 Оценка 920
[+2/-0]
Оценка 920
[+2/-0]

 Оценить
Оценить 






| Оценка 920
[+2/-0]
Оценить
|
Пример RegExpTest.zip - 2 KB
Пример RegexNetTest.zip - 11 KB
Словосочетание «регулярные выражения», прямой перевод английского «Regular expressions», звучит довольно неуклюже. Однако оно уже настолько прижилось, что попало в словари, поэтому придется использовать именно его – за неимением лучшего.
Регулярные выражения – это один из способов поиска подстрок (соответствий) в строках. Осуществляется это с помощью просмотра строки в поисках некоторого шаблона. Общеизвестным примером могут быть символы «*» и «?», используемые в командной строке DOS. Первый из них заменяет ноль или более произвольных символов, второй же – один произвольный символ. Так, использование шаблона поиска типа "text?.*" найдет файлы textf.txt, text1.asp и другие аналогичные, но не найдет text.txt или text.htm. Если в DOS использование регулярных выражений было крайне ограничено, то в других местах (то есть операционных системах и языках программирования) они почти достигли уровня высокого искусства. «Почти» потому, что предметы высокого искусства практически невозможно употреблять в повседневной жизни. Более сложным примером применения регулярных выражений может быть удаление мусора, внесенного Microsoft Word при сохранении документа в формате HTML. Разработчики Word умудрились все сделать по-своему, в результате чего HTML-документ порой становится больше исходного DOC-файла за счет огромного количества понятных только IE5 тегов, вычистить которые вручную нет никакой возможности.
Особенно полезны регулярные выражения в программах, написанных на скриптовых (интерпретируемых) языках, например, VBScript, JScript и Perl. Из-за того, что весь их код интерпретируется, разбор текстовых строк и выражений выполняется неприемлемо медленно. Применение регулярных выражений дает значительное увеличение производительности, поскольку библиотеки, интерпретирующие регулярные выражения, обычно пишутся на низкоуровневых высокопроизводительных языках (С, С++, Assembler). Например, в MSDN с помощью регулярных выражений осуществляется динамическое форматирование HTML-страниц:
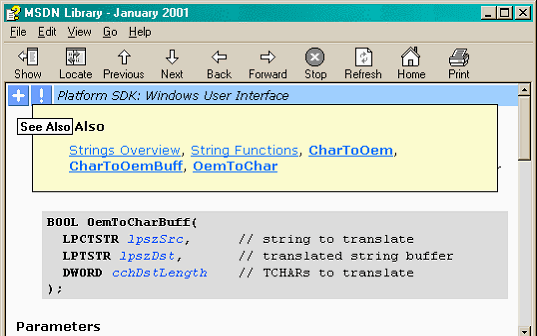
Рис.1. Всплывающее окно See Also создается динамически с помощью регулярных выражений.
Обычно с помощью регулярных выражений выполняются три действия:
Наибольшее развитие регулярные выражения получили в Perl, где их поддержка встроена непосредственно в интерпретатор. В других языках, как правило, используются реализующие регулярные выражения дополнения и модули сторонних разработчиков. В VBScript и JScript используется объект RegExp, в С/С++ можно использовать библиотеки Regex++ и PCRE (Perl Compatible Regular Expression), а также ряд менее известных библиотек, для Java существует целый набор расширений – ORO , RegExp, Rex и gnu.regexp.
Особняком стоит Microsoft Visual Studio.Net, существующая пока только в beta-версии, но уже удостоившаяся массы публикаций и разговоров. Реализация регулярных выражений в .Net (Regex) полностью совместима с Perl, и даже несколько расширена. Все, что говорится про Perl, вполне применимо к .Net.
В составе ATL 7, также входящего в VC.Net, имеется шаблон XXX, который позволяет встраивать регулярные выражения в С++-программы (независимо от CLR). Он доступен в исходных текстах, поэтому его можно довольно просто приспособить к своим надобностям, то есть встроить в него поддержку нужного языка или добавить необходимую функциональность. Этот шаблон по всей видимости, должен оказаться самой быстрой реализацией регулярных выражений, поскольку весь код подставляется компилятором как inline и, соответственно, компилятор может качественно оптимизировать код. Прямая работа с любыми видами строк (вид строки задается в качестве параметра шаблона) также повышает производительность.
Реализации регулярных выражений различаются, однако в целом они очень похожи друг на друга, и, как правило, программист, однажды освоивший использование регулярных выражений, в дальнейшем практически не встречает затруднений.
Синтаксис регулярных выражений до сих пор не полностью стандартизован. Существует POSIX-версия регулярных выражений, полностью описывающая стандарт синтаксиса для POSIX. Но версия Perl шире и более гибка, чем и объясняется ее широкая распространенность. Большинство библиотек по синтаксису и используемым метасимволам совместимо с Perl, поэтому имеет смысл начать разбираться с использованием регулярных выражений на примере именно этого языка.
На практике применяются три типа машин регулярных выражений.
Чаще всего программисты используют традиционные NFA-машины, поскольку они точнее, чем DFA или POSIX NFA. Хотя в наихудшем случае время их работы растет по экспоненте, использование образцов, снижающих уровень неоднозначности и ограничивающих глубину поиска с возвратом (backtracking), позволяет управлять их поведением, уменьшая время поиска до приемлемых значений.
Реально только в синтаксис Perl использование регулярных выражений встроено непосредственно. В остальных языках для этого используются методы классов. Так, например, в C# работа с регулярными выражениями выглядит следующим образом:
Regex re = new Regex("pattern", "options"); MatchCollection mc = re.Matches("this is just one test"); iCountMatchs = mc.Count; |
где re – это новый объект-Regex, в чьем конструкторе передается образец поиска (pattern) и опции (options) (Таблица 1), задающие различные варианты поиска
| Символ | Значение |
|---|---|
| I | Поиск без учета регистра. |
| m | Многострочный режим, позволяющий находить совпадения в начале или конце строки, а не всего текста. |
| n | Находит только явно именованные или нумерованные группы в форме (?<name>…). Значение этого будет объяснено ниже, при обсуждении роли скобок в регулярных выражениях. |
| c | Компилирует. Генерирует промежуточный MSIL-код, перед исполнением превращающийся в машинный код. |
| s | Позволяет интерпретировать конец строки как обыкновенный символ-разделитель. Часто это значительно упрощает жизнь. |
| x | Исключает из образца неприкрытые незначащие символы (пробелы, табуляция и т.д.) и включает комментарии в стиле Perl (#). Есть некоторая вероятность, что к выходу в свет эти комментарии могут исчезнуть. |
| r | Ищет справа налево. |
Сочетание флагов m и s дает очень удобный режим работы, учитывающий концы строк и позволяющий пропустить все незначащие символы, включая символ конца строки.
Ниже приведен пример на VB 6, использующий внешнюю библиотеку VBScript RegExp, поставляемую с MS Scripting Host. Ее можно скачать с сайта Microsoft (или найти vbscript.dll в большинстве его продуктов). Этот пример разбирает строку и помещает найденные вхождения в список List1.
Dim re As New VBScript_RegExp.RegExp Dim matchs As MatchCollection re.Pattern = "pattern" re.Global = True ' для поиска по всему тексту. Set matchs = re.Execute("this is just one test") Dim m As VBScript_RegExp.Match List1.Clear For Each m In matchs List1.AddItem m.Value & " Ndx " & m.FirstIndex & " Len " & m.Length Next |
В других языках все выглядит аналогично.
Perl разделяет составные части определения регулярного выражения символами "/". Выглядит это примерно так:
expression =~ m/pattern/[switches] |
Такое выражение выполняет поиск подстроки, соответствующий шаблону 'pattern' в строке expression и возвращает найденные подстроки ($1, $2, $3, ...). "m" означает "match", т.е. соответствие. Например,
$test = "this is just one test";
$test =~ m/(o.e)/ |
вернет "one" в $1.
Для замены применяется выражение
expression =~ s/pattern/new text/[switches] |
Это выражение, как несложно догадаться, заменяет "pattern" на "new text". Например:
$test = "this is just one test";
$test =~ s/one/my/ |
заменит one на my, в результате давая "this is just my test", сохраняемое в $test.
В Perl используются те же опции, что и в .Net, кроме "n" и "r". В других реализациях библиотек регулярных выражений опций меньше, либо вовсе нет. Так, в приведенном выше примере на VB настройки производятся через свойства объекта RegExp. Ниже примеры будут даваться в основном в стиле Perl.
Я не стану пытаться написать полный справочник по всем символам, используемым в шаблонах регулярных выражений. Для этого есть другие источники. Здесь мы приведем только основные метасимволы.
В двойных кавычках далее будут употребляться значения, выдаваемые регулярными выражениями, а в одинарных – синтаксис регулярных выражений.
В Perl метасимволы, которые вы хотите использовать не как таковые, а как собственно символы, должны быть прикрыты escape-символом \, как в С++ (в других языках может быть иначе, например, в VB это не нужно). То есть, чтобы найти "[", нужно писать '\['. Символ \ означает, что идущий за ним символ – это спецсимвол, константа и так далее. Например, 'n' означает букву "n". '\n' означает символ новой строки. Последовательность '\\' соответствует "\", а '\(' соответствует "(".
Символ '.' соответствует любому символу, кроме '\n' (если не используется опция 's', увы, доступная только в Perl 5-совместимых реализациях). Чтобы найти любой символ, включая \n, используйте что-нибудь вроде '[.\n]'.
Выражением может быть один символ или последовательность символов, заключенных в круглые или квадратные скобки. Особенности использования скобок будут описаны ниже.
Используя квадратные скобки, можно указать группу символов (это называют классом символов) для поиска. Например, конструкция 'б[аи]ржа' соответствует словам «баржа» и «биржа», т.е. словам, начинающимся с «б», за которым следуют «а» или «и», и заканчивающимся на «ржа».
Возможно и обратное, то есть, можно указать символы, которых не должно содержаться в найденной подстроке. Так, '[^1-6]' находит все символы, кроме цифр от 1 до 6. Следует упомянуть, что внутри класса символов '\b' обозначает символ backspace (стирания).
Если неизвестно, сколько именно знаков должна содержать искомая подстрока, можно использовать спецсимволы, именуемые мудреным словом квантификаторы (quantifiers). Например, можно написать "hel+o", что будет означать слово, начинающееся с "He", со следующими за ним одно или несколько "l", и заканчивающееся на "о". Следует понять, что квантификатор относится к предшествующему выражению, а не отдельному символу.
Список квантификаторов вы можете найти в таблице 2.
| Символ | Описание |
|---|---|
| * | Соответствует 0 или более вхождений предшествующего выражения. Например, 'zo*' соответствует "z" и "zoo". |
| + | Соответствует 1 или более предшествующих выражений. Например, "zo+" соответствует "zo" and "zoo", но не "z". |
| ? | Соответствует 0 или 1 предшествующих выражений. Например, 'do(es)?' соответствует "do" в "do" or "does". |
| {n} | n – неотрицательное целое. Соответствует точному количеству вхождений. Например, 'o{2}' не найдет "o" в "Bob",но найдет два "o"' в "food". |
| {n,} | n – неотрицательное целое. Соответствует вхождению, повторенному не менее n раз. Например, 'o{2,}' не находит "o" в "Bob", зато находит все "o" в "foooood". 'o{1,}' эквивалентно 'o+'. 'o{0,}' эквивалентно 'o*'. |
| {n,m} | m и n – неотрицательные целые числа, где n <= m. Соответствует минимум n и максимум m вхождений. Например, 'o{1,3} находит три первые "o" в "fooooood". 'o{0,1}' эквивалентно 'o?'. Пробел между запятой и цифрами недопустим. |
Важной особенностью квантификаторов '*' и '+' является их всеядность. Они находят все, что смогут – вместо того, что нужно. То есть,
$test = "hello out there, how are you";
$test =~ m/h.*o/ |
означает "искать 'h', за которым следует несколько произвольных символов, за которыми следует 'o'". В виду, наверное, имелось "hello", но найдено будет "hello out there, how are yo" – из-за жадности регулярного выражения, ищущего не первую, а последнюю "о". Излечить квантификатор от жадности можно, добавив '?'. То есть,
$test = "hello out there, how are you";
$test =~ m/h.*?o/ |
найдет именно "hello", что и было нужно, поскольку ищет 'h', за которым следует несколько произвольных символов, до первого встреченного 'o'".
Проверка начала или конца строки производится с помощью метасимволов ^ и $. Например, "^thing" соответствует строке, начинающейся с "thing". "thing$" соответствует строке, заканчивающейся на "thing". Эти символы работают только при включенной опции 's'. При выключенной опции 's' находятся только конец и начало текста. Но и в этом случае можно найти конец и начало строки, используя escape-последовательности \A и \Z. Все это относится только к Perl-совместимым реализациям. Остальные же будут искать только конец и начало текста. В .Net имеется еще и символ \z, точный конец строки.
Для задания границ слова используются метасимволы '\b' и '\B'.
$test =~ m/out/ |
соответствует не только "out" в "speak out loud", но и "out" в "please don't shout at me". Чтобы избежать этого, можно предварить образец маркером границы слова:
$test =~ m/\bout/ |
Теперь будет найдено только "out" в начале слова. Не стоит забывать, что ВНУТРИ класса символов '\b' обозначает символ backspace (стирания).
Приведенные в Таблице 3 метасимволы не заставляют машину регулярных выражений продвигаться по строке или захватывать символы. Они просто соответствуют определенному месту строки. Например, ^ определяет, что текущая позиция – начало строки. '^FTP' возвращает только те "FTP", что находятся в начале строки.
| Символ | Значение |
|---|---|
| ^ | Начало строки. |
| $ | Конец строки, или перед \n в конце строки(см. опцию m). |
| \A | Начало строки (ignores the m option). |
| \Z | Конец строки, или перед \n в конце строки (игнорирует опцию m). |
| \z | Точно конец строки (игнорирует опцию m). |
| \G | Начало текущего поиска (Часто это в одном символе за концом последнего поиска). |
| \b | На границе между \w (алфавитно-цифровыми) и \W (не алфавитно-цифровыми) символами. Возвращает true на первых и последних символах слов, разделенных пробелами. |
| \B | Не на \b-границе. |
Символ '|' можно использовать для перебора нескольких вариантов. Использование этого символа совместно со скобками – '(...|...|...)' – позволяет создать группы вариантов. Скобки используются для "захвата" подстрок для дальнейшего использования и сохранения их во встроенных переменных $1, $2, ..., $9.
Например,
$test = "I like apples a lot";
$test =~ m/like (apples|pines|bananas)/ |
сработает, поскольку "apples" – один из трех перечисленных вариантов. Скобки также поместят "apples" в $1 как обратную ссылку для дальнейшего использования. В основном это имеет смысл при замене, см. "Различия синтаксиса регулярных выражений".
Мы уже говорили об одной из важнейших возможностей регулярных выражений – способность сохранения части соответствий для дальнейшего использования. Кстати, избежать этого можно с помощью использования '?:'.
Например,
$test = "Today is monday the 18th.";
$test =~ m/([0-9]+)th/
|
сохранит "18" в $1, а
$test = "Today is monday the 18th.";
$test =~ m/[0-9]+th/ |
ничего не станет сохранять – из-за отсутствия скобок.
$test = "Today is monday the 18th.";
$test =~ m/(?:[0-9]+)th/ |
также ничего не станет сохранять благодаря использованию оператора '?:'.
Следующий пример демонстрирует, как можно использовать эту возможность в операции замены:
$test = "Today is monday the 18th.";
$test =~ s/ the ([0-9]+)th/, and the day is $1/ |
приведет к записи "Today is monday, and the day is 18." в переменную $test.
Можно ссылаться на подстроки, уже найденные данным запросом, используя \1, \2, ..., \9. Следующее регулярное выражение удалит повторяющиеся слова:
$test = "the house is is big";
$test =~ s/\b(\S+)\b(\s+\1\b)+/$1/ |
записывает "the house is big" в $test.
Иногда нужно сказать "найдите вот это, но только если перед ним не стоит вот этого", или "найдите вот это, но только если за ним не стоит вот этого". Пока речь идет об одиночном символе, достаточно воспользоваться [^...].
В более сложном случае придется использовать так называемые lookahead-условия или lookbehind-условия. Не путайте Positive lookahead с оптимистичным взглядом в будущее. Всего есть четыре типа таких условий:
Примеры:
$test = "HTML is a document description-language and not a programming-language";
$test =~ m/(?<=description-)language/ |
Найдет первое "language" ("description-language"), как предваряемое "description-", а
$test = "HTML is a document description-language and not a programming-language";
$test =~ m/(?<!description-)language/ |
Найдет второе "language" ("programming-language").
Следующие примеры выполнены в .Net. Поиск осуществляется в следующем тексте:
void aaa { if(...) { try { ... } catch(Exception e1) { MessageBox.Show(e1.ToString(), "Error"); } finally { listBox1.EndUpdate(); } } } |
Шаблон \{(?=[^\{]*\}).*?\} находит самый глубоко вложенный блок, выделенный фигурными скобками. Результат выполнения:
Шаблон (?<=try\s*)\{(?=[^\{]*\}).*?\} находит самый глубоко вложенный блок выделенный фигурными скобками, перед которым есть try. Результат выполнения: { ... }.
Шаблон (?<!try\s*)\{(?=[^\{]*\}).*?\} находит самый глубоко вложенный блок выделенный фигурными скобками перед которым нет слова try. Результат выполнения:
В этих примерах жирным выделены Lookahead- и Lookbehind-условия.
Вот еще несколько примеров использования регулярных выражений, более приближенных к реальной жизни.
s/(\S+)(\s+)(\S+)/$3$2$1/ |
В других языках замена обычно делается отдельным методом, одним из параметров передается шаблон замены, где можно использовать переменные $1, $2, $3 и т.д.
m/(\w+)\s*=\s*(.*?)\s*$/ |
Здесь имя – в $1, а значение - в $2.
m/(\d{4})-(\d\d)-(\d\d)/ |
Теперь YYYY - в $1, MM - в $2, DD - в $3.
m/^.*(\\|\/) |
В "Y:\KS\regExp\!.Net\Compilation\ms-6D(1).tmp" такое выражение найдет "Y:\KS\regExp\!.Net\Compilation\"
Будучи примененным к файлу С++, выделяет комментарии, строки и идентификаторы "new", "static char" и "const". Работает и на старом RegExp:
("(\\"|\\\\|[^"])*"|/\*.*\*/|//[^\r]*|#\S+|\b(new|static char|const)\b) |
Выделяет тег <a href="…"> в HTML-коде:
<\s*a("[^"]*"|[^>])*> |
Как уже упоминалось выше, регулярные выражения широко используются практически во всех языках программирования. Каждый из языков накладывает свой отпечаток на синтаксис регулярных выражений, хотя суть и не меняется. Так, например, то, что в JScript пишется /a.c/, в VBScript, естественно, будет "a.c".
Microsoft всегда старается сделать все по-своему, поэтому синтаксис регулярных выражений .NET несколько расширен, и включает ряд новых возможностей – например, поиск справа налево. Пишущие по-арабски поймут, зачем это нужно.
| Символ | Значение |
|---|---|
| \w | Слово. То же, что и [a-zA-Z_0-9]. |
| \W | Все, кроме слов. То же, что и [^a-zA-Z_0-9]. |
| \s | Любое пустое место. То же, что и [ \f\n\r\t\v]. |
| \S | Любое непустое место. То же, что и [^ \f\n\r\t\v]. |
| \d | Десятичная цифра. То же, что и [0-9]. |
| \D | Не цифра. То же, что и [^0-9]. |
Кстати, регулярные выражения в .Net умеют понимать русский язык. Особенно интересно и слегка непривычно то, что они делают это корректно. В Help'е сказано, например, что при поиске границы слова с использованием \b работают символы [a-zA-Z_0-9], однако верить этому не следует. На практике это не так. Русские буквы ищутся и находятся не хуже латиницы. Впрочем, может быть, к release-версии все будет приведено к соответствию с Help'ом.
Классы, определяющие регулярные выражения .NET – это часть библиотеки базовых классов Microsoft .NET Framework, что означает одинаковую реализацию регулярных выражений для всех языков и средств, работающих с CLR (Common Language Runtime) – естественно, за вычетом языковых особенностей, типа уже упоминавшихся escape-символов.
В .Net появились условные сравнения (conditional evaluation). Позволяет варьировать используемые шаблоны в зависимости от результатов поиска предыдущего подвыражения. Это заставит, например, пропустить правую скобку, если левая уже была найдена подвыражением. К сожалению, информация об этом пока слишком обрывочна, чтобы говорить об этом подробнее.
Положительный и отрицательный lookbehind. Последние версии Perl поддерживают такую возможность для строк фиксированной длины. У машины регулярных выражений .NET эта возможность не ограничена ничем, кроме здравого смысла.
Кроме перечисленных, есть еще и масса других, менее значительных дополнений и расширений, но перечислять их все нет ни сил, ни желания. Особенно учитывая, что всё может измениться без предупреждения.
Увы, Microsoft традиционно пребывает в состоянии творческого безумия, и правая рука у него не знает, что делает левая (подробнее об этом см. "Средства программирования). Поэтому в саму среду Microsoft .Net встроена ДРУГАЯ библиотека регулярных выражений. Если они это изменят до выхода финальной версии (все, что вы здесь читаете, написано на базе beta 1), честь им и хвала. Если же не изменят (например, по забывчивости), разработчикам, скорее всего, придется работать по принципу "одним пользуемся, другое продаем".
По умолчанию Regex компилирует регулярные выражения в последовательность внутренних байт-кодов регулярных выражений (это высокоуровневый код, отличный от Microsoft intermediate language (MSIL)). При исполнении регулярных выражений байт-код интерпретируется.
Если же конструировать объект Regex с опцией 'с', он компилирует регулярные выражения в MSIL-код вместо упомянутого байт-кода. Это позволяет JIT-компилятору Microsoft .NET Framework преобразовать выражение в родные машинные коды для повышения производительности.
Но сгенерированный MSIL нельзя выгрузить. Единственный способ выгрузить код – это выгрузить из памяти приложение целиком. Это значит, что занимаемые скомпилированным регулярным выражением ресурсы нельзя освободить, даже если сам объект Regex уже освобожден и уничтожен сборщиком мусора.
Из-за этого казуса приходится задумываться – стоит ли компилировать регулярные выражения с опцией 'с', и если да, то какие и сколько. Если приложение должно постоянно использовать множество регулярных выражений, придется обойтись интерпретацией. А вот если есть несколько постоянно используемых регулярных выражений, можно и скомпилировать их для ускорения работы.
Для повышения производительности Regex кэширует в памяти все регулярные выражения. Поэтому повторного разбора при каждом очередном использовании не происходит. Такой подход несколько уменьшает разницу в производительности компилируемых и интерпретируемых регулярных выражений.
В качестве примера использования регулярных выражений мы создали .Net-приложение, использующее регулярные выражения для поиска в тексте.
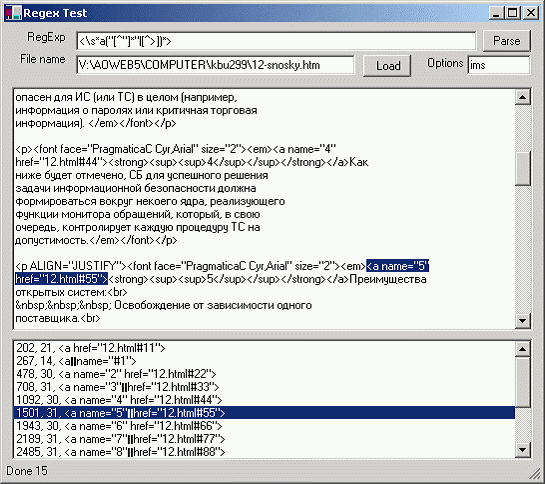
Рис.2. Приложение RegExpTest
Мода – великая вещь, поэтому писать приложение следует не на Java, не на VB, а на C#. Это модно, и доказывает, что автор не стоит на месте, а работает над собой.
Отрывки кода этого примера приведены в Листинге 1. Само приложение можно скачать с нашего ftp-сайта.
Листинг 1. Использование регулярных выражений в C#
// Класс для хранения информации о найденном вхождении protected class MyItem { public MyItem(string Match, int Index, int Len) { this.Match = Match; this.Index = Index; this.Len = Len; } public override string ToString() { return Index.ToString() + ", " + Len.ToString() + ", " + Match; } public string Match; public int Index; public int Len; } ... protected void Parce() { int iCountMatchs = 0; try { // Очищаем лист-бокс listBox1.Items.Clear(); statusBar1.Text = "Parsing..."; // создаем объект re, задавая в его конструкторе // шаблон и опции Regex re = new Regex(tbPattern.Text, tbOptions.Text); // Выполняем поиск заданного выше шаблона внутри // текста и текстового поля tbTextForSearch MatchCollection mc = re.Matches(tbTextForSearch.Text); iCountMatchs = mc.Count; // Выводим информацию о количестве найденных вхождений... statusBar1.Text = "Load list (" + iCountMatchs.ToString() + ")..."; // ...и заносим информацию о них в лист-бокс. listBox1.BeginUpdate(); foreach(Match m in mc) { // Для хранения информации о найденном вхождении // мы используем созданный нами класс MyItem. // Элементы управления (типа лист-бокса) в .Net // позволяют хранить вместо текстового значения // объект, а при отображении текста в строке вызывают // метод - ToString. Так что объект любого класса, // реализующего метод ToString, может выступать в // качестве элемента лист-бокса. listBox1.Items.Add(new MyItem(m.ToString(), m.Index, m.Length)); } } catch(Exception e1) { MessageBox.Show(e1.ToString(), "Error"); } finally { listBox1.EndUpdate(); statusBar1.Text = "Done " + iCountMatchs.ToString(); } } |
Это только краткое ведение в регулярные выражения и их использование. Если вы хотите лучше разобраться в этом, попробуйте потренироваться в создании регулярных выражений самостоятельно. Практика показывает, что разбор чужих регулярных выражений практически бесполезен, читать их почти невозможно. Однако лучше научиться пользоваться ими – это часто упрощает жизнь.
| Оценка 920
[+2/-0]
Оценить
|
