Метод “таблиц-двойников”
Метод единой таблицы аудита
Метод таблиц-версий
Метод одной таблицы версий
Oracle и flashback queries
C2 audit

|
Метод последнего изменения
Метод “таблиц-двойников” Метод единой таблицы аудита Метод таблиц-версий Метод одной таблицы версий Oracle и flashback queries C2 audit |
|
Одной из частых задач при проектировании базы данных является протоколирования действий пользователей и разработка механизма версионности записей. Существует много различных методов решения этой задачи. В статье рассмотрены наиболее часто используемые при этом методы и проблемы, с которыми можно столкнуться. Для начала надо определиться с терминологией, иначе можно запутаться – у каждого может быть свой взгляд на то, что такое история изменений. Под историей изменений я имею в виду историю изменения записи таблицы базы данных. Помещенные в историю значения являются статическими и уже не могут изменяться (версии значений). Версионность обычно возникает из требования к системе предоставлять состояния записи на моменты в прошлом, протоколирование нужно для выяснения обстоятельств неправильного ввода информации.
Например, в расчете зарплаты есть понятие ставки, которая может изменяться ежедневно. Зарплата считается по актуальным для какой-то даты значениям ставок. Например, если ставка действует с 15 числа, и меняется раньше того дня, когда она должна применяться, то достаточно просто отметить, что запись была изменена (например, пользователем DBUser 10-го апреля в 14:15). Если потребуется узнать, кто последний изменял запись, можно быстро получить ответ. Но если пользователь захочет поменять ставку после того дня, когда она начала применяться и по ней пошли расчеты зарплаты, то нужно создавать новую версию записи. Обычно процесс создания новых версий для пользователя является прозрачным, т.е. пользователь ничего не знает про версии и работает, как будто никаких версий нет, ему показывается лишь одна запись по состоянию на какую-то дату, обычно последнюю. Если я запущу расчет зарплаты за прошлый месяц с точки зрения данных прошлого месяца, то мне и будет все посчитано так, как было в прошлом месяце, цифра в цифру. Если же расчет будет запущен с точки зрения данных текущего месяца, то у меня получатся другие результаты. Это я и называю историей (версионностью значений данных) - атрибуты объекта, взятые во времени, никогда не противоречат остальным данным системы за период их действия.
Для многих задач достаточно отслеживать, кто и когда последний раз изменял запись. Например, есть таблица “Карточка основного средства”. При внесении изменения в эту таблицу хочется знать, кто последний менял запись. В этом случае нужно добавить во все таблицы два поля: автора и время изменения . Если требуется также знать, кто удалял запись, необходимо добавить поле-признак удаления, например IsDeleted bit default 0, где значение 0 означает, что запись не удалена, 1 – что запись логически удалена. При таком подходе, вместо удаления записи физически командой delete, требуется логическое удаление записей. При выборках необходимо фильтровать по значению этого поля, при удалениях записей – просто изменить значение поля признака логического удаления. Наличие поля IsDeleted очень полезно при возникновении вопроса, куда делась запись – можно быстро и легко посмотреть, кто же ее удалил. Плюсы и минусы этого метода очевидны – требуется мало дополнительного места, просто в реализации. При таком подходе можно получить последнего пользователя, внесшего изменения, что во многих случаях является достаточным для выяснения обстоятельств неверного ввода. Однако метод не позволяет получить информацию о состоянии до последнего изменения. Кроме того, периодически нужно чистить такие таблицы, физически удаляя записи, помеченные как удаленные – например, все, помеченные, как удаленные, более месяца назад. Если операция удаления выполняется часто, то лучше переносить удаленные записи в другие таблицы, чтобы не засорять исходные удаленными записями.
Метод заключается в том, что для каждой основной таблицы создается дублирующая таблица, включающая все поля из исходной таблицы, а также поле-тип операции над записью. При необходимости добавляются дополнительные служебные поля. Данный подход можно назвать методом таблиц-двойников или таблиц истории. При изменениях основной записи в таблице истории создается копия измененной записи с отметкой, кто и когда ее изменил. На рис. 1 показан пример взаимодействия основной таблицы и таблицы-двойника.
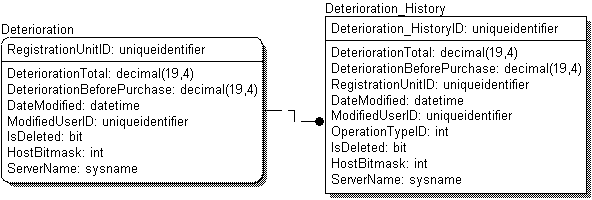
Рис. 1. Взаимодействие основной таблицы и таблицы-двойника
В примере показана таблица Deterioration (износ), содержащая первичный ключ с названием RegistrationUnitID, и связанная по нему с таблицей истории Deterioration_History. В таблице истории, кроме полей исходной таблицы, содержится поле OperationTypeID. В это поле заносится тип операции – создание записи, изменение или удаление.
Иногда достаточно, чтобы сохранялись не все состояния записи, а только часть изменений. Например, какой-то пользователь несколько раз поменял одну и ту же запись. Нужно ли нам сохранять все эти изменения? Это зависит от требований к программе. В приведенном выше примере со ставкой зарплаты версии изменений необходимо создавать только если ставка измененяется после того как она начала применяться. В похожих случаях имеет смысл применение комбинированного подхода. В тех случаях, когда при изменении записи требуется сохранять предыдущее состояние, необходимо создавать новые версии записей. Для создания новой версии нужно скопировать измененную запись в таблицу-двойник. Когда новая версия не нужна — просто изменять основную запись. В этом случае при изменении основной записи можно записывать в нее же, кто и когда ее изменил. В любой возможной реализации такого подхода несложно сделать включение/выключение протоколирования, если база начнет переполняться.
Метод таблиц-двойников хорошо применять, если изменения основной таблицы происходят не слишком часто. Иначе нужно применять другие подходы, потому что таблицы истории будут быстро расти. Метод обеспечивает возможность получения данных на любой момент времени, что необходимо для версионности записей. Однако, если в таблице есть группа часто меняющихся атрибутов, можно вынести протоколирование изменений этих атрибутов в отдельную таблицу. Таким образом, протоколирование изменений будет разделено на 2 части: запись частых и запись редких изменений. Такой подход позволяет без существенных трудозатрат добавлять протоколирование операций и версионность записей для любой таблицы. Метод прост в реализации, несложно включается практически в любое приложение, даже если оно не было изначально рассчитано на работу с историческими данными. Еще один, и довольно существенный плюс такого подхода – простота написания запросов для получения состояния записи на любой момент времени.
Допустим, что для приведенных на рис. 1 таблиц потребуется получить состояние записи в таблице Deterioration, имеющей значение первичного ключа RegistrationUnitID=’ {1CCE32A7-0E5E-4222-950E-01EC3D919775}’ на 4 апреля 2004 года, 14:30. Для этого в таблице Deteriration_History нужно найти все записи, что были изменены до этого момента, и среди них найти ту запись, которая была изменена последней. Это и есть состояние записи на заданный момент. Полностью запрос:
select *
from Deterioration_History dethist
where RegistrationUnitID='{1CCE32A7-0E5E-4222-950E-01EC3D919775}'and DateModified<='4/4/2004 14:30'andnotexists(select dh.* from Deterioration_History dh
where dh.RegistrationUnitID='{1CCE32A7-0E5E-4222-950E-01EC3D919775}'and dh.DateModified<='4/4/2004 14:30'and dh.DateModified>dethist.DateModified )
|
В таблице Deterioration_History имеется кластерный индекс по полю RegistrationUnitID, являющемуся первичным ключом в основной таблице, что обеспечивает высокую скорость работы запросов к таблице истории.
Нужно отметить, что производительность, если и снижается, то ненамного. Это связано с тем, что исторические и актуальные данные находятся в разных таблицах, а большинство запросов выполняется к актуальным данным. Таким образом, производительность снижается только за счет некоторого количества обращений к таблицам изменений. Минус, похоже, только один, но существенный – требуется большой объем дискового пространства для хранения таблиц-двойников. Однако этот недостаток можно существенно уменьшить, если хранить не всю историю изменений, а только за некоторый интервал времени, например, за месяц. Если все-таки требуется, чтобы сохранялась информация обо всех изменениях, то необходимо оценить расходы дисковой памяти — возможно, не все так плохо, как кажется. Например, в проекте, где я сейчас занимаюсь базой данных, по расчетам размер базы достигнет 1 Тб только через 5 лет эксплуатации. Значительную часть этого объема будут составлять таблицы изменений. В проекте применен описанный здесь подход – для небольшой части таблиц ведутся версии записей, для основной же части таблиц ведется простая фиксация того, кто и когда изменил запись.
Довольно часто применяемый метод протоколирования – создание одной таблицы аудита. Пример такой таблицы показан на рис 2. Поля записи имеют следующий смысл:
Здесь я предполагаю, что ключ не составной и имеет тип int. Если имеются составные первичные ключи, или первичный ключ имеет другой тип, несложно в эту схему внести соответствующие изменения. В поле OperationData вносится информация об изменении данных, необходимая для понимания сути изменений. Минимальной информацией является сам факт изменения записи. А можно вносить все измененные поля вместе с их значениями.
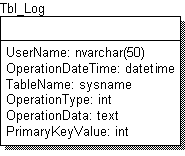
Рис. 2. Единая таблица аудита.
При организации такой схемы может возникнуть нежелательная ситуация, когда добавления или изменения данных будут приводить к блокировке одного и того же ресурса. Такая ситуация часто возникает, когда производится блокировка на уровне страницы. Например, в отсутствие общей таблицы аудита модификация записей в двух разных таблицах вряд ли может привести к блокировкам. Но если информация об изменениях этих записей должна заноситься в одну и ту же таблицу, с большой вероятностью возникнет узкое место. Такие проблемы могут возникать, если частой операцией в базе является операция изменения записей и не включен механизм блокировок уровня записи.
В одной из реализаций, с которыми мне пришлось столкнуться, при любой операции с таблицами, за которыми ведется наблюдение, в таблицу аудита вносилась запись. В поле «сведения об операции» при создании новой записи заносились все значения полей в формате “название поле=’значение’”, через запятую. Далее, при изменении, в таком же формате вносились значения измененных полей, а при удалении туда помещалось в том же формате все содержимое записи. Сделано все это было на триггерах, приходилось анализировать каждую запись: смотреть, что в ней поменялось, готовить строку для сохранения, сохранять. Разумеется, в случае групповых операций все это работает очень медленно. Например, возникла задача обновить расписание полетов. Оно находилось в двух таблицах, на каждой из которых был включен триггер, ведущий протоколирование. Обновление при включенном протоколировании выполнялось около 5 минут, и несколько секунд с отключенными триггерами – это было на базе Oracle 8.1.7. Думаю, что и на других БД, в том числе SQL Server, такой подход тоже будет медленным. Кроме низкой производительности, такой подход имеет еще один существенный недостаток: очень сложно получить состояние записи на какой-то момент времени. Такой метод хорошо подходит для протоколирования изменений, но не для версионности. Как-то передо мной была поставлена задача по восстановлению состояния записи на произвольный момент в БД, использующей такую схему. Задача не из невозможных, но довольно сложная. Версии записей в такой схеме получаются долго - много вычислений. Был написан метод, который получает текущее состояние записи, а затем последовательно просматривает сведения об изменении этой записи в таблице аудита. По данным, хранящимся в этой таблице, восстанавливается состояние записи на заданный момент.
Однако такая схема все же применяется, так как требует меньше места, чем вариант с таблицами-двойниками. В основных таблицах так же, как и в методе таблиц-двойников, хранятся только актуальные версии записей, что делает запросы по актуальным данным достаточно быстрыми. В целом, метод хорошо подходит для протоколирования изменений БД, где нет массовых операций (или есть возможность отключать протоколирование на время массовых операций), где есть требования экономии дискового пространства и нет необходимости быстро получать состояние записей на произвольный момент времени.
Одной из вариаций этого подхода является разбиение таблицы аудита на две, что показано на рис. 3.
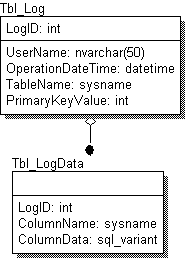
Рис.3. Разделение таблицы аудита на две.
По сравнению с предыдущим подходом с единой таблицей аудита, здесь измененные значения полей вынесены в отдельную таблицу Tbl_LogData – для каждого изменения создается запись в Tbl_Log с пометкой, кто и когда проводил изменение, название таблицы и значение первичного ключа. Затем в таблицу Tbl_LogData заносятся измененные значения полей. Тип sql_variant не позволяет сохранять данные типа image или text, поэтому, если потребуется сохранять и их, то нужно делать дополнительную таблицу для них.
Впервые задача по созданию базы с версионностью записей возникла у меня в моем первом проекте БД для корпоративной информационной системы. Одним из требований была возможность получения не только версии какой-то записи, но и версии записей из других таблиц, на которые эта запись ссылается. Каждая таблица, для которой был необходим этот механизм, разбивалась на две: таблицу-заголовок и таблицу версий. Таблица-заголовок — это таблица с неизменяемой частью записи. Запись туда заносится один раз и больше никогда не изменяется, за исключением проставления отметки о логическом удалении. Таблица версий записи содержит набор изменямых атрибутов. При изменении записи создается новая версия, прежняя версия используется только для истории. Для того чтобы ссылки указывали на определенную версию записи, делаем ссылку на таблицу версий записи. Если не нужно получать версию записи, то делаем ссылку на таблицу-заголовок. . На рис. 4. показан пример структуры таблиц при описанном подходе.

Рис. 4. Таблица с неизменяемой частью и таблица версий.
На диаграмме приведены три таблицы. Таблица Tbl_Subject содержит неизменяемую часть данных о контрагенте и является таблицей-заголовком для контрагента; таблица Tbl_SubjectVersion содержит записи с версиями контрагента; Tbl_SupplierOffer – одна из таблиц, содержащая информацию о коммерческих предложениях поставщиков. Как видно, для контрагента было найдено совсем немного неизменяемых атрибутов. На той же диаграмме видны два варианта ссылок: ссылка на таблицу-заголовок – поле ID_HigherSubject в Tbl_SubjectVersion (вышестоящий контрагент для холдинговых структур), и поле ID_SubjectVersion в таблице Tbl_SupplierOffer – ссылка на версию контрагента для коммерческого предложения. Таким образом, мы можем получить версию контрагента на момент занесения записи в Tbl_SupplierOffer. Поле ID_HigherSubject ссылается на таблицу-заголовок, так как нам не нужны версии ссылки для этого поля. Нам нужно получать версию контрагента для коммерческого предложения на тот момент, когда была создана запись, поэтому используется ссылка на версию контрагента. При создании новой версии записи контрагента прежняя версия помечается как удаленная, создается новая версия; при этом все ссылки, которые ссылались на предыдущую версию, остаются неизменными, что позволяет получать состояние записи на момент ввода.
Я не вижу существенных достоинств данного подхода по сравнению с другими. В то же время недостатков у него предостаточно. Объем требуемого дискового пространства не меньше, чем при работе с таблицами-двойниками, а реализация намного сложнее. Ту же самую функциональность легко получить при помощи таблиц-двойников, при сохранении даты изменения. Поскольку с использованием таблиц-двойников мы можем получить состояние записи на любой момент времени, то несложно восстановить состояние записи и всех записей, на которые она ссылается, по состоянию на любой момент времени. Хотя писать запросы при таком подходе проще, поскольку ссылка (если это ссылка на таблицу версий) и так указывает на нужную версию. При использовании таблиц-двойников приходится использовать более сложные запросы .
Я предпочитаю метод с таблицами-двойниками для тех таблиц, где требуется версионность. Если бы я снова проектировал ту структуру БД, то сделал бы все на основе метода таблиц-двойников – та база получилась довольно сложной (около 500 таблиц), и использование таблиц-двойников позволило бы существенно упростить реализацию. При использовании метода таблиц-версий в таблице версий смешиваются исторические и актуальные данные, что ухудшает производительность при выборках – серверу приходится просматривать много лишних записей, особенно при полном сканировании таблицы; ухудшается избирательность индексов, так как значительная часть записей индексов соответствует историческим данным, которые редко используются. Если таблица только с актуальными данными может быть закеширована в памяти, то таблица с актуальными и историческими данными может и не поместиться – и тогда серверу БД придется чаще обращаться к дискам, что сильно снижает скорость.
Этот метод похож на предыдущий – но создается не две таблицы, а одна. Запись при изменении помечается как удаленная, создается новая запись, в ней заполняется поле-ссылка на предыдущую версию записи. На рис. 5 показан пример таблицы для этого метода:

Рис. 5. Метод со ссылками на предыдущую запись.
Требования к дисковому пространству примерно те же, что и для таблиц версий. В этом подходе в таблице версий смешиваются исторические данные и актуальные данные, что ухудшает производительность. По сравнению с подходом, в котором таблицы делятся на две части – таблицы с неизменяемой частью и таблицы версий – здесь сложнее делать выборки по истории, и хуже производительность из-за того, что в таблице много редко используемых данных. Если в методе с отдельными таблицами версий можно делать ссылку на неизменяемую голову записи, то в этом методе такое не получается, что также усложняет систему.
В Oracle поддерживается механизм flashback queries, позволяющий получить состояние записи на любой момент в прошлом, которое еще хранится в логе транзакций БД. Метод требует очень много места, при интенсивной работе с базой обычно можно смотреть данные всего на 10-15 часов назад – для большего не хватает места. Впрочем, если данные редко модифицируются, то такой подход тоже можно использовать.
SQL Server поддерживает c2 audit mode, при этом логируются все действия пользователей. Протокол действий пользователей пишется в файлы, путь к которым указывается в настройках. Из БД простыми средствами к этим файлам не обратишься, да их и непросто анализировать. Думаю, лучше этот метод не применять, если действительно нет необходимости в полном протоколировании всех действий пользователей. Метод основательно ухудшает производительность, пригоден только для протоколирования действий пользователей, но для версионности записей полностью не подходит – предыдущие версии записей, наверное, и в этом подходе можно получить, но это будет очень и очень непросто.