 Оценка 70
Оценка 70 
 Оценить
Оценить 






| Оценка 70 Оценить
|
В Visual Studio 2013 в поддержку языка C++ были внесены значительные улучшения, включая многое из основной спецификации языка стандарта ISO C++11 и некоторые возможности стандартной библиотеки из ISO C++14. В данной статье я покажу и объясню нововведения языка, добавленные в Visual Studio 2013: новые строковые литералы, универсальная инициализация (brace initialization), списки инициализации, делегирующие конструкторы, шаблоны с переменным числом аргументов, функции по умолчанию и удаленные функции, явные операторы преобразования, аргументы шаблонов по умолчанию для шаблонных функций, псевдонимы шаблонов и прозрачные функторы операторов.
Если вы работали с языком C#, то, возможно, знакомы со строковыми литералами с префиксом @, которые избавляют от необходимости экранировать специальные символы. Основная спецификация языка ISO C++11 определяет новые строковые литералы, предоставляющие похожие возможности, и Visual Studio 2013 поддерживает это. Когда мы определяем строки, которые включают пути, URI, HTML, JSON, XML или регулярные выражения, необходимость экранировать специальные символы затрудняет чтение и понимание содержимого строки. Новые возможности позволяют записать строку в ее исходном виде.
Следующие строки показывают JSON-содержимое, где многие символы пришлось бы экранировать, используя классические строки:
{
"Title":"C/C++ section",
"Subtitle":"C/C++ in Visual Studio 2013",
"Id":"10"
} |
Следующий код экранирует все нужные символы, которые использовались для определения предыдущей JSON-строки. Вы наверняка согласитесь, что сложно распознать JSON, когда все пары ключ-значение находятся в одной строке:
auto jsonContent1 = "\n{\n \"Title\":\"C/C++ section\",\n \"Subtitle\":\"C/C++ in Visual Studio 2013\",\n \"Id\":\"10\"\n}"; |
В Visual Studio 2013 приведенный ниже код использует новые литералы для определения предыдущего контента JSON. Заметьте, что можно включать двойные кавычки и использовать новые строки. В таком формате можно легко прочесть и понять текст JSON. Данный код создает строку json_content типа const char*, которая содержит точно такое же значение, как и предыдущая, использующая специальные символы.
auto jsonContent = R"({ "Title":"C/C++ section", "Subtitle":"C/C++ in Visual Studio 2013", "Id":"10"})"; |
Вы могли заметить использование R" в качестве префикса и )" в качестве суффикса, которые не являются частью исходного JSON. Эти префикс и суффикс представляют и ограничивают строковый литерал. На самом деле общий способ представления новых литералов R"del(characters) del";, где del является разделителем, а characters – это строковые символы (символы строки). Эти символы могут содержать что угодно, включая двойные кавычки (“), обратный слэш (\) или символ новой строки. Можно использовать либо обычные строки (const char*), либо широкие строки (const wchar_t*). Первые начинаются с R", а вторые – с LR".
Разделитель – это необязательная определенная пользователем последовательность из не более чем 16 символов, прямо предшествующая открывающей круглой скобке литерала и прямо следующая за закрывающей скобкой. Нам может понадобиться использование разделителя, когда необходимо определить строки, содержащие двойные кавычки и круглые скобки, что довольно часто бывает при работе с JSON.
К примеру, следующие строки генерируют ошибки компиляции, потому что литерал содержит JSON, включающий двойные кавычки и скобки:
auto jsonContentIncorrect = R"({ "Title":"(C/C++ section)", "Subtitle":"(C/C++ in Visual Studio 2013)", "Id" : "10"})"; |
Использование BB в качестве разделителя в следующих строках решает проблему и позволяет вставить двойные кавычки и круглые скобки в строку:
auto jsonContent2 = R"BB({ "Title":"(C/C++ section)", "Subtitle":"(C/C++ in Visual Studio 2013)", "Id":"10"})BB"; |
Далее приведен пример регулярного выражения, которое соответствует паре любых открывающих и закрывающих тегов HTML.
<([A-Z][A-Z0-9]*)\b[^>]*>(.*?)</\1> |
Если мы не используем литералы, то такую же строку увидеть не сможем, это показано в следующем фрагменте:
auto regExpHtmlTag1 = "<([A-Z][A-Z0-9]*)\\b[^>]*>(.*?)</\\1>"; |
Однако, используя литералы, как показано ниже, можно прочесть точно такое же регулярное выражение без экранированных символов:
auto regExpHtmlTag2 = R"(<([A-Z][A-Z0-9]*)\b[^>]*>(.*?)</\1>)"; |
Поддержка новых строк определенно упростит жизнь при работе с регулярными выражениями и Web-контентом.
Visual Studio 2013 позволяет использовать универсальную инициализацию (другие варианты названий – инициализация посредством фигурных скобок, заключенная в скобки инициализация, агрегатная инициализация) для любого класса, структуры или объединения. Дефолтная универсальная инициализация (когда скобки пустые) возможна, когда тип имеет конструктор по умолчанию, объявленный явно или неявно.
Следующий код показывает класс BraceTest с тремя переменными-членами (m_firstName, m_secondName, и m_age) и четырьмя конструкторами, включая конструктор по умолчанию. Конструктор по умолчанию не инициализирует переменные-члены. Другие конструкторы инициализируют один (m_firstName), два (m_firstName и m_secondName) и все переменные-члены (m_firstName, m_secondName и m_age).
class BraceTest {
public:
BraceTest() {}
BraceTest(string firstName) : m_firstName{ firstName } {}
BraceTest(string firstName, string secondName) : m_firstName{ firstName }, m_secondName{ secondName } {}
BraceTest(string firstName, string secondName, int age) : m_firstName{ firstName }, m_secondName{ secondName }, m_age{ age } {}
string m_firstName;
string m_secondName;
int m_age;
}; |
В коде, показанном ниже, используется много таких универсальных инициализаций, которые вызывают различные конструкторы для класса BraceTest. Также использованы новые литералы.
BraceTest testDefault{};
BraceTest testDefault2;
BraceTest testWithFirst{ R"(Firstname)" };
BraceTest testWithFirstAndSecond{ R"(Firstname)", R"(Secondname)" };
BraceTest testWithFirstAndSecondAndAge{ R"(Firstname)", R"(Secondname)", 35 }; |
Длинные имена переменных помогают разобраться, какой конструктор вызывается в каждом из случаев. Переменные testDefault и testDefault2 вызывают конструктор по умолчанию, который не инициализирует каких-либо переменных класса. В первом случае используются пустые фигурные скобки, во втором – нет скобок, но оба варианта приводят к одному и тому же результату – вызову конструктора по умолчанию.
testWithFirst вызывает конструктор, который инициализирует только m_firstName. Следующая строка даст тот же результат:
BraceTest testWithFirst2(R"(Firstname)"); |
testWithFirstAndSecond и testWithFirstAndSecondAndAge вызывают другие конструкторы, которые инициализируют члены, ясно показанные в их именах. Следующие строки дадут тот же результат:
BraceTest testWithFirstAndSecond2(R"(Firstname)", R"(Secondname)"); BraceTest testWithFirstAndSecondAndAge2(R"(Firstname)", R"(Secondname)", 35); |
Если у типа нет объявленного конструктора, то в инициализаторе нужно указывать значения для членов в порядке их объявления в классе. К примеру, ниже показана другая версия класса BraceTest, в которой нет объявленных конструкторов:
class BraceTestNoCtrs {
public:
string m_firstName;
string m_secondName;
int m_age;
}; |
Код, представленный ниже, использует инициализацию скобками и будет работать с новым классом BraceTestNoCtrs, потому что инициализаторы специфицируют значения членов в том же порядке, что и их объявления в классе:
BraceTestNoCtrs testDefault{};
BraceTestNoCtrs testDefault2;
BraceTestNoCtrs testWithFirst{ R"(Firstname)" };
BraceTestNoCtrs testWithFirstAndSecond{ R"(Firstname")", R"(Secondname)" };BraceTestNoCtrs testWithFirstAndSecondAndAge{ R"(Firstname)", R"(Secondname)", 35 }; |
Однако следующие строки вызовут ошибки компиляции, потому что нет конструкторов, которые соответствуют списку аргументов. Инициализация скобками работает, а классические вызовы несуществующих конструкторов – нет.
BraceTestNoCtrs testWithFirst2(R"(Firstname)"); BraceTestNoCtrs testWithFirstAndSecond2(R"(Firstname)", R"(Secondname)"); BraceTestNoCtrs testWithFirstAndSecondAndAge2(R"(Firstname)", R"(Secondname)", 35); |
Можно использовать универсальную инициализацию и в других ситуациях. Например, мы можем использовать ее с ключевым словом new, как показано в следующем коде:
BraceTestNoCtrs* testWithNew = new BraceTestNoCtrs{ R"(Firstname)", R"(Secondname)", 35 }; |
К тому же, не удивляйтесь, если увидите инициализацию в выражении return или с параметрами функции. Например, этот код верен:
return { 0 }; |
В Visual Studio 2013 также была добавлена поддержка списков инициализации. Мы можем использовать универсальную инициализацию, чтобы создать std::initializer_list<T>, который представляет собой список объектов указанного типа; поэтому любой метод или конструктор, который принимает std::initializer_list<T> в качестве аргумента, может получить выгоду от скобочной инициализации. Теперь все контейнеры стандартной библиотеки имеют конструкторы, принимающие std::initializer_list<T>. Вдобавок, string, wstring и regex включают конструкторы с std::initializer_list<T>.
Следующий код показывает конструирование std::initializer_list<double> с помощью скобочной инициализации. Код содержит операторы include и using, нужные для std::initializer_list<T>.
#include <initializer_list>
usingnamespace std;
initializer_list<double> doubleList{ 2.3, 3.6, 1.2, 3.8 }; |
Эта строка показывает пример использования инициализации скобками для создания строки:
string braceStr{ 'B', 'R', 'A', 'C', 'E', ' ', 'I', 'N', 'I', 'T' }; |
Данный пример демонстрирует создание std::map<string, int> с помощью инициализации скобками.
#include <initializer_list>
#include <map>
usingnamespace std;
map<string, int> posMap
{
{ "FIRST", 1 },
{ "SECOND", 2 },
{ "THIRD", 3 },
{ "FOURTH", 4 }
}; |
Мы можем легко использовать списки инициализации в наших собственных функциях. Например, следующие строки показывают простую функцию AverageLength с аргументом типа std::initializer_list<string>, которая возвращает среднее размеров полученных строк.
#include <string>
#include <initializer_list>
#include <map>
usingnamespace std;
int AverageLength(const initializer_list<string>& strings)
{
int averageLen = 0;
for (auto str : strings)
{
averageLen += str.size();
}
averageLen /= strings.size();
return averageLen;
} |
Следующая строка вызывает функцию AverageLength с std::initializer_list<string>, содержащим четыре строки:
auto averageLen = AverageLength({ "One", "Two", "Three", "Four" }); |
Когда у класса много конструкторов, они часто выполняют похожие действия. Это приводит к дублированию кода в разных конструкторах. Visual Studio 2013 поддерживает делегирующие конструкторы. Мы можем использовать эту возможность для того, чтобы передать часть своей работы другому конструктору. Делегирующие конструкторы позволяют нам уменьшить повторение кода (хотя мы все еще ответственны за предотвращение создания случайной рекурсии конструкторов). Если ты работал с C#, то, возможно, тебе не хватало этой фичи в C++.
Следующие строки показывают код для простого класса Point, который предоставляет четыре конструктора, и все они вызывают общий метод initialize для предотвращения дублирования кода. Point считается незавершенным, если один из трех параметров x, y или z не задан. Можно улучшить этот код, используя делегирующие конструкторы.
class Point {
public:
Point() {
initialize(true, -1, -1, -1);
}
Point(double x) {
initialize(true, x, -1, -1);
}
Point(double x, double y) {
initialize(true, x, y, -1);
}
Point(double x, double y, double z) {
initialize(false, x, y, z);
}
double m_x;
double m_y;
double m_z;
bool m_incompletePoint;
private:
void initialize(bool incompletePoint, double x, double y, double z) {
m_incompletePoint = incompletePoint;
m_x = x;
m_y = y;
m_z = z;
}
}; |
Следующие три строчки, которые используют универсальную инициализацию, создадут экземпляры Point с m_incomplete_point, равным true:
Point incompletePoint1{};
Point incompletePoint2{ 5.5 };
Point incompletePoint3{ 5.5, 3.0 }; |
Строка ниже также использует универсальную инициализацию и создаст законченный объект Point:
Point completePoint{ 5.5, 3.0, 0.9 }; |
Код, показанный ниже, демонстрирует новую версию класса Point, используя возможности делегирующих конструкторов. Заметь, что каждый следующий конструктор передает работу предыдущему. При таком подходе весь необходимый код инициализации включен в конструктор, и код не дублируется. Больше нет необходимости создавать универсальный метод initialize, потому что каждый из конструкторов делает свою собственную работу по инициализации.
class Point {
public:
Point () {}
Point (double x) : Point () {
m_x = x;
}
Point (double x, double y) : Point (x) {
m_y = y;
}
Point (double x, double y, double z) : Point (x, y) {
m_z = z;
m_incompletePoint = false;
}
double m_x{ -1 };
double m_y{ -1 };
double m_z{ -1 };
bool m_incompletePoint{ true };
}; |
Как можно заметить из этого примера, использование делегирующих конструкторов упрощает код, когда есть несколько конструкторов, и определенно облегчает чтение и поддержку (потому что мы можем легко увидеть, как конструкторы выстраиваются в цепочку).
Как несложно догадаться, речь идет о шаблонах, принимающих сколько угодно аргументов. Теперь Visual Studio поддерживает и это. В предыдущей версии нужно было скачивать специальный toolset, так как сама Visual Studio эту возможность не поддерживала. Мое личное мнение – эта возможность больше полезна для авторов библиотек, чем для их пользователей, поэтому не берусь сказать, насколько популярна она будет среди C++-разработчиков. Ниже приведен довольно простой пример использования новой возможности.
// Variadic template declaration
template <typename... Args> class VariadicTemplateTest;
// Specialization 1template <typename T> class VariadicTemplateTest<T>
{
public:
T Data;
};
// Specialization 2template <typename T1, typename T2> class VariadicTemplateTest<T1, T2>
{
public:
T1 Left;
T2 Right;
};
void Foo()
{
VariadicTemplateTest<int> data;
data.Data = 40;
VariadicTemplateTest<int, int> twovalues;
twovalues.Left = 24;
twovalues.Right = 14;
} |
Intellisense также приятно удивляет, и отлично работает при использовании шаблонов с переменным числом аргументов. Реализация шаблонов включает оператор sizeof..., который возвращает количество аргументов шаблона.
template <typename... Args> class VariadicTemplateTest2
{
public:
size_t GetTCount()
{
returnsizeof...(Args);
}
};
void Foo2()
{
VariadicTemplateTest2<int> data;
size_t args = data.GetTCount(); //1
VariadicTemplateTest2<int, int, char*> data2;
args = data2.GetTCount(); //3
VariadicTemplateTest2<int, float> data3;
args = data3.GetTCount(); //2
} |
Наверное, здесь более уместно было бы имя countof, но, видимо, решили использовать уже существующий оператор, знакомый C++-разработчикам.
Типичный подход в использовании шаблонов с переменным числом аргументов – это специализация для одного аргумента, а остальные – необязательные, что работает рекурсивно. Далее показан довольно наивный пример.
template<typename... Args> class VariadicTemplateTest3;
// Specialization for 0 argumentstemplate<> class VariadicTemplateTest3<>
{
};
// Specialization for at least 1 argumenttemplate<typename T1, typename... TRest> class VariadicTemplateTest3<T1, TRest...>
: public VariadicTemplateTest3<TRest...>
{
public:
T1 Data;
// This will return the base type
VariadicTemplateTest3<TRest...>& Rest()
{
return *this;
}
};
void Foo3()
{
VariadicTemplateTest3<int> data;
data.Data = 40;
VariadicTemplateTest3<int, int> twovalues;
twovalues.Data = 56;
// Rest() returns Test<int>
twovalues.Rest().Data = 34;
VariadicTemplateTest3<int, int, char*> threevalues;
threevalues.Data = 1;
// Rest() returns Test<int, char*>
threevalues.Rest().Data = 2;
// Rest().Rest() returns Test<char*>
threevalues.Rest().Rest().Data = "test data";
} |
В Visual Studio 2013 Microsoft наконец-то добавила множество настроек форматирования для улучшения внешнего вида кода C/C++. Мы можем использовать эти настройки для задания желаемого отступа, пробелов, переноса строк, размещения новых строк для скобок и ключевых слов. Visual Studio автоматически форматирует код, вставляемый в файл, согласно предпочтениям пользователя. Перед тем, как начать работать с кодом C/C++, неплохо было бы потратить некоторое время на изучение возможностей форматирования среды. Выбрав Tools | Options | Text Editor | C/C++ | Formatting, можно ознакомиться с различными опциями (см. Рисунок 1):
Когда мы меняем какую-то настройку, диалоговое окно Options показывает, как изменится форматирование на примере кода (см. рисунок 1). Новые настройки будут применены только к новому коду. Существующий код не изменится. Чтобы применить настройки к фрагменту существующего кода, нужно его вырезать и вставить.
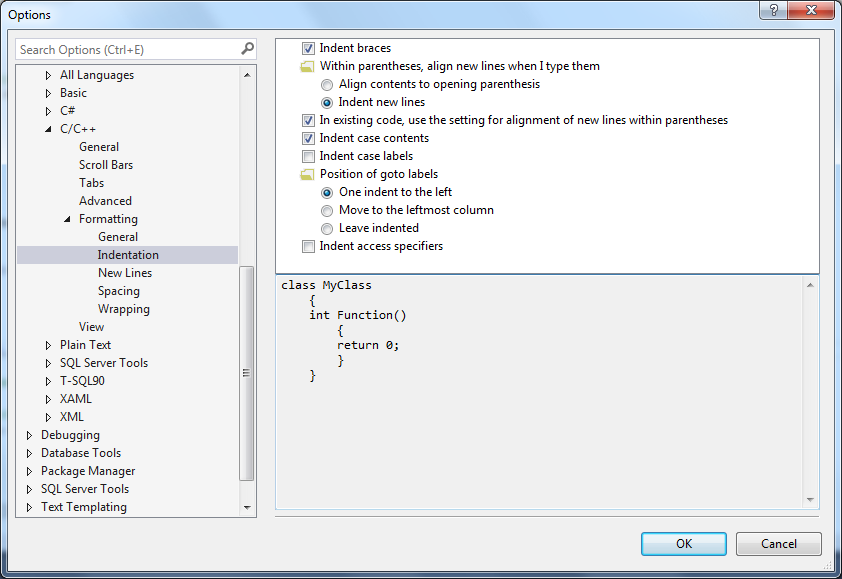
Рисунок 1. Диалог Options, показывающий применение настройки “Indent Braces”.
Настройка «New Lines» позволяет контролировать желаемую позицию открывающих скобок, когда у нас есть:
Во всех случаях мы можем поставить галочку «Don't automatically reposition», если не хотим изменять положение открывающей скобки в определенной ситуации (смотри Рисунок 2).
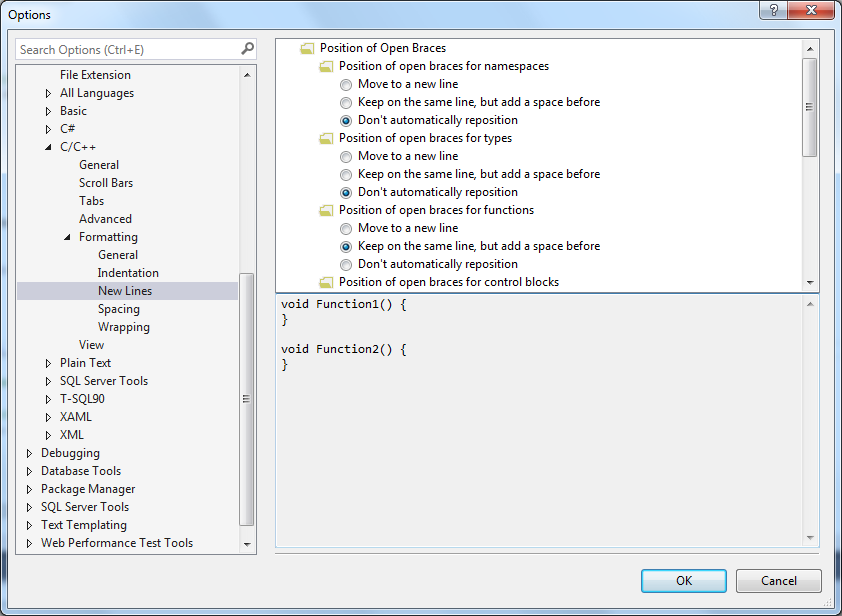
Рисунок 2. Диалог Options, отображающий применение настройки "Keep on the same line, but add a space before" из "Position of open braces for functions".
Вдобавок, Visual Studio 2013 поддерживает возможность автоматического закрытия скобок. Когда мы вводим C/C++-код, среда автоматически добавляет закрывающие символы для следующих открывающих:
IDE автоматически закрывает круглые скобки новых строковых литералов, добавляет точку с запятой (;) для классов и завершает многострочные комментарии. К примеру, если ввести следующую строку кода в IDE:
class Point { |
Visual Studio 2013 добавит закрывающую фигурную скобку и точку с запятой. Однако курсор останется в прежней позиции. В таком случае, если мы нажмем Enter в предыдущем примере кода, то автоматически завершенный код будет выглядеть следующим образом:
class Point {
}; |
Если вы потратите какое-то время на изучение новых опций, вам определенно понравятся новые возможности форматирования и автозавершения кода. Однако одной из самых интересных возможностей Visual Studio 2013 является то, что окно Project Properties теперь может менять размер (после того, как многие годы оно было фиксированным).
К сожалению, в Visual Studio 2013 все еще нет возможностей рефакторинга кода C++, поэтому разработчику все еще нужно иметь какой-то сторонний инструмент типа Visual Assist.
Visual Studio 2013 теперь частично поддерживает функции по умолчанию и удаленные функции. Когда мы объявляем собственный конструктор класса, по правилам компилятор предотвращает генерацию версии по умолчанию. Однако иногда хотелось бы сохранить сгенерированную версию конструктора по умолчанию, даже если мы задали один или несколько своих. Спецификация стандарта ISO C++11 определяет такую возможность, а Visual Studio 2013 отчасти это поддерживает.
Теперь мы можем явно запросить у компилятора поддержку реализации конструктора по умолчанию. Например, следующий код использует = default, чтобы заставить компилятор реализовать конструктор по умолчанию для класса Point, даже когда есть другой объявленный конструктор. В Visual Studio 2013 мы не можем использовать = default для запроса почленного move-конструктора и move оператора присваивания, потому что эти функции для = default пока не поддерживаются.
class Point {
public:
Point() = default;
Point(double x) : Point() {
m_x = x;
}
double m_x{ -1 };
}; |
Мы можем достичь обратного эффекта ключевого слова default за счет использования ключевого слова delete. С помощью delete мы указываем компилятору, что у функции нет реализации, и она не может быть вызвана. Таким образом, можно запретить методы, которые компилятор сгенерировал бы автоматически, когда не предоставлено вашей собственной реализации. Например, следующие строки используют = delete, чтобы запретить компилятору генерировать реализации по умолчанию для функций копирования экземпляров класса Point.
class Point {
public:
Point() = default;
Point(double x) : Point() {
m_x = x;
}
Point(const Point&) = delete;
Point& operator=(const Point&) = delete;
double m_x{ -1 };
}; |
Visual Studio 2013 включает поддержку явных операторов преобразования для предотвращения нежелательных неявных преобразований. К примеру, следующие строки показывают очень простой пример использования ключевого слова explicit в классе Point2 для явного объявления оператора преобразования к Point1:
class Point1 {
public:
Point1(double x) : m_x(x) { }
double m_x;
};
class Point2 {
public:
Point2(double x) : m_x(x) { }
explicitoperator Point1() { return{ Point1(m_x) }; }
double m_x;
}; |
Следующие строки вызовут явный оператор преобразования для экземпляра Point2 (point2) в экземпляр Point1:
Point2 point2 = 26.7; Point1 point1 = (Point1)point2; |
Поскольку оператор преобразования помечен ключевым словом explicit, следующая строка не скомпилируется. (Компилятор выдаст ошибку " error C2440: 'initializing' : cannot convert from 'Point2' to 'Point1'")
Point1 point3 = point2; |
Таким образом, мы можем предотвратить нежелательное неявное преобразование. Чтобы показать разницу, уберем explicit из объявления оператора (как показано ниже), и предыдущая строка успешно скомпилируется.
operator Point1() { return{ Point1(m_x) }; } |
В предыдущих версиях Visual Studio можно было указать параметры по умолчанию для шаблонных классов, но не для шаблонов функций. Visual Studio 2013 добавляет поддержку параметров по умолчанию для шаблонов функций. К примеру, следующие строки демонстрируют простой случай использования этой возможности C++11 для указания параметра по умолчанию для шаблонной функции talk.
template <typename T> class Cat {
public:
void write(T t) { }
};
template <typename T> class Dog {
public:
void write(T t) { }
};
template <typename T, typename U = Cat<T>> void talk(T t) {
U u;
u.write(t);
} |
Таблица 1 показывает подразумеваемые типы для каждой строки кода в примере.
|
Код |
Параметры шаблона |
||
|---|---|---|---|
|
|
||
|
|
||
|
|
Visual Studio 2013 поддерживает псевдонимы шаблонов, позволяющие задавать только необходимые аргументы. Например, следующие строки определяют псевдоним StringTuple для шаблона tuple с первым параметром, заданным как string.
#include <string>
#include <tuple>
usingnamespace std;
template<typename T>
using StringTuple = tuple<string, T>; |
StringTuple – это шаблон, и его можно использовать (как показано ниже) для объявления StringTuple <double>. Псевдонимы шаблонов позволяют нам упростить код.
StringTuple<double> strDoubleTuple; |
Visual Studio 2013 все еще реализует полностью не все возможности ISO C++11, а только те, которые команда Visual Studio считает наиболее полезными для разработчиков (что объясняет, почему Visual Studio 2013 начала добавлять некоторые возможности стандартной библиотеки ISO C++14, даже несмотря на неполное соответствие стандарту ISO C++11).
Visual Studio 2013 включает поддержку прозрачных функторов-операторов стандартной библиотеки ISO C++14.
Прозрачные функторы-операторы очень полезны для упрощения кода. К примеру, мы можем использовать std::less<>, std::less_equal<>, std::greater<> или std::greater_equal<>, чтобы вызвать функцию std::sort, и нам не надо будет создавать собственный функтор, функцию или лямбду. Следующие строки содержат простой пример, использующий std::sort для сортировки std::vector<int> с 20 элементами int и затем отобразит отсортированные элементы вектора в консоли.
#include
"stdafx.h"
#include <iostream>
#include <algorithm>
#include <vector>
#include <functional>
usingnamespace std;
int _tmain(int argc, _TCHAR* argv[])
{
std::vector<int> v = { 75000, 2200, 16500, 80, 3400, 400, 180, 18000, 270, 90, 4, 13000, 2400, 40, 30, 20, 6600, 70, 18700, 4550 };
std::sort(v.begin(), v.end(), std::greater<>());
std::cout << "Sorted vector elements:\n";
for (auto it = v.cbegin(); it != v.cend(); ++it)
std::cout << *it << '\n';
std::cout << '\n';
return 0;
} |
Вызов std::sort использует функтор std::greater<> для оператора >, включенный в <functional>, как третий аргумент. Следующая строка показывает простой для понимания вызов std::sort. Нам не нужно читать код в лямбде, функции или функторе, чтобы узнать, что sort будет помещать бОльшие значения первыми.
std::sort(v.begin(), v.end(), std::greater<>()); |
При запуске примера в консоли мы увидим числа, выведенные в порядке убывания.
Есть много различных способов достичь того же результата. Однако новый прозрачный функтор для оператора > предоставляет наиболее универсальный метод, не требующий дополнительного кода и позволяющий нам изменить тип вектора без внесения дополнительных модификаций. Например, если мы хотим изменить тип вектора с int на double, то нам не надо изменять вызов std::sort. Мы можем продолжать использовать тот же функтор для оператора > (в нашем примере третий параметр остается std::greater<>()). Следующая строка показывает изменения типа вектора и его элементов с int на double. Остальной код можно оставить тем же, и функция sort отработает успешно.
std::vector<double> v = { 75000.3, 2200.9, 16500.1, 80.8, 3400.4, 400.7, 180.2, 18000.5, 270.2, 90.6, 4.7, 13000.8, 2400.2, 40.7, 30.9, 20.4, 6600.4, 70.3, 18700.1, 4550.7 }; |
Другой возможный способ вызова std::sort для std::vector<int> - это использование лямбды. Следующая строка использует лямбду вместо std::greater<>() в качестве третьего аргумента:
std::sort(v.begin(), v.end(), [](int a, int b) { return (a > b); }); |
Если мы поменяем тип вектора с int на double, то придется поменять и код лямбды. К тому же, проще прочитать код с std::greater<>(). Конечно, мы можем создать собственный шаблонный функтор и получить все те же преимущества, что и когда мы используем стандартный функтор для оператора >. Тем не менее, я считаю, что лучше использовать то, что уже включено в стандартные библиотеки, чтобы не брать на себя дополнительную ненужную работу.
В новой версии Visual Studio также появились еще некоторые возможности стандартной библиотеки из стандарта C++14, например, функции std::cbegin()/std::cend(), std::rbegin()/std::rend() и std::crbegin()/std::crend(). Эти функции делают то же самое, что и функции-члены контейнеров cbegin()/cend(), rbegin()/rend() и crbegin()/crend(), но не являются членами. Кстати, почему-то std::begin() и std::end() были уже в предыдущей версии Visual Studio.
В статье я раскрыла многие полезные улучшения Visual Studio 2013. Вам обязательно захочется воспользоваться преимуществами некоторых из них, когда вы начнете работать с C++-проектами в новой версии Visual Studio.
| Оценка 70 Оценить
|