Особенностью алгоритма РРМ является то, что его контекстная модель явно разделена на независимые части. Этими частями является модели контекстных порядков, которые не имеют каких бы то ни было жестких связей друг с другом. Каждый контекстный порядок в РРМ хранит и анализирует информацию для контекстов только определенной и строго фиксированной длинны, и не использует информацию других контекстных порядков, за исключением случаев применения специальных методов улучшения сжатия, таких например, как наследование информации.
Кодирование каждого символа в РРМ осуществляется путем последовательного опроса всех моделей порядков на возможность оценки вероятности появления этого символа в текущем контексте. В РРМ под контекстом понимается цепочка символов, стоящая перед взятым символом в потоке кодируемых данных. Если символ не может быть оценен на текущем порядке, происходит переход на более низкий порядок, и так далее, до тех пор, пока символ не будет закодирован, а это обязательно должно произойти, поскольку последний из опрашиваемых порядков строится так, чтобы кодировать все символы, пришедшие к нему. Порядки обозначают по числу символов в контексте, с которым они работают. Так, например, контекстный порядок order5 рассматривает только контексты, содержащие 5 символов. Самый младший порядок, кодирующий символы, впервые появившиеся в текущем сеансе работы кодека, обозначают order_static. Разница в числе символов в контексте у соседних порядков равна единице. В общем случае, при кодировании или декодировании каждого символа, алгоритм РРМ начинает опрашивать контекстные порядки, начиная с самого старшего порядка. Если применяется механизмом оценки локального порядка (LOE), то начальный порядок может и не иметь наибольший контекст.
Контекстная модель РРМ, которая имеет все контекстные порядки, начиная с установленного старшего порядка и кончая порядком order_static, можно условно назвать "полной". Если создать контекстную модель, из которой будут исключены некоторые контекстные порядки, то есть разница в длине контекста для некоторых соседних порядков не будет равняться единице, то такую модель можно условно назвать "неполной". Соответственно кодеки, построенные на таких моделях можно назвать "полными" и "неполными". Эта терминология для краткости и используется в этой работе. Цель данной работы – выяснить, дает ли какое-либо преимущество использование неполных РРМ-кодеков в сравнении с полными.
Оценка неполных кодеков
Обычно кодеки, использующие те или иные алгоритмы сжатия, принято оценивать по трем основным критериям: степени сжатия, требованиям к ресурсам и скорости работы. Неполные кодеки РРМ являются своего рода модификацией полных РРМ-кодеков, поэтому их стоит оценивать не отдельно, а в сравнении с этими кодеками. Таким образом, для оценки неполных РРМ-кодеков можно сформулировать три основных вопроса:
Можно ли увеличить компрессию, используя неполный кодек вместо полного, и насколько это эффективно?
Можно ли уменьшить размеры запрашиваемых ресурсов, используя эти кодеки?
Получается ли выигрыш по времени при кодировании и декодировании, если кодек содержит пропуски контекстных порядков?
Поиском ответов на эти вопросы и посвящена эта работа.
Обозначение неполных кодеков
Будем обозначать полный РРМ-кодек, который имеет ограничения на максимальную возможную длину контекста равную М, как OrderM. Значение М в этом кодеке также задает число контекстных порядков, если не учитывать порядки order0 и order_static.
Обозначим как OrderP(M)[L] неполный кодек, где Р – число порядков модели без учета order_static и order0, М – максимально возможная длинна контекста, L – список контекстных порядков, задающийся в квадратных скобках. Список порядков также не включает порядки order_static и order0, поскольку эти порядки всегда входят в любой из рассматриваемых в этой работе неполных кодеков. Например, обозначение Order3(5)[12 5] задает кодек, с максимальной длиной контекста, равной 5 и состоящего из 3 контекстных порядков order1, order2, order5, дополнительно к порядкам order0 и order_static.
Неполный кодек можно представить в более компактном виде, если вместо списка порядков поставить ключ, каждый бит которого указывает наличие или отсутствие того или иного порядка, начиная с order1. Используя этот ключ, можно обозначить неполный кодек как OrderP(M)K, где К есть ключ порядков. В предлагаемой в этой работе реализации левые биты этого ключа содержат младшие порядки, то есть ключ читается справа налево. Таким образом, кодек Order3(5)[12 5] будет обозначаться как Order3(5)19, где десятичное число 19 (в бинарном виде 10011) говорит о включении только порядков, имеющих длину контекста равную 1, 2 и 5 символов.
Создание неполного кодека
Чтобы создать РРМ-кодек, поддерживающий неполную контекстную модель, была использована библиотека PPMtc [1], разработанная автором. Эта библиотека представляет собой набор шаблонных классов языка С++ для построения РРМ-кодеков, использующих различные способы вычисления кода ухода и методы улучшения компрессии.
С помощью этой библиотеки был построен шаблон класса универсального кодека T_ppm_universal_codec. Особенностью этого класса является возможность на его основе создавать любые кодеки, имеющие максимальные порядки от 1 до 10-го. При этом этот же класс позволяет создавать и неполные кодеки, в которых наличие или отсутствие определенных контекстных порядков регулируется описанным выше ключом.
Так выглядит определение этого класса:
template<typename T,typename Tcoder,typename Texec,int Torder_num>
class T_ppm_universal_codec
{
public:
typedef T_symbol_node<T> T_node; // тип структуры символаtypedef T_entry_cnt<T_node,T> T_symb_cnt; // тип контейнера структур символов typedef T_cntxt_info_hi<T,T_c3> T_info3; // тип контекста order3 typedef T_entry_cnt<T_info3,T > T_cntx3_cnt;// тип контейнера контекстов order3
...
typedef T_cntxt_info_hi<T,T_c10> T_info10; // тип контекста order10 typedef T_entry_cnt<T_info10,T> T_cntx10_cnt;// тип контейнера контекстов order10protected:
T_ppm_generic_algo<Tcoder,Texec> m_algo; // обобщенный PPM algorithm
T_ppm_order_base<Tcoder,Texec>* m_orders[E_max_order_num]; // массив порядков
Tcoder* m_freq_coder; // частотный кодировщик
Texec* m_exec; // объект исполнительной модели
T_ppm_properties m_props; // установки кодека
unsigned short m_orders_key; // ключ включенных порядков
T_symb_cnt *m_symbs_o2; // контейнер структур символов порядка order2
T_symb_cnt *m_symbs_o3; // контейнер структур символов порядка order3
T_cntx3_cnt *m_cntxs_o3; // контейнер структур контекста порядка order3
...
T_symb_cnt *m_symbs_o10; // контейнер структур символов порядка order10
T_cntx10_cnt *m_cntxs_o10; // контейнер структур контекста порядка order10
T_ppm_universal_codec(int order_num, // общее число порядков
unsigned short key, // ключ порядков
T_ppm_settings& s, // установки
Tcoder* freq_coder, // частотный кодировщик
Texec* exec, // объект исполнительной модели
T cnt_capacity, // емкость контейнеров
bool fixed) // фиксированные ли контейнеры
...
};
Параметрами шаблона этого класса являются: тип контейнера для хранения структур описания символов и контекстов, тип кодека, тип исполнительного объекта, а также максимальное значение порядка. Класс содержит следующие объекты (их реализацию можно найти в библиотеке PPMtc): обобщенный алгоритм, массив контекстных порядков, указатель на частотный кодировщик, указатель на исполнительный объект, структуру базовых установок кодека и указатели на контейнеры для хранения структур символов и контекстов для всех порядков.
Каждый бит ключа соответствует определенному контекстному порядку. Самый младший бит - первому порядку, второй справа бит – второму порядку, и так далее. Поскольку в PPMtc максимально возможно создавать кодеки до десятого порядка включительно, ключ порядков может принимать значения от 1 до 1023. Десять ключей, такие как 1, 3, 7, 15, 31, 63, 127, 255, 511 и 1023 задают полные РРМ кодеки, соответственно с 1-го по 10-ый порядки. Остальные 1013 ключей задают неполные РРМ кодеки, содержащие пропуски одного или нескольких контекстных порядков.
Инициализация порядков с использованием ключа происходит в конструкторе класса T_ppm_universal_codec следующим образом:
m_orders[0] = new T_ppm_order_static<Tcoder,Texec>(m_props);// создается order_static
m_orders[1] = new T_ppm_order_0<Tcoder,Texec>(m_props); // создается order0if(m_orders_key & 0x1) // создается order1
m_orders[ind++] = new T_ppm_order_1<Tcoder,Texec>(m_props);
if(m_orders_key & 0x2) // создается order2
{
// создаем контейнер структур описания символа для order2
m_symbs_o2 = new T_symb_cnt(cnt_capacity,fixed);
m_orders[ind++] = new T_ppm_order_2<T,Tcoder,Texec>(m_props,*m_symbs_o2);
}
if(m_orders_key & 0x4) // создается order3
{
// создаем контейнер структур описания символа для order3
m_symbs_o3 = new T_symb_cnt(cnt_capacity,fixed);
// создаем контейнер структур описания контекста для order3
m_cntxs_o3 = new T_cntx3_cnt(cnt_capacity,fixed);
m_orders[ind++] = new
T_ppm_order_hi<T,Tcoder,Texec,T_c3>(m_props,*m_symbs_o3,*m_cntxs_o3);
}
...
if(m_orders_key & 0x200) // создается order10
{
// создаем контейнер структур описания символа для order10
m_symbs_o10 = new T_symb_cnt(cnt_capacity,fixed);
// создаем контейнер структур описания контекста для order10
m_cntxs_o10 = new T_cntx10_cnt(cnt_capacity,fixed);
m_orders[ind++] = new
T_ppm_order_hi<T,Tcoder,Texec,T_c10>(m_props,*m_symbs_o10,*m_cntxs_o10);
}
// инициализация обобщенного алгоритма PPM
m_algo.init(m_orders,order_num+2,m_freq_coder,m_exec);
Реализация функций кодирования и декодирования аналогична реализации этих функций в библиотеке РРМtc:
// Функция компрессирования данных// in - входной поток несжатых данных // in_size - размер несжатых данных в потоке// out - выходной поток сжатых данных // returns: число байт, скопированных в выходной поток int encode(T_bytestream& in,int in_size,T_bytestream& out)
{
m_props.reset();
int result=m_algo.encode(in,in_size,out);
if(result<1)
return result;
return out.get_pos();
}
// Функция декомпрессирования данных// in - входной поток сжатых данных // in_size - размер сжатых данных в потоке// out - выходной потока несжатых данных // returns: число байт, скопированных в выходной потокint decode(T_bytestream& in,int out_size,T_bytestream& out)
{
m_props.reset();
unsigned int start_out = out.get_pos();
m_algo.decode(in,out_size,out);
return out.get_pos()-start_out;
}
Чтобы точно подсчитать размеры необходимой для работы кодека памяти, класс T_ppm_universal_codec содержит специальную функцию подсчета памяти get_used_memory().
Реализация ее выглядит следующим образом:
unsigned long get_used_memory()
{
unsigned long mem;
mem = sizeof(T_ppm_generic_algo<Tcoder,Texec>)+
sizeof(T_ppm_order_static<Tcoder,Texec>)+
sizeof(T_ppm_order_0<Tcoder,Texec>)+sizeof(Texec);
// подсчет памяти для order1if(m_orders_key & 0x1)
mem+= sizeof(T_ppm_order_1<Tcoder,Texec>);
// подсчет памяти для order2if(m_orders_key & 0x2)
{
mem+=sizeof(T_ppm_order_2<T,Tcoder,Texec>);
if(m_symbs_o2->is_fixed())
mem+=sizeof(T_node)*m_symbs_o2->get_init_size();
else
mem+=sizeof(T_node)*m_symbs_o2->size();
}
...
// подсчет памяти для order10if(m_orders_key & 0x200)
{
mem+=sizeof(T_ppm_order_hi<T,Tcoder,Texec,T_c10>);
if(m_symbs_o10->is_fixed())
mem+=sizeof(T_node)*m_symbs_o10->get_init_size()+
sizeof(T_cntx10_cnt)*m_cntxs_o10->get_init_size();
else
mem+=sizeof(T_node)*m_symbs_o10->size()+
sizeof(T_cntx10_cnt)*m_cntxs_o10->size();
}
return mem;
}
Реализация шаблона класса T_ppm_universal_codec находится в прилагаемом к этой работе файле tc_ppm_universal_codec.h.
Создание кодека с использованием класса T_ppm_universal_codec выглядит так:
// установки кодека
T_ppm_settings Settings={4,8000,8,2000,3};
// определение объекта исполнительной модели, вычисляющего код ухода по методу PPMD+typedef T_exec_model_PPMDp_full T_exec;
// определение кодекаtypedef T_ppm_universal_codec<unsigned long,T_rangecoder,T_exec,10> T_codec;
// частотный кодировщик
T_rangecoder range;
int order_num = 0;
// подсчет по ключу Key числа порядков модели без учета order_static и order0unsigned int mask = 0x1;
for(int i=1;i<=10;++i)
{
if(Key & mask)
++order_num;
mask=mask<<1;
}
// создается объект исполнительной модели
T_exec* exec = new T_exec(order_num,Settings);
// создание кодека
T_codec* codec = new T_codec(order_num,Key,Settings,&range,exec,1024,false);
// кодированиеint encoded_size = codec->encode(stream_in, plain_file_size,stream_out);
Тестирование
Для создания кодеков использовался объект исполнительной модели T_exec_model_PPMDp_full из библиотеки PPMtc, который реализует вычисление кода ухода по методу D+, поддерживает LOE и метод увеличение веса при инициализации. Настройки кодека, такие как шаг изменения счетчика частот, максимальная возможная частота для символа и другие, брались в точности те, что использовались при тестировании полных кодеков в библиотеке PPMtc. В зависимости от ограничения, накладываемого на память, использовались кодеки с двумя типами контейнеров:
контейнеры без ограничения памяти;
контейнеры имеющих фиксированное число записей равное 216-1;
Для тестирования кодеков был задействован шаблон codec_test() из библиотеки PPMtc, который последовательно запускает функцию кодирования и декодирования для каждого файла из пакета тестирования, собирая при этом информацию о степени компрессии, скорости работы кодека, а также о величине используемой памяти. Все информация выдается на экран и в специальный файл результатов тестирования.
Так же как при тестировании библиотеки PPMtc были использованы пакеты тестов с сайта Archive Comparison Test (A.C.T.) [2] :
Calgary Corpus (вариант Large), 18 файлов, общим размером 3251493 байта;
ТЕХТ, 3 файла, файлов, общим размером 4920277 байт;
GRAPHICS, 8 файлов, общим размером 12466304;
EXECUTABLE, 3 файла, общим размером 4938680 байт;
SOUND, 2 файла, общим размером 8702392 байт;
В качестве платформы для сравнения скорости работы полных и неполных РРМ кодеков был выбран нетбук на базе процессора Intel Atom N450 1.66GHz с 2Gbyte оперативной памяти и с операционной системой Windows 7 Starter.
Тестирование компрессии на пакете Calgary Corpus
По результатам тестирования степени сжатия всех 1013 неполных кодеков на пакете Calgary Corpus можно выдвинуть несколько предположений.
Предположение 1. Среди неполных кодеков, имеющих одинаковое число порядков, наилучшие значения компрессии показывают кодеки, у которых пропуск контекстных порядков находится только в середине. Кодеки, которые содержат чередование пропуска и наличие порядков, в большинстве случаев им уступают. Но наихудшие результаты имеют кодеки, у которых отсутствуют младшие контекстные порядки.
Вот несколько примеров результатов компрессии для неполных кодеков.
Для неполных кодеков, содержащих 3 порядка, с максимальной длинной контекста равной 5:
Order3(5)[12 5] – 72.281% – пропуск порядков в середине;
Согласно этому предположению, чтобы найти наилучший неполный кодек, нет нужды перебирать все варианты неполных кодеков. Достаточно рассмотреть небольшое их подмножество, состоящее из кодеков, содержащих пропуски одного или нескольких порядков только в середине. В Таблице 1 приведены ключи лучших неполных кодеков в зависимости от выбранного максимального порядка и числа контекстных порядков.
Max порядок
Ключи лучших неполных кодеков, по числу входящих в них порядков
1
2
3
4
5
6
7
8
9
2
2
3
4
5
4
8
9
11
5
16
17
19
23,27
6
32
33
35
39,51
47,55,
59
7
64
65
67
71,99
79,103,
115
111,95,
119,123
8
128
129
131
135,195
143,199,
227
175,207,
159,243
223,239,
191,247,
251
9
256
257
259
263,387
271,391,
451
287,399,
455,483
319,415,
463,487,
499
383,447,
479,495,
503,507
10
512
513
515
519
527,775,
899
543,783,
903,963
575,799,
911,967,
995
639,831,
927,975,
999,1011
767,895,
959,991,
1007,1015,
1019
Таблица 1. Ключи лучших неполных кодеков
Далее кодеки из Таблицы 1 для краткости будут называться "лучшими неполными кодеками".
Предположение 2. Степени сжатия лучших неполных кодеков, имеющих одинаковое количество порядков, близки по своему значению и возрастают до определенного порядка при увеличении максимального порядка.
Например, неполные кодеки порядка 1, такие как Order1(2)[2], Order1(3)[3], Order1(4)[4], ... Order1(10)[10] выдают одинаковое сжатие, равное 58.484%.
Неполные кодеки, порядка 4, такие как Order4(5)[1235], Order4(6)[1236], Order4(7)[1237], Order4(8)[1238], Order4(9)[1239], Order4(10)[12310] выдают одинаковое сжатие равное 74.194%.
Неполные кодеки порядка 6, такие как Order6(7)[123467], Order6(8)[123478], Order6(8)[123468], Order6(9)[123489], Order6(10)[1234910], выдают одинаковое сжатие равное 74.816%.
Значение компрессии для кодеков Order8(9)[12345789], Order8(10)[123458910], Order9(10) [1234578910] равны соответственно 74.791%, 74.871% и 74.768.
Предположение 3. Значение лучшей компрессии для неполных кодеков определенного порядка, больше или равно значению компрессии для полных кодеков с тем же числом порядков.
В Таблице 2 приведены результаты сравнения полных и лучших неполных кодеков с тем же числом порядков по степени сжатия на наборе Calgary Corpus.
Число порядков
Сжатие полного, %
Сжатие лучшего неполного,%
Ключи лучших неполных кодеков.
1
58.484
58.484
4,8,16,32,64,128,256,512
2
67.114
67.115
5,9,17,33,65,129,257,513
3
72.281
72.281
11,19,35,67,131,259,515
4
74.194
74.194
23,39,71,134,263,519
5
74.661
74.661
47,79,143,271,527
6
74.734
74.816
111,175,207,399,783
7
74.713
74.838
463,911
8
74.699
74.871
927
9
74.675
74.768
991
10
74.652
-
-
Таблица 2 Сравнение полных и неполных кодеков по степени сжатия на наборе Calgary Corpus.
Согласно Таблице 2 лучшие неполные кодеки не уступают полным кодекам с тем же числом порядков. Самые лучшие результаты компрессии выделены полужирным шрифтом.
Предположение 4. Самую сильную компрессию следует искать у неполных кодеков, у которых число порядков равно или больше числа порядков полного кодека, показавшего наилучшие результаты сжатия.
Среди всех протестированных на пакете Calgary Corpus 1013 неполных кодеков нашлось чуть больше 20 кодеков, которые превзошли или повторили лучший результат сжатия этого пакета, показанный полным кодеком Order6. В Таблице 3 приведен список этих кодеков, отсортированных по величине компрессии.
Таблица 3. Кодеки, повторившие или превзошедшие лучший результат кодека Order6 при сжатии пакета Calgary Corpus.
Согласно Таблице 3, чтобы конкурировать с лучшим полным кодеком, число порядков неполного кодека должно быть, по крайней мере, не меньше, чем у полного кодека. Кодек с самым плотным сжатием с ключом 927 (Order8(10)[12345 8910]) превзошел лучший полный кодек на 0.137%.
Тестирование отдельных файлов из пакета Calgary Corpus
В Таблице 4 приведены результаты сжатия лучшего неполного кодека Order8(10)927 для каждого файла пакета Calgary Corpus в сравнении с полным кодеком, имеющим тоже число контекстных порядков Order8.
Файл
Сжатие полного k=255, %
Сжатие неполного k=927,%
Разница,%
bib
77.311
77.461
0.150
book1
71.290
71.696
0.406
book2
75.859
76.062
0.203
geo
43.360
43.367
0.007
news
70.742
70.889
0.147
obj1
52.446
52.488
0.042
obj2
70.176
70.132
-0.044
paper1
71.033
71.120
0.087
paper2
71.328
71.513
0.185
paper3
67.837
67.977
0.140
paper4
64.098
64.180
0.082
paper5
62.590
62.615
0.025
paper6
69.991
70.059
0.068
pic
90.183
90.229
0.046
progc
70.407
70.453
0.046
progl
80.295
80.328
0.033
progp
79.437
79.453
0.016
trans
82.821
82.853
0.032
Все вместе
74.699
74.871
0.172
Таблица 4. Сравнение полного и неполного кодека с тем же числом порядков для каждого файла из Calgary Corpus
Согласно Таблице 4, несмотря на то, что неполный кодек k=927 показал лучшие результаты при сжатии всего пакета Calgary Corpus, отдельные файлы он сжимает хуже, чем полный кодек Order8 (для него ключ k=255) с тем же числом контекстных порядков. Например, файл obj2 при сжатии неполным кодеком занимает больше места, чем при сжатии полным.
Отдельно сжимая каждый файл из пакета Calgary Corpus различными неполными кодеками, можно определить какие кодеки лучше всего сжимают эти файлы. В таблице 5 приведен список неполных кодеков, которые дают наибольшее сжатие для каждого отдельного файла пакета Calgary Corpus. Кодек k=927 является лучшим только для 3 файлов из этого пакета.
Таблица 5. Лучшие кодеки для каждого файла пакета Calgary Corpus
Согласно Таблице 5 можно сделать вывод, что универсального неполного кодека, который одинаково хорошо сжимает все типы данных (а пакет Calgary Corpus содержит файлы с различными типами данных) не существует. Следовательно, можно сформулировать ее одно предположение.
Предположение 5. Для каждого типа данных можно найти свой неполный кодек, который сжимает данные наилучшим образом, такой, что результат его сжатия будет, по крайней мере, не хуже, чем у полного кодека.
Проверка выдвинутых предположений на других пакетах
В Таблице 6 приведены результаты сравнения по степени сжатия полных и лучших неполных кодеков с тем же числом порядков на наборе ACT TEXT.
Число порядков
Сжатие полного, %
Сжатие лучшего неполного,%
Ключи лучших неполных кодеков.
1
55.507
55.507
512
2
64.927
64.927
513
3
73.205
73.205
515
4
77.688
77.688
519
5
79.445
79.445
527
6
80.164
80.217
783
7
80.472
80.553
799
8
80.602
80.745
927
9
80.653
80.735
991
10
80.672
-
-
Таблица 6. Сравнение полных и лучших неполных кодеков на ACT TEXT.
Тестирование ACT TEXT показало, что предположения 1,2 и 3 верны и для этого пакета. А вот Предположение 4 не работает: лучшие неполные кодеки для этого набора имеют 8 контекстных порядков, а лучший полный – 10. Поэтому Предположение 4 следует изменить следующим образом: самую сильную компрессию следует искать у тех неполных кодеков, у которых число контекстных порядков незначительно (в пределах двух порядков в ту или иную сторону) отличается от числа порядков полного кодека, показавшего наилучшие результаты сжатия.
Лучший неполный кодек order8(10)[123458910] превосходит полный кодек всего на 0.073%. Эта разница достаточно мала, но если обратиться к компрессии отдельных файлов, то согласно Таблице 7 файлы 1musk10.txt и anne11.txt из пакета ACT TEXT имеют преимущество в компрессии больше половины процента, и только на файле world95.txt неполный кодек уступает полному. Но если вместо кодека order8(10)927 использовать кодек order9(10)959, то компрессия для этого файла будет 84.025%, что выше, чем сжатие у полного кодека.
Файл
Сжатие полного к=255, %
Сжатее неполного к=927, %
Разница,%
1musk10.txt
76.213
76.780
0.667
anne11.txt
73.493
74.004
0.632
world95.txt
84.088
83.852
-0.063
Таблица 7. Сравнение полного и лучшего неполного кодека при сжатии каждого файла из ACT TEXT
В Таблице 8 приведены результаты сравнения полных и лучших неполных кодеков с тем же числом порядков по степени сжатия на наборе ACT EXEC.
Число порядков
Сжатие полного, %
Сжатие лучшего неполного,%
Ключи лучших неполных кодеков.
1
41.627
41.627
512
2
52.424
52.424
513
3
56.604
56.604
515
4
58.060
58.060
519
5
58.730
58.730
527
6
59.030
59.048
783
7
59.131
59.149
799
8
59.199
59.224
927
9
59.228
59.251
959
10
59.247
-
-
Таблица 8. Сравнение полных и неполных кодеков на наборе ACT EXEC
При тестировании на этом пакете нашлось всего три неполных кодека, которые смогли сравняться или превзойти лучший полный кодек по степени сжатия, когда как при тестировании на пакете Calgary Corpus таких кодеков было больше двадцати. Разница компрессии лучшего неполного кодека Order9(10)959 с ним очень незначительна и равна всего 0.004%.
Все выдвинутые предположения были подтверждены при тестировании на этом пакете.
В Таблице 9 приведены результаты сравнения по степени сжатия полных и лучших неполных кодеков с тем же числом порядков на наборе ACT GRAPH.
Число порядков
Сжатие полного, %
Сжатие лучшего неполного,%
Ключи лучших неполных кодеков.
1
36.432
36.432
512
2
52.625
52.625
513
3
59.802
59.802
515
4
60.376
60.376
519
5
60.398
60.398
527
6
60.400
60.443
903
7
60.501
60.572
967
8
60.531
60.594
975
9
60.532
60.571
1007
10
60.548
-
-
Таблица 9. Сравнение полного и лучшего неполного кодека на ACT GRAPH
Для этого пакета тестов разница лучшего неполного Order8(10)975 и полного кодека очень мала и равна 0.046%. При тестировании на этом пакете также подтвердились все выдвинутые ранее предположения.
Тестирование с использование ресурсных ограничений
Для этого тестирования использовались неполные кодеки типа PPMD+mem1 из библиотеки PPMtc, которые имеют ограничение на максимальное число хранимых в контейнерах структур описаний символов и контекстов, равное 216-1 записям.
В таблицах 10-14 приведены результаты сравнения по степени сжатия полных и лучших неполных кодеков с тем же числом порядков и с ограничениями по памяти на различных тестовых наборах. Жирным шрифтом выделены наилучшие результаты компрессии.
Число порядков
Сжатие полного, %
Сжатие лучшего неполного, %
Ключи лучших неполных кодеков.
2
67.114
67.115
513
3
72.280
72.280
515
4
74.124
74.128
71
5
74.554
74.553
79
6
74.646
74.691
399
7
74.657
74.721
799
8
74.674
74.775
927
9
74.670
74.736
991
10
74.663
-
-
Таблица 10. Сравнение сжатия полных и лучших неполных кодеков с ограничениями по памяти на пакете Calgary Corpus.
Число порядков
Сжатие полного, %
Сжатие лучшего неполного, %
Ключи лучших неполных кодеков.
3
73.123
73.117
515
4
77.053
77.079
519
5
78.544
78.552
527
6
79.230
79.221
543
7
79.554
79.545
799
8
79.680
79.753
927
9
79.777
79.873
895
10
79.841
-
-
Таблица 11. Сравнение сжатия полных и лучших неполных кодеков с ограничениями по памяти на пакте ACT TEXT.
Число порядков
Сжатие полного, %
Сжатие лучшего неполного, %
Ключи лучших неполных кодеков.
3
55.210
55.037
515
4
56.150
56.168
519
5
56.805
56.843
527
6
57.338
57.302
543
7
57.637
57.692
799
8
57.793
57.886
927
9
57.956
57.897
895
10
58.003
-
-
Таблица 12. Сравнение сжатия полных и лучших неполных кодеков с ограничениями по памяти на пакте ACT EXEC.
Число порядков
Сжатие полного, %
Сжатие лучшего неполного, %
Ключи лучших неполных кодеков.
3
57.638
57.722
515
4
59.067
59.037
519
5
59.344
59.414
527
6
59.529
59.583
783
7
59.719
59.728
799
8
59.769
59.790
975
9
59.759
59.776
1007
10
59.804
-
-
Таблица 13. Сравнение сжатия полных и лучших неполных кодеков с ограничениями по памяти на пакте ACT GRAPH.
Число порядков
Сжатие полного, %
Сжатие лучшего неполного, %
Ключи лучших неполных кодеков.
3
12.471
12.608
515
4
12.466
12.405
771
5
12.435
12.499
775
6
12.396
12.492
963
7
12.415
12.502
995
8
12.413
12.509
999
9
12.421
12.441
959
10
12.421
-
-
Таблица 14. Сравнение сжатия полных и лучших неполных кодеков с ограничениями по памяти на пакте ACT WAV.
Согласно приведенным выше таблицам, при использовании контейнеров с ограничениями по числу записей не всегда лучшие неполные кодеки превосходят полные с тем же числом порядков. Также для тестов ACT EXEC и ACT GRAPH не один из неполных кодеков не смог превзойти результат сжатия кодека Order10.
Поэтому предположение 3 следует немного изменить: Значение лучшей компрессии для неполных кодеков определенного порядка в большинстве случаев больше или равно значению компрессии для полных кодеков с тем же числом порядков. При использовании ограничений на память лучшие неполные кодеки могут уступать полным кодекам.
Подводя итог тестирования на степень сжатия различных пакетов неполными кодеками, можно заключить, что для каждого пакета или типа данных можно подобрать такой неполный кодек, который будет сжимать данные лучше, чем полный. Но при этом величина этого улучшения будет не очень высокой. Наилучшие результаты показали неполные кодеки при сжатии пакета Calgary Corpus и ACT WAV, где в обоих случая компрессия улучшилась на 0.137%. При сжатии отельных файлов, лучшие результаты неполные кодеки показали на текстовом файле 1musk10.txt пакета ACT TEXT, улучшив сжатие на 0.667%.
Влияние неполных кодеков на распределение числа кодирований символов по порядкам
Использование неполных кодеков приводит к перераспределению числа кодирований на каждом из порядков. Можно заметить, что для алгоритма РРМ характерно то, что чем чаще происходит кодирование на старших порядках, тем плотнее будет результат кодирования. В общем случае, определить то, как скажется отсутствие одного или нескольких порядков на числе кодирований символов на оставшихся порядках, достаточно сложно. Но можно утверждать, что если распределение пошло в сторону увеличения числа кодирований символов на больших порядках, то это приведет к улучшению компрессии.
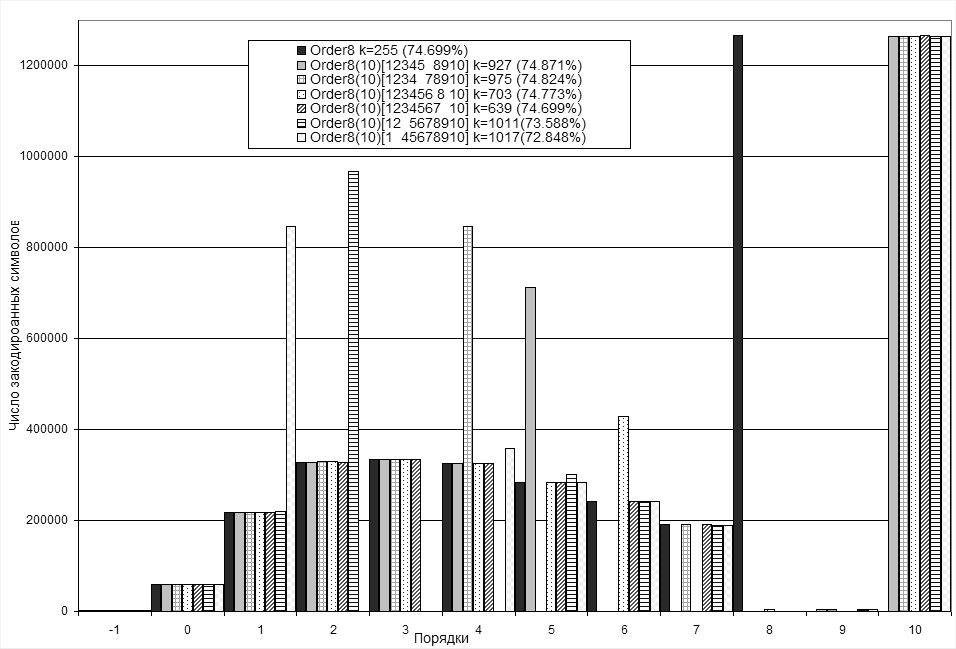
Чтобы разобраться, почему некоторые неполные кодеки сжимают данные лучше, чем другие, обратимся к рисунку 1. На этом рисунке представлена диаграмма распределения числа кодирований символов по контекстным порядкам для полного кодека Order8 и некоторых неполных кодеков с тем же числом порядков при сжатии пакета Calgary Corpus.
Рисунок 1. Распределение числа символов по порядкам при сжатии Calgary Corpus
По диаграмме видно, что при использовании полного кодека (к=255) максимальное число кодирований символ приходится на самый старший порядок order8. При использовании неполных кодеков максимальной число кодирований также находится на самом старшем порядке, для неполных кодеков на рисунке 2 – это order10.
У неполных кодеков кроме основного пика кодирования на самом старшем из порядков появляется еще и дополнительный пик. Чем на большем порядке второй пик появился, тем лучше будет компрессия. Так, для кодека к=1017 резко возросло число кодирований символов на порядке order1, поскольку отсутствуют порядки order2 и order3, а это отрицательно сказалось на компрессии – этот кодек кодирует хуже, чем все остальные, представленные на рисунке 1.
Но не только порядок, на котором находится второй пик числа закодированных символов, влияет на сжатие, не менее важна и величина этого пика. Так, например, у лучшего на рисунке 1 неполного кодека к=927, пик находится на order5, а у кодека k=703, он находится на order6, но поскольку величина это пика гораздо меньше, чем у к=927, этот кодек кодирует хуже.
Память, требуемая неполным кодекам
Особенностью алгоритма РРМ являются симметричность заказа памяти при кодировании и декодировании, поэтому все выводы этого раздела справедливы как для кодирования, так и для декодирования.
Тестирование неполных кодеков на различных тестовых пакетах, позволили сделать вывод, что лучшие по компрессии неполные кодеки, представленные в таблице 1, как правило, требуют меньше памяти, чем все другие неполные кодеки равного им числа порядков. Скорее всего, это связано с использование "техники исключения при обновлении". Согласно ей, при обновлении порядков после кодирования символа из обновления исключаются порядки, работающие с контекстами, число символов которых меньше, чем на том порядке, где произошло кодирование. Чем на более высоком контекстном порядке идет кодирование, тем плотнее будет сжатие, и тем меньше порядков будет обновляться и сохранять свою статистику.
Если сравнивать неполные кодеки с одинаковым числом порядков между собой, то нельзя утверждать, что чем лучше неполный кодек кодирует, тем меньше ему памяти ему требуется.
В таблице 15 приведены результаты сравнения размера требуемой памяти для полных кодеков и тех неполных кодеков, которые требуют меньше всего памяти при тестировании на пакете Calgary Corpus.
Число порядков
Затраты памяти полных кодеков, Кбайт
Затраты памяти лучших неполных кодеков, Кбайт
Ключи неполных кодеков, требующих наименьшую память
1
130
357
4,8,16,32,64,128,256,512
2
888
907
5,9,17,33,65,129,257,513
3
2365
2365
11,19,35,67,131,259,515
4
4806
4806
23,39,71,134,263,519
5
8301
8302
47,79,143,271,527
6
15361
18270
111,175,207,399,783
7
25708
28786
223
8
38906
44835
479
9
54466
62756
991
10
71833
-
-
Таблица 15. Сравнение полных и неполных кодеков по размеру требуемой памяти при сжатии пакете Calgary Corpus.
Согласно таблице 15, размеры требуемой памяти для неполных кодеков больше или равны размерам памяти, требуемой для полных кодеков с тем же числом порядков. Можно отметить, что при малых числах порядков разница в требуемой памяти у неполных кодеков в сравнении с полными либо отсутствует, либо незначительна. При увеличении числа порядков эта разница начинает заметно расти, достигая максимального значения на самом старшем порядке. Та же закономерность была выявлена и при тестировании и других тестовых пакетов.
При использовании кодеков имеющих ограничение на максимальное число хранимых в контейнерах структур описаний символов и контекстов, никакой разницы в заказе памяти для полных и неполных кодеков нет.
Таким образом, уменьшить размеры памяти, необходимой для работы кодека, при замене полного кодека неполным с тем же числом порядков, не удастся. Более того, неполные кодеки иногда могут требовать значительно больше памяти, чем соответствующие им полные кодеки.
Скорость работы неполных кодеков
Как говорилось выше, для тестирования скорости работы кодеков использовался достаточно слабый по производительности компьютер, относящийся к классу нетбуков, чтобы более точно оценить время работы неполных кодеков.
В Таблице 16 и 17 показаны средние результаты скорости работы полных и неполных кодеков при компрессии и декомпрессии пакета Calgary Corpus. Для вычисления времени работы каждый тест для каждого кодека был запущен 6 раз, а средние значение получено как среднеарифметическое этих запусков
Число порядков
Полные кодеки
Неполные кодеки
Время компрессии, sec
Время декомпрессии, sec
Суммарное время, sec
Время компрессии, sec
Время декомпрессии, sec
Суммарное время, sec
Самый быстрый кодек
1
2.2641
4.0025
6.2666
2.3909
2.3015
4.6924
Order1(2)2
2
2.7980
3.2491
6.0471
3.1869
3.6721
6.8590
Order2(4)9
3
3.9641
4.4780
8.4421
4.0350
4.4843
8.5193
Order3(4)11
4
5.1109
5.6130
10.7239
5.3831
5.6158
10.9989
Order4(5)27
5
6.7447
7.1772
13.9219
6.7749
7.2422
14.0171
Order5(6)47
6
8.6156
9.0087
17.6243
8.7293
9.0530
17.7823
Order6(7)95
7
10.7623
11.0635
21.8258
10.9556
11.2640
22.2196
Order7(10)575
8
13.2428
13.6207
26.8635
13.5563
14.0253
27.5816
Order8(10)639
9
16.7676
16.5757
33.3433
16.9693
16.6663
33.6356
Order9(10)767
10
20.4059
20.1927
40.5986
Таблица 16. Сравнение полных и неполных кодеков без ограничений памяти по степени сжатия на пакете Calgary Corpus.
Число порядков
Полные кодеки
Неполные кодеки
Время компрессии, sec
Время декомпрессии, sec
Суммарное время, sec
Время компрессии, sec
Время декомпрессии, sec
Суммарное время, sec
Самый быстрый кодек
2
2.783
3.291
6.074
3.2600
3.5032
6.7632
Order2(5)24
3
3.9523
4.4376
8.3899
4.0510
4.5065
8.5575
Order3(4)11
4
6.2578
6.7630
13.0208
6.8670
7.3670
14.234
Order4(5)23
5
12.2982
12.7680
25.0662
12.6950
13.1990
25.8940
Order5(6)47
6
16.3166
16.9854
33.3020
20.5886
21.0260
41.6146
Order6(7)95
7
26.23375
26.4185
52.6522
25.1786
25.4458
50.6244
Order7(8)223
8
30.4630
30.6422
61.1052
30.3920
30.9720
61.3640
Order8(10)927
9
36.5826
37.0426
73.6252
36.4093
36.8716
73.2809
Order9(10)991
Таблица 17. Сравнение полных и неполных кодеков с ресурсными ограничениями по степени сжатия на пакете Calgary Corpus.
Согласно таблицам 16 и 17, неполные кодеки смогли опередить полные кодеки с тем же числом порядков только при числе порядков, равном одному для кодеков без ограничений по памяти, и с числом порядков 7 и 9 для кодеков без ограничений. Во всех остальных случаях неполные кодеки работают медленнее, чем те полные кодеки, которые имеют с ними равное число порядков.
Также можно заметить, что на скорость работы кодека, если для него не установлены ограничения по памяти, существенно влияет то, сколько памяти этот кодек запрашивает. Как было показано выше, лучшие кодеки, приведенные в Таблице 1, требуют меньше памяти, чем другие неполные кодеки, поэтому и скорость работы у них лучше.
Проведенные тесты производительности работы кодеков показали, что в большинстве случаев замена неполных кодеков полными с тем же числом порядков, никакого выигрыша по времени не дает.
Заключение
Таким образом, после тестирования неполных кодеков на всех используемых в этой работе тестовых пакетах можно заключить, что применение этого типа кодеков нельзя назвать эффективным и универсальным способом улучшения компрессии. Согласно приведенным тестам, они могут улучшить компрессию не больше чем на 1%, при этом в большинстве случаев, за это придется заплатить небольшой потерей производительности, а если не используются фиксированные контейнеры записей, то и дополнительными ресурсными затратами. Можно сказать, что в подавляющем большинстве случаев вместо неполного кодека, стоит выбирать полный кодек с тем же числом контекстных порядков.
И, тем не менее, не следует полностью отбрасывать из рассмотрения эти кодеки. Как было показано на тестах, для каждого типа данных и даже отдельного файла можно подобрать неполный кодек, который достаточно хорошо может улучшить сжатие. Таким образом, использование неполных кодеков можно отнести к методам тонкой настройки компрессора на определенный тип данных.
В данной работе были выдвинуты несколько предположений о неполных кодеках, и поскольку эти предположения были подтверждены тестами на различных пакетах тестирования, ими можно воспользоваться для поиска неполного кодека, который лучше всего сжимает требуемый тип данных.
Литература
А. Титов. Конструктор РРМ-подобных кодеков. RSDN Magazine 02/2011, К-Пресс
http://compression.ca/act/index.html
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.