 Оценка 100
Оценка 100 
 Оценить
Оценить 






| Оценка 100 Оценить
|
 |
Итак. "Каждая хозоперация подлежит отражению в одной и той же сумме одновременно по дебету одного счета и кредиту другого". Уберем из этого определения плохо детерминированное понятие "хозоперация" и введем понятие "проводка". Так всем будет понятнее. Получится: "Каждая проводка подлежит отражению в одной и той же сумме одновременно по дебету одного счета и кредиту другого".
Зададимся вопросом – что же означает слово "отражению"? В данном случае это означает, что проводка должна изменять остаток на обоих счетах. Точнее, она должна уменьшать остаток на одном счете и увеличивать на другом. Если мыслить примитивно, то нам понадобится ввести сущность (объект, если кому так больше нравится) "счет" и физически хранить для нее остаток. Но тут возникает вопрос, а на какую дату нужно хранить остаток? Или это должен быть остаток вообще (за весь период жизни предприятия)? Ответ – нет, так как и бухгалтеру и управленцу нужно получать остатки на определенную дату. Более того, им нужны еще и обороты. Правильно? Думаю – да. И тут нужно обратить внимание на брошенное мной по ходу дела слово: получать!
Это слово было сказано неспроста. Дело в том, что хранить остатки и обороты совершенно не нужно. Их и так можно посчитать в любой момент времени. Правильно?
Слышу тихий ропот: "при некоторых объемах эти расчеты просто несерьезно делать каждый раз, пересчитывая все с самого начала. Нужны срезы..." Правильно, но это всего лишь отдельный вопрос производительности. И решать его нужно отдельно от вопроса структуры хранения информации. Индексированные/материализованные view прекрасно решают проблему производительности сервера (да и программиста). Если вы еще не перешли на SQLServer 2000 или Oracle8i (9i), то самое время сделать это. Да и на других серверах можно грамотно создать таблицы, содержащие агрегированную информацию. Главное, что это не повод для нереляционного хранения данных в реляционной СУБД.
Существует мнение, что двойная запись плохо описывается средствами реляционных БД и при попытке реализации приводит к денормализации с ограничением целостности. Такое мнение приводит к созданию систем, состоящих из огромного количества слабо связанных таблиц, например, отдельных таблиц для накладных прихода товара на склад (расхода со склада) и учета кассовых ордеров. Это приводит к существенному усложнению обобщенного анализа данных, хранящихся в таком конгломерате таблиц. В принципе, любые учетные данные полиморфны по своей природе. В них всегда можно выделить общую составляющую, позволяющую обобщенно рассматривать данные с разных точек зрения. К сожалению, при вышеописанном подходе этого очень трудно добиться. Так, в приведенном примере складские накладные и кассовые ордера, скорее всего, будут содержать совершенно разные поля и, скорее всего, не будет учтено, что и кассовый ордер, и накладная, в конечном счете, являются отражением перевода денег или товара.
Такое "потабличное" проектирование очень упрощает жизнь проектировщика. Однако это та простота, которая впоследствии выйдет боком, так как не описывает жизненных процессов предприятия, а занимается простой регистрацией документов. Системы, построенные по такому или подобному принципу можно назвать документно-ориентированными, или системами, строящимися от документа. Обычно такие системы или вообще не содержат бухгалтерии, или содержат ее в виде отдельного блока. Данные из БД попадают в бухгалтерию из таблиц документов, обычно пакетно, за отчетный период. Только после этого бухгалтер начинает работать с информацией, находясь вне связи с реальной жизнью, то есть реальной учетной ситуацией.
Является ли нормализованной таблица, описанная в листинге 2?
Каждая запись в таблице отражает информацию только об одной сущности – проводке. Данная таблица не будет иметь ни одной повторяющейся записи, из таблицы нельзя вынести данные в другие (ссылочные) таблицы. Вроде, все говорит о том, что таблица соответствует самым жестким требованиям нормализации. Значит, на первый вопрос отвечаем положительно.
Можно ли в этой таблице хранить проводки, отвечающие принципам двойной записи?
Каждая проводка содержит информацию о дебетовом и кредитовом счете (в виде ссылки), причем в ней отражены и дебетуемый, и кредитуемый счета.
Проводка содержит дату ее совершения и сумму. Совокупность даты проводки, суммы и направления перемещения денег дает нам возможность записывать таким образом нормальные бухгалтерские проводки, удовлетворяя всем требованиям двойной записи. Просто вместо учета изменения счетов мы начали учитывать изменения этих самых счетов во времени. Никто не запрещает записывать проводку как два отдельных изменения счетов (дебетового и кредитового), но тогда и появляется та самая проблема с "нереляционностью" и "ненормализованностью".
Чтобы не быть голословным, я создал маленькую тестовую базу (см. листинги 1 и 2), состоящую из двух таблиц (я буду пользоваться синтаксисом SQL Server 2000, но он довольно близок к SQL 9x). Первая хранит некие аналитические признаки. Упростим задачу и предположим, что это просто бухгалтерские счета. Вот описание этих таблиц в виде ER-диаграммы:
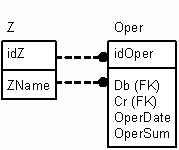
Рисунок 1
SET QUOTED_IDENTIFIER ON SET ANSI_NULLS ON GO CREATE TABLE Z ( idZ INT NOT NULL PRIMARY KEY, ZName VARCHAR(0) NOT NULL ) |
Вторая таблица – это таблица, содержащая проводки.
SET QUOTED_IDENTIFIER ON SET ANSI_NULLS ON GO CREATE TABLE Oper ( idOper INT IDENTITY (0, 1) NOT NULL PRIMARY KEY, Db INT NOT NULL FOREIGN KEY REFERENCES Z, Cr INT NOT NULL FOREIGN KEY REFERENCES Z, OperDate DATETIME NOT NULL, OperSum FLOAT NOT NULL ) |
Как видно из определения второй таблицы, поля Db и Cr являются ссылками на аналитическую таблицу. В принципе, каждая запись аналитической таблицы может содержать неограниченное количество дополнительных аналитических признаков, но суть от этого не изменится. Главное, что мы совершаем перевод денег с одной единицы аналитики на другую (равнозначную по глубине/уровню). Посчитать остатки/обороты для такого вида таблиц довольно просто. Для начала заполним наши таблицы данными:
INSERT INTO Z(idZ, ZName) VALUES(1, 'OC') INSERT INTO Z(idZ, ZName) VALUES(2, 'Амортизация ОС') INSERT INTO Z(idZ, ZName) VALUES(10, 'Склад материалов') INSERT INTO Z(idZ, ZName) VALUES(41, 'Товары') INSERT INTO Z(idZ, ZName) VALUES(46, 'Реализация') INSERT INTO Z(idZ, ZName) VALUES(50, 'Касса') INSERT INTO Z(idZ, ZName) VALUES(51, 'Расчетный счет') INSERT INTO Z(idZ, ZName) VALUES(60, 'Поставщики') INSERT INTO Z(idZ, ZName) VALUES(71, 'Авансовые отчеты') INSERT INTO Z(idZ, ZName) VALUES(75, 'Учт.кап.') SET DATEFORMAT DMY INSERT INTO Oper(Db, Cr, OperDate, OperSum) VALUES(51, 75, '01.01.2002', 1000) INSERT INTO Oper(Db, Cr, OperDate, OperSum) VALUES(50, 51, '02.01.2002', 300) INSERT INTO Oper(Db, Cr, OperDate, OperSum) VALUES(71, 50, '03.01.2002', 100) INSERT INTO Oper(Db, Cr, OperDate, OperSum) VALUES(10, 71, '04.01.2002', 55) INSERT INTO Oper(Db, Cr, OperDate, OperSum) VALUES(50, 71, '04.01.2002', 40) INSERT INTO Oper(Db, Cr, OperDate, OperSum) VALUES(60, 50, '05.01.2002', 200) INSERT INTO Oper(Db, Cr, OperDate, OperSum) VALUES(41, 60, '06.01.2002', 180) INSERT INTO Oper(Db, Cr, OperDate, OperSum) VALUES(51, 60, '06.01.2002', 20) INSERT INTO Oper(Db, Cr, OperDate, OperSum) VALUES(50, 71, '07.01.2002', 5) |
Теперь можно создать упрощенный вариант расчета оборотной ведомости. Для простоты выбросим расчет остатка на промежуточную дату и обороты (их нетрудно добавить, но это усложнит понимание основного принципа).
Итак, рассчитать оборотку для некоторого уровня аналитики можно в два приема. Сначала нужно выделить уровень аналитики, для которого необходимо произвести расчет, а потом произвести агрегацию, соединив таблицу проводок и аналитики. В нашем, простейшем, случае есть только один уровень аналитики, а значит, дополнительный запрос на выборку и агрегацию аналитики не требуется. То есть мы можем рассчитывать обороты и остатки на основании данных из таблицы проводок.
Общий алгоритм совсем прост – нужно выбрать необходимые записи (за некоторый период) из таблицы проводок и посчитать их сумму для дебета и кредита каждого из счетов. К сожалению, записать это одним запросом (без подзапросов) невозможно (если кто извернется, то покажите, как). Я знаю два обхода данной проблемы. Первый известный мне способ – мы можем создать основной запрос, который будет возвращать список аналитических признаков, а обороты и остатки подсчитывать в простых подзапросах. Второй – можно произвести агрегацию отдельно для дебетовых и кредитовых признаков и соединить полученные запросы с помощью FULL OUTER JOIN. Я продемонстрирую второй подход:
SELECT ISNULL(DbS.Db, CrS.Cr) AS Z, ISNULL(CrS.CrSum, 0) AS Db, ISNULL(DbS.DbSum, 0) AS Cr FROM (SELECT Cr, SUM(OperSum) AS CrSum FROM Oper GROUP BY Cr) AS CrS FULL OUTER JOIN (SELECT Db, SUM(OperSum) AS DbSum FROM Oper GROUP BY Db) AS DbS ON CrS.Cr = DbS.Db |
Данный запрос содержит два подзапроса (выделенных жирным), которые рассчитывают обороты по дебету и кредиту аналитических признаков.
Если нужно вычислять оборот и остаток за определенный период, нужно добавить в подзапросы фильтрацию необходимого периода. Приведенный выше запрос должен будет сам стать подзапросом. Дело в том, что для полноценной обработки нужно рассчитать остаток на начало периода и оборот за период. Техника тут будет примерно такая же, так что вряд ли ее стоит касаться. Тот же FULL OUTER JOIN по аналитическим признакам... Остаток на конец рассчитывается путем сложения остатка на начало периода и оборота за период.
Если нужно добавить название аналитического признака, то можно сделать еще одну вложенность и JOIN со справочной таблицей. Вот вариант для нашего примера:
SELECT sb.Db, Z.ZName, sb.Cr, sb.Z FROM Z INNER JOIN (SELECT ISNULL(DbS.Db, CrS.Cr) AS Z, ISNULL(CrS.CrSum, 0) AS Db, ISNULL(DbS.DbSum, 0) AS Cr FROM (SELECT Cr, SUM(OperSum) AS CrSum FROM Oper GROUP BY Cr) AS CrS FULL OUTER JOIN (SELECT Db, SUM(OperSum) AS DbSum FROM Oper GROUP BY Db) AS DbS ON CrS.Cr = DbS.Db ) AS sb ON Z.idZ = sb.Z |
В данном случае большая вложенность запросов не будет приводить к понижению производительности, так как только самые глубокие запросы занимаются действительно серьезной обработкой данных. Остальные уже работают с относительно небольшим количеством агрегированных данных.
Стоит также обратить внимание на то, что при соединении результата с записями из таблицы аналитики применяется INNER JOIN. INNER JOIN более эффективен, к тому же, если применить OUTER JOIN, в запрос попадут "лишние записи" (аналитики, для которой не было оборотов).
Однако может появиться (и появляется) вопрос:
Все это конечно очень здорово. Но вот простой пример. Я хочу получить баланс, причем не просто по счетам, но и с группировкой по аналитикам. Что-то вроде:
Товары на складе 1000
Продукты питания 200
Вобла 50
Пиво "Lowenbrau" 150
Одежда 400
Джинсы 250
Майки 150
Обувь 400
Кроссовки 200
Ласты на каблуках 200
|
Здесь "Товары на складе" - это счет, "Продукты питания", "Одежда", "Обувь" - аналитики типа "Вид товара", а все остальное - аналитики типа "Товар". Если данные хранятся в виде:
tblEntries ---------- entry_id entry_volume account_id analytic_0_id analytic_1_id ... analytic_N_id |
то написав
SELECT SUM( entry_volume ) ... GROUP BY account_id, analytic_0_id analytic_1_id ... analytic_N_id |
мы тут же получим нужный нам результат. А как быть в случае с более универсальным хранением аналитических атрибутов?
Первое что хочется здесь заметить – это то, что пример не очень удачен. Дело в том, что в данном примере определяются не атрибуты проводки, а атрибуты номенклатуры. Количественный учет – в некотором смысле учет в другом измерении. Не в денежном, а в количественном. Точнее в количественно-денежном.
Здесь есть смысл остановиться и поподробнее разобрать общую структуру проводки. Посмотрите на следующий рисунок:
| Дебет | Кредит | Дата | Сумма |
Если оперировать не бухгалтерскими терминами, а общечеловеческими (или даже, можно сказать, объектно-ориентированными), можно сказать, что Дебет – это «место», куда пришли деньги, Кредит – откуда эти деньги ушли, Дата – момент времени, когда эти деньги перешли из одной «точки» в другую, а сумма – и есть перемещенная сумма. Но ведь деньги – это всего лишь абстрактная единица измерения (всеобщий эквивалент). По сути, это универсальная единица измерения для любых предметов и дел. По сути, сумма, с точки зрения проводки, есть не что иное, как универсальное измерение некоторого ресурса, который подвергается перемещению с одного «места» на другое. Например, перемещению могут подлежать кроссовки в количестве 10 пар, но в бухгалтерской проводке будет записана только их суммарная стоимость в определенной валюте (единице измерения), т.е. вместо 10 пар кроссовок будет записано 15 000 рублей. С алгоритмической точки зрения это – всего лишь запись в более полиморфном виде, т.е. в денежном эквиваленте, который можно обрабатывать более полиморфно (например, можно сложить обороты по продажам всех товаров). Взгляд на сумму в проводке как на количественное описание некого ресурса позволяет довести эту абстракцию до логической завершенности. Итак, и сумма проводки, и количество товара являются всего лишь измерением перемещаемого ресурса. Эта концепция прекрасно ложится на любую сферу деятельности предприятия. Например, в качестве ресурса может выступать время, затраченное работником на выполнение некоторой работы, имеющей определенную стоимость (за единицу времени), то есть появляется возможность считать сдельную зарплату универсальными учетными средствами. Путем нехитрых размышлений можно прийти к мысли, что ресурс может измеряться в разных единицах и иметь собственные атрибуты (как z-объекты). Вот новое представление проводки:
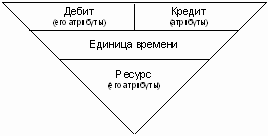
Рисунок 2
Стало быть, говоря о количественно-суммовом учете (товаре и группе, к которой он относится), мы получаем не атрибуты дебетового или кредитового z-объекта, а атрибуты единицы ресурса (тип и группу). При этом количество товара есть ни что иное, как другое измерение (отличное от денежного). Заметьте, тип товара – это аналитика именно единицы измерения! И не следует причислять ее к дебету или кредиту. Более того, я бы даже посоветовал не хранить ее в проводке. В проводке нужно хранить только сумму в деньгах (полиморфное представление). Количественный учет лучше вынести в отдельную таблицу, содержащую ссылку на проводку (связь "одна проводка ко многим детализирующим записям"). При этом можно будет добавлять несколько количественно-суммовых записей для одной проводки, а проводка будет содержать общую сумму по всем этим записям. Таким образом, проводка будет похожа на простую накладную, что очень хорошо отражает реальную жизнь. Чтобы пояснить мысль, создадим простую реализацию вышесказанного. Назовем таблицу, в которой будут лежать детали проводки, OperDet (детали операции). Номенклатура в этом случае учитывается как ссылка (поле в таблице количественно-суммового учета) на таблицу(ы) справочника номенклатуры. Вот ее описание и описание сопутствующих таблиц:
SET QUOTED_IDENTIFIER ON SET ANSI_NULLS ON GO CREATE TABLE "Product" ( "idProd" INT IDENTITY NOT NULL PRIMARY KEY, "ProdName" VARCHAR(100) NOT NULL, "ProdGroup" VARCHAR(20) NOT NULL) GO CREATE TABLE "OperDet" ( "idOper" INT NOT NULL, "idProd" INT NOT NULL, "DetCount" FLOAT NOT NULL, "DetPrice" FLOAT NOT NULL) GO ALTER TABLE "OperDet" ADD CONSTRAINT "OperDet_PK" PRIMARY KEY ("idOper", "idProd") ALTER TABLE "OperDet" ADD CONSTRAINT "Oper_OperDet_FK1" FOREIGN KEY("idOper") REFERENCES "Oper" ("idOper") |
А вот ER-диаграмма:
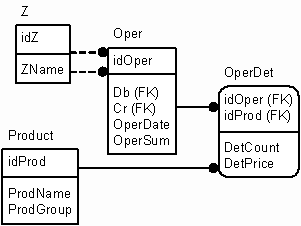
Рисунок 3
При этом, правда, появляется необходимость синхронизировать сумму операции (проводки) с суммой по соответствующим деталям операции. Это можно сделать в триггерах или в middleware.
Как ни странно, замечательное структурирование, продемонстрированное в примере выше, не порождает множества аналитических признаков. По сути, признак один – номенклатура. А нарисованное деревце – всего лишь структурирование самих признаков, и является простым (одиночным) атрибутом номенклатуры, ссылающимся на отдельный справочник групп. Можно хранить такой справочник как дерево (в виде специальной реляционной структуры) и перед агрегацией выбирать необходимые листья этого дерева (которые и являются номенклатурой), а затем делать соединение с таблицей деталей проводки и таблицей проводок, получая тем самым структуру, аналогичную приведенной выше. Агрегации по иерархии групп можно добиться, «разворачивая» ее в виде простой плоской (виртуальной) таблицы, содержащей по одной колонке для каждого уровня вложенности. Например, дерево:
Название ветки # ветки в БД
Товары на складе 1
Продукты питания 2
Вобла 3
Пиво "Lowenbrau" 4
Одежда 5
Джинсы 6
Майки 7
Обувь 8
Кроссовки 9
Ласты на каблуках 10
|
можно развернуть в следующую временную таблицу:
| 1 | NULL | NULL |
| 1 | 2 | NULL |
| 1 | 2 | 3 |
| 1 | 2 | 4 |
| 1 | 5 | NULL |
| 1 | 5 | 6 |
| 1 | 5 | 7 |
| 1 | 8 | 9 |
| 1 | 8 | 10 |
Для агрегации из этой таблицы нужно выделить все значения последней колонки не содержащие NULL. При формировании окончательного отчета нужно объединить (с помощь OUTER JOIN) результат агрегации с этой таблицей (по последнему полю) и подсчитать промежуточные результаты. Этот способ не требует изменения структуры БД для изменения уровней иерархии. Более того, можно создавать виртуальные иерархии (только на время построения запроса).
Но вопрос может быть связан не обязательно с количественно-суммовым учетом. Ресурс, и тем более, z-объект (ведь атрибуты применимы и к ним) может иметь различные структуру и количество атрибутов (аналитических признаков). Как быть в этой ситуации? Я вижу два выхода – создать универсальную структуру для хранения неограниченного количества аналитических признаков, или создавать (лучше всего динамически) отдельные таблицы для хранения аналитической информации для отдельных типов z-объектов. Честно говоря, до сих пор я не могу отдать предпочтение одному из вариантов. Динамические таблицы сложнее в реализации, зато дают возможность хранить атрибуты не только ссылочного типа, но и обычные атрибуты (текстовые, числовые, булевы, даты). С другой стороны, несколько усложняются полиморфные запросы, возвращающие информацию сразу по нескольким типам z-объектов или разным типам ресурсов. В любом случае, наиболее часто используемые атрибуты есть смысл хранить или непосредственно в таблице, хранящей z-объекты/ресурсы, или в таблице, описывающей их типы (например, непосредственно в z-объекте можно хранить бухгалтерский счет или тип z-объекта, а в описании типа – уже номер бухгалтерского счета). При этом для z-объекта/ресурса будет иметься полиморфная запись в универсальной таблице, хранящей z-объекты (детали операции для ресурсов), и в специализированной таблице для конкретного типа z-объектов/ресурса. Связь между этими таблицами должна быть один к одному. Собственно, это очень похоже на то, что предлагает документно-ориентированный подход (хранение информации о дебете и кредите каждого счета в отдельной таблице) только в этом случае имеется связующая таблица, хранящая информацию о проводке. По сути – это то же самое, но приведенное в нормальную (нормализованную и непротиворечивую) реляционную форму.
Второй вариант тоже подразумевает наличие полиморфной таблицы z-объектов/ресурсов, но вместо динамического создания таблиц для каждого их типа использует одну универсальную таблицу. Схема, позволяющая задавать неограниченное количество атрибутов для любого z-объекта (на рисунке связующая таблица имеет название Z2Ref), показана на рисунке 4.
Ref – это упрощенная справочная таблица. В реальной жизни ее место должны занять таблицы, реализующие универсальную (необходимой сложности) модель справочников (куда можно динамически добавлять справочники и/или уровни иерархии). По сути, между таблицей Ref и Z появляется связь "многие ко многим", т.е. с любым z-объектом можно ассоциировать любой элемент справочника и наоборот. Это позволяет добиться максимальной гибкости и при этом не создавать лишние таблицы (как в предыдущем случае).
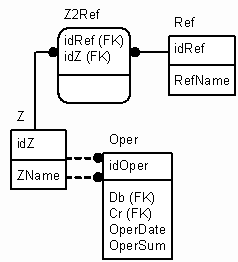
Рисунок 4
Теперь, усложнив и запутав все что можно, я попробую показать, как в этом случае можно получать агрегированные результаты в разрезе некоторого набора элементов универсального справочника.
Для начала нам нужно заполнить таблицы Ref и Z2Ref начальными значениями. Так как до реальной жизни этому всему далеко, я заполнил эти таблицы тем, что пришло к голову:
SET QUOTED_IDENTIFIER ON SET ANSI_NULLS ON GO CREATE TABLE "Ref" ( "idRef" INT IDENTITY NOT NULL PRIMARY KEY, "RefName" VARCHAR(100) NOT NULL ) CREATE TABLE "Z2Ref" ( "idRef" INT NOT NULL, "idZ" INT NOT NULL ) ALTER TABLE "Z2Ref" ADD CONSTRAINT "Z2Ref_PK" PRIMARY KEY clustered ("idZ", "idRef") INSERT INTO Ref(RefName) VALUES('Васек') INSERT INTO Ref(RefName) VALUES('Склад 1') INSERT INTO Ref(RefName) VALUES('Петек') INSERT INTO Ref(RefName) VALUES('Склад 2') INSERT INTO Ref(RefName) VALUES('Касса 1') INSERT INTO Ref(RefName) VALUES('Касса 1') INSERT INTO Ref(RefName) VALUES('Нюрка') INSERT INTO Z2Ref(idRef, idZ) VALUES(3, 10) INSERT INTO Z2Ref(idRef, idZ) VALUES(3, 41) INSERT INTO Z2Ref(idRef, idZ) VALUES(1, 50) INSERT INTO Z2Ref(idRef, idZ) VALUES(3, 60) INSERT INTO Z2Ref(idRef, idZ) VALUES(7, 60) INSERT INTO Z2Ref(idRef, idZ) VALUES(1, 71) INSERT INTO Z2Ref(idRef, idZ) VALUES(3, 71) INSERT INTO Z2Ref(idRef, idZ) VALUES(1, 75) |
Предположим теперь, что нам нужно получить обороты для Васька и Петька, т.е. для записей 1 и 3 из таблицы Ref (в реальной жизни стоило бы добавить тип z-объекта, так как не стоит смешивать неоднородные данные, но здесь этого не делается – за неимением такового в упрощенной схеме). Чтобы создать такой запрос, достаточно несколько модернизировать предыдущие запросы:
SELECT Agr.Z, Ref.RefName AS Name, Agr.Db, Agr.Cr FROM (SELECT ISNULL(DbS.idRef, CrS.idRef) AS Z, ISNULL(CrS.CrSum, 0) AS Db, ISNULL(DbS.DbSum, 0) AS Cr FROM (SELECT Z2Ref.idRef, SUM(Oper.OperSum) AS DbSum FROM Oper INNER JOIN Z ON Oper.Db = Z.idZ INNER JOIN Z2Ref ON Z.idZ = Z2Ref.idZ WHERE (Z2Ref.idRef IN (1, 3)) GROUP BY Z2Ref.idRef ) DbS FULL OUTER JOIN (SELECT Z2Ref.idRef, SUM(Oper.OperSum) AS CrSum FROM Oper INNER JOIN Z ON Oper.Cr = Z.idZ INNER JOIN Z2Ref ON Z.idZ = Z2Ref.idZ WHERE (Z2Ref.idRef IN (1, 3)) GROUP BY Z2Ref.idRef ) CrS ON DbS.idRef = CrS.idRef ) Agr INNER JOIN Ref ON Agr.Z = Ref.idRef |
Их основу, как и раньше, составляют два агрегирующих подзапроса, вычисляющие обороты по дебету и кредиту выбранных аналитических признаков. Задание признаков в этом примере сделано через оператор in(), в реальных запросах может быть и результатом подзапроса.
Конечно, в реальной жизни к этому и так не маленькому запросу прибавится еще немало дополнительных прибамбасов. В результате запросы могут стать плохо читаемыми. Поэтому для их создания следует применять шаблоны или даже некий псевдоязык, который будет скрывать сложность реальных запросов. Можно также попросту разбить запрос на несколько отдельных запросов, а связывание этих запросов производить средствами TSQL (для MS SQL Server) или PLSQL (для Oracle), а то и в middleware. Главное учитывать, что дебетовый подзапрос есть "зеркальное" отражение кредитового, а первый уровень всего лишь добавляет текстовые описания к аналитическим признакам.
Перед разработчиком, пытающимся использовать полиморфные (универсальные) структуры и алгоритмы, рано или поздно встанет вопрос производительности. В конце концов, все данные предприятия попадают в очень небольшой набор таблиц, две из которых (таблица проводок/операций и детали операции) будут содержать записи по всем операциям на предприятии. Это предъявляет особые требования к оптимизации скоростных характеристик системы. Конечно, такие требования стоят и перед разработчиками «плоских» систем, где каждый отдел учета хранится в отдельной таблице, но там, в виду распределения информации между таблицами этот вопрос стоит менее остро.
Современные компьютеры легко справляются с модификацией и оперативным представлением данных (в разрезе отдельных z-объектов, договоров, партий товара, авансовых отчетов и т.п.), при условии правильного построения индексов. Для хорошо нормализованных баз это обычно означает всего лишь наличие индексов на первичных и внешних ключах таблиц. Другое дело – агрегация информации! В большой организации объем данных, вводимых за пару лет, может заставить задуматься даже суперкомпьютер, а в нашей стране народ обычно ориентируется на значительно более прозаическую технику.
Выход можно найти, например, в создании промежуточных агрегированных результатов. По сути, агрегированные отчеты в современных OLTP-системах являются ничем иным, как OLAP-запросами. OLTP-данные плохо подходят для такой работы. Промежуточное агрегирование как раз и позволяет преобразовать данные к более пригодной для анализа форме и/или как минимум значительно сократить объем рассчетов.
Агрегированные результаты можно хранить в отдельных (специально для этого созданных) таблицах, рассчитывая результаты в триггерах или middleware-слое, или, как уже говорилось выше, используя материализованные (в терминологии Oracle8/9i) или индексированные (в терминологии MS SQL Server 2000) представления. К сожалению, на использование материализованных (индексированных) представлений накладываются довольно суровые ограничения, и с их помощью не всегда можно преобразовать данные в необходимый (в конечном итоге) вид, но они позволяют с минимальными трудозатратами получить автоматически обновляемые агрегированные результаты. Для получения необходимых результатов можно также создавать обычные представления, хранимые процедуры (используя такие возможности TSQL и PLSQL, как временные таблицы и курсоры), или реализовать (инкапсулировать) необходимую логику в middleware-слое.
В принципе, осуществляя ручное агрегирование, можно добиться больших результатов, так как можно будет более разумно использовать особенности структуры БД, создавать многоуровневые иерархии агрегатных таблиц и применять более сложную логику, но сложность такой реализации намного выше. Если условия позволяют, лучше использовать материализованные представления (вкупе с обычными представлениями и хранимыми процедурами), и только если появится серьезные основания, переходить на «ручной» режим.
Чтобы продемонстрировать использование индексированных представлений в SQL Server 2000, я создал небольшой пример, рассчитывающий оборотную ведомость за определенный период. Оборотная ведомость интересна тем, что обычно обрабатывает все проводки, находящиеся в системе. Это происходит из-за того, что в ней рассчитывается оборот за нужный период и остаток на начало этого периода, ввиду чего в общем случае захватываются все данные с начала работы фирмы по конечный период. В результате объем подлежащих агрегации данных становится неприемлемо велик для обработки в реальном времени. Заметить серьезное замедление, однако, можно только при действительно большом объеме данных.
Для эксперимента я написал скрипт, который заполняет приведенную выше таблицу Oper некоторым количеством записей, указываемым в строке «WHILE @counter < 10000000». Как видите, в данном случае в таблицу было помещено 10 миллионов записей. Это большое число по любым меркам. Даже большой фирме придется немало потрудиться, чтобы создать такое количество записей. Записи распределялись по 100 на каждый день равномерно между всеми аналитическими объектами. Количество объектов было невелико, что схоже с бухгалтерскими счетами в учетной системе. Не стоит искать какой-либо осмысленности в этих данных, это просто набор данных для измерения производительности. Важны только объемы. Вот этот скрипт:
SET QUOTED_IDENTIFIER ON SET ANSI_NULLS ON GO SET NOCOUNT ON DECLARE @counter INT, @zoDb INT, @zoCr INT, @dt DATETIME, @summ FLOAT SET DATEFORMAT DMY Set @dt = '01-01-1998' Set @zoDb = 1 Set @summ = 1 Set @zoCr = 51 Set @counter = 1 WHILE @counter < 10000000 BEGIN INSERT INTO Oper(Db, Cr, OperDate, OperSum) VALUES(@zoDb, @zoCr, @dt, @summ) IF((@counter % 10) = 0) SET @dt = DATEADD(Day, 1, @dt) SET @zoDb = CASE WHEN @zoDb = 1 THEN 2 WHEN @zoDb = 2 THEN 10 WHEN @zoDb = 10 THEN 41 WHEN @zoDb = 41 THEN 46 WHEN @zoDb = 46 THEN 50 WHEN @zoDb = 50 THEN 51 WHEN @zoDb = 51 THEN 60 WHEN @zoDb = 60 THEN 71 WHEN @zoDb = 71 THEN 1 END SET @zoCr = CASE WHEN @zoCr = 1 THEN 2 WHEN @zoCr = 2 THEN 10 WHEN @zoCr = 10 THEN 41 WHEN @zoCr = 41 THEN 46 WHEN @zoCr = 46 THEN 50 WHEN @zoCr = 50 THEN 51 WHEN @zoCr = 51 THEN 60 WHEN @zoCr = 60 THEN 71 WHEN @zoCr = 71 THEN 1 END SET @summ = @summ + 12.123 IF @summ > 1000 SET @summ = 1 SET @counter = @counter + 1 IF (@counter % 1000) = 0 PRINT @counter END SET NOCOUNT OFF |
Средствами SQL Server 2000 можно создать один запрос, или одно обычное view, которое будет получать оборотную ведомость за один раз. Однако такой запрос или view будут содержать подзапросы, внешние соединения (outer join) и другие препятствующие созданию индексированного представления элементы. К тому же, такой запрос будет громоздким и непонятным. Скажу честно, половина программистов просто не сможет написать такого сложного запроса. Исходя из этих соображений, запрос был разбит на простые составляющие. Подзапросы, обрабатывающие самые большие объемы данных, разбиты на части, и наиболее тяжелые расчеты переписаны для использования индексированных представлений вместо базовых таблиц.
Сложность запроса обусловлена двумя обстоятельствами. Во-первых, как уже говорилось, приходится считать отдельно обороты для дебета и кредита аналитических объектов (z-объектов). Во-вторых, нам нужно вычислить остаток на начало, оборот за период и остаток на конец периода. С оборотами по дебету и кредиту ничего не поделаешь, поэтому пришлось создать два индексированных представления – по одному для дебетовой и кредитовой агрегации. С остатками все проще, так как остаток на конец можно получить сложением остатка на начало периода и оборота за период. Остаток на начало периода – это, по большому счету, тот же оборот, но за период от начала деятельности предприятия до начала расчетного периода. Поэтому можно создать универсальный запрос (view или функцию, возвращающую набор данных), который будет рассчитывать и то, и другое. Удобнее всего оформить такой запрос в виде функции с двумя параметрами – датой начала и датой окончания периода. При этом для расчета остатка можно задать в качестве начала дату создания организации, или, что намного проще, дату сотворения мира. К сожалению, последнее по техническим причинам невыполнимо (у SQL Server 2000 есть ограничения на минимальное значение даты), поэтому придется датой 01.01.1000. Поэтому, если вы решите использовать этот алгоритм в реальной системе, проверьте, не была ли ваша организация создана раньше, и не заведены ли в систему данные за тот период.
Еще одна сложность заключается в том, что нам нужно индексированное представление, которое позволит получать обороты за любой период. Для этого индексированное представление должно содержать агрегаты каждого аналитического признака в разрезе определенного промежутка времени. Если принять за такой промежуток времени день, за неделю для каждого аналитического признака должно получиться от нуля (при отсутствии оборотов) до семи записей в индексированном представлении. Для 10 аналитических признаков это составит менее 70 записей в неделю, независимо от количества проводок, или около двадцати пяти тысяч записей в год. Для большинства организаций это достаточный уровень агрегации. Даже за десять лет наберется несколько сотен тысяч записей, работа с которыми не составляет проблемы для современной техники. Но если количество аналитических признаков увеличится, такой уровень агрегации окажется недостаточным.
Так, в созданной мной базе содержится 10 миллионов записей, охватывающих большой период времени. Если произвести агрегацию по дням, то, учитывая количество аналитических признаков, количество записей в индексированных представлениях будет всего в 10 раз меньше, чем в таблице проводок (Oper). Этого явно недостаточно. Поэтому нужно провести агрегацию по большим промежуткам времени, например, по месяцам. Индексированное представление, выполняющее такую агрегацию, может выглядеть так:
SET QUOTED_IDENTIFIER ON SET ANSI_NULLS ON GO -- Создаем view (которое впоследствии станет индексированным) -- Это view вычисляет агрегаты для аналитических признаков -- в разрезе года и месяца. CREATE VIEW dbo.CrS WITH SCHEMABINDING AS SELECT Cr, YEAR(OperDate) AS CrYear, MONTH(OperDate) AS CrMonth, COUNT_BIG (*) AS Cnt, SUM(OperSum) AS CrSum FROM dbo.Oper GROUP BY Cr, YEAR(OperDate), MONTH(OperDate) -- Создаем кластерный индекс для view, превращая тем самым его -- в индексированное view. CREATE UNIQUE CLUSTERED INDEX IX_CrS ON dbo.CrS (Cr, CrYear, CrMonth) WITH DROP_EXISTING ON [PRIMARY] -- Создаем дополнительный индекс для индексированного представления. -- Это позволит ускорить выборку данных. CREATE INDEX IX_CrS_Year ON dbo.CrS (CrYear) WITH DROP_EXISTING ON [PRIMARY] |
Индексированное представление CrS хранит агрегаты для каждого аналитического признака в разрезе год-месяц, причем только для кредитовых оборотов. Для расчета дебетовых оборотов нужно создать точно такое же представление, но вместо Cr надо подставить Db. В результате получится индексированное представление DbS, производящее агрегацию оборотов по дебету. Для экономии места я не буду приводить его здесь.
Теперь, чтобы получить оборот за год или месяц, достаточно примитивного запроса, суммирующего данные за указанный период. В бухгалтерии обороты вычисляются за квартал или месяц, поэтому даже в таком виде этот запрос уже можно использовать. Но было бы удобнее все-таки иметь возможность получения оборотов за любой промежуток времени в днях. Любой не кратный месяцу период можно представить как период, кратный месяцу, и два «хвостика» размером в несколько дней. Объем этих «хвостиков» невелик. Поэтому их обороты можно получить прямым вычислением по базовым таблицам. При этом время на такой расчет очень мало, так как объем обрабатываемых данных незначителен. Эти расчеты удобно вынести в отдельные функции, возвращающие наборы данных. Это нововведение SQL Server 2000 позволяет существенно сократить количество кода в SQL-запросах и упростить его понимание. Такую функцию можно использовать в операторе FROM вместо таблицы, или view. Я создал шесть функций, по три для расчета оборотов по дебету и кредиту. Функции CrObAfter и CrObBefore рассчитывают те самые «хвостики», а CrObMiddle – основную часть периода (используя для расчета индексированное представление). Как и в прошлый раз, варианты функций для дебета я не привожу – по тем же причинам, что и для индексированного представления.
-- Эти функции упрощают работу с индексированным представлением -- внося дополнительную абстракцию. CREATE FUNCTION CrObAfter(@DateEnd AS DATETIME) RETURNS TABLE AS RETURN ( SELECT Cr, SUM(OperSum) AS CrSum FROM Oper WITH(INDEX(DateIndex)) where OperDate >= DATEADD(d, 1-DAY(@DateEnd), @DateEnd) and OperDate <= @DateEnd group by Cr ) CREATE FUNCTION CrObBefore(@DateBegin AS DATETIME) RETURNS TABLE AS RETURN ( SELECT Cr, SUM(OperSum) AS CrSum FROM Oper WITH(INDEX(DateIndex)) where OperDate < DATEADD(m, 1, DATEADD(d, 1-DAY(@DateBegin), @DateBegin)) and OperDate >= @DateBegin group by Cr ) CREATE FUNCTION CrObMiddle(@DateBegin AS DATETIME, @DateEnd AS DATETIME) RETURNS TABLE AS RETURN ( SELECT Cr, SUM(CrSum) AS CrSum FROM CrS WITH(NOEXPAND/*, INDEX(IX_CrS_Year)*/) where (CrYear = YEAR(@DateBegin) and CrMonth >= MONTH(@DateBegin)) or (CrYear > YEAR(@DateBegin) and CrYear < YEAR(@DateEnd)) or (CrYear = YEAR(@DateEnd) and CrMonth <= MONTH(@DateEnd)) GROUP BY Cr ) |
Все эти функции получают параметры типа DATETIME. Для вычленения нужных периодов используется функция DATEADD, а также функции MONTH, YEAR и DAY.
К сожалению, оптимизатор запросов SQL Server 2000 не только не в состоянии самостоятельно переписать сложный запрос для использования в нем индексированного представления, но и не в силах справиться с теми простыми запросами, которые я вынес в эти функции. Если вы внимательно посмотрите на код этих функций, то заметите хинт для индексированного представления WITH(NOEXPAND), заставляющий SQL Server в обязательном порядке использовать индексированное представление, не обращаясь к базовым таблицам. Если не указать этот хинт, SQL Server начинает тупо перемалывать 10 миллионов записей, игнорируя индексированное представление. Скорее всего, такое поведение объясняется тем, что SQL Server не в состоянии создать статистику для индексированного представления. Однако он ошибся и при составлении плана обыкновенных запросов к базовым таблицам, содержащихся в функциях CrObAfter и CrObBefore. Он решил, что сканирование 10 миллионов записей – это быстрее, чем lookup 300 записей по дополнительному индексу (колонки OperDate). Тем не менее, он угадал, что сканирование дополнительного индекса индексированного представления не даст повышения производительности. В качестве эксперимента можете раскомментировать «INDEX(IX_CrS_Year)» в функции CrObMiddle и убедиться, что скорость выполнения запроса упала. По всей видимости, проблема с индексом в том, что размер первичного ключа индексированного представления довольно велик.
Остальные функции просто завершают работу, собирая результаты разных запросов в один общий результат. Функция CrOb объединяет «хвостики» и основную часть запроса, принимая начало и конец периода и вычисляя оборот за этот произвольный период:
CREATE FUNCTION CrOb(@DateBegin AS DATETIME, @DateEnd AS DATETIME) RETURNS TABLE AS RETURN ( SELECT ISNULL(b.Cr, ISNULL(a.Cr, m.Cr)) AS Cr, ISNULL(b.CrSum, 0) + ISNULL(a.CrSum, 0) + ISNULL(m.CrSum, 0) AS CrSum FROM CrObBefore(@DateBegin) AS b FULL OUTER JOIN CrObAfter(@DateEnd) AS a ON b.Cr = a.Cr FULL OUTER JOIN CrObMiddle(@DateBegin, @DateEnd) AS m ON a.Cr = m.Cr ) |
Функция Ob объединяет результат работы функций CrOb и DbOb, выводя их в формате, привычном бухгалтеру:
CREATE FUNCTION Ob(@DateBegin AS DATETIME, @DateEnd AS DATETIME) RETURNS TABLE AS RETURN ( SELECT ISNULL(CrOb.Cr, DbOb.Db) AS Z, DbOb.DbSum, CrOb.CrSum FROM CrOb(@DateBegin, @DateEnd) CrOb FULL OUTER JOIN DbOb(@DateBegin, @DateEnd) DbOb ON CrOb.Cr = DbOb.Db ) |
И, наконец, функция Oborotka вызывает повторно функцию Ob для расчета сначала остатка (оборота с 01.01.1000 по DateBegin), а потом для расчета оборота за период. Остаток на конец, как и говорилось раньше, рассчитывается из остатка на начало и оборота за период.
CREATE FUNCTION Oborotka(@DateBegin AS DATETIME, @DateEnd AS DATETIME) RETURNS TABLE AS RETURN ( SELECT ISNULL(Ost.Z, Ob.Z) AS Z, Ost.DbSum AS DbOstBg, Ost.CrSum AS CrOstBg, Ob.DbSum AS DbOb, Ob.CrSum AS CrOb, Ost.DbSum + Ob.DbSum AS DbOstEnd, Ost.CrSum + Ob.CrSum AS CrOstEnd FROM Ob('01-01-1000', @DateBegin) Ost FULL OUTER JOIN Ob(@DateBegin, @DateEnd) Ob ON Ost.Z = Ob.Z ) |
В конечном итоге, для получения оборотной ведомости достаточно выполнить следующий SQL-запрос:
SELECT * FROM Oborotka('01.06.1998', '01.02.2222') |
Его выполнение на подопытной базе, содержащей 10 миллионов записей, занимает одну-две секунды (на AMD 1400). Результат выполнения этой функции приведен на рисунке 5. Обратите внимание на время выполнения запроса (обведенное черным овалом). Если выполнить запрос напрямую, время его выполнения составит примерно шесть минут.
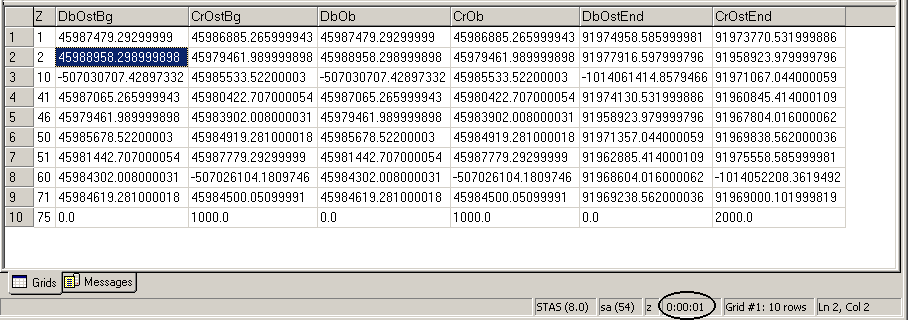
Рисунок 5. Оборотная ведомость, рассчитанная функцией Oborotka.
Итак, использование индексированных представлений может позволить существенно поднять скорость выполнения часто требуемых отчетов и сэкономить немалые деньги, а грамотная инкапсуляция – избежать повышения уровня сложности.
Создавать представление и управлять их индексами удобнее всего из MS SQL Server Enterprise Manager. На рисунке 6 показан момент настройки индексов для индексированного представления.
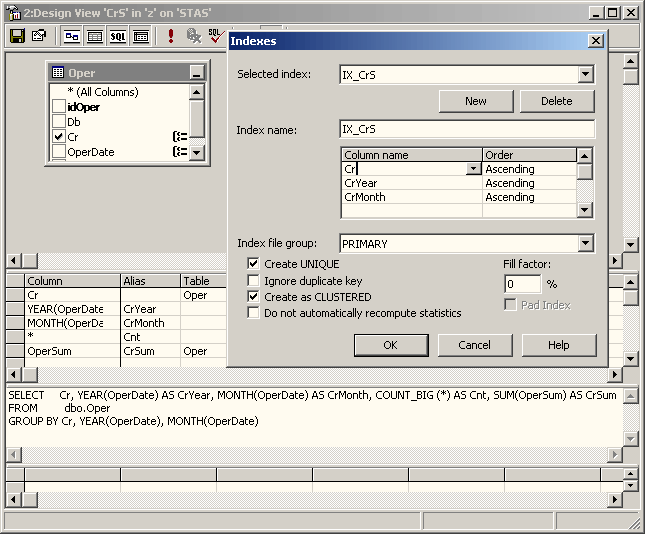
Рисунок 6. Дизайнер представлений в MS SQL Server Enterprise Manager.
Вообще, все проблемы с формированием базы и запросов разрешимы. Я больше задумываюсь над тем, что к универсальной структуре базы нужны универсальные механизмы работы. В далеком 96-м мы решили создать набор компонентов, который стал бы оберткой для этой универсальной структуры и смог бы работать дополнительным уровнем абстракции. Первую попытку мы сделали в 97-ом. В качестве объектной модели были выбраны COM и ActiveX. В качестве первого средства реализации использовалась Delphi. Мы сделали набор визуальных компонентов для работы со справочниками, тестовую версию которых можно скачать с нашего сайта www.optim.su. Опыт разработки таких компонентов показал, что для их создания нужно применять middleware-слой (первые компоненты были сделаны в двухуровневой технологии клиент-сервер), причем нужна не зависящая от языка и имеющая ряд особенностей технология доступа к данным. Одной из особенностей такой технологии является возможность передачи и динамического изменения метаданных для каждого элемента курсора. Второй вывод сделанный нами – нужна инфраструктура, позволяющая динамически создавать пользовательский интерфейс. Именно тогда мы приняли решение создать ascDB и ascContainer. Ввиду серьезных ограничений, накладываемых (особенно в те времена) Delphi (вернее, VCL), нам пришлось использовать для создания этих компонентов VC и ATL (тогда еще то ли 1, то ли 2). Мы назвали эти компоненты нижним слоем ядра конструктора учетных систем. Собственно, сначала даже не планировалось делать эти библиотеки коммерческими (они предназначались только для внутреннего использования).
В ближайшее время мы планируем продолжить работу над этим проектом. Речь идет о работе над новой версией набора компонентов для работы со справочниками, учитывающей опыт, полученный в пилотном проекте, и над так называемым ядром. Это ядро будет организовано по описанным выше принципам, но будет содержать кучу дополнительных технологий, которые нужны для полнофункциональных учетных систем. Так, там будет работа с валютой, расчет оборотов и остатков, работа со справочниками (с помощью набора компонентов, о котором говорилось выше) и многое другое. Конечной целью является создание многоуровневого конструктора, позволяющего "собирать" приложения прямо на глазах у заказчика. В этот конструктор будут подключаться модули, которые вместе с расширениями для ядра должны позволить создавать системы из модулей независимых производителей.
Так вот, ... к чему я веду? Не хочет ли кто присоединится к этому проекту? Минимум, что нужно – это более детально сформулировать идеи (на бумаге) и обсудить эти технологии. Так же интересно было бы заполучить альфа- и бета-тестеров, помогающих в создании этого конструктора. Ну и естественно, мы не отказались бы от сотрудничества с заинтересованными фирмами (особенно с богатыми) и частными лицами. В зависимости от доли участия первая версия этого продукта вам будет передана или вообще бесплатно или с большой скидкой. Само собой разумеется, вы получите возможность получать ответы на свои вопросы и использовать беты для создания пилотных версий ваших продуктов.
| Оценка 100 Оценить
|