 Оценка 0
Оценка 0 
 Оценить
Оценить 






| Оценка 0 Оценить
|
Nitra использует весьма сложные алгоритмы разбора, что позволяет описывать язык в более естественной манере, а также описывать неоднозначные языки, то есть языки, не имеющие однозначной контекстно-свободной грамматики (например, C++). Кроме того, Nitra поддерживает автоматическое восстановление после обнаружения ошибок. Разбор текста, содержащего ошибки, может повлечь появление неоднозначностей даже в однозначной грамматике.
Чтобы проводить парсинг в условиях всех описанных выше сложностей, парсеры, созданные с помощью Nitra, записывают информацию о парсинге в специальные структуры данных. Эти структуры данных содержат информацию обо всех деталях разбора с учетом неоднозначностей и ошибок, содержащихся в разбираемом тексте.
Парсеры, созданные с помощью Nitra, не позволяют непосредственно вмешиваться в процесс парсинга. Это сделано вследствие того, что во время парсинга может анализироваться большое количество альтернативных путей разбора, в которых может запутаться даже гуру в области парсинга. Вместо этого Nitra позволяет разрешить неоднозначности автоматически или вручную (после окончания парсинга).
Результатом парсинга в Nitra всегда является класс ParseResult (объявленный в пространстве имен Nitra, в библиотеке Nitra.Runtime.dll). Данные хранятся в нем в очень низкоуровневом виде. Большая часть этих данных описывается в двух массивах целых чисел (Int32). Кроме того, результат парсинга может содержать значения, собранные разными парсерами (так как Nitra-парсеры могут объединяться во время исполнения), и могут содержать информацию о восстановлении после обнаружения ошибок.
Все это делает анализ ParseResult нетривиальной задачей. Чтобы упростить эту задачу и абстрагироваться от внутреннего представления, в Nitra имеется два механизма анализа ParseResult:
Выбор механизма анализа зависит от стоящих задач. Анализ ParseTree подразумевает больше возможностей, но требует написания отдельного кода для анализа каждого правила. Обходчики лучше подходят там, где требуется собрать однородные данные со всего результата парсинга, и нет нужды выписывать специальную обработку для отдельных правил.
Зависимые свойства – это реализация атрибутных грамматик. Термин «атрибут» не используется в Nitra, так как исходно Nitra основана на .Net, а в .Net этот термин используется для пользовательских метаданных.
С помощью зависимых свойств можно осуществлять сбор информации с дерева разбора или деклараций, и производить необходимые вычисления. Основной особенностью зависимых свойств является то, что их вычисление производится в ленивой манере.
| ПРИМЕЧАНИЕ Ленивые вычисления — это стратегия вычисления, согласно которой вычисления откладываются до тех пор, пока не понадобится их результат. |
Ленивые вычисления позволяют не думать об их порядке. Значение свойства будет вычислено, как только станут доступны значений других зависимых свойств, участвующих в его расчете (то есть тех, от которых оно зависит).
Расчет зависимых свойств производится ровно один раз. Если грамматика (в том числе и расширение грамматики) содержит двойной расчет зависимого свойства, это считается ошибкой. Такие ошибки, в общем случае, могут быть выявлены только во время выполнения, так как дополнительные расчеты могут быть подгружены вместе с расширениями грамматики.
Вычисления зависимых свойств похожи на присвоения обычных свойств императивного языка (такого как C# или Nemerle):
UsingDirectives.ScopeIn = this.ScopeIn; UsingDirectives.AliasTableIn = Scope.Table(); UsingDirectives.OpenScopeIn = []; Members.ScopeIn = Hide(Union(this.ScopeIn, UsingDirectives.AliasTableOut), Union(UsingDirectives.OpenScopeOut)); Members.ParentNamespace = Namespace; |
но, в отличие от императивных языков, расчеты производятся отложенно (лениво) и в порядке, определяемом зависимостью.
Тот факт, что одни свойства зависят от других позволяет, задавать порядок вычисления неявно. Это позволяет:
Избежать явного разбития процесса компиляции на стадии.
Расширять и/или изменять порядок вычислений внутри синтаксических расширений.
Синтаксис объявления зависимых свойств:
syntax FieldValue
{
| Expression = "=" Expression ";"
| Empty = ";"
}
| InDependentProperty = "in" Name ":" NitraType FieldValue
| OutDependentProperty = "out" Name ":" NitraType FieldValue
| InOutDependentProperty = "inout" Name ":" NitraType ";" |
Примеры декларации зависимых свойств:
declaration Namespace : UsingSite
{
Parent : UsingSite;
in ParentNamespace : NamespaceSymbol;
out Namespace : NamespaceSymbol;
...
}
declarations UsingDirective
{
Parent : UsingSite;
inout AliasTable : Scope.Table;
inout OpenScope : list[Scope];
...
} |
Декларация с ключевым словом «inout» объявляет пару свойств, добавляя к их имени суффиксы «In» и «Out». Таким образом:
inout AliasTable : Scope; |
эквивалентно:
in AliasTableIn : Scope;
out AliasTableOut : Scope; |
Объявление inout-свойств – это распространенный паттерн. Он используется для «протаскивания» значений сквозь структуру синтаксических деревьев и деклараций.
Зависимые свойства могут быть присвоены как узлу, в котором они объявлены, так и дочерним узлам. Зависимые свойств, объявленные на дереве разбора, могут обращаться к свойствам, объявленным внутри правила или в подправилах. Зависимые свойства, объявленные в декларациях, соответственно, могут обращаться к зависимым свойствам той же декларации или объявленным в дочерних элементах (т.е. свойствам, тип которых реализует IDeclaration или является коллекцией элементов, реализующих IDeclaration).
Вычисление зависимых свойств может содержать обращение к другим зависимым свойствам, к дереву разбора или к методам, объявленным в правилах. При этом считается, что эти методы должны возвращать всегда одну и ту же информацию, то есть быть «чистыми» (зависеть только от своих параметров и значений из дерева разбора). Методы, объявленные на дереве разбора, не имеют права обращаться к зависимым свойствам, так как для кода методов не обеспечивается расчет зависимостей и ленивое исполнение. Однако методы могут получать значения зависимых свойств.
Для списков элементов, для каждого из которых доступны зависимые свойства, поддерживается «протаскивание» значений через такие свойства. Например, если имеется декларация Member с зависимым свойством Prop, то для списка Members (содержащего элементы типа Member) конструкция:
Members.Prop = 42; |
присвоит значение «42» свойству всем всех элементов списка.
Если у элементов списка имеются inout-свойства, то конструкция:
Members.PropIn = 42;
this.Ptop2 = Members.PropOut; |
то значение 42 будет присвоено свойству PropIn первого элемента списка. Далее значение свойства PropOut первого элемента будет присвоено свойству PropIn второго элемента. Так будет продолжаться, пока значение не будет «протащено» через все элементы списка. Значение PropOut последнего элемента списка будет присвоено свойству this.Ptop2. Таким образом, значение будет передаваться между всеми элементами списка, и каждый элемент списка может изменить его.
Значение будет «протаскиваться» через свойства даже в случае, если впоследствии оно не будет использоваться:
Members.PropIn = 42; |
Достоинством зависимых свойств является то, что программисту не нужно задавать вручную последовательность поступления. В случае если присвоения свойств делаются слева направо, или данные поднимаются вверх по дереву, вычисление всех зависимых свойств в дереве производится за минимальное количество проходов по дереву. Однако возможны ситуации, когда для вычисления зависимых свойств может потребоваться существенно больше проходов. Поэтому стоит избегать передачи значений между зависимыми свойствами от правого подправила грамматики к левому.
Nitra позволяет определять методы прямо внутри правил грамматики. Эти методы подмешиваются к дереву разбора. Методы дерева разбора являются самым эффективным и довольно простым способом сбора информации из дерева разбора.
Внутри таких методов подправила правила, в которых объявлены методы, доступны как поля класса. При этом вы можете считывать текст подправил, их местоположение и вызвать другие Rule-методы (у любых подправил или того же правила). Rule-методы могут иметь любое количество параметров произвольного типа. Это позволяет осуществлять любые вычисления на дереве разбора.
При объявлении Rule-метода в расширяемом правиле такие методы автоматически становятся виртуальными. Такие методы могут быть переопределены в расширяющих правилах. Если Rule-метода объявлен в расширяемом правиле и не имеет тела, то такие методы обязательно должны быть переопределены в расширениях (расширяющих правилах).
syntax RuleMethod = RuleMethodAttributes "private"? Name
"(" (RuleMethodsParam; ",")* ")"":" Type RuleMethodBody
syntax RuleMethodBody
{
| Block
| Expression = "=" Expression ";"
| Empty = ";"
}
syntax RuleMethodOverride = MethodAttributes "override" Name RuleMethodBody
syntax RuleMethodMissing = MethodAttributes "missing" Name RuleMethodBody |
Пример Rule-метода:
Value() : string = GetText(IdentifierBody); |
Для переопределения виртуальных Rule-методов в расширяющих правилах используется ключевое слово override. При этом сигнатура метода не описывается (так как Nitra не поддерживает перегрузки Rule-методов по сигнатуре).
Пример Rule-методов на расширяемых правилах (пример из грамматики Nitra):
syntax RuleMethodBody
{
BodyLocation() : Nitra.Location;
IsEmpty() : bool;
| Block
{
override BodyLocation = Block.Location;
override IsEmpty = false;
}
| Expression = sm "=" sm Expression ";" nl
{
override BodyLocation = Expression.Location;
override IsEmpty = false;
}
| Empty = ";" nl
{
override BodyLocation = Location(this.Location.Source,
this.Location.StartPos, this.Location.StartPos);
override IsEmpty = true;
}
} |
Кроме того, для Rule-методов можно задавать обработчики отсутствующих значений:
Value() : double; missing Value = double.NaN; |
Эти обработчики вызываются, если для некоторого подправила пропущено значение в разбираемом тексте. Данный обработчик может вернуть некоторое значение, которое будет использоваться при дальнейшей обработке. Если его не задать, то при обращении к Rule-методу произойдет исключение.
Значение, вычисленное в результате вызова Rule-метода, может быть преобразовано в свойство узла дерева разбора (кэшировано). Такое свойство может быть использовано на последующих проходах. Это позволяет организовать многопроходную обработку, не задумываясь о передаче и хранении промежуточных результатов. Для преобразования значения Rule-метода в свойство используется атрибут [Cached]. При этом для формирования имени свойства используется имя Rule-метода. Если Rule-метод имеет префикс: Get, Compute, Calculate, Calc, Create, Make, Evaluate или Eval, то такой префикс удаляется. Так что из метода GetText() будет создано свойство Text.
В расширяемых правилах можно создавать не виртуальные, частные методы. Такие методы удобны для декомпозиции или для образования свойств с помощью атрибута [Cached].
| AbstractDeclaration = "abstract""declaration" Name DeclarationInheritance? Body=DeclarationBody { [Cached] privateMakeDeclarationSymbol() : ParsedAbstractDeclarationSymbol = ParsedAbstractDeclarationSymbol(this); override CollectGlobalSymbols { def symbol = MakeDeclarationSymbol(); // теперь будет доступно свойство «DeclarationSymbol»_ = ns.Node.AddAndReport.[DeclarationSymbol](symbol, Name.Location); Body.CollectGlobalSymbols(symbol); } |
По своим вычислительным возможностью, расширяемости и удобству Rule-методы аналогичны зависимым свойствам. Преимуществом Rule-методов является гарантированно высокая скорость вычислений. Они не добавляют никаких накладных расходов (за исключением очень простого кода проверки на зацикливание) и гарантируют линейное время обхода.
К недостаткам Rule-методов можно отнести то, что их использование требует явного описания стадий обработки (компиляции) дерева разбора. Особенно неприятно это при сопровождении больших грамматик, так как добавление новой стадии вынуждает добавлять новые Rule-методы ко всем веткам, которые могут идти выше в дереве разбора.
ParseTreeVisitor позволяет обойти дерево разбора универсальным образом. Это класс (по сути, интерфейс) с очень простым устройством:
public
abstract
class ParseTreeVisitor
{
publicvirtual Enter(parseTree : ParseTree) : void
{
IgnoreParams();
}
publicvirtual Leave(oldTree : ParseTree, newTree : ParseTree) : void {
IgnoreParams();
}
publicvirtual Visit(parseTree : ParseTree) : ParseTree
{
parseTree.Apply(this)
}
} |
Для создания собственного посетителя нужно создать наследник этого класса и реализовать три метода, описанные выше или даже только метод Visit. Метод Visit будет вызваться для каждого узла в дереве разбора, а методы Enter и Leave при начале и в конце обхода узлов.
ParseTreeVisitor позволяет как просто обойти все ветки дерева разбора, так и произвести их замену. Если в методе Visit возвратить новую ветку, то ParseTreeVisitor заменит ею ветку, которая была передана в метод Visit в качестве параметра. При этом будут перестроены все ветки от текущей до корня дерева разбора. Таким образом, ParseTreeVisitor можно использовать для изменения дерева разбора, а также для устранения неоднозначностей.
Чтобы продолжить обход, из метода Visit нужно произвести вызов: ast.Apply(this).
Если по каким-то причинам обход дерева для нижележащих веток производить не надо, можно просто вернуть значение параметра ast.
Если вернуть новое значение, оно будет подставлено вместо узла, переданного в метод Visit в параметре ast. При этом будут пересозданы все ветки, начиная от текущей и до корня дерева разбора.
Недостатками использования ParseTreeVisitor является то, что вам придется осуществлять проверки типов в время выполнения, чтобы понять, что за ветка была передана в метод Visit (в параметре ast) и производить повышающее приведение типа, чтобы работать с конкретными узлами дерева разбора. Если вы используете Nemerle, для этого можно воспользоваться сопоставлением с образцом (оператор match). При этом также можно воспользоваться квази-цитированием.
Ниже приведен пример вызов метода Where (из Linq) на аналогичный императивный код (использующий цикл и внешнюю коллекцию):
using Nemerle;
using Nemerle.Collections;
using Nemerle.Text;
using Nemerle.Utility;
using System;
using SCG = System.Collections.Generic;
using Nitra;
using Nitra.Quote;
using CSharp.StatementsParseTree;
[assembly: ImportRules(Grammar = "CSharp.SplicableStatements",
GrammarAlias = "stmt")]
[assembly: ImportRules(Grammar = "CSharp.SplicableExpressions",
GrammarAlias = "expr")]
internalsealedclass CSharpVisitor : ParseTreeVisitor
{
[Record]
privatestruct VisitorContext
{
public Statements : SCG.List[Statement];
}
_contexts : SCG.Stack[VisitorContext] = SCG.Stack();
_parents : SCG.Stack[ParseTree] = SCG.Stack();
publicoverride Enter(ast : ParseTree) : void {
_parents.Push(ast);
}
publicoverride Leave(_ : ParseTree, _ : ParseTree) : void {
_ = _parents.Pop();
}
publicoverride Visit(ast : ParseTree) : ParseTree
{
quotematch (ast)
{
| statementList is ListParseTree[Statement] =>
def newStatements = SCG.List(statementList.Length);
_contexts.Push(VisitorContext(newStatements));
foreach (item in statementList)
newStatements.Add(Visit(item) :> Statement);
_ = _contexts.Pop();
statementList.UpdateItems(newStatements)
| expressionStatement is EmbeddedStatement.ExpressionStatement
when _parents.Peek() is IndentedEmbeddedStatement =>
def newStatements = SCG.List();
_contexts.Push(VisitorContext(newStatements));
def newExprStmt = expressionStatement.Apply(this)
:> EmbeddedStatement;
_ = _contexts.Pop();
if (newStatements.Count > 0)
{
newStatements.Add(quote
<# stmt::Statement: $EmbeddedStatement(newExprStmt) #>);
quote <# EmbeddedStatement: { $Statements(newStatements.ToNList()) }
#>
}
else newExprStmt;
| <# Expression: $(expr1).Where($Name(item) => $Expression(pred)) #>
when _contexts.Count > 0 with context = _contexts.Peek() =>
def varName = NameGenerator.GenerateName("buffer");
context.Statements.Add(quote <# Statement:
var $Name(Identifier.Create(context, false, varName)) =
new List<object>();
#>);
context.Statements.Add(quote <# Statement:
foreach (var $Name(item) in $Expression(expr1))
if ($BooleanExpression(pred))
$Identifier(Identifier.Create(context, false, varName))
.Add($Identifier(item));
#>);
quote <# Expression:
$Identifier(Identifier.Create(context, false, varName)) #>;
| <# Expression: !false #> => quote <# Expression: true #>
| x => x.Apply(this)
}
}
}
internalmodule NameGenerator
{
privatemutable _id : int = 0;
public GenerateName(body : string) : string
{
_id += 1;
"__N_" + body + "_" + _id
}
} |
Чтобы запустить этот «посетитель», нужно выполнить следующий код:
def text = File.ReadAllText(fileName);
def source = SourceSnapshot(text, 0, fileName);
def parseResult = CSharp.Main.CompilationUnit(source, parserHost);
def parseTree = CSharp.MainParseTree.CompilationUnit.Create(parseResult);
def visitor = CSharpVisitor();
def newParseTree = parseTree.Apply(visitor); |
Полученное дерево разбора можно преобразовать обратно в текст с помощью метода ToString().
Квази-цитирование – это способ работы с деревом разбора с помощью высокоуровневых паттернов. Паттерн может содержать фрагмент кода на целевом языке (с указанием правила, с которого нужно начинать разбор этого фрагмента), который может содержать «сплайсы» (или как их еще называют – «дыры»). В дыры можно вставлять код, формирующий дерево разбора программным путем. Сплайс начинается со знака «$», за которым идет имя правила и круглые скобки, содержащие выражение на Nemerle, формирующее значение, подставляемое вместо сплайса. В некоторых местах имя правила можно опустить, так как компилятор сам понимает, какой тип должен иметь сплайс.
Квази-цитаты могут использоваться как для формирования кода (его дерева разбора), так и для распознавания фрагментов кода. При этом в случае формирования кода сплайсы содержат выражения, вставляющиеся вместо сплайсов, а в случае разбора (pattern matching) сплайсы должны содержать имена переменных, в которые помещаются фрагменты кода. Это позволяет создать обобщенные образцы кода. Например, паттерн:
<# Expression: $(expr1).Where($Name(item) => $Expression(pred)) #> |
описывает выражение вызова метода Where, которому передается лямбда. При этом в переменную «expr1» помещается дерево разбора соответствующее выражению, у которого вызывается метод (это может ссылка на переменную, содержащую коллекцию или более сложное выражение), в item помещается имя параметра (то, что он один, определяется именем правила Name, указанным у сплайса), а в переменную pred помещается выражение, соответствующее телу лябмды.
Чтобы воспользоваться квази-цитированием, необходимо предварительно сгенерировать поддержку квази-цитирования для Nitra-грамматики разбираемого языка. Для этого в проект, содержащий грамматику языка, для которого нужна поддержка квази-цитирования, нужно добавить атрибут Nitra.MakeSplicable. В этом атрибуте нужно указать основной модуль грамматики языка, например:
[assembly: Nitra.MakeSplicable(CSharp.Main)] |
Поддержку квази-цитирования можно добавить и к грамматике, доступной в виде исполнимого модуля (когда исходного кода нет). При этом нужно создать новый проект, подключить к нему грамматику и добавить атрибут Nitra.MakeSplicable.
Код, использующий квази-цитирование, должен находиться в сборке, отличной от сборки, содержащей поддержку квази-цитирования для языка, так как код квази-цитирования должен быть скомпилирован до его применения.
Последним способом анализа результатов парсинга являются Walker-ы. В отличие от всех остальных методов, Walker-ы работают непосредственно с результатом парсинга (с так называемым Raw Parse Tree, закодированным в виде двух целочисленных массивов). Так как Walker-ы не создают промежуточных представлений, они являются самым быстрым способом анализа.
Минусами использования Walker-ов является большая сложность их использования и отсутствие места для складирования промежуточных результатов разбора. Кроме того, Walker-ы не позволяют сослаться на конкретную подветку дерева разбора, так что анализ дерева разбора с их помощью должен всегда производиться с корня дерева разбора.
Walker-ы не могут применяться к деревьям разбора, построенным с помощью квази-цитирования или вручную (только к результатам парсинга текста).
Walker-ы могут пропускать некоторые подветви дерева разбора, перепрыгивая к следующим. Это позволяет ускорить поиск нужной информации, если она ищется только в части разбираемого текста (например, отображаемой на экран в редакторе кода).
Walker-ы применяются для сбора информации о подсветке токенов, фолдинге и т.п. Для всего этого есть уже готовые волкеры.
Как и ParseTreeVisitor, Walker-ы являются гомогенными обходчиками, так что одна реализация будет работать со всеми (возможно, даже созданными в будущем) языками.
Пример Walker-а, собирающего информацию о подсветке:
using Nemerle;
using Nemerle.Text;
using Nemerle.Utility;
using Nitra.Collections;
using Nitra.Internal;
using Nitra.Internal.Recovery;
using Nitra.Runtime.Reflection;
using System;
using System.Collections.Generic;
using System.Linq;
type SpanInfoSet = System.Collections.Generic.HashSet[Nitra.SpanInfo];
namespace Nitra.Runtime.Highlighting
{
internalsealedclass HighlightingWalker : WalkerBase[SpanInfoSet]
{
range : NSpan;
publicthis(range : NSpan)
{
//HashSet;this.range = range;
}
publicoverride OnRegularCall(
ruleInfo : SubruleInfo.RegularCall,
startPos : int,
endPos : int,
parseResult : ParseResult,
context : SpanInfoSet) : void
{
_ = parseResult;
when (endPos >= 0)
{
def spanClass = ruleInfo.SpanClass;
when (spanClass != null && range.IntersectsWith(startPos, endPos)
&& endPos > startPos)
{
_ = context.Add(SpanInfo(NSpan(startPos, endPos), spanClass));
}
}
}
publicoverride OnTokenString(
ruleInfo : SubruleInfo.TokenString,
startPos : int,
endPos : int,
parseResult : ParseResult,
context : SpanInfoSet) : void
{
_ = parseResult;
when (endPos >= 0)
{
def spanClass = ruleInfo.SpanClass;
when (spanClass != null && range.IntersectsWith(startPos, endPos)
&& endPos > startPos)
{
_ = context.Add(SpanInfo(NSpan(startPos, endPos), spanClass));
}
}
}
publicoverride OnSimpleCall(
ruleInfo : SubruleInfo.SimpleCall,
startPos : int,
endPos : int,
parseResult : ParseResult,
context : SpanInfoSet) : void
{
when (range.IntersectsWith(startPos, endPos))
base.OnSimpleCall(ruleInfo, startPos, endPos, parseResult, context);
}
publicoverride OnExtensibleCall(
ruleInfo : SubruleInfo.ExtensibleCall,
startPos : int,
endPos : int,
parseResult : ParseResult,
context : SpanInfoSet) : void
{
when (range.IntersectsWith(startPos, endPos))
base.OnExtensibleCall(ruleInfo, startPos, endPos,
parseResult, context);
}
publicoverride OnOption(
ruleInfo : SubruleInfo.Option,
startPos : int,
endPos : int,
parseResult : ParseResult,
context : SpanInfoSet) : void
{
when (range.IntersectsWith(startPos, endPos))
base.OnOption(ruleInfo, startPos, endPos, parseResult, context);
}
publicoverride OnList(
ruleInfo : SubruleInfo.List,
startPos : int,
endPos : int,
parseResult : ParseResult,
context : SpanInfoSet) : void
{
when (range.IntersectsWith(startPos, endPos))
base.OnList(ruleInfo, startPos, endPos, parseResult, context);
}
publicoverride OnListWithSeparator(
ruleInfo : SubruleInfo.ListWithSeparator,
startPos : int,
endPos : int,
parseResult : ParseResult,
context : SpanInfoSet) : void
{
when (range.IntersectsWith(startPos, endPos))
base.OnListWithSeparator(ruleInfo, startPos, endPos,
parseResult, context);
}
publicoverride WalkSimple(
startPos : int,
endPos : int,
ruleParser : SimpleRuleParser,
parseResult : ParseResult,
context : SpanInfoSet) : void
{
base.WalkSimple(startPos, endPos, ruleParser, parseResult, context);
def spanClass = ruleParser.Descriptor.SpanClass;
when (spanClass != null && range.IntersectsWith(startPos, endPos)
&& endPos > startPos)
{
_ = context.Add(SpanInfo(NSpan(startPos, endPos), spanClass));
}
}
publicoverride WalkPrefix(
rawTreePtr : int,
startPos : int,
endPos : int,
ruleParser : ExtensionRuleParser,
parseResult : ParseResult,
context : SpanInfoSet) : void
{
base.WalkPrefix(rawTreePtr, startPos, endPos, ruleParser,
parseResult, context);
when (endPos >= 0)
{
def spanClass = ruleParser.Descriptor.SpanClass;
when (spanClass != null && range.IntersectsWith(startPos, endPos)
&& endPos > startPos)
{
_ = context.Add(SpanInfo(NSpan(startPos, endPos), spanClass));
}
}
}
publicoverride WalkPostfix(
rawTreePtr : int,
startPos : int,
endPos : int,
ruleParser : ExtensionRuleParser,
parseResult : ParseResult,
context : SpanInfoSet) : void
{
base.WalkPostfix(rawTreePtr, startPos, endPos, ruleParser,
parseResult, context);
when (endPos >= 0)
{
def spanClass = ruleParser.Descriptor.SpanClass;
when (spanClass != null && range.IntersectsWith(startPos, endPos)
&& endPos > startPos)
{
_ = context.Add(SpanInfo(NSpan(startPos, endPos), spanClass));
}
}
}
}
} |
Не секрет, что проекты бывают разными по размеру. Nitra должна обеспечивать поддержку больших и очень больших проектов для самых разных языков. Поэтому нам, разработчикам Nitra, приходится думать о таких вещах как кэширование и оптимизации на уровне работы IDE. Кэшировать все данные бесполезно, а какие данные нужно кэшировать, зависит от языка. Поэтому авторы языка должны описать для Nitra, какие данные должны кэшироваться, на уровне проектов и решений (в терминологии Visual Studio, или модулей и проектов, в терминах мира Java).
Nitra кэширует декларации верхнего уровня. Примерами деклараций верхнего уровня для языков вроде C# или Nemerle являются: пространства имен, объявления типов, члены типов (без тел методов). В Nitra декларациями верхнего уровня являются: пространства имен, синтаксические модули, правила (без содержимого правил). Такие данные автоматически сериализуются Nitra при записи проектов, и при повторном открытии проектов парсинг не изменявшихся исходников не производится.
Автор языка, использующий Nitra, должен описать декларации верхнего уровня для своего языка и описать отображение правил грамматики на эти декларации. По этому описанию Nitra автоматически создаст код, переносящий данные из дерева разбора в декларации, а также код сериализации и десериализации всех деклараций в рамках решения (Solution). Здесь и далее будет применяться терминология, используемая в Visual Studio – «проект» и «решение».
Декларации – это нечто вроде классов в ООП, описывающих AST. Дерево деклараций состоит из следующих элементов:
Таким образом, декларации образуют иерархию, корнем которой является Project. Его дочерними элементами являются декларации для файлов (CompilationUnit-ы), а те, в свою очередь, содержат иерархию деклараций для каждого файла. Причем декларации должны отражать иерархию реальных деклараций языка.
Отличие декларации от AST заключается в том, что декларация объявляет некоторую именованную сущность. По сути, декларации это подтип AST, имеющий одно дополнительное свойство – Name.
Декларации для Project и CompilationUnit могут выглядеть следующим образом:
[Project] declaration Project { GlobalNamespace = CreateGlabalNamespace(); CompilationUnits.GlobalNamespace = GlobalNamespace; CompilationUnits.InScope = GlobalNamespace.Scope; // зависимое свойство, используется для раасчетовout GlobalNamespace : NamespaceSymbol; // структурное свойство, описывает дочерние декларации// «*» - означает «список, допускающий хранение 0 или более элементов» CompilationUnits : CompilationUnit*; } [CompilationUnit] declarations CompilationUnit : UsingSite { | CSharp in GlobalNamespace : NamespaceSymbol; Members.ParentNamespace = GlobalNamespace; Namespace = GlobalNamespace; } |
CompilationUnit описывается как declarations для того, чтобы впоследствии в проект можно было бы добавить другие типы файлов.
Для описания деклараций используются конструкции «declaration» и «declarations». Конструкция declarations позволяет описать расширяемую декларацию (аналогичную описанию расширяемого свойства). Расширяемая декларация может содержать несколько альтернатив. Например, CompilationUnit может описывать альтернативы для CSharp, Razor, CSS и т.п. Список поддерживаемых языков может пополняться динамически за счет конструкции «extend declarations».
Вот описание синтаксиса для
syntax NamespaceMember
{
| AbstractDeclaration = "abstract""declaration" Name DeclarationInheritance?
Body=DeclarationBody
| SimpleDeclaration = "declaration" Name DeclarationInheritance?
DeclarationParent? Body=DeclarationBody
| ExtensibleDeclaration = "declarations" Name DeclarationInheritance?
DeclarationParent? Body=ExtensibleDeclarationBody
| ExtendDeclaration = "extend""declarations" (Name "=")? BaseName=QualifiedName
Body=ExtensibleDeclarationBody
| MapDeclaration = "declare" DeclarationName=QualifiedName
RuleName=("from" QualifiedName)? MapDeclarationBody
...
} |
Декларации могут содержать или вложенные декларации (т.е. свойства содержащие ссылки на другие деларации или списки деклараций), или зависимые свойства. Первый тип свойств позоляет описать структуру деклараций, а второй – производить произвольные рассчеты на дереве деклараций.
Кроме того, любая декларация содержит свойство Parent, в котором хранится ссылка на другую декларацию, в которую вложена текущая декларация. Тип Parent IAst.
Дерево разбора в общем случае может сильно отличаться от абстрактного и компактного представления, задаваемого декларациями. Для того чтобы не писать руками код, анализирующий дерево разбора и создающий на его основе дерево деклараций, Nitra предлагает DSL отображения дерева разбора (синтаксиса) на дерево деклараций.
Код на этом DSL указывает, как отобразить дерево разбора на декларации. Отображение задается конструкцией «map», имеющей следующий синтаксис:
| MapSyntax = "map""syntax" RuleName=QualifiedName "to" DeclarationName=QualifiedName MapSyntaxBody ... syntax MapSyntaxBody { | Delegate = ";" | Map = "<-" QualifiedName ";" | Inline = "=" Expr=MapDeclarationExpression | PerMember = "{" Members=MapDeclarationMember* "}" } syntax MapDeclarationMember { | Automatic = FieldName=Name "<-" RuleFieldName=Name ";" | Inline = FieldName=Name "=" Code=MapDeclarationExpression | Extension = "|" DeclarationName=Name RuleName=("from" sm Name)? Body=MapSyntaxBody? } |
Единственным предопределенным отображением является отображение идентификаторов на предопределенную декларацию Referense. Оно описывает ссылку на простое (не составное) имя. Все остальные отображения должны быть явно описаны в nitra-файлах.
Вот пример отображения
map syntax Main.CompilationUnit to CompilationUnit.CSharp
{
Externs <- ExternAliasDirectives;
UsingDirectives <- UsingDirectives;
}
map syntax TopDeclarations.ExternAliasDirective to ExternAliasDirective
{
Name <- Name;
}
map syntax TopDeclarations.UsingDirective to UsingDirective
{
| Alias
{
Name <- Name;
NamespaceOrTypeName <- QualifiedName;
}
| Open
{
NamespaceOrTypeName <- QualifiedName;
}
} |
Здесь Main.CompilationUnit, TopDeclarations.ExternAliasDirective и TopDeclarations.UsingDirective – это имена правил грамматики C#, а CompilationUnit.CSharp, ExternAliasDirective и UsingDirective – это имена деклараций. «<-» указывает, какие подправила отображать на какие поля деклараций.
Для реализации нетривиальных отображений можно использовать сопоставление с образцом.
Если декларативное отображение невозможно, можно использовать произвольный код.
Ко времени написания этой статьи работы над DSL отображения были еще не закончены. Мы планируем закончить их в феврале 2015 года.
Символы описывают метаинформацию, собранную из кода. Символы создаются с помощью отображения на них деклараций. У одного символа может быть ноль или более деклараций. Например, у пространства (в C#) имен может не быть деклараций, так как оно может быть не описано в проекте, в котором имеется ссылка на него. Например, если в C# написать следующий код:
namespace A.B
{
} |
то это будет декларация для пространства имен B, вложенного в пространство имен A. При этом декларации для пространства имен A не будет.
В качестве примера символа, который может иметь несколько деклараций, можно привести класс C#. В C# можно объявить так называемые partial-классы:
partial
class A { void Foo() {} }
partialclass A { int Bar; } |
Для класса A будет создан один экземпляр символа, у которого будет две декларации.
Естественно, что есть и третий вариант, когда у символа есть ровно одна декларация. Это является самым распространенным случаем.
Символы и декларации поддерживают автоматическую сериализацию и загрузку для проектов и решений. Это обеспечивает быструю загрузку проектов.
Для символа всегда можно получить список деклараций, по которым символ был создан. По декларации всегда можно получить все или часть дерева разбора. Это позволяет получать детальную информацию, необходимую для IDE.
Для создания символов также используется отображение. Но на этот раз отображение деклараций на символы. При этом отображаться уже могут не только свойства, полученные путем отображения дерева разбора на декларации, но и зависимые свойства (полученные в процессе расчетов).
Отображение на символы еще не реализовано. Ее реализация планируется в первом квартале.
Nitra поддерживает автоматическое связывание имен.
Связывание имен – это процесс поиска символа, соответствующего некоторому имени в программе. Например, когда мы объявляем (в C#-программе) поле и указываем его тип, нужно понять, существует ли этот тип, и если существует, получить по нему детальную информацию. В результате связывания получается ссылка на символ, описывающий тип поля или сообщение об ошибке.
Так как связывание кардинально отличается в разных языках, Nitra предоставляет не законченное решение, а строительные блоки. Первым таким блоком является подсистема областей видимостей (scopes) и зависимые свойства в декларациях. Они позволяют указать, как области видимости должны располагаться в дереве разбора, и как области видимости должны отображаться друг в друга и перекрывать друг друга.
Само связывание производится с использованием области видимости, вычисленной и привязанной к AST.
Такое подход позволяет настроить связывание для самых разных языков с учетом всех их особенностей.
Nitra предоставляет комплекс решений, которые в итоге позволяют с помощью очень высокоуровневых описаний описать все детали современного языка программирования и автоматически получить большинство сервисов IDE для своих языков. При этом Nitra позволяет создавать расширяемые языки и расширять имеющиеся языки (описанные на Nitra).
Подсистема связывания позволяет вычислить по дереву разбора символы, несущие информацию об именованных сущностях языка программирования. Для средств кэширования и инкрементального обновления проектов и решений в Nitra введено промежуточное представление, называемое декларациями (а по сути, являющееся разновидностью AST).
Декларации позволяют описать дерево объявлений в файле проекта, произвести расчет областей видимости, отображения одних областей видимости в другие и сокрытие областей видимости другими областями видимости. Это позволяет производить связывание имен и получать в итоге такие сервисы IDE, как расширенная подсветка, навигация по коду, рефакторинг переименования, получение информации об участках кода и т.п.
Кроме того, обеспечивается автоматическое кэширование символов и деклараций. Это позволяет работать с большими проектами без задержек, в реальном режиме времени.
Ниже приведен пример, демонстрирующий отображение двух partial-классов C# в соответствующие декларации и отображение деклараций в символы.
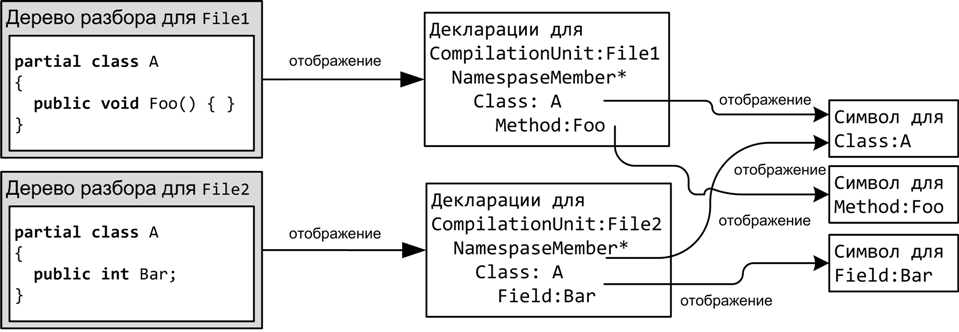
Figure 1. Отображение дерева разбора на символы
Обратите внимание, что две декларации класса преобразуются в один символ для класса A.
Работы над декларациями, символами, отображением, областями видимости и т.п. не были закончены на момент написания данной статьи. Но скорее всего, когда вы будете ее читать, эти работы (хотя бы частично) уже будут завершены. В противном случае вы можете использовать для получения информации о дереве разбора: обходчики (walkers), Rule-методы, ParseTreeVisitor или Квази-цитирование.
Нам интересны любые отклики и предложения по Nitra. Вы можете оставлять их на форуме (http://rsdn.ru/forum/nemerle/) или в issue (https://github.com/JetBrains/Nitra/issues) в github-репозитории проекта. Там же можно следить за прогрессом разработки.
| Оценка 0 Оценить
|