Представление объектов в оперативной памяти, указатели
Динамическая память и стек
Отслеживание утечек памяти
Стиль определения указателей
Резюме
Список литературы

|
Оперативная память
Представление объектов в оперативной памяти, указатели Динамическая память и стек Отслеживание утечек памяти Стиль определения указателей Резюме Список литературы |
|
Я думаю, что некоторые крупнейшие ошибки
— даже на самых верхних уровнях архитектуры —
происходят из-за слабого или неверного понимания
некоторых простых вещей на самых нижних уровнях.
Джоэл Спольски
Язык C++ по меркам сегодняшнего дня является языком программирования относительно низкого уровня. В частности, он не берёт на себя в полной мере управление таким важным ресурсом компьютера, как оперативная память. Поэтому крайне важно при изучении основ программирования на этом языке составить правильное представление об организации оперативной памяти, предоставляемой программам, и о базовых принципах работы с ней.
Знание основ управления памятью будет полезным и при использовании других языков программирования.
С точки зрения разработчика программного обеспечения оперативная память представляет собой упорядоченную последовательность ячеек — байт, предназначенных для размещения данных, которыми оперирует программа во время своего выполнения.
Упорядоченность означает, что каждый элемент последовательности (каждая ячейка памяти) имеет свой порядковый номер. Этот порядковый номер называют адресом ячейки памяти — адресом байта. Непрерывный диапазон ячеек, доступный для адресации в конкретной операционной системе, называют адресным пространством.
Схематично память обычно представляют так, как показано на рис. 1.
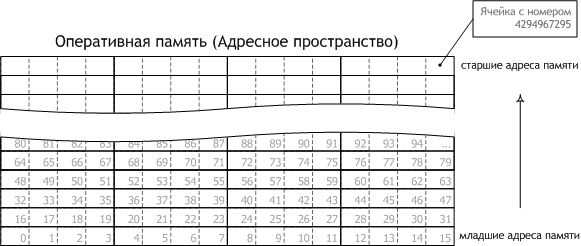
Рис. 1. Адресное пространство
Байты упорядочивают снизу вверх, указанные в ячейках числа — это номера ячеек, являющиеся их адресами. Начальные адреса памяти часто называют младшими или нижними, а конечные — старшими или верхними.
Общее количество доступных для адресации ячеек памяти определяется разрядностью операционной системы, более точно — разрядностью типа данных, используемого в конкретной операционной системе для хранения номера ячейки.
Современные операционные системы в своём большинстве представлены 32- и 64-разрядными версиями. В 32-разрядных операционных системах для работы с номерами ячеек памяти используются 32-разрядные (4-байтные) типы данных. Адресовать в таких системах можно до 4294967296 ячеек — максимальное число, которое можно представить 32 разрядами, что в точности соответствует 4 Гб адресного пространства. В 64-разрядных операционных системах для работы с номерами ячеек памяти используются 64-разрядные (8-байтные) типы данных. Количество ячеек, которое можно адресовать в таких системах, измеряется эксабайтами. В дальнейшем для большей определённости мы будем предполагать, что работа ведётся в 32-разрядной операционной системе.
В итоге, с каждой ячейкой памяти связано двевеличины — порядковый номер ячейки, называемый адресом, и данные, которые хранятся в ячейке по этому адресу.
Все объекты, которые каким-либо образом определяются в программе, размещаются в оперативной памяти. Рассмотрим следующую небольшую программу на языке C++:
#include <iostream>
usingnamespace std;
void main()
{
int i = 17;
int j = 29;
int* p1 = &i;
cout << p1 << endl;
cout << *p1 << endl;
*p1 = 103;
cout << i << endl;
int* p2 = p1;
*p2 = 107;
cout << i << endl << *p1 << endl;
i = 207;
cout << *p1 << endl << *p2 << endl;
p2 = &j;
cout << *p2 << endl;
} |
В первых двух строчках функции main
int i = 17;
int j = 29; |
определяются переменные i и j, являющиеся объектами целочисленного типа int, которые инициализируются значениями 17 и 29 соответственно. При выполнении этих строк кода в памяти выделяются ячейки под хранение значений переменных i и j или, иными словами, под размещение объектов i и j, в которые записываются начальные значения 17 и 29.
На рис. 2 показано состояние памяти после выполнения рассматриваемых строк кода.

Рис. 2. Размещение в памяти объектов i и j
Для определенности будем считать, что объект с именем i размещен в памяти, начиная с 48-ой ячейки.
| ПРИМЕЧАНИЕ Следует отметить, что память (доступное программе адресное пространство) разбивается на разделы (непрерывные диапазоны ячеек), часть из которых резервируется под нужды операционной системы. Так, в операционных системах Microsoft Windows младшие адреса памяти используются для выявления нулевых указателей, в связи с чем вероятность встретить в программе объект, расположенный по адресу 48, близка к нулю. Однако на данном этапе в целях упрощения изложения и исключения операций с большими числами мы не будем принимать этот факт во внимание. Не лишним будет сказать, что одной из лучших книг, описывающих архитектуру памяти Windows, является книга Джеффри Рихтера «Windows для профессионалов» [7]. |
Количество ячеек памяти, необходимое для размещения объекта (необходимое для хранения состояния объекта), определяется типом объекта. Объектам целочисленного типа достаточно 4 ячеек — 4 байт. Таким образом, объект i занимает 4 ячейки — с 48-й по 51-ю включительно, в этих ячейках хранится число 17.
Можно сказать по-другому: данные, расположенные в памяти с 48-й по 51-ю ячейку, известны в нашей программе под именем i и интерпретируются как целое число.
Следом за объектом i располагается объект j. Он также является объектом типа int, а следовательно, тоже занимает 4 ячейки — с 52-й по 55-ю, в этих ячейках хранится число 29.
Номер первой из занимаемых объектом ячеек памяти называют адресом объекта. Так, адресом объекта i будет число 48, а объекта j — число 52.
Адрес объекта является той характеристикой, которая идентифицирует объект, отличает один объект от всех других объектов в системе.
Рассмотрим следующую строчку нашей программы:
int* p1 = &i;
|
Здесь определяется переменная p1, являющаяся указателем (pointer) на объект типа int, которая инициализируется адресом объекта i. Указатели — это особый вид объектов, предназначенных для хранения информации о местоположении в памяти других объектов.
Значением объекта-указателя является адрес другого объекта.
О том, что p1 является указателем, говорит символ ‘*’, следующий непосредственно за названием типа. Указатели типизированы: при определении объекта-указателя задается тип объектов, на которые он может указывать — значением объекта-указателя может быть только адрес объекта соответствующего типа. Так, указателю на объект типа int может быть присвоен только адрес объекта типа int, указателю на объект типа double — только адрес объекта типа double и т. п. В нашем случае p1 может указывать только на объекты типа int; значением p1 может быть только адрес объекта типа int. Компилятор не позволит (выдав соответствующее сообщение об ошибке) присвоить переменной p1 адрес объекта, не относящегося к типу int.
Символ ‘&’, предшествующий переменной i, обозначает операцию взятия адреса. Унарная префиксная операция взятия адреса обеспечивает переход от объекта к его адресу. В нашем случае она возвращает адрес объекта i, которым инициализируется переменная p1.
|
Часто операцию взятия адреса также называют операцией получения адреса. |
Адрес объекта, как отмечалось ранее, — это номер ячейки, начиная с которой объект размещается в памяти. Объект i размещается в памяти, начиная с 48-й ячейки, следовательно, его адресом является число 48, оно же является значением объекта-указателя p1. На рис. 3 показана конфигурация памяти после выполнения рассматриваемой строчки программы.

Рис. 3. Размещение в памяти объектов i, j и p1
Объекты-указатели, равно как и любые другие объекты, размещаются в памяти, занимая в ней определённое количество ячеек. Поскольку объект-указатель хранит адрес другого объекта, а адрес — это номер ячейки памяти, то, независимо от типа (а, следовательно, и размера) объекта, на который указывает объект-указатель, сам объект-указатель в 32-разрядных операционных системах всегда занимает в памяти 4 ячейки — 4 байта.
В нашем случае объект p1 занимает ячейки с 56-й по 59-ю, в этих ячейках хранится число 48, являющееся номером ячейки, начиная с которой в памяти размещён объект i.
Распечатаем теперь значение переменной p1:
cout << p1 << endl; |
| ПРИМЕЧАНИЕ endl — сокращение от end line — манипулятор стандартного потока вывода, записывающий в него символ перевода строки ‘\n’ и форсирующий отображение информации на экране. |
Мы вполне можем ожидать, что данный код выведет на экран число 48, однако… будет выведено число 00000030. Дело в том, что при работе с адресами ячеек памяти (а, следовательно, с адресами объектов и значениями объектов-указателей) принято использовать шестнадцатеричную систему счисления.
Шестнадцатеричная система удобна. В этой системе значение любого байта может быть записано посредством двух шестнадцатеричных цифр, а так как под хранение адреса ячейки памяти отводится 4 байта, то любой адрес может быть компактно представлен восемью шестнадцатеричными цифрами. Перевод чисел из двоичной системы счисления в шестнадцатеричную и обратно выполняется крайне просто. Кроме того, отображение (равно как и запись) адресов ячеек памяти в шестнадцатеричной системе счисления позволяет визуально отличать их от значений целочисленных переменных.
| ПРИМЕЧАНИЕ Для перевода числа из двоичной системы счисления в шестнадцатеричную следует двоичные цифры объединить в группы по четыре в направлении справа налево и заменить каждую группу соответствующей шестнадцатеричной цифрой. Обратный перевод выполняется аналогичным образом: каждую шестнадцатеричную цифру нужно заменить её представлением в двоичной системе, дополненном, при необходимости, лидирующими нулями до 4 разрядов. Обоснование данного правила можно найти в книге Джеймса Андерсона «Дискретная математика и комбинаторика» [12]. |
Вернёмся к примеру. Число 48 является суммой пятой и четвёртой степеней двойки; в двоичной системе счисления ему соответствует число 110000, которое, в соответствии с приведённым выше правилом перевода, в шестнадцатеричной системе записывается как 30, что, за исключением шести лидирующих нулей, в точности соответствует выводу нашей программы. Лидирующие нули используются для достижения единого восьмизначного формата отображения адресов памяти — младшие адреса памяти, представляемые меньшим количеством знаков, дополняются ими до 8 разрядов.
Так как далеко не все шестнадцатеричные числа содержат в своей записи буквенные символы, то для того, чтобы явно показать, что число представлено в шестнадцатеричной системе счисления, непосредственно перед ним часто ставят префикс ’0x’.
На рис. 4 показана рассмотренная ранее конфигурация памяти в более общепринятом виде (лидирующие нули, в целях упрощения картины, опущены).

Рис. 4
| ПРИМЕЧАНИЕ Говоря о размещении объектов в оперативной памяти, необходимо сказать о существовании нескольких моделей представления в памяти многобайтных объектов, таких, например, как объекты типа int. Основными являются модели little-endian и big-endian. В модели little-endian запись числа начинается с младшего байта и заканчивается старшим. Такой порядок записи чисел принят на архитектурах x86. В модели big-endian запись числа начинается со старшего байта и заканчивается младшим. Такой порядок является стандартным для сетевых протоколов TCP/IP. Например, число 29 (в шестнадцатеричной системе счисления — 0x1D), являясь значением объекта типа int (занимающим в памяти 4 байта), в модели little-endian будет представлено последовательностью байт со значениями 1D, 00, 00, 00; в модели big-endian — последовательностью байт со значениями 00, 00, 00, 1D. Преимуществом модели little-endian является возможность преобразования типов целых чисел при чтении меньшего количества байт. Так, прочитав значение 0x0000001D объекта типа int как данные объекта типа short, т. е. только первые два байта, мы получим число 0x001D, прочитав это же значение как данные объекта типа char, т. е. только первый байт, мы получим число 0x1D. Для записи больших чисел, длина которых существенно превышает разрядность машины, также предпочтительнее порядок little-endian, поскольку арифметические операции над числами производятся от младших разрядов к старшим. Числа, представленные в модели big-endian, выглядят естественным для арабской записи чисел образом. |
Следующая строчка программы
cout << *p1 << endl; |
демонстрирует переход от указателя на объект к объекту, на который данный указатель указывает. В отличие от рассмотренной ранее строки, выводящей на экран значение непосредственно переменной p1, эта строчка распечатывает состояние объекта, на который переменная p1 указывает — результатом её выполнения будет вывод на экран числа 17.
В данном контексте символ ‘*’, предшествующий p1, обозначает операцию разыменования. Унарная префиксная операция разыменования обеспечивает переход от указателя на объект к объекту, расположенному в памяти по адресу, хранимому в указателе. Операция разыменования становится возможной исключительно в силу типизации указателей: в типе заложена информация о размере памяти, необходимой для размещения объекта, и о способе интерпретации содержащихся в ней данных, что в совокупности с адресом однозначно идентифицирует объект в памяти.
В нашем случае p1 — это указатель на объект целочисленного типа int, значением p1 является число 0x30. Следовательно, применяемая к p1 операция разыменования возвращает объект, расположенный в памяти начиная с ячейки с номером 0x30, занимающий в ней 4 байта, относящийся к типу int, т. е. объект, известный в нашей программе под именем i. Значением объекта, соответственно, будет число 17 — именно оно находится в четырех ячейках памяти, на которые указывает p1 (рис. 5).
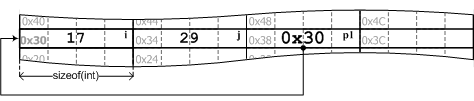
Рис. 5
| ПРИМЕЧАНИЕ В некотором смысле, операция разыменования * является обратной по отношению к операции взятия адреса & — для произвольного объекта d любого наперёд заданного типа, поддерживающего операцию сравнения, выражение *&d == d всегда истинно. |
Используя операцию разыменования, мы можем не только получать значение адресуемого указателем объекта (в частности, для вывода на экран), но и изменять это значение – например, так, как это делается в следующей строке нашей программы:
*p1 = 103; |
Здесь выполняется присваивание нового значения объекту, на который указывает p1. Сначала, при помощи операции разыменования, осуществляется переход от указателя p1 к объекту, адрес которого хранится в p1, после чего полученному объекту присваивается новое значение — в ячейки памяти, отведённые под этот объект, записывается число 103. Как мы знаем, p1 указывает на объект i, следовательно, приведённый код модифицирует данные в ячейках памяти, занимаемых объектом i, изменяя тем самым состояние объекта i.
На рис. 6 показана конфигурация памяти после выполнения рассматриваемой инструкции.

Рис. 6
Вывод на экран значения объекта i
cout << i << endl; |
приведёт теперь к отображению числа 103, что полностью подтверждает наши рассуждения — мы изменили состояние объекта через указатель на него.
Таким образом, используя указатель p1 (и операцию разыменования), мы можем производить над объектом i в точности те же самые действия, что и с использованием имени i. Следовательно, p1 можно трактовать как ещё одно имя объекта i. Подобные имена называют косвенными. В итоге у нас есть один целочисленный объект и два его имени: прямое — i и косвенное — p1, посредством которых можно обращаться к этому объекту — получать или изменять его состояние.
Косвенных имён может быть и больше. Так, в следующей строке нашей программы создаётся ещё одно косвенное имя — p2, при помощи которого мы можем работать с объектом i.
int* p2 = p1;
|
| ПРИМЕЧАНИЕ Смысл символа ‘*’ зависит от контекста, в котором он используется. При определении переменной (int* p;) он говорит о том, что определяемая переменная будет указателем; при использовании в префиксной форме (*p) он обозначает операцию разыменования указателя; в инфиксной форме (например, в выражении 5 * 7) символ ‘*’ обозначает операцию умножения. |
В строке кода выше определяется указатель p2 на объект типа int, который инициализируется значением указателя p1 — числом 0x30 — адресом объекта i (рис. 7). Тем самым, p2 становится ещё одним указателем на объект i, ещё одним именем, позволяющим косвенно обращаться к объекту i.

Рис. 7. Размещение в памяти объектов i, j, p1 и p2
Итак, у нас есть целочисленный объект с именем i и два объекта-указателя с именами p1 и p2, которые указывают на объект i. Т.е. p1 и p2, с одной стороны, являются именами объектов-указателей, а с другой — косвенными именами объекта i; применив к этим именам операцию разыменования, мы получим доступ к одному и тому же объекту — объекту i.
К примеру, следующий код
*p2 = 107; |
по аналогии с рассмотренным ранее, производит запись числа 107 в ячейки памяти, отведённые под объект, адрес которого хранится в указателе p2, т. е. в ячейки памяти, занимаемые объектом i. Здесь, как и ранее, мы изменяем состояние объекта i через указатель на него, но теперь делаем это с помощью переменной p2.
Состояние памяти после выполнения данного кода показано на рис. 8.

Рис. 8
|
i, *p1, *p2 обозначают один объект. Гради Буч в своей книге «Объектно-ориентированный анализ и проектирование с примерами приложений на C++» [11] отмечает, что «источником множества ошибок в объектно-ориентированном программировании является неумение отличать имя объекта от самого объекта». |
Распечатав значение объекта i и значение объекта, на который указывает p1:
cout << i << endl << *p1 << endl; |
мы получим один и тот же результат — число 107, так как именно оно теперь является значением объекта i и именно на него указывают переменные p1 и p2.
Рассмотрим обратную ситуацию — присвоим новое значение непосредственно объекту i.
i = 207; |
Выполнение этого кода (см. рис. 9) напрямую скажется на результатах последующего разыменования указателей p1 и p2.
cout << *p1 << endl << *p2 << endl; |
В обоих случаях на экран будет выведено число 207: посредством имён i, p1 и p2 мы прямо или косвенно обращаемся к одному и тому же объекту в памяти, поэтому воздействие на объект через одно из этих имён незамедлительно отражается на результате, получаемом через любое другое имя.

Рис. 9
При необходимости указатель на один объект всегда можно превратить в указатель на другой объект соответствующего типа. К примеру, сделаем из p2 (указателя на объект i) указатель на объект j. Для этого достаточно переменной p2 присвоить адрес объекта j.
p2 = &j; |
| ПРИМЕЧАНИЕ Результатом применения операции взятия адреса & к объекту типа int будет объект типа int* и наоборот, результатом применения к объекту типа int* операции разыменования * будет объект типа int. |
Рис. 10 иллюстрирует состояние памяти после выполнения приведённой строки кода.

Рис. 10
В данном случае (перед p2 нет символа ‘*’) осуществляется присваивание нового значения непосредственно объекту-указателю p2 — в отведённые под него ячейки памяти записывается адрес объекта j — число 0x34, тем самым изменяется состояние p2 — он становится указателем на объект j.
Если теперь распечатать значение объекта, адресуемого указателем p2
cout << *p2 << endl; |
то на экран будет выведено число 29, то есть значение объекта j.
| ПРИМЕЧАНИЕ У объекта-указателя, равно как и у любого другого объекта, есть адрес — номер ячейки, начиная с которой объект-указатель располагается в памяти. Так, адресом объекта-указателя p1 является число 0x38, объекта-указателя p2 — число 0x3C. Получить адрес объекта-указателя можно посредством применения к нему операции взятия адреса &. Результатом применения этой операции к указателю на объект типа int (к объекту типа int*) будет объект типа int**. |
В большинстве случаев сложности при работе с указателями возникают вследствие двойственности их природы: можно работать с адресом, являющимся значением указателя, а можно с объектом, расположенным по этому адресу.
Лучшему пониманию происходящего в программе (а также при проектировании того, что должно в ней происходить) помогает схематичное отображение (на обычной бумаге, обычной ручкой) состояния объектов и связей между ними, подобно тем схемам, что были приведены при разборе нашего примера. Схемы визуально показывают какой указатель на какой объект указывает, что чему присваивается, что происходит при выполнении той или иной операции с точки зрения размещения объектов в памяти. Восприятие визуальных образов происходит гораздо легче и быстрее.
| ПРИМЕЧАНИЕ Для полноты картины следует сказать о возможности определения нетипизированных указателей. Нетипизированные указатели определяются как указатели на void: void* p; Указателю на void можно присвоить адрес объекта любого типа (значение указателя на объект любого типа). Операция разыменования к указателям на voidне применима, поскольку при отсутствии информации о типе нет информации о размере адресуемого указателем объекта и о способе интерпретации данных этого объекта. Чтобы получить доступ к объекту, адрес которого хранит нетипизированный указатель, необходимо выполнить явное преобразование типа указателя (преобразование типов объектов осуществляется посредством функций static_cast, const_cast, reinterpret_cast и dynamic_cast). Используются указатели на void, в основном в функциях, оперирующих не объектами, а непосредственно областями памяти (malloc, free, realloc и т. п.). Как отмечает Бьерн Страуструп в своей книге «Язык программирования C++» [1] (это основная книга по языку), «функции, использующие void*, обычно существуют на самых нижних уровнях системы, где происходит работа с аппаратными ресурсами. Наличие void* на более высоких уровнях подозрительно и, скорее всего, является индикатором ошибки на этапе проектирования». |
В общем случае оперативная память, с которой работает программа, подразделяется на три вида: статическую, автоматическую и динамическую.
Статическая память — это область памяти, выделяемая при запуске программы до вызова функции main из свободной оперативной памяти для размещения глобальных и статических объектов, а также объектов, определённых в пространствах имён.
|
Объект называют глобальным, если он определён вне функции, класса или пространства имён. Объект, определённый с использованием ключевого слова static, называют статическим. Глобальные объекты, а также объекты, определённые в пространствах имён или статически в классах, размещаются в памяти (конструируются) до вызова функции main, а разрушаются после завершения работы этой функции. Пространства имён — это способ разделения программы на логические составляющие; механизм ограничения области видимости имён. |
Автоматическая память — это специальный регион памяти, резервируемый при запуске программы до вызова функции main из свободной оперативной памяти и используемый в дальнейшем для размещения локальных объектов: объектов, определяемых в теле функций и получаемых функциями через параметры в момент вызова. Автоматическую память часто называют стеком.
Динамическая память — это совокупность блоков памяти, выделяемых из доступной свободной оперативной памяти непосредственно во время выполнения программы под размещение конкретных объектов.
| ПРИМЕЧАНИЕ Регионом, областью или блоком памяти называют непрерывную последовательность ячеек памяти. Обычно регион больше области, а область больше блока. |
Далее мы сосредоточим внимание на подходах к организации автоматической и динамической памяти и на принципах работы с этими видами памяти.
Непосредственное управление автоматической памятью — выделение памяти под локальные объекты при их создании и освобождение занимаемой объектами памяти при их разрушении — осуществляется компилятором. Собственно, по этой причине память и называют автоматической.
Посмотрим, какие закономерности характерны для размещаемых в автоматической памяти объектов, и почему данный вид памяти также называют стеком.
Период времени от момента создания объекта до момента его разрушения, т. е. период времени, в течение которого под объект выделена память, называют временем жизни объекта.
Время жизни локальных объектов определяется областью видимости их имён. Область видимости локального имени начинается с места его объявления и заканчивается в конце блока, в котором это имя объявлено. Область видимости аргументов функции ограничивается телом функции, т. е. считается, что имена аргументов объявлены в самом внешнем блоке функции.
| ПРИМЕЧАНИЕ Область видимости имени — это часть текста программы, в рамках которой имя может быть использовано. |
Таким образом, время жизни локального объекта начинается в процессе выполнения функции в момент определения объекта и заканчивается в момент выхода процесса выполнения из блока, обрамляющего это определение.
Обрабатывая определение локального имени, такого как i, j, p1 и p2 из рассмотренного ранее примера, компилятор генерирует код размещения соответствующего ему объекта в регионе автоматической памяти: код выделения памяти под объект и вызова конструктора для инициализации выделенной памяти.
Обрабатывая завершение блока (закрывающую фигурную скобку ‘}’) компилятор генерирует код разрушения всех объектов, определённых в этом блоке: код вызова деструкторов и освобождения занимаемой объектами памяти. В случае с нашим примером компилятор на месте фигурной скобки, завершающей тело функции main, сгенерирует код разрушения объектов p2, p1, j и i, т. е. всех объектов, чьи имена в данном месте выходят из области видимости.
Учитывая вложенность вызовов функций, а также вложенность блоков внутри функций можно говорить о вложенности времён жизни локальных объектов: время жизни объектов, созданных позже, заканчивается раньше. Это, в свою очередь, позволяет сделать вывод о том, что размещение объектов в автоматической памяти и их удаление из неё происходит по принципу LIFO.
| ПРИМЕЧАНИЕ LIFO — сокращение от Last In First Out — принцип обслуживания элементов в порядке, обратном их поступлению — первым обслуживается (извлекается) элемент, пришедший последним. |
Программным воплощением данного принципа является стек, который и используется в большинстве компиляторов C++ для реализации автоматической памяти. Именно вследствие такой реализации (такого внутреннего устройства) автоматическую память часто называют стеком, а локальные объекты — стековыми. В дальнейшем этого названия будем придерживаться и мы.
Еще раз вернёмся к нашему примеру. Все те объекты, размещение которых в оперативной памяти мы рассматривали, т. е. i, j, p1 и p2, являясь локальными объектами, размещаются не абстрактно в оперативной памяти, а в конкретном её регионе — стеке. Рис. 11 иллюстрирует это, отражая состояние стека непосредственно перед выходом из функции main.
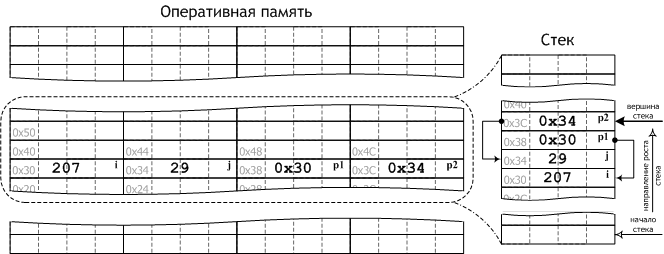
Рис. 11. Регион автоматической памяти — стек
Объекты в стеке размещаются последовательно друг за другом в порядке их определения (см. рис. 11). Выделение памяти в стеке в общих чертах сводится к смещению указателя вершины стека в направлении роста стека на размер размещаемого объекта; освобождение памяти — к смещению указателя вершины стека в обратном направлении на размер удаляемого объекта (помните о вложенности времён жизни локальных объектов). Операции выделения и освобождения памяти в стеке выполняются очень быстро.
| ПРИМЕЧАНИЕ 1. Порядок расположения в автоматической памяти объектов, определяемых в теле функций, в отличие от порядка расположения объектов, передаваемых функциям через параметры, никак не регламентируется и остаётся на усмотрение разработчиков компиляторов. По этой причине он может отличаться от рассмотренного выше и изменяться от одной версии компилятора к другой. Более того, некоторые локальные объекты могут размещаться компилятором в регистрах процессора. Объекты, передаваемые через параметры функции, по умолчанию закладываются в стек в порядке, обратном их перечислению в списке параметров. 2. На архитектурах x86 стек растет в сторону уменьшения адресов памяти, т. е. вниз. В итоге, размещение объектов в стеке могло бы быть таким, как показано на рис. 12. Однако указанные замечания не имеют существенного значения для понимания сути рассматриваемых концепций, в связи с чем, мы не станем, в дальнейшем, акцентировать на них внимание и будем придерживаться первоначальной модели стека. |
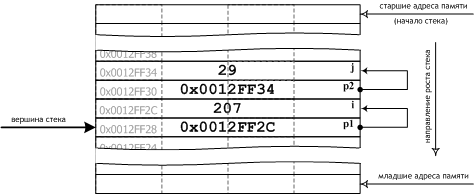
Рис. 12. Размещение объектов в стеке на архитектурах x86
Размещение объектов в стеке имеет неоспоримые преимущества. Прежде всего, в силу автоматического разрушения объектов: нам не нужно заботиться об удалении стековых объектов, это делает за нас компилятор, генерируя на выходе локального имени из области видимости код разрушения соответствующего ему объекта — код вызова деструктора и освобождения отведённой (в стеке) под объект памяти. Существенное значение имеет и высокая скорость размещения объектов в стеке.
Однако специфика работы со стеком накладывает и определённые ограничения — далеко не все объекты могут быть в нём размещены. Стратегия автоматического удаления не позволит нам создать в функции стековый объект, время жизни которого превышало бы время выполнения функции. Из того, что выделение памяти в стеке возлагается на компилятор, следует, что размер (а значит и тип) размещаемых в стеке объектов должен быть известен на этапе компиляции, что часто бывает невозможно. Простейшая задача обработки массива, размерность и элементы которого вводятся с клавиатуры или из файла, является ярким тому подтверждением. Кроме того, размер стека в большинстве случаев ограничен (для программ, разрабатываемых в среде Microsoft Visual Studio, размер стека по умолчанию — 1 Мб), что приводит к невозможности размещения в нём больших объектов, к примеру, тех же массивов. Средством преодоления рассмотренных ограничений является динамическая память, особенностям работы с которой посвящен следующий раздел.
Доступную программе свободную оперативную память часто, в связи со спецификой размещения в ней объектов, называют кучей (heap). В общем случае нет чёткого, наперёд заданного (как в стеке) порядка расположения объектов в ней: распределение блоков памяти происходит динамически — в большинстве реализаций под объект отводится первый подходящий по размеру свободный блок. Вследствие этого динамическую память часто определяют как память, выделяемую из кучи (непосредственно во время выполнения программы под размещение конкретных объектов).
В отличие от стека, которым управляет компилятор, управление динамической памятью осуществляется явным образом: выделение памяти производится оператором new, освобождение — оператором delete (C++, конечно же, поддерживает работу с памятьюв стиле С, например, с помощью функций malloc и free, но для целей данной статьи это несущественно – прим.ред.).
Рассмотрим работу с динамической памятью на примере небольшой программы:
#include <iostream>
usingnamespace std;
int* CreateObject()
{
int* p = newint(309);
cout << p << endl;
return p;
}
void main()
{
int* p1 = NULL;
p1 = CreateObject();
cout << p1 << endl;
if (p1)
{
cout << *p1 << endl;
*p1 = 517;
}
delete p1;
} |
Программа состоит из двух функций: main, с которой начинается выполнение любой C++-программы, и CreateObject. Функция CreateObject создаёт в динамической памяти объект типа int и возвращает указатель на него. Функция main вызывает функцию CreateObject, получает указатель на созданный ею объект, производит с этим объектом некоторую работу, после чего разрушает его. Исследуем процесс выполнения этой программы.
В первой строчке функции main:
int* p1 = NULL;
|
определяется переменная p1, являющаяся указателем на объект целочисленного типа int, которая инициализируется предопределённым значением NULL.
NULL — это специальное значение, используемое для идентификации объектов-указателей, которые ни на что не указывают; оно соответствует нулевому адресу и обычно определяется одним из следующих способов:
#define NULL 0
constint NULL = 0; |
| ПРИМЕЧАНИЕ В C++0х введена новая константа – nullptr, специально предназначенная для обозначения нулевого указателя – прим.ред. |
Гарантируется, что в программе (в системе) не может быть объектов с нулевым адресом, следовательно, объект-указатель со значением 0 можно интерпретировать как указатель, который ничего не адресует. Такие объекты-указатели называют нулевыми указателями. Значение NULL или 0 может быть присвоено указателю на объект любого типа. Разыменование нулевого указателя приводит к неопределённому поведению программы, в большинстве случаев — к её аварийному завершению.
При выполнении рассматриваемой строки кода в оперативной памяти, более точно — в стеке, выделяются ячейки под размещение объекта-указателя p1, в эти ячейки записывается число 0 — p1 ни на что не указывает. Рис. 13 отражает состояние памяти (с учётом её разделения на регионы) после выполнения данной строки кода.
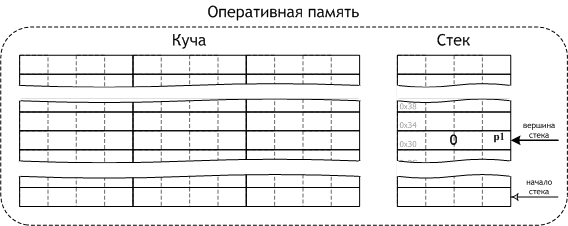
Рис. 13. Куча и стек
Как и ранее, для большей определённости, будем считать, что объект-указатель p1 размещён в стеке по адресу 0x30, т.е. занимает с 48-й по 51-ю ячейки памяти.
| ПРИМЕЧАНИЕ В дальнейшем на схемах мы будем отображать только значимые для нас области стека и кучи. |
Перейдем к следующей строке функции main:
p1 = CreateObject(); |
В этой строке осуществляется вызов функции CreateObject и сохранение возвращаемого ею значения в переменной p1. При вызове функции CreateObject выполнение функции main приостанавливается и процесс выполнения переходит к первой строчке функции CreateObject:
int* p = newint(309);
|
Данная строка программы представляет для нас наибольший интерес, поскольку мы начинаем работать с динамической памятью. В этой строке определяется локальный объект-указатель p, который инициализируется адресом нового,создаваемого оператором newв динамической памяти целочисленного объекта со значением 309.
Формат вызова оператора new таков: ключевое слово «new», за которым следует тип создаваемого объекта, за которым в круглых скобках может следовать список параметров, необходимых для начальной инициализации объекта.
Что делает оператор new? Во-первых, он выделяет память в куче. Для этого на основе информации о типе оператор new вычисляет количество ячеек памяти, необходимое для размещения объекта этого типа, и обращается к системе, более точно — к диспетчеру памяти, с запросом о предоставлении блока памяти рассчитанного размера. Во-вторых, он вызываетконструктор — специальный метод создаваемого объекта, выполняющий на основе переданных в круглых скобках параметров начальную инициализацию полученной памяти. Возвращаемым значением оператора new является адрес созданного объекта.
| ПРИМЕЧАНИЕ В целом действия, производимые оператором new, напоминают те, что выполняет компилятор при создании локальных объектов, с той разницей, что оператор new выделяет память в куче, а под локальные объекты память выделяется в стеке. После выделения памяти в обоих случаях происходит её инициализация посредством вызова конструктора. Вызов конструктора завершает создание объекта. |
Возникает два вопроса: что подразумевается под термином «выделение памяти» (или «предоставление памяти») и что произойдет, если диспетчер памяти не сможет выделить блок требуемого размера?
У диспетчера памяти (его также называют менеджером памяти) есть список выделенных (иначе говоря, занятых) и свободных блоков памяти. Получив запрос от оператора new, он просматривает этот список в поисках первого свободного блока достаточного размера. Обнаружив такой блок, диспетчер памяти проверяет, равен ли его размер тому, что был запрошен, или превосходит его. Если равен, то диспетчер памяти помечает найденный блок как занятый (выделенный под размещение объекта) и возвращает адрес этого блока оператору new. Если же размер найденного блока больше запрашиваемого, то диспетчер памяти отделяет от него блок требуемого размера, разбивая тем самым исходный блок на два, помечает полученный блок как занятый и возвращает его адрес оператору new.
После того как блок памяти помечен диспетчером как занятый, он закрепляется за создаваемым объектом и не может быть отдан под размещение какого-либо другого объекта до тех пор, пока мы явно не освободим его (вызовом оператора delete).
Бывают случаи, когда диспетчер памяти не может найти свободный блок требуемого размера. Ранее, до появления в стандарте C++ исключений (exceptions), в таких случаях оператор new возвращал значение NULL. С появлением исключений поведение оператора new было изменено — теперь при нехватке памяти он генерирует исключение std::bad_alloc.
| ПРИМЕЧАНИЕ К моменту включения в стандарт исключений и соответствующего изменения работы оператора new, на языке C++ было реализовано огромное количество программных систем, поэтому в целях поддержки существующего кода многие современные компиляторы имеют специальную настройку, позволяющую выбирать между двумя возможными вариантами поведения оператора new. Однако пользоваться этой настройкой и включать устаревшее поведение при разработке новых проектов не рекомендуется — это отрицательно скажется как на переносимости кода, так и его читаемости. Для тех же ситуаций, когда у вас найдутся веские причины избегать использования исключений, предусмотрен специальный формат вызова оператора new: new(std::nothrow) type (args) Константа std::nothrow, указанная в круглых скобках непосредственно за ключевым словом «new», явно говорит о том, что в случае нехватки памяти оператор new вместо генерации исключения std::bad_alloc должен вернуть значение NULL (type и args, как и в общем случае, — тип создаваемого объекта и возможные параметры его инициализации). Оператор new, в тех случаях, когда конструктор создаваемого им объекта генерирует исключение, выполняет освобождение выделенной ранее памяти. |
Вернёмся к рассматриваемой нами строке программы:
int* p = newint(309);
|
Конфигурация памяти после её выполнения представлена на рис. 14.
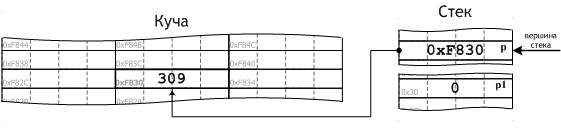
Рис. 14
Для определённости будем считать, что созданный оператором new объект располагается в оперативной памяти (в куче) по адресу 0xF830, т. е. занимает в ней с 63536 по 63539 ячейки включительно.
| ПРИМЕЧАНИЕ Куча и стек — это разные регионы адресного пространства, часто расположенные на значительном удалении друг от друга, в связи с чем адреса объектов, размещённых в куче, обычно весьма существенно отличаются от адресов объектов, размещённых в стеке. |
Оператор new создаёт в куче объект типа int со значением 309 и возвращает адрес этого объекта — число 0xF830. Компилятор создаёт в стеке объект-указатель p и инициализирует его адресом, возвращённым оператором new — в ячейки памяти, отведённые в стеке под p, записывается число 0xF830.
В итоге рассматриваемая строчка порождает в памяти два (это важно, обратите особое внимание) объекта: объект целочисленного типа int со значением 309 в куче и объект-указатель p в стеке. Адрес созданного в куче объекта является значением стекового объекта-указателя p (см. рис. 14).
Как мы знаем по результатам разбора первого примера, указатель на объект можно трактовать как косвенное имя адресуемого им объекта. Однако если в случае с указателем на стековый объект мы можем обратиться к объекту как посредством указателя, так и прямого имени, то в случае с указателем на объект в куче прямого имени, такого как i или j, в нашем распоряжении нет. С объектом в куче мы можем работать (получать или изменять его состояние) только посредством указателей.
Вывод на экран значения переменной p
cout << p << endl; |
в условиях наших допущений об адресе созданного оператором new объекта приведёт ко вполне ожидаемому результату — отображению шестнадцатеричного числа 0000F830.
В следующей строке
return p;
|
завершается выполнение функции CreateObject. Из неё в функцию main возвращается значение 0xF830 — адрес динамически созданного целочисленного объекта со значением 309.
При выходе процесса выполнения из функции все определённые в этой функции локальные объекты разрушаются, отведённая под их размещение память освобождается, указатель вершины стека смещается вниз, занимая то положение, в котором он находился до вызова функции. С завершением работы функции CreateObject перестаёт существовать объект-указатель p, однако адресуемый им объект, созданный оператором new в куче, остаётся. Этот объект не является стековым и, следовательно, на выходе из функции компилятор не генерирует код его разрушения. Адрес этого объекта, являясь возвращаемым значением функции CreateObject, присваивается в функции main локальной переменной p1:
p1 = CreateObject(); |
Рис. 15 отражает состояние оперативной памяти после выполнения приведённой выше строки кода.
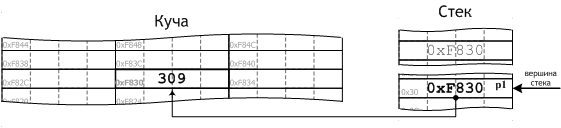
Рис. 15
Распечатав значение объекта-указателя p1
cout << p1 << endl; |
мы убеждаемся в том, что оно в точности совпадает со значением, которое было у разрушенного к этому моменту объекта-указателя p функции CreateObject. p1 — новое косвенное имя динамически созданного в функции CreateObject объекта, посредством p1 мы можем работать с этим объектом в функции main.
В следующей строке функции main, непосредственно перед тем, как начать работу с адресуемым указателем p1 объектом, выполняется проверка допустимости операции разыменования:
if (p1)
|
| ПРИМЕЧАНИЕ В C++ значение выражения считается истинным, если оно отлично от нуля. Таким образом, данный оператор проверяет, не равно ли значение указателя p1 NULL. |
Вообще говоря, в рамках разбираемого примера данная проверка необязательна. В случае недостаточного количества памяти оператор new сгенерирует исключение, после чего — учитывая, что мы это исключение нигде не обработали — наша программа аварийно завершится; до рассматриваемой строки процесс выполнения просто не дойдет. Но такая проверка необходима, если предположить, что функция CreateObject самостоятельно обрабатывает исключение std::bad_alloc и в случае его возникновения возвращает значение NULL; либо, что в функции CreateObject по каким-либо причинам использовалась nothrow-версия оператора new; либо, что функция CreateObject относится к сторонней библиотеке, в документации к которой сказано, что при невозможности создания объекта данная функция возвращает значение NULL и т.п.
Проверив указатель p1 на возможность разыменования, мы распечатываем значение адресуемого им объекта:
cout << *p1 << endl; |
В результате выполнения этого кода на экран будет выведено число 309 (см. рис. 15) — то самое число, которым в функции CreateObject проинициализирован динамически создаваемый объект.
Далее динамически созданному объекту присваивается новое значение:
*p1 = 517; |
При этом совершаются те же действия, что и при задании через указатель нового значения стековому объекту. Сначала, посредством операции разыменования, осуществляется переход от указателя p1 к объекту, адрес которого хранится в p1, после чего полученному объекту присваивается новое значение — в ячейки памяти, отведённые под этот объект, записывается число 517.
Состояние памяти после выполнения данной строки программы показано на рис. 16.

Рис. 16
Как видите, при работе с объектом через указатель нет разницы, в каком конкретно регионе памяти этот объект размещён: в стеке или в куче — доступ к объекту для получения или изменения его состояния выполняется одинаково.
В заключительной строчке функции main удаляется адресуемый указателем p1 объект:
delete p1; |
Оператор delete производит действия, в точности обратные тем, что совершает оператор new при создании объекта, а именно: вызывает деструктор — специальную функцию деинициализации разрушаемого объекта, после чего освобождаетпамять, занимаемую объектом в куче.
| ПРИМЕЧАНИЕ Вызов конструктора уведомляет создаваемый объект о том, что память под него выделена и её необходимо проинициализировать — записать в неё начальные значения. Деструктор — функция, парная конструктору. Вызов деструктора уведомляет разрушаемый объект о том, что процесс его удаления начат и объекту необходимо освободить те ресурсы, которые были им захвачены во время жизни. |
Для освобождения памяти оператор delete (как и оператор new) обращается к диспетчеру памяти, передаёт ему адрес удаляемого объекта и сообщает, что работа с областью памяти, занимаемой этим объектом, завершена. Диспетчер памяти выполняет всю работу по освобождению памяти.
Таким образом, удаление объекта из памяти означает, что память, отведённая под хранение его данных, перестает быть закреплённой за этим объектом — она возвращается системе и может быть отдана ею под размещение данных другого объекта.
В нашем случае оператор delete возвращает системе блок памяти, начинающийся с ячейки 0xF830 — адреса удаляемого объекта — значения указателя p1. На рис. 17 показано состояние памяти после выполнения рассматриваемой строки кода.
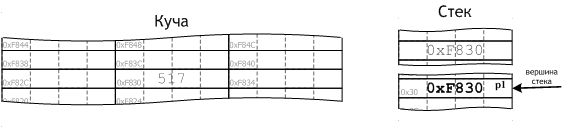
Рис. 17
О том, какие данные будут храниться в диапазоне ячеек памяти 0xF830–0xF833 после выполнения оператора delete, мы достоверно знать не можем: если система ещё не успела отдать этот блок памяти под размещение какого-либо объекта, в них по-прежнему будет число 517, если успела — некие новые данные.
| ПРИМЕЧАНИЕ В большинстве случаев непосредственно в момент удаления объекта из памяти — из кучи или из стека — с данными, содержащимися в отведённых под этот объект ячейках, ничего не происходит. Но эти ячейки перестают быть закреплёнными за объектом (поскольку логически объект больше не существует), они становятся свободными, доступными для размещения других объектов. И вот тогда, когда эти ячейки будут отданы под размещение нового объекта, хранимая в них информация будет затёрта данными нового объекта. |
Надо обратить внимание на то, что при удалении адресуемого указателем p1 объекта с самим указателем p1, с его значением ничего не происходит. Оператор delete освобождает память в куче, указатель же p1 располагается в стеке, отведённая под него память будет освобождена только при выходе p1 из области видимости. В ячейках памяти, занимаемых указателем p1 в стеке (см. рис. 17), после выполнения оператора delete будет записана та же информация, что и до вызова этого оператора — число 0xF830 — адрес уже несуществующего объекта.
Таким образом, после выполнения оператора delete мы получаем недействительный указатель (
В нашем примере никаких дополнительных действий не требуется, так как выполнение функции завершается на следующей после вызова оператора delete строке, и указатель p1 будет автоматически разрушен.
| ПРИМЕЧАНИЕ Допускается применение оператора delete к нулевому указателю (указателю со значением NULL). В этом случае оператор delete ничего не делает и сразу возвращает управление в вызывающую функцию. |
Управление динамической памятью является важнейшей стороной программирования на C++. Работая с динамической памятью, мы вплотную сталкиваемся с указателями, понимание природы которых позволяет избежать огромного количества ошибок. Как написал Джоэл Спольски в своей новой книге «Джоэл: и снова о программировании» [10]: «Указатели и рекурсия требуют определённых способностей к рассуждению и абстрактному мышлению, а главное — умения рассматривать проблему на нескольких уровнях абстракции одновременно. Поэтому способность разобраться в указателях и рекурсии непосредственно связана с перспективой стать выдающимся программистом».
Наберите рассмотренную программу в редакторе среды программирования, например, в Microsoft Visual Studio. Запустите её под отладчиком, в режиме пошагового выполнения посмотрите на значения и адреса объектов. Поэкспериментируйте с программой: попробуйте два раза подряд вызвать оператор удаления для одного и того же указателя или разыменовать нулевой указатель, посмотрите на поведение программы в каждом из случаев.
Необходимость явного управления временем жизни, а точнее, своевременного удаления динамических объектов, вызывает основные сложности при работе с ними. Когда объект, созданный оператором new, становится более не нужным, он должен быть удален оператором delete. В противном случае память, закреплённая за этим объектом, так и останется занятой (не будет возвращена системе) — диспетчер памяти не будет учитывать её при размещении других объектов. Потеря всех указателей на динамический объект (по завершении их времени жизни или при присваивании им новых значений) приведёт к тому, что освобождение занимаемой объектом памяти станет невозможным — возникнет утечка памяти (memory leak).
Библиотеки, входящие в Microsoft Visual C++, предоставляют механизм отслеживания утечек памяти, позволяющий диагностировать их наличие в программе и способствующий обнаружению в коде программы мест их возникновения.
Суть механизма в следующем. В отладочной версии программы (т. е. при её сборке в конфигурации Debug) функции и операторы выделения и освобождения памяти в куче подменяются их специальными отладочными версиями, которые, в дополнение к непосредственно выделению и освобождению памяти, ведут учёт выделяемых программой блоков памяти. Например, отладочные функции выделения памяти при каждом своём вызове могут помещать в некий глобальный список запись с информацией о выделенном блоке памяти: адрес блока, размер блока, имя файла, в котором осуществлен вызов функции, номер строки в нём и пр. Отладочные функции освобождения памяти, соответственно, могут удалять из этого списка ту запись, которая описывает освобождаемый блок.
Перед самым завершением выполнения программы на основе результатов работы отладочных функций выделения и освобождения памяти (например, если список выделенных блоков памяти не пуст) формируется отчёт по выделенным, но не освобождённым блокам, который отображается в окне Output среды разработки. Этот отчёт для каждого не освобождённого блока включает: номер блока, имя файла и номер строки в этом файле, содержащей вызов функции выделения памяти, адрес блока, его размер и значение начальных ячеек (при двойном щелчке мышью по имени файла осуществляется переход к строке этого файла, содержащей вызов функции выделения памяти). При отсутствии утечек памяти отчёт не выводится.
Подключение к разрабатываемой программе механизма отслеживания утечек памяти осуществляется в два этапа. Сначала в отладочной версии программы нужно выполнить подмену функций для работы с кучей их отладочными версиями. Это делается посредством следующих строк кода:
#ifdef _DEBUG
#define _CRTDBG_MAP_ALLOC
#include <stdlib.h>
#include <crtdbg.h>
#definenewnew(_NORMAL_BLOCK, __FILE__, __LINE__)
#endif |
Хорошим местом для размещения этих строк является файл stdafx.h — стандартный заголовочный файл (header file) создаваемых в среде Microsoft Visual Studio проектов.
| ПРИМЕЧАНИЕ Файл stdafx.h предназначен для подключения часто используемых, но редко изменяемых в процессе разработки приложения заголовочных файлов, в частности, заголовочных файлов стандартной библиотеки C++. На основе stdafx.h строится файл предварительно скомпилированных заголовков (precompiled headers file, .pch-файл), позволяющий существенно сократить время компиляции проекта за счёт исключения необходимости повторной компиляции файлов, подключенных в stdafx.h. |
| ПРИМЕЧАНИЕ Подмену оператора new приведённым выше способом нужно делать после подключения тех классов, которые переопределяют этот оператор: в частности, после подключения файлов стандартной библиотеки iostream, string, list и др. |
После подмены функций работы с кучей для формирования и вывода отчёта об утечках памяти по завершении выполнения программы необходимо в начале функции main поместить код:
#ifdef _DEBUG
_CrtSetDbgFlag(_CRTDBG_ALLOC_MEM_DF /*| _CRTDBG_CHECK_ALWAYS_DF*/ | _CRTDBG_LEAK_CHECK_DF /*| _CRTDBG_DELAY_FREE_MEM_DF*/);
#endif |
Здесь вызов функции _CrtSetDbgFlag также находится внутри блока условной компиляции и, следовательно, будет компилироваться только при условии, что определена символическая константа препроцессора _DEBUG, т. е. только при сборке отладочной версии программы.
Для того чтобы протестировать работу механизма отслеживания утечек памяти, подключите его к программе, рассмотренной в предыдущем разделе. Скомпилируйте отладочную версию этой программы и запустите её из среды разработки. По завершении выполнения программы посмотрите на вывод в окне Output — информации об утечках памяти быть не должно. Закомментируйте в последней строке функции main оператор удаления объекта, адресуемого p1, снова скомпилируйте и запустите программу в режиме отладки. После завершения её работы вновь посмотрите на вывод в окне Output и сравните его с тем, что был во время предыдущего запуска программы.
В рассмотренных нами примерах стиль определения указателей таков: каждый указатель (равно как и любой другой объект) определяется на отдельной строке; символ ‘*’ пишется сразу (без промежуточных пробелов) за названием типа объектов, которые определяемый указатель может адресовать:
int* p;
|
При таком подходе, int* можно трактовать как тип «указатель на int».
Если вы предпочитаете определять более одного объекта в строке, то символ ‘*’ необходимо записывать непосредственно перед определяемым указателем:
int *p;
|
В противном случае, вид определения не будет отражать его сути. В строке
int* p1, p2, p3;
|
указателем является только переменная p1; переменные p2 и p3 — это объекты типа int. Определение трёх указателей в одной строке осуществляется так:
int *p1, *p2, *p3;
|
Брайан Керниган и Деннис Ритчи в книге «Язык программирования C» [2] отмечают, что изначально форма объявления int *p «задумывалась как мнемоническая. Объявление сообщает, что выражение *p имеет тип int. Синтаксис объявления переменной копирует синтаксис выражений, в котором эта переменная может появляться».
Конечно же, у каждой операционной системы своя собственная архитектура памяти, имеющая несколько более сложную модель управления, чем та, что была нами рассмотрена. Однако пока вы не занимаетесь специальными вопросами программирования под конкретную операционную систему и не решаете задачи разделения данных между разными приложениями, рассмотренной модели вполне достаточно.
Что касается операционных систем семейства Microsoft Windows, то архитектура памяти, особенности управления ею, внутреннее устройство кучи и стека, файлы, проецируемые в память, и прочее исчерпывающе описаны в книге Джеффри Рихтера «Windows для профессионалов» [7].
О нетривиальных подходах к управлению памятью, написании собственных диспетчеров памяти для нестандартного размещения объектов конкретных классов, а также об умных, мудрых, гениальных, ведущих и невидимых указателях можно почитать в книге Джеффа Элджера «C++: библиотека программиста» [4], содержание которой более точно отражает английский вариант названия «C++ for Real Programmers».