WriteLine (ex.Message); } |
PLINQ, как и класс Parallel, завершает выполнение запроса или цикла при возникновении первого исключения, и обработка последующих элементов и тел цикла не выполняется. Однако до завершения текущей итерации цикла могут возникнуть и другие исключения. Первое возникшее исключение доступно через свойство InnerException класса AggregateException.
Класс AggregateException предоставляет пару методов, упрощающих обработку исключений: методы Flatten и Handle.
Исключения AggregateException довольно часто будут содержать другие исключения с типом AggregateException. Например, это может произойти, если дочерняя задача сгенерирует исключение. Можно устранить любое количество уровней вложенности и упростить обработку исключения путем вызова метода Flatten. Этот метод возвращает новый объект AggregateException, который содержит простой плоский список вложенных исключений:
catch (AggregateException aex) { foreach (Exception ex in aex.Flatten().InnerExceptions) myLogWriter.LogException (ex); } |
Иногда бывает удобным перехватывать только определенные типы исключений, а другие типы исключений передавать дальше. Метод Handle класса AggregateException предоставляет такую возможность. Он принимает предикат, который выполняется для каждого вложенного исключения:
public void Handle (Func<Exception, bool> predicate) |
Если предикат возвращает true, считается, что исключение «обработано». После того, как этот делегат выполнен для каждого исключения, происходит следующее:
Например, следующий код перегенерирует другой объект AggregateException, который содержит единственное исключение с типом NullReferenceException:
var parent = Task.Factory.StartNew (() => { // Мы будем генерировать 3 исключения сразу с помощью трех дочерних задач: int[] numbers = { 0 }; var childFactory = new TaskFactory (TaskCreationOptions.AttachedToParent, TaskContinuationOptions.None); childFactory.StartNew (() => 5 / numbers[0]); // Division by zero childFactory.StartNew (() => numbers [1]); // Index out of range childFactory.StartNew (() => { throw null; }); // Null reference }); try { parent.Wait(); } catch (AggregateException aex) { // Обратите внимание, нам все еще нужно вызвать метод Flatten aex.Flatten().Handle (ex => { if (ex is DivideByZeroException) { Console.WriteLine ("Divide by zero"); return true; // Это исключение «обработано» } if (ex is IndexOutOfRangeException) { Console.WriteLine ("Index out of range"); return true; // Это исключение «обработано» } return false; // Все остальные исключения будут переданы далее }); } |
Framework 4.0 предоставляет набор новых коллекций в пространстве имен System.Collections.Concurrent. Все они полностью потокобезопасны:
|
Параллельная коллекция |
Непараллельный эквивалент |
|---|---|
|
ConcurrentStack<T> |
Stack<T> |
|
ConcurrentQueue<T> |
Queue<T> |
|
ConcurrentBag<T> |
(нет) |
|
BlockingCollection<T> |
(нет) |
|
ConcurrentDictionary <TKey,TValue> |
Dictionary <TKey,TValue> |
Параллельные коллекции иногда бывают полезны при решении обычных задач многопоточности, когда нужна потокобезопасная коллекция. Однако есть несколько пояснений:
Другими словами, использование этих коллекций не эквивалентно использованию стандартных коллекций с операторами lock. Например, если выполнить этот код в одном потоке:
var d = new ConcurrentDictionary<int,int>(); for (int i = 0; i < 1000000; i++) d[i] = 123; |
он будет выполняться втрое медленнее, нежели следующий код:
var d = new Dictionary<int,int>(); for (int i = 0; i < 1000000; i++) lock (d) d[i] = 123; |
(Однако
Параллельные коллекции отличаются от стандартных коллекций еще и тем, что они содержат специальные методы для выполнения атомарных операций типа «проверить-и-выполнить» (test-and-act), такие как TryPop. Большинство этих методов унифицированы посредством интерфейса IProducerConsumerCollection<T>.
Существует два основных сценария использования коллекций типа поставщик/потребитель (producer/consumer):
Классическим примером являются стеки и очереди. Коллекции типа поставщик/потребитель играют значительную роль в мире параллельного программирования, поскольку они прекрасно подходят для эффективных lock-free реализаций.
Интерфейс IProducerConsumerConnection<T> представляет потокобезопасную коллекцию типа поставщик/потребитель. Следующие классы реализуют этот интерфейс:
Интерфейс IProducerConsumerCollection<T> расширяет интерфейс ICollection<T> путем добавления следующих методов:
void CopyTo (T[] array, int index); T[] ToArray(); bool TryAdd (T item); bool TryTake (out T item); |
Методы TryAdd и TryTake проверяют, может ли быть выполнена операция добавления/удаления элемента, и если операция может быть выполнена, то она выполняется. Проверка и выполнение операции выполняются атомарно, устраняя необходимость в блокировке, которая понадобилась бы при использовании стандартной коллекции:
int result; lock (myStack) if (myStack.Count > 0) result = myStack.Pop(); |
Метод TryTake возвращает false, если коллекция пуста. Метод TryAdd всегда завершается успешно и возвращает true во всех трех существующих реализациях. Если вы напишете свою собственную параллельную коллекцию, которая будет запрещать дубликаты, то она сможет возвращать false, если такой элемент уже существует в коллекции (например, если вы напишете параллельную версию класса
Конкретный элемент, который удаляется при вызове метода TryTake, определяется конкретной реализацией:
Эти три класса в основном реализуют методы TryTake и TryAdd явно (explicitly), предоставляя ту же самую функциональность с помощью других открытых методов с более точными названиями, такими как TryDequeue и TryPop.
Класс ConcurrentBag<T> хранит
Преимущество использования ConcurrentBag<T> по сравнению с ConcurrentQueue<T> и ConcurrentStack<T> состоит в том, что при вызове метода Add из нескольких потоков одновременно
Внутри ConcurrentBag<T> содержит связный private-список для каждого потока. Элементы добавляются в этот список, который относится к тому потоку, который вызвал метод Add, тем самым устраняя конкуренцию. Когда вы перебираете значения коллекции, перечислитель проходит по закрытому списку каждого потока, возвращая каждый элемент этого списка.
Когда вы вызываете метод Take, вначале просматривается закрытый (private) список текущего потока. Если там есть хотя бы один элемент, задача может быть завершена очень быстро и (в большинстве случаев) безо всякой конкуренции. Но если этот список пуст, метод должен «украсть» элемент из private-списка другого потока, что может повлечь возможный конкурентный доступ.
Короче говоря, метод Take вернет последний элемент, добавленный этим потоком; если такого элемента нет, то он вернет последний элемент, добавленный другим, случайно выбранным потоком.
Класс ConcurrentBag<T> идеально подходит, когда основными параллельными операциями являются добавление элементов, или когда добавление и получение элементов сбалансировано для каждого потока. Первый вариант мы видели, когда мы использовали Parallel.ForEach для реализации параллельной проверки правописания:
var misspellings = new ConcurrentBag<Tuple<int,string>>(); Parallel.ForEach (wordsToTest, (word, state, i) => { if (!wordLookup.Contains (word)) misspellings.Add (Tuple.Create ((int) i, word)); }); |
ConcurrentBag будет плохим выбором для очереди типа “поставщик/потребитель», поскольку в этом случае элементы добавляются и удаляются
При вызове метода TryTake на любой из коллекций типа «поставщик/потребитель», которые мы обсудили ранее (ConcurrentStack<T>, ConcurrentQueue<T> и ConcurrentBag<T>) возвращается false, если коллекция пуста. В некоторых сценариях полезно
Вместо добавления соответствующей перегруженной версии метода TryTake с этой функциональностью (что приведет к резкому скачку количества членов после добавления отмены и таймаутов), разработчики PFX решили инкапсулировать эту функциональность в отдельном классе под названием BlockingCollection<T>. Этот класс оборачивает любую коллекцию, которая реализует интерфейс IProducerConsumerCollection<T>, и позволяет получать элемент из нижележащей коллекции, блокируя выполнение, если такого элемента нет.
Блокирующая коллекция также позволяет ограничить общий размер коллекции, блокируя
Для использования BlockingCollection<T>:
Если при вызове конструктора вы не передадите коллекцию, автоматически будет создан экземпляр класса ConcurrentQueue<T>. Методы добавления и удаления элементов позволяют указать маркеры отмены и таймауты. Методы Add и TryAdd могут блокировать выполнение в случае ограничения размера коллекции; методы Take и TryTake блокируют выполнение, если коллекция пуста.
Другим способом получения элементов коллекции является вызов метода GetConsumingEnumerable. Этот метод возвращает (потенциально) бесконечную последовательность, которая возвращает элементы, когда они становятся доступными. Можно принудительно завершить последовательность путем вызова метода CompleteAdding: этот метод также предотвращает последующие добавления элементов в очередь.
Мы уже написали очередь типа поставщик/потребитель, используя методы Wait и Pulse. Вот тот же самый класс, переработанный с использованием BlockingCollection<T> (обработка исключений опущена):
public class PCQueue : IDisposable { BlockingCollection<Action> _taskQ = new BlockingCollection<Action>(); public PCQueue (int workerCount) { // Создаем и запускаем независимую задачу для каждого: for (int i = 0; i < workerCount; i++) Task.Factory.StartNew (Consume); } public void Dispose() { _taskQ.CompleteAdding(); } public void EnqueueTask (Action action) { _taskQ.Add (action); } void Consume() { // Последовательность, которую мы перебираем будет заблокирована, // когда не будет доступных элементов, и завершится после выззова. foreach (Action action in _taskQ.GetConsumingEnumerable()) action(); // Выполняем задачу. } } |
Поскольку мы ничего не передали в конструктор BlockingCollection, он автоматически создал экземпляр параллельной очереди. Если бы мы передали экземпляр ConcurrentStack, мы бы получили стек типа поставщик/потребитель.
Класс BlockingCollection также содержит статические методы AddToAny и TakeFromAny, которые позволяют добавлять или получать элемент из нескольких блокируемых коллекций. При этом действие выполняется над первой коллекцией, способной обработать этот запрос.
Только что написанный класс типа «поставщик/потребитель» является не гибким в том плане, что не позволяет отслеживать состояние элемента после его добавления в коллекцию. Было бы здорово, если бы мы могли:
Идеальным решением было бы наличие метода EnqueueTask, который бы возвращал объект, предоставляющий всю описанную выше функциональность. Хорошая новость в том, что такой класс уже существует, и делает именно то, что нужно. Это класс Task. Все, что нужно – это перехватить управление задачей с помощью TaskCompletionSource:
public class PCQueue : IDisposable { class WorkItem { public readonly TaskCompletionSource<object> TaskSource; public readonly Action Action; public readonly CancellationToken? CancelToken; public WorkItem ( TaskCompletionSource<object> taskSource, Action action, CancellationToken? cancelToken) { TaskSource = taskSource; Action = action; CancelToken = cancelToken; } } BlockingCollection<WorkItem> _taskQ = new BlockingCollection<WorkItem>(); public PCQueue (int workerCount) { // Создаем и запускаем независимуюд задачу для каждого: for (int i = 0; i < workerCount; i++) Task.Factory.StartNew (Consume); } public void Dispose() { _taskQ.CompleteAdding(); } public Task EnqueueTask (Action action) { return EnqueueTask (action, null); } public Task EnqueueTask (Action action, CancellationToken? cancelToken) { var tcs = new TaskCompletionSource<object>(); _taskQ.Add (new WorkItem (tcs, action, cancelToken)); return tcs.Task; } void Consume() { foreach (WorkItem workItem in _taskQ.GetConsumingEnumerable()) if (workItem.CancelToken.HasValue && workItem.CancelToken.Value.IsCancellationRequested) { workItem.TaskSource.SetCanceled(); } else try { workItem.Action(); workItem.TaskSource.SetResult (null); // Указываем о завершении } catch (Exception ex) { workItem.TaskSource.SetException (ex); } } } |
В методе EnqueueTask в очередь добавляется рабочий элемент, инкапсулирующий в себе делегат и объект класса TaskCompletionSource, который, в свою очередь, позволяет позднее управлять задачей, которая будет возвращена из этого метода.
В методе Consume вначале проверяется, не отменена ли задача после удаления рабочего элемента. Если нет, запускается делегат, и затем вызывается метод SetResult объекта TaskCompletionSource для указания завершения выполнения задачи.
Вот как можно использовать этот класс:
var pcQ = new PCQueue (1); Task task = pcQ.EnqueueTask (() => Console.WriteLine ("Easy!")); ... |
Теперь можно ожидать завершения задачи task, выполнять продолжения для этой задачи, распространять исключения на продолжения родительских задач и т.д. Другими словами, мы получили богатство модели задач, реализовав фактически свой собственный планировщик.
В мире параллельного программирования использование спин-примитивов всегда предпочтительнее использования блокировок, поскольку это устраняет накладные расходы на переключение контекста и переходы в режим ядра. SpinLock и SpinWait разработаны специально для того, чтобы помочь в таких случаях. В основном они применяются для разработки собственных конструкций синхронизации.
| ПРЕДУПРЕЖДЕНИЕ SpinLock и SpinWait являются структурами, а не классами! Это решение является серьезной оптимизацией, позволяющей избежать косвенных накладных расходов сборщика мусора. Это значит, что вы должны быть внимательными и, например, не создать случайно |
Структура SpinLock позволяет заблокировать выполнение, не подвергаясь накладным расходам на переключение контекста, путем того, что поток будет крутиться в бесконечном цикле (spinning) (занят бесполезной работой). Этот подход разумен в сценариях с высокой конкуренцией, когда блокировка будет захватываться на очень короткий промежуток времени (например, при написании потокобезопасного связного списка с нуля).
| ПРИМЕЧАНИЕ Если спин-блокировка будет продолжаться слишком длительное время (мы говорим максимум о миллисекундах), это израсходует отведенный потоку квант времени и приведет к переключению контекста, как и при обычной блокировке. Когда поток получит управление, снова произойдет переключение контекста с помощью цикла «ожидания/переключения» (“spin-yielding”)* Это расходует значительно меньше ресурсов процессора посравнению с обычной спин-блокировкой, но больше по сравнению с обычной блокировкой потока. На машине с одноядерным процессором в случае ожидания спин-блокировки переключение контекста произойдет сразу же.
|
Использование структуры SpinLock аналогично использованию обычной блокировки (конструкции lock), за исключением следующего:
Другим отличием является то, что при вызове метода Enter вы
Вот пример:
var spinLock = new SpinLock (true); // Разрешаем отслеживание владельца bool lockTaken = false; try { spinLock.Enter (ref lockTaken); // Выполняем что-либо... } finally { if (lockTaken) spinLock.Exit(); } |
Как и при использовании обычной блокировки, значение lockTaken после вызова метода Enter будет равным false только в том случае, если метод сгенерирует исключение и блокировка не будет захвачена. Это происходит в очень редких случаях (таких, как вызов метода Abort текущего потока или генерация исключения OutOfMemoryException) и позволяет точно знать, нужен ли последующий вызов метода Exit.
Структура SpinLock содержит также метод TryEnter, который принимает тайм-аут в качестве параметра.
| ПРИМЕЧАНИЕ Неуклюжая семантика типов-значений и отсутствие языковой поддержки для спин-блокировок заставляют предположить, что разработчики этой конструкции |
Наиболее разумным сценарием применения SpinLock является создание собственных конструкций синхронизации. И даже тогда спин-блокировки не являются такими полезными, как может показаться. Они все еще ограничивают параллелизм. И они понапрасну расходуют ресурсы процессора, не выполняя
SpinWait помогает в разработке lock-free кода, который крутится в цикле (spins), а не блокируется. Это осуществляется путем реализации особых мер, предотвращающих ресурсное голодание (resource starvation) и инверсию приоритета (priority inversion), которые в противном случае могут возникнуть в случае ожидания в цикле (spinning).
| ПРЕДУПРЕЖДЕНИЕ Lock-free программирование с помощью SpinWait – это одна из наиболее сложных техник в многопоточном программировании, которая используется тогда, когда никакие другие, более высокоуровневые, конструкции не способны решить поставленную задачу. Предварительным условием для использования этой конструкции является понимание принципов неблокирующей синхронизации. |
Предположим, мы написали систему уведомления исключительно с помощью простого флага:
bool _proceed; void Test() { // Крутимся в цикле, пока другой поток не выставит _proceed в true: while (!_proceed) Thread.MemoryBarrier(); ... } |
Этот код будет очень эффективным, если при запуске функции Test флаг _proceed уже будет установлен в true, или _proceed станет равным true спустя несколько циклов после этого. Но давайте предположим, что значение _procceed будет равно false в течение нескольких секунд, и что метод Test будет вызван одновременно четырьмя потоками. В таком случае ожидание в цикле загрузит все четыре ядра четырехядерного процессора! Это приведет к замедлению работы других потоков (вследствие ресурсного голодания), включая выполнение того потока, который в конечном счете установит значение _proceed в true (инверсия приоритета). Ситуация обостряется еще сильнее на одноядерных компьютерах, где ожидание в цикле практически всегда приводит к инверсии приоритета (и хотя сегодня одноядерные компьютеры становятся редкостью, одноядерные
Структура SpinWait решает эту проблему двумя путями. Во-первых, она ограничивает ресурсоемкие циклы до определенного количества итераций, по истечению которых квант времени, выделенный текущему потоку, прерывается на каждой последующей итерации (путем вызова метода Thread.Yield и Thread.Sleep), снижая тем самым потребление ресурсов. Во-вторых, она определяет, происходит ли выполнение на одноядерном компьютере, и если это так, то прерывает выполнение каждого цикла.
Существует два способа использования структуры SpinWait. Первый способ – использовать статический метод SpinUntil. Этот метод принимает предикат (и таймаут в качестве необязательного параметра).
bool _proceed; void Test() { SpinWait.SpinUntil (() => { Thread.MemoryBarrier(); return _proceed; }); ... } |
Другим (более гибким) способом использования SpinWait является создание экземпляра структуры с последующим вызовом SpinOnce в цикле:
bool _proceed; void Test() { var spinWait = new SpinWait(); while (!_proceed) { Thread.MemoryBarrier(); spinWait.SpinOnce(); } ... } |
В текущей реализации SpinWait выполняет 10 итераций, прежде чем произойдет переключение контекста. Однако управление не возвращается
На одноядерном компьютере SpinWait переключает контекст выполнения на каждой итерации. Вы можете проверить, будет ли SpinWait прерывать выполнение потока при следующем вызове с помощью свойства NextSpinWillYield.
Если SpinWait будет оставаться в режиме «ожидания/переключения» (“spin-yielding”) достаточно долго (порядка 20 циклов), то он периодически начнет вызвать Thread.Sleep на несколько миллисекунд, для еще большего сберегания ресурсов, что поможет выполнять полезную работу другим потокам.
SpinWait совместно с Interlocked.CompareExchange может применяться для атомарного обновления полей значениями, вычисляемыми на основе предыдущего значения (read-modify-write). Предположим, что мы хотим умножить значение поля x на 10. Такой простой способ не является потокобезопасным:
x = x * 10; |
по той же причине, что и инкремент поля не является потокобезопасной операцией, как было показано в разделе Неблокирующая синхронизация.
Корректный способ выполнения этой операции без блокировок выглядит так:
Например:
int x; void MultiplyXBy (int factor) { var spinWait = new SpinWait(); while (true) { int snapshot1 = x; Thread.MemoryBarrier(); int calc = snapshot1 * factor; int snapshot2 = Interlocked.CompareExchange (ref x, calc, snapshot1); if (snapshot1 == snapshot2) return; // Нас никто не опередил. spinWait.SpinOnce(); } } |
| ПРИМЕЧАНИЕ Можно повысить производительность (немного), убрав вызов функции Thread.MemoryBarrier. Этот вызов необязателен, поскольку метод CompareExchange в любом случае создает барьер памяти, так что худшее, что может произойти в этом случае – дополнительный цикл ожидания, если snapshot1 получит старое значение на первой итерации. |
Метод Interlocked.CompareExchange обновляет значение поля указанным значением,
Метод CompareExchange перегружен, чтобы работать также и с типом object. Этой перегрузкой можно воспользоваться, чтобы реализовать lock-free обновление любых ссылочных типов:
static void LockFreeUpdate<T> (ref T field, Func <T, T> updateFunction) where T : class { var spinWait = new SpinWait(); while (true) { T snapshot1 = field; T calc = updateFunction (snapshot1); T snapshot2 = Interlocked.CompareExchange (ref field, calc, snapshot1); if (snapshot1 == snapshot2) return; spinWait.SpinOnce(); } } |
Вот как можно использовать этот метод для потокобезопасной работы с событиями без использования блокировок (кстати, именно так компилятор C# 4.0 реализует события по умолчанию):
EventHandler _someDelegate; public event EventHandler SomeEvent { add { LockFreeUpdate (ref _someDelegate, d => d + value); } remove { LockFreeUpdate (ref _someDelegate, d => d - value); } } |
| ПРИМЕЧАНИЕ
Можно решить решить предыдущую задачу по-другому, обернув доступ к разделяемому полю с помощью SpinLock. Однако проблема со спин-блокировкой заключается в том, что она позволяет продолжить выполнение только одному потоку за раз, хотя и устраняет (обычно) накладные расходы на переключение контекста. С помощью SpinWait можно продолжить выполнение, |
В заключение давайте рассмотрим следующий класс:
class Test { ProgressStatus _status = new ProgressStatus (0, "Starting"); class ProgressStatus // Класс неизменяемый { public readonly int PercentComplete; public readonly string StatusMessage; public ProgressStatus (int percentComplete, string statusMessage) { PercentComplete = percentComplete; StatusMessage = statusMessage; } } } |
Можно использовать метод LockFreeUpdate для «инкремента» поля _status класса PercentComplete следующим образом:
LockFreeUpdate (ref _status, s => new ProgressStatus (s.PercentComplete + 1, s.StatusMessage)); |
Обратите внимание, что здесь создается новый объект класса ProgressStatus на основе существующего значения. Благодаря методу LockFreeUpdate, процесс чтения существующего значения объекта PercentComplete, увеличение его на единицу и запись этого значения обратно не могут быть прерваны
| Оценка 1020
[+1/-0]
Оценить
|
